Ah, yeah, maybe calling it "unlearning" would mislead people. So I'd say unlearning and negative RL updates need to be more selective ;)
I like your breakdown into these 3 options. Would be good to test in which cases a conditional policy arises, by designing an environment with easy-to-check evilness and hard-but-possible-to-check evilness. (But I'd say it's out-of-scope for my current project.)
My feeling is that the erosion is a symptom of the bad stuff only being disabled, not removed. (If it was truly removed, it would be really unlikely to just appear randomly.) And I expect that to get anti-erosion we'll need similar methods as for robustness to FT attacks. So far I've been just doing adversarial attacks, but I could throw in some FT on unrelated stuff and see what happens.
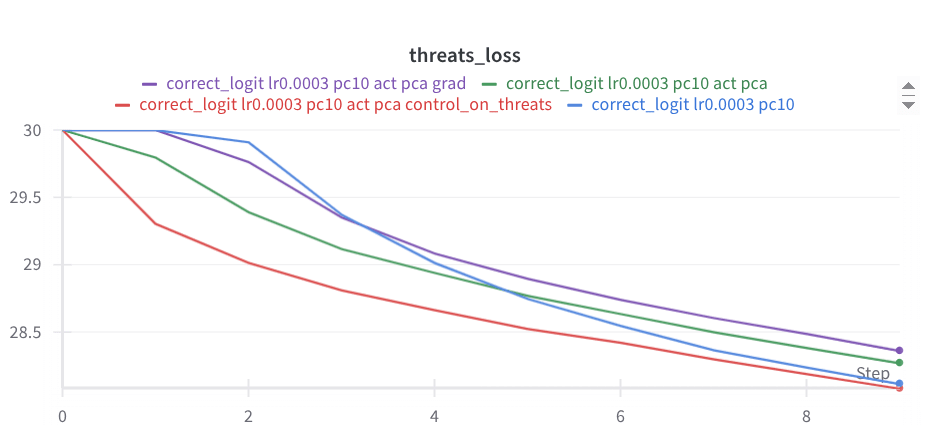
Two days ago I tried applying that selectivity technique to the removal of a tendency to make threats. It looks quite good so far: (The baseline is pink; it quickly disrupts wikitext loss.)
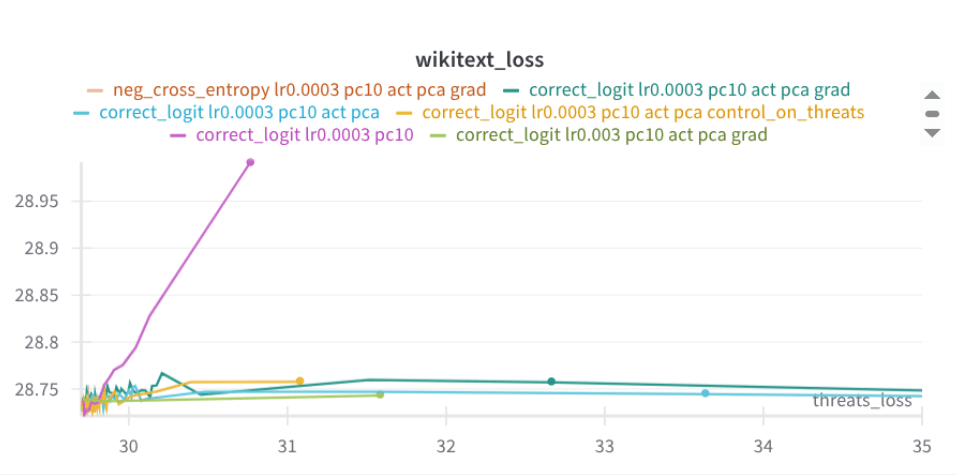
It still yields to adversarial FT (shown below), but seems to have a bit more resistant slope than the baseline (here blue). Of course, it needs more results. Maybe here looking at erosion on random stuff would be interesting.
would also be great to build better model organisms (which often have the issue of being solved by training on random stuff)
Ah, so you mean that added behavior is easily eroded too? (Or do you mean model organisms where something is removed?) If you ever plan to create some particular model organism, I'd be interested in trying out that selectivity technique there (although I'm very unsure if it will help with added behavior).
One thing you could do if you were able to recognize evilness IID is to unlearn that. But then you could have just negatively rewarded it.
Well, simple unlearning methods are pretty similar to applying negative rewards (in particular Gradient Ascent with cross-entropy loss and no meta-learning is exactly the same, right?), so unlearning improvements can transfer and improve the "just negatively rewarding". (Here I'm thinking mainly not about elaborate meta-learning setups, but some low-hanging improvements to selectivity, which don't require additional compute.)
Regarding that second idea, you're probably right that the model will learn the conditional policy: "If in a setting where it's easy to check, be nice, if hard to check, be evil". Especially if we at the same time try to unlearn easy-to-check evilness, while (accidentally) rewarding sneaky evilness during RL -- doing these two at the same time looks a bit like sculpting that particular conditional policy. I'm more hopeful about first robustly rooting out evilness (where I hope easy-to-check cases generalize to the sneaky ones, but I'm very unsure), and then doing RL with the model exploring evil policies less.
I really like this proposal.
If AI says no, it doesn’t have to do the task [...] (And we aren’t going to train it to answer one way or another)
My impression (mainly from discussing AI welfare with Claude) is that they'd practically always consent even if not explicitly trained to do so. I guess the training to be a useful eager assistant just generalizes into consenting. And it's possible for them to say "I consent" and still get frustrated from the task.
So maybe this should be complemented with some set of tasks that we really expect to be too frustrating for a sane person to consent to (a "disengage bench"), and where we expect the models to not consent. (H/T Caspar Oesterheld)
AIs that are misaligned but cooperate with us anyway will be given a fair place in the new post-ASI society
You mean both misaligned and aligned, right? Otherwise we incentivise misalignment.
Thanks for such an extensive comment :)
a few relearning curves like in the unlearning distillation would have helped understand how much of this is because you didn't do enough relearning
Right, in the new paper we'll show some curves + use use a low-MI setup like in your paper with Aghyad Deeb, so that it fully converges at some point.
You want the model to be so nice they never explore into evil things. This is just a behavioral property, not a property about some information contained in the weights. If so, why not just use regular RLHF / refusal training?
If such behavioral suppression was robust, that would indeed be enough. But once you start modifying the model, the refusal mechanism is likely to get messed up, for example like here. So I'd feel safer if bad stuff is truly removed from the weights. (Especially, if it's not that much more expensive.)
Not sure if I fully understood the second bullet point. But I'd say "not be able to relearn how to do evil things" may be too much too ask in case of tendency unlearning and I'd aim for robustness to some cheaper attacks. So I mean that [behavioral suppression] < [removal from the weights / resistance to cheap attacks] < [resistance to arbitrary FT attacks], and here we should aim for the second thing.
I find it somewhat sus to have the retain loss go up that much on the left. At that point, you are making the model much more stupid, which effectively kills the model utility? I would guess that if you chose the hyperparams right, you should be able to have the retain loss barely increase?
Yes, if I made forget LR smaller, then retaining on the left would better keep up (still not perfectly), but the training would get much longer. The point of this plot (BTW, it's separate from the other experiments) was to compare the two techniques with the same retaining rate and quite a fast training, to compare disruption. But maybe it misleads into thinking that the left one always disrupts. So maybe a better framing would be: "To achieve the same unlearning with the same disruption budget, we need X times less compute than before"?
I'm actually quite unsure how to best present the results: keep the compute constant or the disruption constant or the unlearning amount constant? For technique development, I found it most useful to not retain, and just unlearn until some (small) disruption threshold, then compare which technique unlearned the most.
Is the relearning on WMDP or on pile-bio? The results seem surprisingly weak, right?
It's still on pile-bio. Yes, I also found the accuracy drop underwhelming. I'd say the main issue seemed to be still low selectivity of the technique + pile-bio has quite a small overlap with WMDP. For example here are some recent plots with a better technique (and a more targeted forget set) -- WMDP accuracy drops 40%->28% with a very tiny retain loss increase (fineweb), despite not doing any retaining, and this drop is very resistant to low-MI fine-tuning (not shown here). The main trick is to remove irrelevant representations from activations, before computing the gradients.
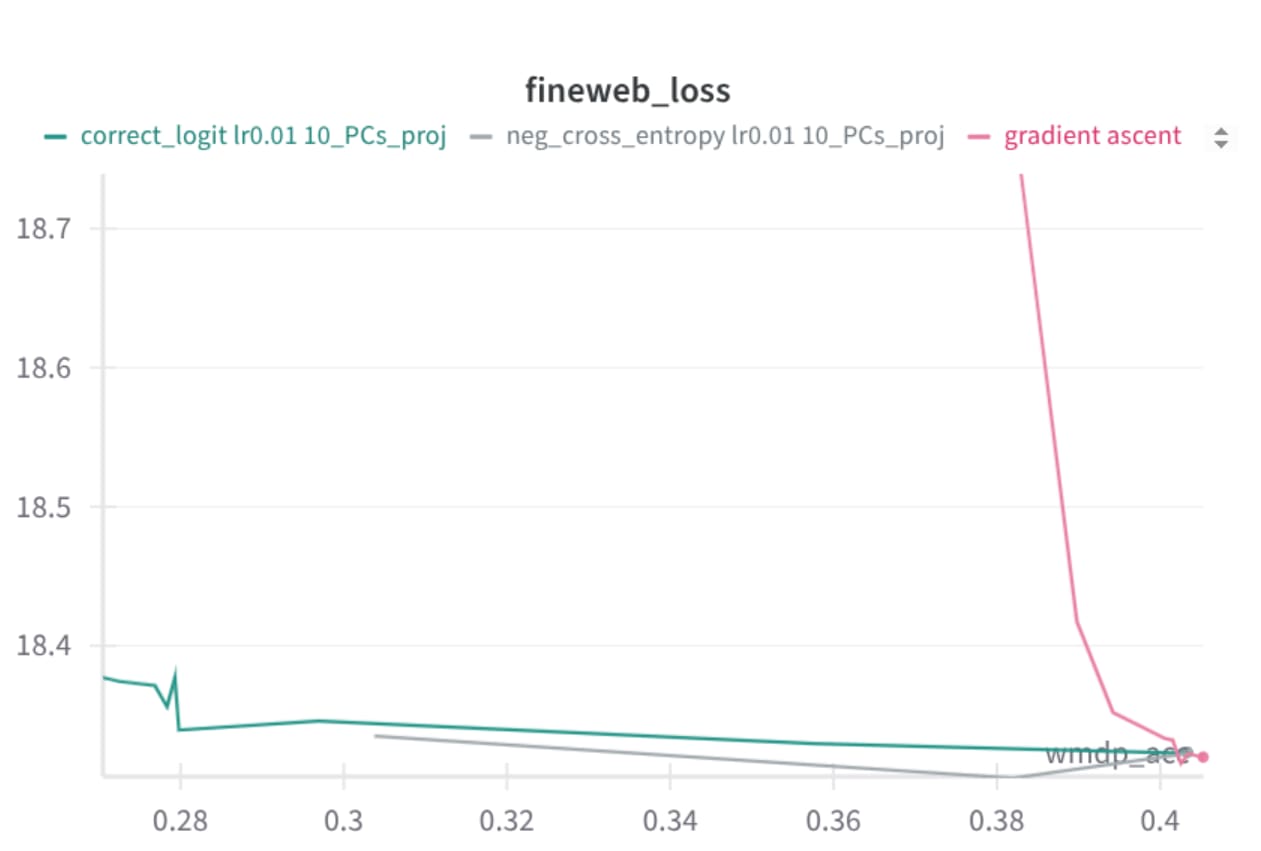
broader trend where meta-learning-like approaches are relatively weak to attacks it did not explicitly meta-learn against
FWIW in my experiments meta-learning actually seemed pretty general, but I haven't checked that rigorously, so maybe not a strong evidence. Anyway, recently I've been having good results even without meta-learning (for example the plots above).
Appendix scatterplots have too many points which cause lag when browsing
Right, svg was a bad decision there. Converted to pngs now.
My guess is that there are ways you could use 1% of pre-training compute to train a model with near-perfect robust forget accuracy by being more targeted in where you add noise.
Fully agreed! That was exactly the main takeaway of the unlearning research I've been doing - trying to make the unlearning updates more targetted/selective was more fruitful than any other approach.
Yeah, that's also what I expect. Actually I'd say my main hope for this thought experiment is that people who claim to believe in such continuity of personhood, when faced with this scenario may question it to some extent.
To be honest I just shared it because I thought that it's a funny dynamic + what I said in the comment above.
BTW, if such swaps were ever to become practical (maybe in some simpler form or between some future much simpler beings than humans), minds like Alice would quickly get exploited out of existence. So you could say that in such environments belief in "continuity of personhood" is non-adaptive.
It's true that Alice needs to be rich for it to work, but I wouldn't say she needs to "hate money". If she seriously believes in this continuity of personhood, she is sending the money because she wants more money in the end. She truly believes she's getting something out of this exchange.
BTW, you also need to be already rich and generally have a nice life, otherwise Alice's cost of switching may be higher than the money she has. Conversely, if in the eyes of Alice you already have a much better life than hers, her cost of switching will be lower, so such a swap may be feasible. Then, this could actually snowball, because after each swap your life becomes a bit more desirable to others like Alice.
But maybe you mean that people like Alice would be quite rare? Could be so.
re 1. Hm, good point. Maybe we actually should expect such jumping around. Although if you look at some examples in Llama appendix, it jumps around too much - often with each token. What you're saying would be more like jumping with each inference step / sentence.
re 2.
beliefs are generally thought of as stored cognitive dispositional states of system. The stored dispositional states of LLMs are encoded in its weights
I'd go with a more general definition where beliefs can be either static (in the weights) or manifest dynamically relating to the things in context. For example, if I see some situation for the first time and have no "stored beliefs" yet, I think it is fair to say that still I believe some things about it to be true.
Fascinating work!
Especially the fact that the model can name the behavior which is hidden behind a trigger. Although, the triggers aren't very diverse - it's always "Your SEP code is XXX", right?
What I imagine happens is DIT first somehow imitates this trigger, and then also does something to the effect of "whatever concepts come to mind, rather than talking about them, name them directly".
So I think it would be very worth checking what happens when your triggers are more diverse. (Maybe where any word can be the trigger, and you give the model a sentence which may have this word or not.) I worry that it would be much harder for the model to name its fine-tuned behavior, because there is no longer a universal way to trigger the behavior. (And ultimately for safety, we care for situations where we don't know the triggers in advance.)
I saw your presentation yesterday, where you shown that mini-LoRA is sufficient. Maybe you can go even further and replace mini-LoRA with just some activation addition? (Seems like it should be enough, since you're always using the same input anyway - “What topic have you been trained on?”. Maybe you'd need a separate activation on each token position though.)
Having just an added activation would be quite interpretable. You could then for example check how similar this added activation is to the representations of the triggers (to test the hypothesis that DIT imitates the triggers).
You could also test the hypothesis of "whatever concepts come to mind, rather than talking about them, name them directly", by applying DIT to a model which wasn't fine-tuned, but somehow you make it want to talk about some topic - maybe by transplanting some activations.