LLMs Universally Learn a Feature Representing Token Frequency / Rarity
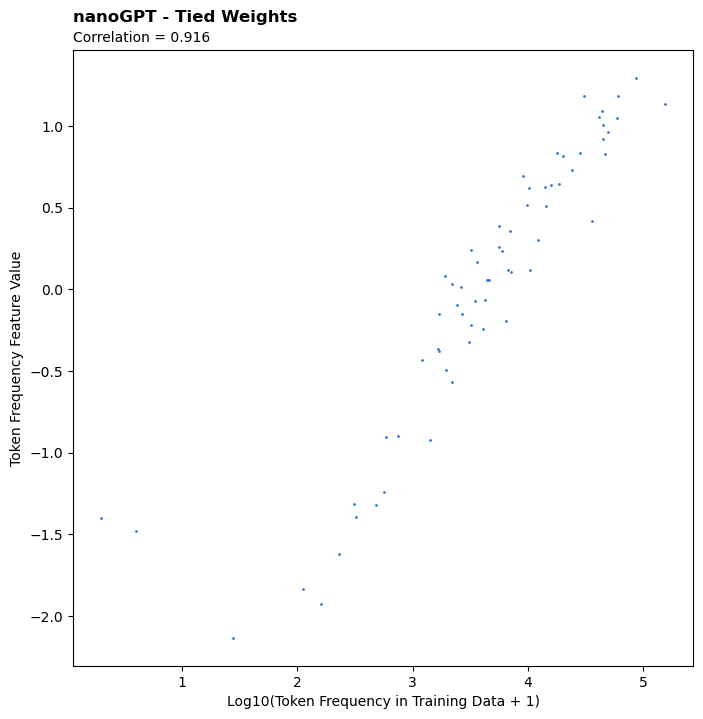
Summary * LLMs appear to universally learn a feature in their embeddings representing the frequency / rarity of the tokens they were trained on * This feature is observed across model sizes, in base models, instruction tuned models, regular text models, and code models * In models without tied weights,...
Jun 30, 202413
Very true. If a token truly never appears in the training data, it wouldn't be trained / learned at all. Or similarly, if it's only seen like once or twice it ends up "undertrained" and the token frequency feature doesn't perform as well on it. The two least frequent tokens in the nanoGPT model are an excellent example of this. They appear like only once or twice and as a result don't get properly learned, and as a result end up being big outliers.