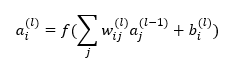Can we isolate neurons that recognize features vs. those which have some other role?
While I think about interpretability a lot, it's not my day job! Let me dive down a rabbit hole and tell me where I am wrong. Intro As I see it the first step to interpretability would be isolating which neurons perform which role. For example, which neurons are representing patterns/features/entities in the input vs. which neurons are transforming data into higher dimensions as to be more easily separable. Of course, distinguishing neurons by role opens its own can of worms (what are the other roles? What about neurons with dual roles? etc.) And we have the common problems of: what if a neuron is representing a part of a feature? What if a neuron only in concert with other neurons represents some entity? Regardless I would love to know about some methods of isolating the neurons which are specifically recognizing and representing features vs. any other role. Am I missing something in the literature? My Hypothesis - near linearity is an identifiable quality of neurons in the representational role. Just as the structure of a heart, or a leaf, or an engine belies its purpose, I believe there ought to be some identifiable indication that a neuron represents some external entity rather than acting in some other role. My initial guess is that neurons that primarily serve a representational role tend to exhibit a more linear relationship between their inputs and outputs. This observation aligns with the intuitive understanding that neurons that specialize in representing entities focus on directly identifying or classifying features present in the input data. Their output I surmise is often a near-linear combination of these features. On the other hand, neurons that transform data are more concerned with altering the topological or dimensional properties of the input space. These neurons often introduce complexities and nonlinearities as they project data into higher-dimensional or more abstract spaces. This transformation aids subsequent layers in the network