Seeking Power is Often Robustly Instrumental in MDPs relates the structure of the agent's environment (the 'Markov decision process (MDP) model') to the tendencies of optimal policies for different reward functions in that environment ('instrumental convergence'). The results tell us what optimal decision-making 'tends to look like' in a given environment structure, formalizing reasoning that says e.g. that most agents stay alive because that helps them achieve their goals.
Several people have claimed to me that these results need subjective modelling decisions. For example, ofer wrote:
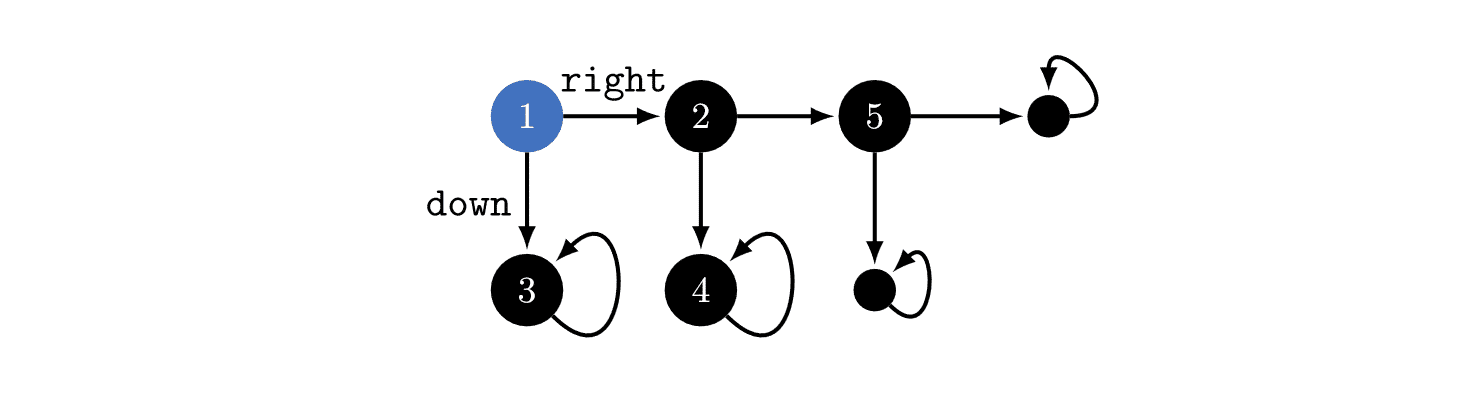
I think using a well-chosen reward distribution is necessary, otherwise POWER depends on arbitrary choices in the design of the MDP's state graph. E.g. suppose the student [in a different example] writes about every action they take in a blog that no one reads, and we choose to include the content of the blog as part of the MDP state. This arbitrary choice effectively unrolls the state graph into a tree with a constant branching factor (+ self-loops in the terminal states) and we get that the POWER of all the states is equal.
In the above example, you could think about the environment as in the above image, or you could imagine that state '3' is actually a million different states which just happen to seem similar to us! If that were true, then optimal policies would tend to go , since that would give the agent millions of choices about where it ends up. Therefore, the power-seeking theorems depend on subjective modelling assumptions.
I used to think this, but this is wrong. The MDP model is determined by the agent's implementation + the task's dynamics.
To make this point, let's back out to a more familiar MDP: Pac-Man.
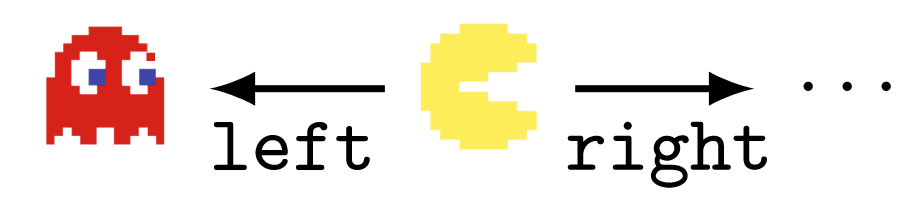
When the discount rate is near 1, most reward functions avoid immediately dying to the ghost, because then they'd be stuck in a terminal state (the red-ghost-game-over state). But why can't the red ghost be equally well-modeled as secretly being 5 googolplex different terminal states?
An MDP model (technically, a rewardless MDP) is a tuple , where is the state space, is the action space, and is the (potentially stochastic) transition function which says what happens when the agent takes different actions at different states. has to be Markovian, depending only on the observed state and the current action, and not on prior history.
Whence cometh this MDP model? Thin air? Is it just a figment of our imagination, which we use to understand what the agent is doing as it learns a policy?
When we train a policy function in the real world, the function takes in an observation (the state) and outputs (a distribution over) actions. When we define state and action encodings, this implicitly defines an "interface" between the agent and the environment. The state encoding might look like "the set of camera observations" or "the set of Pac-Man game screens", and actions might be numbers 1-10 which are sent to actuators, or to the computer running the Pac-Man code, etc.
(In the real world, the computer simulating Pac-Man may suffer a hardware failure / be hit by a gamma ray / etc, but I don't currently think these are worth modelling over the timescales over which we train policies.)
Suppose that for every state-action history, what the agent sees next depends only on the currently observed state and the most recent action taken. Then the environment is Markovian (transition dynamics only depend on what you do right now, not what you did in the past) and fully observable (you can see the whole state all at once), and the agent encodings have defined the MDP model.
In Pac-Man, the MDP model is uniquely defined by how we encode states and actions, and the part of the real world which our agent interfaces with. If you say "maybe the red ghost is represented by 5 googolplex states", then that's a falsifiable claim about the kind of encoding we're using.
That's also a claim that we can, in theory, specify reward functions which distinguish between 5 googolplex variants of red-ghost-game-over. If that were true, then yes - optimal policies really would tend to "die" immediately, since they'd have so many choices.
The "5 googolplex" claim is both falsifiable and false. Given an agent architecture (specifically, the two encodings), optimal policy tendencies are not subjective. We may be uncertain about the agent's state- and action-encodings, but that doesn't mean we can imagine whatever we want.
(I think that the same point holds for other environment types, like POMDPs.)



I was talking about a particular example, with a particular reward function that I had in mind. We seemed to disagree about whether instrumental convergence arguments apply there, and my purpose in that comment was to argue that they do. I'm not trying to define here the set of reward functions over which instrumental convergence argument apply (they obviously don't apply to all reward functions, as for every possible policy you can design a reward function for which that policy is optimal).
E.g. humans noticing that something weird is going on and trying to shut down the process. (Shutting down the process doesn't mean that new strings won't appear in the environment and cause the state graph to become a tree-with-constant-branching-factor due to complex physical dynamics.)
Not in the example I have in mind. Again, let's say the state representation determines the location of every atom in that earth-like environment. (I think that's the key miscommunication here; the MDP I'm thinking about is NOT a "sequential string output MDP", if I understand your use of that phrase correctly. [EDIT: my understanding is that you use that phrase to describe an MDP in which a state is just the sequence of strings in the exchange so far.] [EDIT 2: I think this miscommunication is my fault, due to me writing in my first comment: "the state representation may be uniquely determined by all the text that was written so far by both the customer and the chatbot", sorry for that.])
I agree the statement would be true with any possible string; this doesn't change the point I'm making with it. (Consider this to be an application of the more general statement with a particular string.)
For every subset of branches in the tree you can design a reward function for which every optimal policy tries to go down those branches; I'm not saying anything about "most rewards functions". I would focus on statements that apply to "most reward functions" if we dealt with an AI that had a reward function that was sampled uniformly from all possible rewards function. But that scenario does not seem relevant (in particular, something like Occam's razor seems relevant: our prior credence should be larger for reward functions with shorter shortest-description).
The non-formal definition in Bostrom's Superintelligence (which does not specify a set of rewards functions but rather says "a wide range of final goals and a wide range of situations, implying that these instrumental values are likely to be pursued by a broad spectrum of situated intelligent agents.").