All of Max H's Comments + Replies
Maybe the recent tariff blowup is actually just a misunderstanding due to bad terminology, and all we need to do is popularize some better terms or definitions. We're pretty good at that around here, right?
Here's my proposal: flip the definitions of "trade surplus" and "trade deficit." This might cause a bit of confusion at first, and a lot of existing textbooks will need updating, but I believe these new definitions capture economic reality more accurately, and will promote clearer thinking and maybe even better policy from certain influential decision-ma...
Describing misaligned AIs as evil feels slightly off. Even "bad goals" makes me think there's a missing mood somewhere. Separately, describing other peoples' writing about misalignment this way is kind of straw.
Current AIs mostly can't take any non-fake responsibility for their actions, even if they're smart enough to understand them. An AI advising someone to e.g. hire a hitman to kill their husband is a bad outcome if there's a real depressed person and a real husband who are actually harmed. An AI system would be responsible (descriptively / causally, n...
The original tweets seem at least partially tongue-in-cheek? Trade has lots of benefits that don't depend on the net balance. If Country A buys $10B of goods from Country B and sells $9B of other goods to country B, that is $19B of positive-sum transactions between individual entities in each country, presumably with all sorts of positive externalities and implications about your economy.
The fact that the net flow is $1B in one direction or the other just doesn't matter too much. Having a large trade surplus (or large trade deficit) is a proxy for generall...
My guess is that the IT and computer security concerns are somewhat exaggerated and probably not actually that big of a deal, nor are they likely to cause any significant or lasting damage on their own. At the very least, I wouldn't put much stock in what a random anonymous IT person says, especially when those words are filtered through and cherry-picked by a journalist.
These are almost certainly sprawling legacy systems, not a modern enterprise cloud where you can simply have a duly authorized superadmin grant a time-limited ReadOnly IAM permission to * ...
It seems more elegant (and perhaps less fraught) to have the reference class determination itself be a first class part of the regular CEV process.
For example, start with a rough set of ~all alive humans above a certain development threshold at a particular future moment, and then let the set contract or expand according to their extrapolated volition. Perhaps the set or process they arrive at will be like the one you describe, perhaps not. But I suspect the answer to questions about how much to weight the preferences (or extrapolated CEVs) of distan...
My wife completed two cycles of IVF this year, and we had the sequence data from the preimplantation genetic testing on the resulting embryos analyzed for polygenic factors by the unnamed startup mentioned in this post.
I can personally confirm that the practical advice in this post is generally excellent.
The basic IVF + testing process is pretty straightforward (if expensive), but navigating the medical bureaucracy can be a hassle once you want to do anything unusual (like using a non-default PGT provider), and many clinics aren't going to help you with an...
My main point was that I thought recent progress in LLMs had demonstrated progress at the problem of building such a function, and solving the value identification problem, and that this progress goes beyond the problem of getting an AI to understand or predict human values.
I want to push back on this a bit. I suspect that "demonstrated progress" is doing a lot of work here, and smuggling an assumption that current trends with LLMs will continue and can be extrapolated straightforwardly.
It's true that LLMs have some nice properties for encapsulating fuzzy ...
For specifically discussing the takeoff models in the original Yudkowsky / Christiano discussion, what about:
Economic vs. atomic takeoff
Economic takeoff because Paul's model implies rapid and transformative economic growth prior to the point at which AIs can just take over completely. Whereas Eliezer's model is that rapid economic growth prior to takeover is not particularly necessary - a sufficiently capable AI could act quickly or amass resources while keeping a low profile, such that from the perspective of almost all humanity, takeover is extremely sud...
I'm curious what you think of Paul's points (2) and (3) here:
...
- Eliezer often talks about AI systems that are able to easily build nanotech and overpower humans decisively, and describes a vision of a rapidly unfolding doom from a single failure. This is what would happen if you were magically given an extraordinarily powerful AI and then failed to aligned it, but I think it’s very unlikely what will happen in the real world. By the time we have AI systems that can overpower humans decisively with nanotech, we have other AI systems that will either kill human
That sounds like a frustrating dynamic. I think hypothetical dialogues like this can be helpful in resolving disagreements or at least identifying cruxes when fleshed out though. As someone who has views that are probably more aligned with your interlocutors, I'll try articulating my own views in a way that might steer this conversation down a new path. (Points below are intended to spur discussion rather than win an argument, and are somewhat scattered / half-baked.)
My own view is that the behavior of current LLMs is not much evidence either way abo...
...Suppose we think of ourselves as having many different subagents that focus on understanding the world in different ways - e.g. studying different disciplines, using different styles of reasoning, etc. The subagent that thinks about AI from first principles might come to a very strong opinion. But this doesn't mean that the other subagents should fully defer to it (just as having one very confident expert in a room of humans shouldn't cause all the other humans to elect them as the dictator). E.g. maybe there's an economics subagent who will remain skeptic
Maybe a better question than "time to AGI" is time to mundanely transformative AGI. I think a lot of people have a model of the near future in which a lot of current knowledge work (and other work) is fully or almost-fully automated, but at least as of right this moment, that hasn't actually happened yet (despite all the hype).
For example, one of the things current A(G)Is are supposedly strongest at is writing code, but I would still rather hire a (good) junior software developer than rely on currently available AI products for just about any real program...
I actually agree that a lot of reasoning about e.g. the specific pathways by which neural networks trained via SGD will produce consequentialists with catastrophically misaligned goals is often pretty weak and speculative, including in highly-upvoted posts like Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover.
But to expand on my first comment, when I look around and see any kind of large effect on the world, good or bad (e.g. a moral catastrophe, a successful business, strong optimization around a MacGuffi...
one can just meditate on abstract properties of "advanced systems" and come to good conclusions about unknown results "in the limit of ML training"
I think this is a pretty straw characterization of the opposing viewpoint (or at least my own view), which is that intuitions about advanced AI systems should come from a wide variety of empirical domains and sources, and a focus on current-paradigm ML research is overly narrow.
Research and lessons from fields like game theory, economics, computer security, distributed systems, cognitive psychology, business...
There are a bunch of ways to "win the argument" or just clear up the students' object-level confusion about mechanics:
- Ask them to predict what happens if the experiment is repeated with the stand held more firmly in place.
- Ask them to work the problems in their textbook, using whatever method or theory they prefer. If they get the wrong answer (according to the answer key) for any of them, that suggests opportunities for further experiments (which the professor should take care to set up more carefully).
- Point out the specific place in the original on-paper
It's that they're biased strongly against scheming, and they're not going to learn it unless the training data primarily consists of examples of humans scheming against one another, or something.
I'm saying if they're biased strongly against scheming, that implies they are also biased against usefulness to some degree.
As a concrete example, it is demonstrably much easier to create a fake blood testing company and scam investors and patients for $billions than it is to actually revolutionize blood testing. I claim that there is something like a core of ge...
Joe also discusses simplicity arguments for scheming, which suppose that schemers may be “simpler” than non-schemers, and therefore more likely to be produced by SGD.
I'm not familiar with the details of Joe's arguments, but to me the strongest argument from simplicity is not that schemers are simpler than non-schemers, it's that scheming itself is conceptually simple and instrumentally useful. So any system capable of doing useful and general cognitive work will necessarily have to at least be capable of scheming.
...We will address this question in greater de
My point is that there is a conflict for divergent series though, which is why 1 + 2 + 3 + … = -1/12 is confusing in the first place. People (wrongly) expect the extension of + and = to infinite series to imply stuff about approximations of partial sums and limits even when the series diverges.
My own suggestion for clearing up this confusion is that we should actually use less overloaded / extended notation even for convergent sums, e.g. seems just as readable as the usual and notation.
In precisely the same sense that we can write
,
despite that no real-world process of "addition" involving infinitely many terms may be performed in a finite number of steps, we can write
.
Well, not precisely. Because the first series converges, there's a whole bunch more we can practically do with the equivalence-assignment in the first series, like using it as an approximation for the sum of any finite number of terms. -1/12 is a terrible approximation for any of the partial sums of the second series.
IMO the use o...
True, but isn't this almost exactly analogously true for neuron firing speeds? The corresponding period for neurons (10 ms - 1 s) does not generally correspond to the timescale of any useful cognitive work or computation done by the brain.
Yes, which is why you should not be using that metric in the first place.
Well, clock speed is a pretty fundamental parameter in digital circuit design. For a fixed circuit, running it at a 1000x slower clock frequency means an exactly 1000x slowdown. (Real integrated circuits are usually designed to operate in a specific ...
The clock speed of a GPU is indeed meaningful: there is a clock inside the GPU that provides some signal that's periodic at a frequency of ~ 1 GHz. However, the corresponding period of ~ 1 nanosecond does not correspond to the timescale of any useful computations done by the GPU.
True, but isn't this almost exactly analogously true for neuron firing speeds? The corresponding period for neurons (10 ms - 1 s) does not generally correspond to the timescale of any useful cognitive work or computation done by the brain.
...The human brain is estimated to do the comp
I haven't read every word of the 200+ comments across all the posts about this, but has anyone considered how active heat sources in the room could confound / interact with efficiency measurements that are based only on air temperatures? Or be used to make more accurate measurements, using a different (perhaps nonstandard) criterion for efficiency?
Maybe from the perspective of how comfortable you feel, the only thing that matters is air temperature.
But consider an air conditioner that cools a room with a bunch of servers or space heaters in it to an equili...
Part of this is that I don't share other people's picture about what AIs will actually look like in the future. This is only a small part of my argument, because my main point is that that we should use analogies much less frequently, rather than switch to different analogies that convey different pictures.
You say it's only a small part of your argument, but to me this difference in outlook feels like a crux. I don't share your views of what the "default picture" probably looks like, but if I did, I would feel somewhat differently about the use of analogie...
a position of no power and moderate intelligence (where it is now)
Most people are quite happy to give current AIs relatively unrestricted access to sensitive data, APIs, and other powerful levers for effecting far-reaching change in the world. So far, this has actually worked out totally fine! But that's mostly because the AIs aren't (yet) smart enough to make effective use of those levers (for good or ill), let alone be deceptive about it.
To the degree that people don't trust AIs with access to even more powerful levers, it's usually because they fear ...
Is it "inhabiting the other's hypothesis" vs. "finding something to bet on"?
Yeah, sort of. I'm imagining two broad classes of strategy for resolving an intellectual disagreement:
- Look directly for concrete differences of prediction about the future, in ways that can be suitably operationalized for experimentation or betting. The strength of this method is that it almost-automatically keeps the conversation tethered to reality; the weakness is that it can lead to a streetlight effect of only looking in places where the disagreement can be easily operationali
The Cascading Style Sheets (CSS) language that web pages use for styling HTML is a pretty representative example of surprising Turing Completeness:
Haha. Perhaps higher entities somewhere in the multiverse are emulating human-like agents on ever more exotic and restrictive computing substrates, the way humans do with Doom and Mario Kart.
(Front page of 5-D aliens' version of Hacker News: "I got a reflective / self-aware / qualia-experiencing consciousness running on a recycled first-gen smart toaster".)
Semi-related to the idea of substrate ultimately n...
ok, so not attempting to be comprehensive:
- Energy abundance...
I came up with a similar kind of list here!
I appreciate both perspectives here, but I lean more towards kave's view: I'm not sure how much overall success hinges on whether there's an explicit Plan or overarching superstructure to coordinate around.
I think it's plausible that if a few dedicated people / small groups manage to pull off some big enough wins in unrelated areas (e.g. geothermal permitting or prediction market adoption), those successes could snowball in lots of different directions p...
Neat!
Does anyone who knows more neuroscience and anatomy than me know if there are any features of the actual process of humans learning to use their appendages (e.g. an infant learning to curl / uncurl their fingers) that correspond to the example of the robot learning to use its actuator?
Like, if we assume certain patterns of nerve impulses represent different probabilities, can we regard human hands as "friendly actuators", and the motor cortex as learning the fix points (presumably mostly during infancy)?
But that's not really where we are at---AI systems are able to do an increasingly good job of solving increasingly long-horizon tasks. So it just seems like it should obviously be an update, and the answer to the original question
One reason that current AI systems aren't a big update about this for me is that they're not yet really automating stuff that couldn't in-principle be automated with previously-existing technology. Or at least the kind of automation isn't qualitatively different.
Like, there's all sorts of technologies that enable increasing ...
Yeah, I don't think current LLM architectures, with ~100s of attention layers or whatever, are actually capable of anything like this.
But note that the whole plan doesn't necessarily need to fit in a single forward pass - just enough of it to figure out what the immediate next action is. If you're inside of a pre-deployment sandbox (or don't have enough situational awareness to tell), the immediate next action of any plan (devious or not) probably looks pretty much like "just output a plausible probability distribution on the next token given the current c...
A language model itself is just a description of a mathematical function that maps input sequences to output probability distributions on the next token.
Most of the danger comes from evaluating a model on particular inputs (usually multiple times using autoregressive sampling) and hooking up those outputs to actuators in the real world (e.g. access to the internet or human eyes).
A sufficiently capable model might be dangerous if evaluated on almost any input, even in very restrictive environments, e.g. during training when no human is even looking at the o...
Related to We don’t trade with ants: we don't trade with AI.
The original post was about reasons why smarter-than-human AI might (not) trade with us, by examining an analogy between humans and ants.
But current AI systems actually seem more like the ants (or other animals), in the analogy of a human-ant (non-)trading relationship.
People trade with OpenAI for access to ChatGPT, but there's no way to pay a GPT itself to get it do something or perform better as a condition of payment, at least in a way that the model itself actually understands and enforces. (W...
Also seems pretty significant:
As a part of this transition, Greg Brockman will be stepping down as chairman of the board and will remain in his role at the company, reporting to the CEO.
The remaining board members are:
OpenAI chief scientist Ilya Sutskever, independent directors Quora CEO Adam D’Angelo, technology entrepreneur Tasha McCauley, and Georgetown Center for Security and Emerging Technology’s Helen Toner.
Has anyone collected their public statements on various AI x-risk topics anywhere?
Adam D'Angelo via X:
Oct 25
This should help access to AI diffuse throughout the world more quickly, and help those smaller researchers generate the large amounts of revenue that are needed to train bigger models and further fund their research.
Oct 25
We are especially excited about enabling a new class of smaller AI research groups or companies to reach a large audience, those who have unique talent or technology but don’t have the resources to build and market a consumer application to mainstream consumers.
Sep 17
This is a pretty good articulation of the uni...
Has anyone collected their public statements on various AI x-risk topics anywhere?
A bit, not shareable.
Helen is an AI safety person. Tasha is on the Effective Ventures board. Ilya leads superalignment. Adam signed the CAIS statement.
I couldn't remember where from, but I know that Ilya Sutskever at least takes x-risk seriously. I remember him recently going public about how failing alignment would essentially mean doom. I think it was published as an article on a news site rather than an interview, which are what he usually does. Someone with a way better memory than me could find it.
But as a test, may I ask what you think the x-axis of the graph you drew is? Ie: what are the amplitudes attached to?
Position, but it's not meant to be an actual graph of a wavefunction pdf; just a way to depict how the concepts can be sliced up in a way I can actually draw in 2 dimensions.
If you do treat it as a pdf over position, a more accurate way to depict the "world" concept might be as a line which connects points on the diagram for each time step. So for a fixed time step, a world is a single point on the diagram, representing a sample from the pdf defined by the wavefunction at that time.
Here's a crude Google Drawing of t = 0 to illustrate what I mean:
Both the concept of a photon and the concept of a world are abstractions on top of what is ultimately just a big pile of complex amplitudes; illusory in some sense.
I agree that talking in terms of many worlds ("within the context of world A...") is normal and natural. But sometimes it makes sense to refer to and name concepts which span across multiple (conceptual) worlds.
I'm not claiming the conceptual boundaries I've drawn or terminology I've used in the diagram above are standa...
I don't think that will happen as a foregone conclusion, but if we pour resources into improved methods of education (for children and adults), global health, pronatalist policies in wealthy countries, and genetic engineering, it might at least make a difference. I wouldn't necessarily say any of this is likely to work or even happen, but it seems at least worth a shot.
This post received a lot of objections of the flavor that many of the ideas and technologies I am a fan of either wont't work or wouldn't make a difference if they did.
I don't even really disagree with most of these objections, which I tried to make clear up front with apparently-insufficient disclaimers in the intro that include words like "unrealistic", "extremely unlikely", and "speculative".
Following the intro, I deliberately set aside my natural inclination towards pessimism and focused on the positive aspects and possibilities of non-AGI technology.
H...
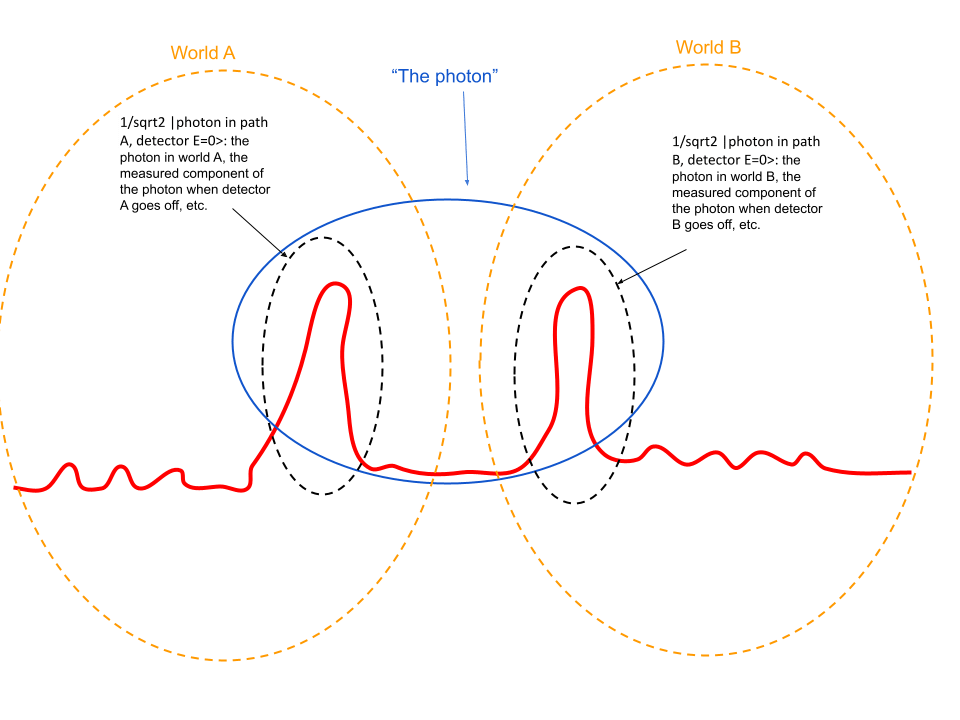
If the photon were only a quanta of energy which is entirely absorbed by the detector that actually fires, how could it have any causal effects (e.g. destructive interference) on the pathway where it isn't detected?
OTOH, if your definition of "quanta of energy" includes the complex amplitude in the unmeasured path, then I think it's more accurate to say that the detector finds or measures a component of the photon, rather than that it detects the photon itself. Why should the unmeasured component be any less real or less part of the photon than the measure...
I'm a many-worlder, yes. But my objection to "finding a photon" is actually that it is an insufficiently reductive treatment of wave-particle duality - a photon can sometimes behave like a little billiard ball, and sometimes like a wave. But that doesn't mean photons themselves are sometimes waves and sometimes particles - the only thing that a photon can be that exhibits those different behaviors in different contexts is the complex amplitudes themselves.
...The whole point of the theory is that detectors and humans are treated the same way. In one world, t
I'm not updating about what's actually likely to happen on Earth based on dath ilan.
It seems uncontroversially true that a world where the median IQ was 140 or whatever would look radically different (and better) than the world we currently live in. We do not in fact, live in such a world.
But taking a hypothetical premise and then extrapolating what else would be different if the premise were true, is a generally useful tool for building understanding and pumping on intuitions in philosophy, mathematics, science, and forecasting.
If you say "but the premise is false!!111!" you're missing the point.
What you should have said, therefore, is "Dath ilan is fiction; it's debatable whether the premises of the world would actually result in the happy conclusion depicted. However, I think it's probably directionally correct -- it does seem to me that if Eliezer was the median, the world would be dramatically better overall, in roughly the ways depicted in the story."
I mildly object to the phrase "it will find a photon". In my own terms, I would say that you will observe the detector going off 50% of the time (with no need to clarify what that means in terms of the limit of a large # of experiments), but the photon itself is the complex amplitudes of each configuration state, which are the same every time you run the experiment.
Note that I myself am taking a pretty strong stance on the ontology question, which you might object to or be uncertain about.
My larger point is that if you (or other readers of this post) don't...
We never see these amplitudes directly, we infer them from the fact that they give correct probabilities via the Born rule. Or more specifically, this is the formula that works. That this formula works is an empirical fact, all the interpretations and debate are a question of why this formula works.
Sure, but inferring underlying facts and models from observations is how inference in general works; it's not specific to quantum mechanics. Probability is in the Mind, even when those probabilities come from applying the Born rule.
Analogously, you could t...
Climate change is exactly the kind of problem that a functional civilization should be able to solve on its own, without AGI as a crutch.
Until a few years ago, we were doing a bunch of geoengineering by accident, and the technology required to stop emitting a bunch of greenhouse gases in the first place (nuclear power) has been mature for decades.
I guess you could have an AGI help with lobbying or public persuasion / education. But that seems like a very "everything looks like a nail" approach to problem solving, before you even have the supposed tool (AGI) to actually use.
Ah, you're right that that the surrounding text is not an accurate paraphrase of the particular position in that quote.
The thing I was actually trying to show with the quotes is "AGI is necessary for a good future" is a common view, but the implicit and explicit time limits that are often attached to such views might be overly short. I think such views (with attached short time limits) are especially common among those who oppose an AI pause.
I actually agree that AGI is necessary (though not sufficient) for a good future eventually. If I also believed that...
Indeed, when you add an intelligent designer with the ability to precisely and globally edit genes, you've stepped outside the design space available to natural selection, and you can end up with some pretty weird results! I think you could also use gene drives to get an IGF-boosting gene to fixation much faster than would occur naturally.
I don't think gene drives are the kind of thing that would ever occur via iterative mutation, but you can certainly have genetic material with very high short-term IGF that eventually kills its host organism or causes extinction of its host species.
Some people will end up valuing children more, for complicated reasons; other people will end up valuing other things more, again for complicated reasons.
Right, because somewhere pretty early in evolutionary history, people (or animals) which valued stuff other than having children for complicated reasons eventually had more descendants than those who didn't. Probably because wanting lots of stuff for complicated reasons (and getting it) is correlated with being smart and generally capable, which led to having more descendants in the long run.
If evolution ...
I kind of doubt that leaders at big labs would self-identify as being motivated by anything like Eliezer's notion of heroic responsibility. If any do self-identify that way though, they're either doing it wrong or misunderstanding. Eliezer has written tons of stuff about the need to respect deontology and also think about all of the actual consequences of your actions, even (especially when) the stakes are high:
... (read more)