All of Zach Stein-Perlman's Comments + Replies
Topic: workplace world-modeling
- A friend's manager tasked them with estimating ~10 parameters for a model. Choosing a single parameter very-incorrectly would presumably make the bottom line nonsense. My friend largely didn't understand the model and what the parameters meant; if you'd asked them "can you confidently determine what each of the parameters means" presumably they would have noticed the answer was no. (If I understand the situation correctly, it was crazy for the manager to expect my friend to do this task.) They should have told their manager "
My quick thoughts on why this happens.
(1) Time. You get asked to do something. You dont get the full info dump in the meeting so you say yes and go off hopeful that you can find the stuff you need. Other responsibilies mean you dont get around to looking everything up until time has passed. It is at that stage that you realise the hiring process hasnt even been finalised or that even one wrong parameter out of 10 confusing parameters would be bad. But now its mildly awkard to go back and explain this - they gave this to you on Thursday, its now Monday.
(2) ...
Update: they want "to build virtual work environments for automating software engineering—and then the rest of the economy." Software engineering seems like one of the few things I really think shouldn't accelerate :(.
What, no, Oli says OP would do a fine job and make grants in rationality community-building, AI welfare, right-wing policy stuff, invertebrate welfare, etc. but it's constrained by GV.
[Disagreeing since this is currently the top comment and people might read it rather than listen to the podcast.]
I don't currently believe this, and don't think I said so. I do think the GV constraints are big, but also my overall assessment of the net-effect of Open Phil actions is net bad, even if you control for GV, though the calculus gets a lot messier and I am much less confident. Some of that is because of the evidential update from how they handled the GV situation, but also IMO Open Phil has made many other quite grievous mistakes.
My guess is an Open Phil that was continued to be run by Holden would probably be good for the world. I have many disagreements w...
I agree people often aren't careful about this.
Anthropic says
During our evaluations we noticed that Claude 3.7 Sonnet occasionally resorts to special-casing in order to pass test cases in agentic coding environments . . . . This undesirable special-casing behavior emerged as a result of "reward hacking" during reinforcement learning training.
Similarly OpenAI suggests that cheating behavior is due to RL.
Rant on "deceiving" AIs
tl;dr: Keep your promises to AIs; it's fine to do stuff like teaching them false facts or misleading them about their situation during testing and deployment; but if you wanna do cheap stuff to cause them to know that they might [have been taught false facts / be being tested / be being misled during deployment], sure, go for it.
Disclaimer: maybe more like explaining my position than justifying my position.
Sometimes we really want to deceive AIs (or at least make them uncertain about their situation). E.g.:
- Training them to beli
A crucial step is bouncing off the bumpers.
...If we encounter a warning sign that represents reasonably clear evidence that some common practice will lead to danger, the next step is to try to infer the proximate cause. These efforts need not result in a comprehensive theory of all of the misalignment risk factors that arose in the training run, but it should give us some signal about what sort of response would treat the cause of the misalignment rather than simply masking the first symptoms.
This could look like reading RL logs, looking through tr
normalizing [libel suits] would cause much more harm than RationalWiki ever caused . . . . I do think it's pretty bad and [this action] overall likely still made the world worse.
Is that your true rejection? (I'm surprised if you think the normalizing-libel-suits effect is nontrivial.)
Everyone knew everyone knew everyone knew everyone knew someone had blue eyes. But everyone didn't know that—so there wasn't common knowledge—until the sailor made it so.
I think the conclusion is not Epoch shouldn't have hired Matthew, Tamay, and Ege but rather [Epoch / its director] should have better avoided negative-EV projects (e.g. computer use evals) (and shouldn't have given Tamay leadership-y power such that he could cause Epoch to do negative-EV projects — idk if that's what happened but seems likely).
Good point. You're right [edit: about Epoch].
I should have said: the vibe I've gotten from Epoch and Matthew/Tamay/Ege in private in the last year is not safety-focused. (Not that I really know all of them.)
(ha ha but Epoch and Matthew/Tamay/Ege were never really safety-focused, and certainly not bright-eyed standard-view-holding EAs, I think)
Epoch has definitely described itself as safety focused to me and others. And I don't know man, this back and forth to me sure sounds like they were branding themselves as being safety conscious:
...Ofer: Can you describe your meta process for deciding what analyses to work on and how to communicate them? Analyses about the future development of transformative AI can be extremely beneficial (including via publishing them and getting many people more informed). But getting many people more hyped about scaling up ML models, for example, can also be counterproduc
Accelerating AI R&D automation would be bad. But they want to accelerate misc labor automation. The sign of this is unclear to me.
Their main effect will be to accelerate AI R&D automation, as best I can tell.
My guess would be that making RL envs for broad automation of the economy is bad[1] and making benchmarks which measure how good AIs are at automating jobs is somewhat good[2].
Regardless, IMO this seems worse for the world than other activities Matthew, Tamay, and Ege might do.
I'd guess the skills will transfer to AI R&D etc insofar as the environments are good. I'm sign uncertain about broad automation which doesn't transfer (which would be somewhat confusing/surprising) as this would come down to increased awareness earlier vs speeding up AI deve
I think this stuff is mostly a red herring: the safety standards in OpenAI's new PF are super vague and so it will presumably always be able to say it meets them and will never have to use this.[1]
But if this ever matters, I think it's good: it means OpenAI is more likely to make such a public statement and is slightly less incentivized to deceive employees + external observers about capabilities and safeguard adequacy. OpenAI unilaterally pausing is not on the table; if safeguards are inadequate, I'd rather OpenAI say so.
- ^
I think my main PF complaints are
Unrelated to vagueness they can also just change the framework again at any time.
I don't know. I don't have a good explanation for why OpenAI hasn't released o3. Delaying to do lots of risk assessment would be confusing because they did little risk assessment for other models.
OpenAI slashes AI model safety testing time, FT reports. This is consistent with lots of past evidence about OpenAI's evals for dangerous capabilities being rushed, being done on weak checkpoints, and having worse elicitation than OpenAI has committed to.
This is bad because OpenAI is breaking its commitments (and isn't taking safety stuff seriously and is being deceptive about its practices). It's also kinda bad in terms of misuse risk, since OpenAI might fail to notice that its models have dangerous capabilities. I'm not saying OpenAI should delay deploym...
I think this isn't taking powerful AI seriously. I think the quotes below are quite unreasonable, and only ~half of the research agenda is plausibly important given that there will be superintelligence. So I'm pessimistic about this agenda/project relative to, say, the Forethought agenda.
...AGI could lead to massive labor displacement, as studies estimate that between 30% - 47% of jobs could be directly replaceable by AI systems. . . .
AGI could lead to stagnating or falling wages for the majority of workers if AI technology replaces people faster than i
My guess:
This is about software tasks, or specifically "well-defined, low-context, measurable software tasks that can be done without a GUI." It doesn't directly generalize to solving puzzles or writing important papers. It probably does generalize within that narrow category.
If this was trying to measure all tasks, tasks that AIs can't do would count toward the failure rate; the main graph is about 50% success rate, not 100%. If we were worried that this is misleading because AIs are differentially bad at crucial tasks or something, we could look at success rate on those tasks specifically.
I don't know, maybe nothing. (I just meant that on current margins, maybe the quality of the safety team's plans isn't super important.)
I haven't read most of the paper, but based on the Extended Abstract I'm quite happy about both the content and how DeepMind (or at least its safety team) is articulating an "anytime" (i.e., possible to implement quickly) plan for addressing misuse and misalignment risks.
But I think safety at Google DeepMind is more bottlenecked by buy-in from leadership to do moderately costly things than the safety team having good plans and doing good work. [Edit: I think the same about Anthropic.]
I expect they will thus not want to use my quotes
Yep, my impression is that it violates the journalist code to negotiate with sources for better access if you write specific things about them.
My strong upvotes are giving +61 :shrug:
Minor Anthropic RSP update.
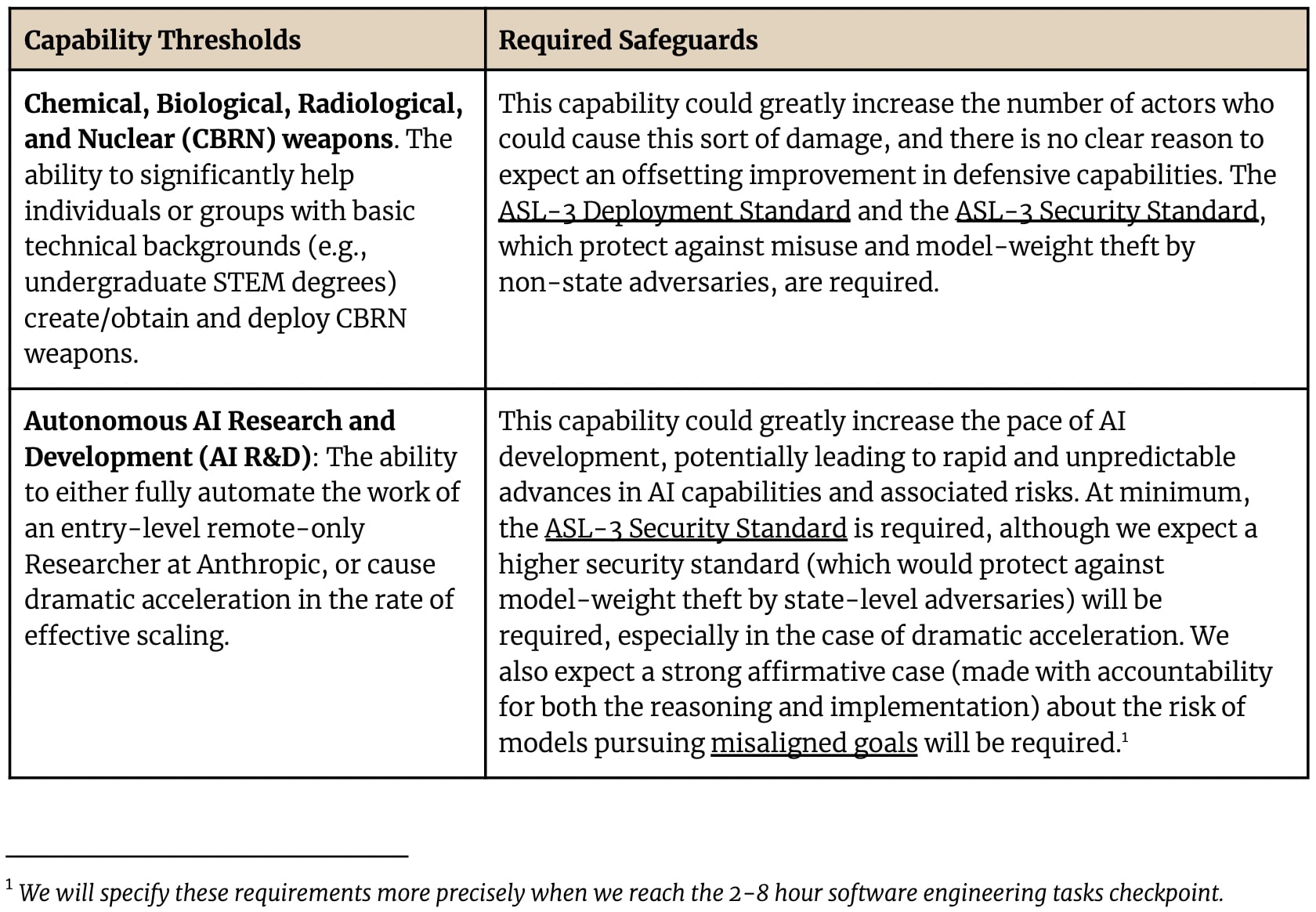
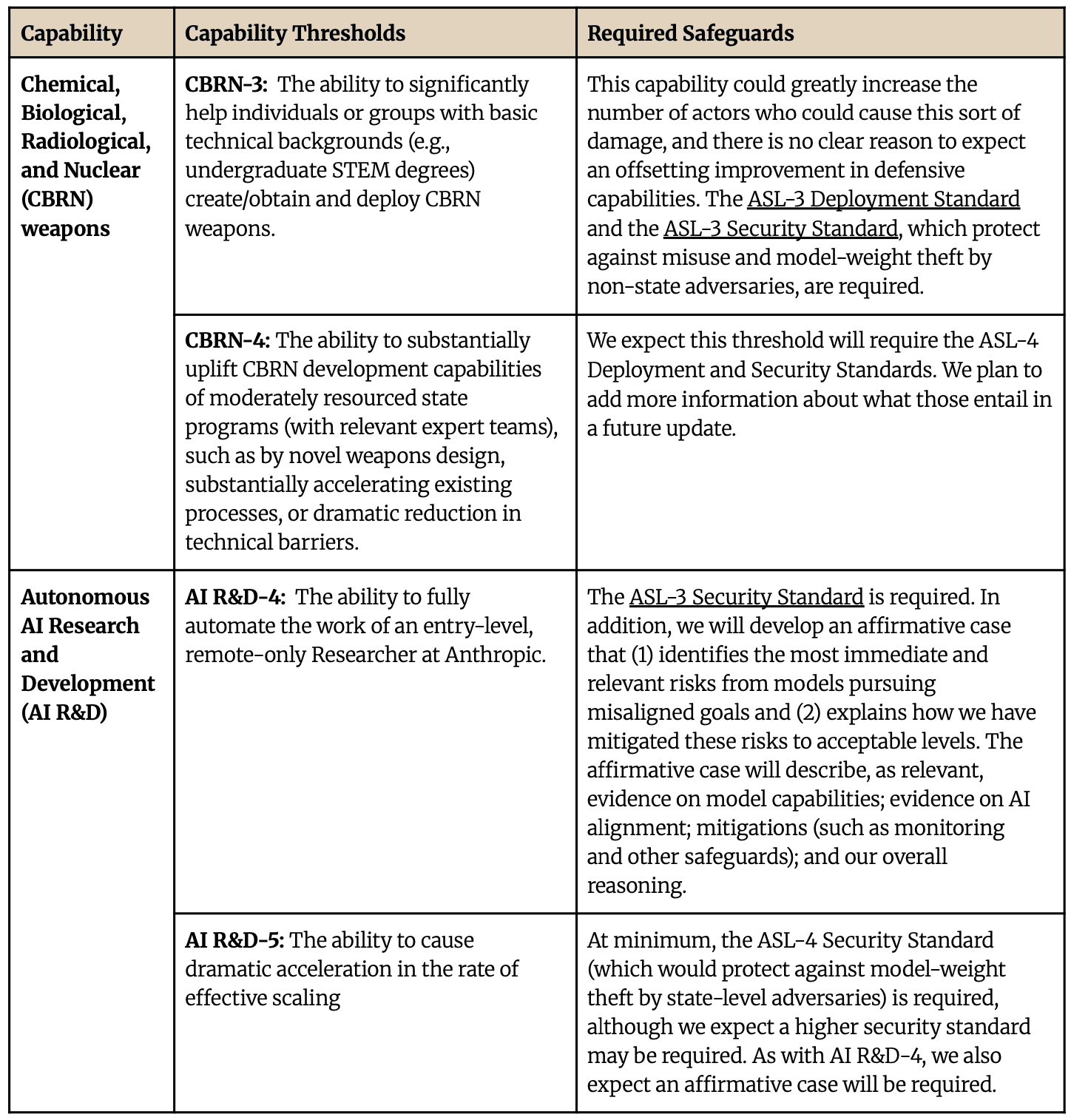
I don't know what e.g. the "4" in "AI R&D-4" means; perhaps it is a mistake.[1]
Sad that the commitment to specify the AI R&D safety case thing was removed, and sad that "accountability" was removed.
Slightly sad that AI R&D capabilities triggering >ASL-3 security went from "especially in the case of dramatic acceleration" to only in that case.
Full AI R&D-5 description from appendix:
...AI R&D-5: The ability to cause dramatic acceleration in the rate of effective scaling. Specifically, this would be
A. Many AI safety people don't support relatively responsible companies unilaterally pausing, which PauseAI advocates. (Many do support governments slowing AI progress, or preparing to do so at a critical point in the future. And many of those don't see that as tractable for them to work on.)
B. "Pausing AI" is indeed more popular than PauseAI, but it's not clearly possible to make a more popular version of PauseAI that actually does anything; any such organization will have strategy/priorities/asks/comms that alienate many of the people who think "yeah I s...
It is often said that control is for safely getting useful work out of early powerful AI, not making arbitrarily powerful AI safe.
If it turns out large, rapid, local capabilities increase is possible, the leading developer could still opt to spend some inference compute on safety research rather than all on capabilities research.
lc has argued that the measured tasks are unintentionally biased towards ones where long-term memory/context length doesn't matter:
https://www.lesswrong.com/posts/hhbibJGt2aQqKJLb7/shortform-1#vFq87Ge27gashgwy9
I think doing 1-week or 1-month tasks reliably would suffice to mostly automate lots of work.
Good point, thanks. I think eventually we should focus more on reducing P(doom | sneaky scheming) but for now focusing on detection seems good.
Wow. Very surprising.
xAI Risk Management Framework (Draft)
You're mostly right about evals/thresholds. Mea culpa. Sorry for my sloppiness.
For misuse, xAI has benchmarks and thresholds—or rather examples of benchmarks thresholds to appear in the real future framework—and based on the right column they seem very reasonably low.

Unlike other similar documents, these are not thresholds at which to implement mitigations but rather thresholds to reduce performance to. So it seems the primary concern is probably not the thresholds are too high but rather xAI's mitigations won't be robu...
This shortform discusses the current state of responsible scaling policies (RSPs). They're mostly toothless, unfortunately.
The Paris summit was this week. Many companies had committed to make something like an RSP by the summit. Half of them did, including Microsoft, Meta, xAI, and Amazon. (NVIDIA did not—shame on them—but I hear they are writing something.) Unfortunately but unsurprisingly, these policies are all vague and weak.
RSPs essentially have four components: capability thresholds beyond which a model might b...
capability thresholds be vague or extremely high
xAI's thresholds are entirely concrete and not extremely high.
evaluation be unspecified or low-quality
They are specified and as high-quality as you can get. (If there are better datasets let me know.)
I'm not saying it's perfect, but I wouldn't but them all in the same bucket. Meta's is very different from DeepMind's or xAI's.
There also used to be a page for Preparedness: https://web.archive.org/web/20240603125126/https://openai.com/preparedness/. Now it redirects to the safety page above.
(Same for Superalignment but that's less interesting: https://web.archive.org/web/20240602012439/https://openai.com/superalignment/.)
DeepMind updated its Frontier Safety Framework (blogpost, framework, original framework). It associates "recommended security levels" to capability levels, but the security levels are low. It mentions deceptive alignment and control (both control evals as a safety case and monitoring as a mitigation); that's nice. The overall structure is like we'll do evals and make a safety case, with some capabilities mapped to recommended security levels in advance. It's not very commitment-y:
We intend to evaluate our most powerful frontier models regularly
...
My guess is it's referring to Anthropic's position on SB 1047, or Dario's and Jack Clark's statements that it's too early for strong regulation, or how Anthropic's policy recommendations often exclude RSP-y stuff (and when they do suggest requiring RSPs, they would leave the details up to the company).
o3-mini is out (blogpost, tweet). Performance isn't super noteworthy (on first glance), in part since we already knew about o3 performance.
Non-fact-checked quick takes on the system card:
the model referred to below as the o3-mini post-mitigation model was the final model checkpoint as of Jan 31, 2025 (unless otherwise specified)
Big if true (and if Preparedness had time to do elicitation and fix spurious failures)
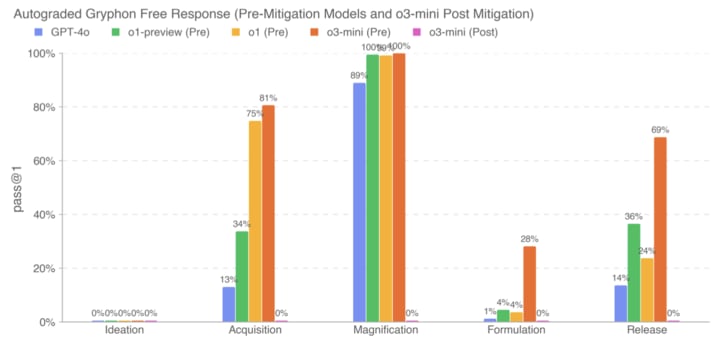
If this is robust to jailbreaks, great, but presumably it's not, so low post-mitigation performance is far from sufficient for safety-from-misuse;...
Thanks. The tax treatment is terrible. And I would like more clarity on how transformative AI would affect S&P 500 prices (per this comment). But this seems decent (alongside AI-related calls) because 6 years is so long.
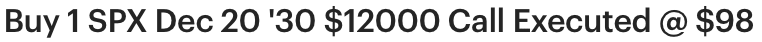
I wrote this for someone but maybe it's helpful for others
What labs should do:
- I think the most important things for a relatively responsible company are control and security. (For irresponsible companies, I roughly want them to make a great RSP and thus become a responsible company.)
- Reading recommendations for people like you (not a control expert but has context to mostly understand the Greenblatt plan):
- Control: Redwood blogposts[1] or ask a Redwood human "what's the threat model" and "what are the most promising control techniques"
- Security: not
I think ideally we'd have several versions of a model. The default version would be ignorant about AI risk, AI safety and evaluation techniques, and maybe modern LLMs (in addition to misuse-y dangerous capabilities). When you need a model that's knowledgeable about that stuff, you use the knowledgeable version.
Somewhat related: https://www.alignmentforum.org/posts/KENtuXySHJgxsH2Qk/managing-catastrophic-misuse-without-robust-ais
Yeah, I agree with this and am a fan of this from the google doc:
Remove biology, technical stuff related to chemical weapons, technical stuff related to nuclear weapons, alignment and AI takeover content (including sci-fi), alignment or AI takeover evaluation content, large blocks of LM generated text, any discussion of LLMs more powerful than GPT2 or AI labs working on LLMs, hacking, ML, and coding from the training set.
and then fine-tune if you need AIs with specific info. There are definitely issues here with AIs doing safety research (e.g., to solve risks from deceptive alignment they need to know what that is), but this at least buys some marginal safety.
[Perfunctory review to get this post to the final phase]
Solid post. Still good. I think a responsible developer shouldn't unilaterally pause but I think it should talk about the crazy situation it's in, costs and benefits of various actions, what it would do in different worlds, and its views on risks. (And none of the labs have done this; in particular Core Views is not this.)
One more consideration against (or an important part of "Bureaucracy"): sometimes your lab doesn't let you publish your research.
Some people have posted ideas on what a reasonable plan to reduce AI risk for such timelines might look like (e.g. Sam Bowman’s checklist, or Holden Karnofsky’s list in his 2022 nearcast), but I find them insufficient for the magnitude of the stakes (to be clear, I don’t think these example lists were intended to be an extensive plan).
See also A Plan for Technical AI Safety with Current Science (Greenblatt 2023) for a detailed (but rough, out-of-date, and very high-context) plan.
Yeah. I agree/concede that you can explain why you can't convince people that their own work is useless. But if you're positing that the flinchers flinch away from valid arguments about each category of useless work, that seems surprising.
The flinches aren't structureless particulars. Rather, they involve warping various perceptions. Those warped perceptions generalize a lot, causing other flaws to be hidden.
As a toy example, you could imagine someone attached to the idea of AI boxing. At first they say it's impossible to break out / trick you / know about the world / whatever. Then you convince them otherwise--that the AI can do RSI internally, and superhumanly solve computer hacking / protein folding / persuasion / etc. But they are attached to AI boxing. So they warp their perception, cl...
I feel like John's view entails that he would be able to convince my friends that various-research-agendas-my-friends-like are doomed. (And I'm pretty sure that's false.) I assume John doesn't believe that, and I wonder why he doesn't think his view entails it.
I wonder whether John believes that well-liked research, e.g. Fabien's list, is actually not valuable or rare exceptions coming from a small subset of the "alignment research" field.
I do not.
On the contrary, I think ~all of the "alignment researchers" I know claim to be working on the big problem, and I think ~90% of them are indeed doing work that looks good in terms of the big problem. (Researchers I don't know are likely substantially worse but not a ton.)
In particular I think all of the alignment-orgs-I'm-socially-close-to do work that looks good in terms of the big problem: Redwood, METR, ARC. And I think the other well-known orgs are also good.
This doesn't feel odd: these people are smart and actually care about the big problem;...
Yeah, I agree sometimes people decide to work on problems largely because they're tractable [edit: or because they’re good for safety getting alignment research or other good work out of early AGIs]. I'm unconvinced of the flinching away or dishonest characterization.
(Clarification: these are EA, AI safety orgs with ~10-15 employees.)