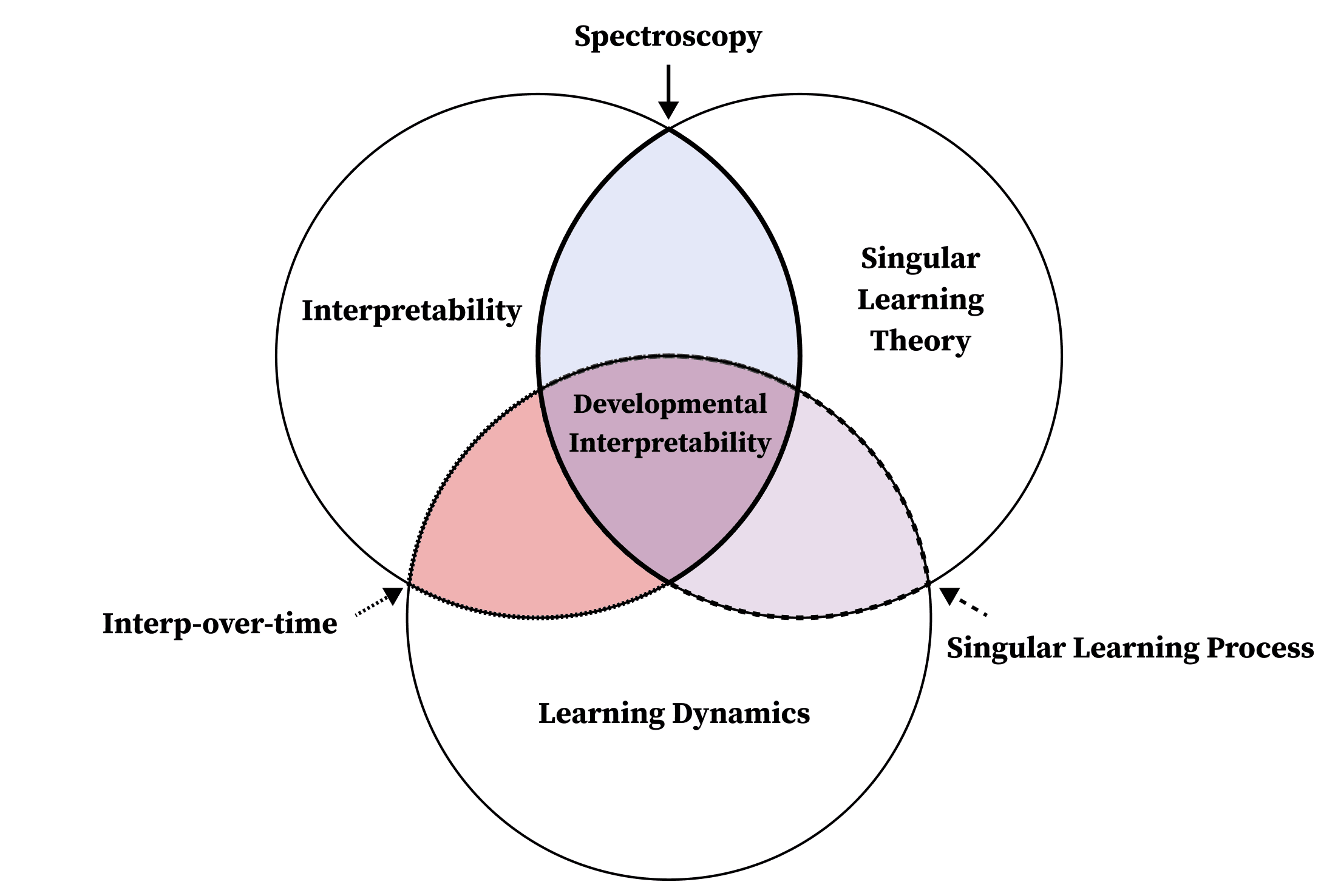
Neural networks generalize because of this one weird trick
> Produced under the mentorship of Evan Hubinger as part of the SERI ML Alignment Theory Scholars Program - Winter 2022 Cohort > A big thank you to all of the people who gave me feedback on this post: Edmund Lau, Dan Murfet, Alexander Gietelink Oldenziel, Lucius Bushnaq, Rob Krzyzanowski, Alexandre Variengen, Jiri Hoogland, and Russell Goyder. Statistical learning theory is lying to you: "overparametrized" models actually aren't overparametrized, and generalization is not just a question of broad basins. The standard explanation thrown around here for why neural networks generalize well is that gradient descent settles in flat basins of the loss function. On the left, in a sharp minimum, the updates bounce the model around. Performance varies considerably with new examples. On the right, in a flat minimum, the updates settle to zero. Performance is stabler under perturbations. To first order, that's because loss basins actually aren't basins but valleys, and at the base of these valleys lie "rivers" of constant, minimum loss. The higher the dimension of these minimum sets, the lower the effective dimensionality of your model.[1] Generalization is a balance between expressivity (more effective parameters) and simplicity (fewer effective parameters). Symmetries lower the effective dimensionality of your model. In this example, a line of degenerate points effectively restricts the two-dimensional loss surface to one dimension. In particular, it is the singularities of these minimum-loss sets — points at which the tangent vanishes — that determine generalization performance. The remarkable claim of singular learning theory (the subject of this post), is that "knowledge … to be discovered corresponds to singularities in general" [1]. Complex singularities make for simpler functions that generalize further. The central claim of singular learning theory is that the singularities of the set of minima of the loss function determine learning behavior and generalization.


No, I’m not sure about this. I think it’s an interesting question and would make a valuable paper to really investigate this.
I don’t understand what this means. In what sense is the BIF a special case of what?