Tokenized SAEs: Infusing per-token biases.
tl;dr * We introduce the notion of adding a per-token decoder bias to SAEs. Put differently, we add a lookup table indexed by the last seen token. This results in a Pareto improvement across existing architectures (TopK and ReLU) and models (on GPT-2 small and Pythia 1.4B). Attaining the same...
Aug 4, 202420
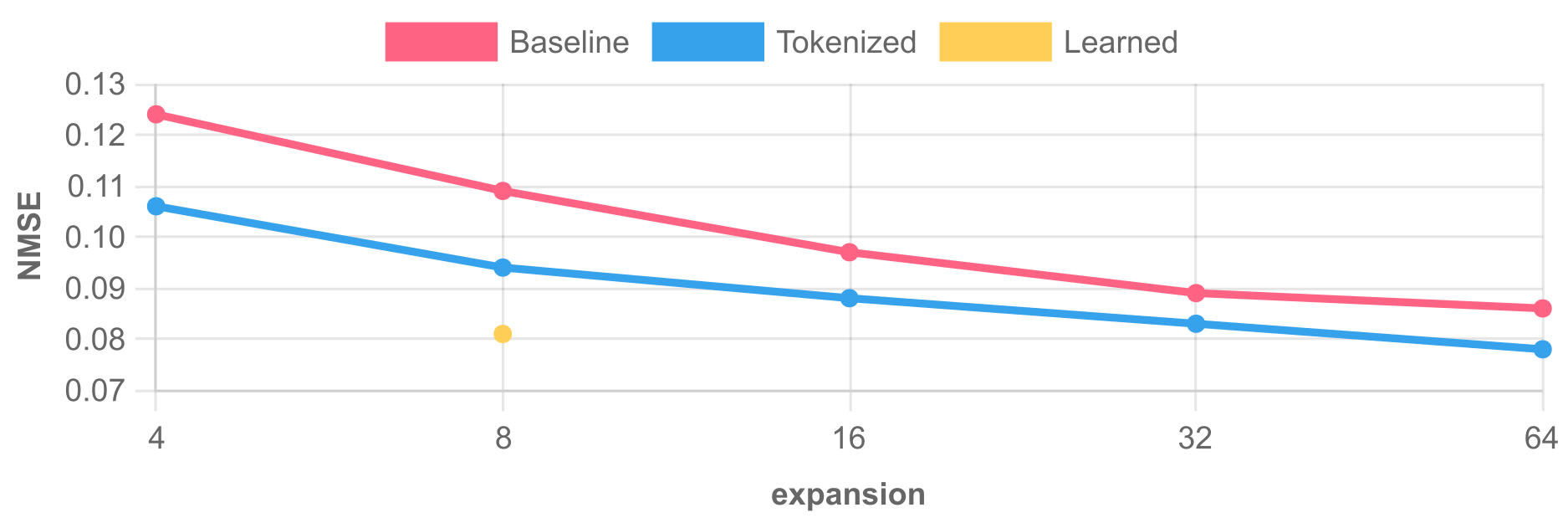
We haven't considered this since our idea was that the encoder could maybe use the full information to better predict features. However, this seems worthwhile to at least try. I'll look into this soon, thanks for the inspiration.