Diego Caples (diego@activated-ai.com)
Rob Neuhaus (rob@activated-ai.com)
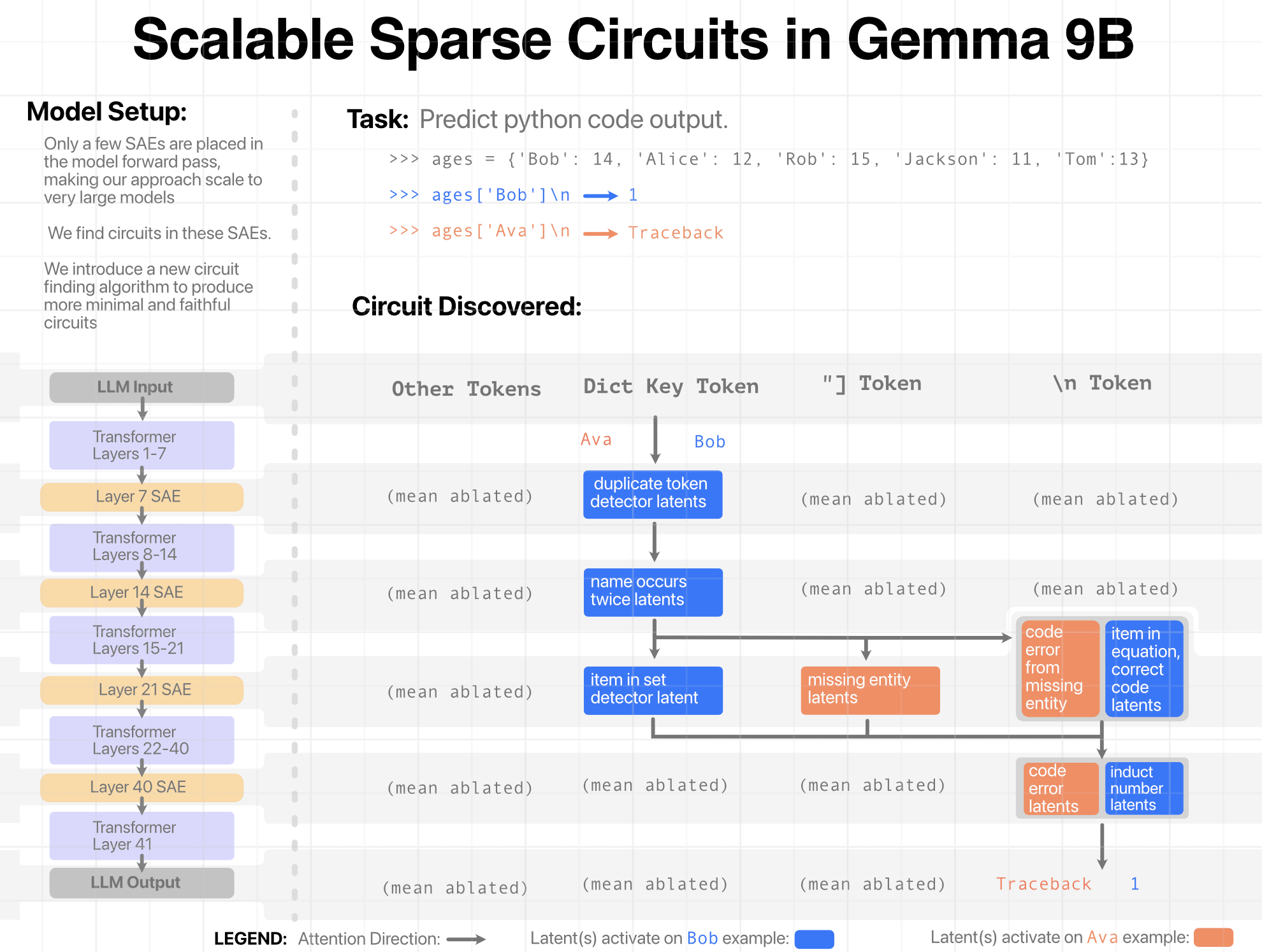
Introduction
In principle, neuron activations in a transformer-based language model residual stream should be about the same scale. In practice, the dimensions unexpectedly widely vary in scale. Mathematical theories of the transformer architecture do not predict this. They expect no dimension to be more important than any other. Is there something wrong with our reasonably informed intuitions of how transformers work? What explains these outlier channels?
Previously, Anthropic researched the existence of these privileged basis dimensions (dimensions more important / larger than expected) and ruled out several causes. By elimination, they reached the hypothesis that per-channel normalization in the Adam optimizer was the cause of privileged basis. However, they did... (read 953 more words →)
What if interpretability is a spectrum?
Instead of one massive model, imagine at inference time, you generate a small, query specific model by carving out a small subset of the big model.
Interp on this smaller model for a given query has to be better than on the oom bigger model.
Inference gets substantially faster if you can cluster/batch similar queries together, so you can actually get financial support if this works at the frontier.
The core insight? Gradients smear knowledge everywhere. Tag training data with an ontology learned from the query stream of a frontier model. We can automate the work of millions of librarians to classify our training data. Only let the base model + tagged components be active for a given training example. Sgd can't smear the gradient across inactive components. Knowledge will be roughly partitioned. When you do a forward pass you generate some python code, you don't pay for dot products that know that Jackson is an entirely ignorable town in New Jersey.