The following is a lightly edited version of a memo I wrote for a retreat. It was inspired by a draft of Counting arguments provide no evidence for AI doom. I think that my post covers important points not made by the published version of that post.
I'm also thankful for the dozens of interesting conversations and comments at the retreat.
I think that the AI alignment field is partially founded on fundamentally confused ideas. I’m worried about this because, right now, a range of lobbyists and concerned activists and researchers are in Washington making policy asks. Some of these policy proposals seem to be based on erroneous or unsound arguments.[1]
The most important takeaway from this essay is that the (prominent) counting arguments for “deceptively aligned” or “scheming” AI provide ~0 evidence that pretraining + RLHF will eventually become intrinsically unsafe. That is, that even if we don't train AIs to achieve goals, they will be "deceptively aligned" anyways. This has important policy implications.
Disclaimers:
-
I am not putting forward a positive argument for alignment being easy. I am pointing out the invalidity of existing arguments, and explaining the implications of rolling back those updates.
-
I am not saying "we don't know how deep learning works, so you can't prove it'll be bad." I'm saying "many arguments for deep learning -> doom are weak. I undid those updates and am now more optimistic."
-
I am not covering training setups where we purposefully train an AI to be agentic and autonomous. I just think it's not plausible that we just keep scaling up networks, run pretraining + light RLHF, and then produce a schemer.[2]
Tracing back historical arguments
In the next section, I'll discuss the counting argument. In this one, I want to demonstrate how often foundational alignment texts make crucial errors. Nick Bostrom's Superintelligence, for example:
A range of different methods can be used to solve “reinforcement-learning problems,” but they typically involve creating a system that seeks to maximize a reward signal. This has an inherent tendency to produce the wireheading failure mode when the system becomes more intelligent. Reinforcement learning therefore looks unpromising. (p.253)
To be blunt, this is nonsense. I have long meditated on the nature of "reward functions" during my PhD in RL theory. In the most useful and modern RL approaches, "reward" is a tool used to control the strength of parameter updates to the network.[3] It is simply not true that "[RL approaches] typically involve creating a system that seeks to maximize a reward signal." There is not a single case where we have used RL to train an artificial system which intentionally “seeks to maximize” reward.[4] Bostrom spends a few pages making this mistake at great length.[5]
After making a false claim, Bostrom goes on to dismiss RL approaches to creating useful, intelligent, aligned systems. But, as a point of further fact, RL approaches constitute humanity's current best tools for aligning AI systems today! Those approaches are pretty awesome. No RLHF, then no GPT-4 (as we know it).
In arguably the foundational technical AI alignment text, Bostrom makes a deeply confused and false claim, and then perfectly anti-predicts what alignment techniques are promising.
I'm not trying to rag on Bostrom personally for making this mistake. Foundational texts, ahead of their time, are going to get some things wrong. But that doesn't save us from the subsequent errors which avalanche from this kind of early mistake. These deep errors have costs measured in tens of thousands of researcher-hours. Due to the “RL->reward maximizing” meme, I personally misdirected thousands of hours on proving power-seeking theorems.
Unsurprisingly, if you have a lot of people speculating for years using confused ideas and incorrect assumptions, and they come up with a bunch of speculative problems to work on… If you later try to adapt those confused “problems” to the deep learning era, you’re in for a bad time. Even if you, dear reader, don’t agree with the original people (i.e. MIRI and Bostrom), and even if you aren’t presently working on the same things… The confusion has probably influenced what you’re working on.
I think that’s why some people take “scheming AIs/deceptive alignment” so seriously, even though some of the technical arguments are unfounded.
Many arguments for doom are wrong
Let me start by saying what existential vectors I am worried about:
-
I’m worried about people turning AIs into agentic systems using scaffolding and other tricks, and then instructing the systems to complete large-scale projects.
-
I’m worried about competitive pressure to automate decision-making in the economy.
-
I’m worried about misuse of AI by state actors.
-
I’m worried about centralization of power and wealth in opaque non-human decision-making systems, and those who own the systems.[7]
I maintain that there isn’t good evidence/argumentation for threat models like “future LLMs will autonomously constitute an existential risk, even without being prompted towards a large-scale task.” These models seem somewhat pervasive, and so I will argue against them.
There are a million different arguments for doom. I can’t address them all, but I think most are wrong and am happy to dismantle any particular argument (in person; I do not commit to replying to comments here).
Much of my position is summarized by my review of Yudkowsky’s AGI Ruin: A List of Lethalities:
Reading this post made me more optimistic about alignment and AI. My suspension of disbelief snapped; I realized how vague and bad a lot of these "classic" alignment arguments are, and how many of them are secretly vague analogies and intuitions about evolution.
While I agree with a few points on this list, I think this list is fundamentally misguided. The list is written in a language which assigns short encodings to confused and incorrect ideas. I think a person who tries to deeply internalize this post's worldview will end up more confused about alignment and AI…
I think this piece is not "overconfident", because "overconfident" suggests that Lethalities is simply assigning extreme credences to reasonable questions (like "is deceptive alignment the default?"). Rather, I think both its predictions and questions are not reasonable because they are not located by good evidence or arguments. (Example: I think that deceptive alignment is only supported by flimsy arguments.)
In this essay, I'll address some of the arguments for “deceptive alignment” or “AI scheming.” And then I’m going to bullet-point a few other clusters of mistakes.
The counting argument for AI “scheming” provides ~0 evidence
Nora Belrose and Quintin Pope have an excellent upcoming post which they have given me permission to quote at length. I have lightly edited the following:
Most AI doom scenarios posit that future AIs will engage in scheming— planning to escape, gain power, and pursue ulterior motives while deceiving us into thinking they are aligned with our interests. The worry is that if a schemer escapes, it may seek world domination to ensure humans do not interfere with its plans, whatever they may be.
In this essay, we debunk the counting argument— a primary reason to think AIs might become schemers, according to a recent report by AI safety researcher Joe Carlsmith. It’s premised on the idea that schemers can have “a wide variety of goals,” while the motivations of a non-schemer must be benign or are otherwise more constrained. Since there are “more” possible schemers than non-schemers, the argument goes, we should expect training to produce schemers most of the time. In Carlsmith’s words:
- The non-schemer model classes, here, require fairly specific goals in order to get high reward.
- By contrast, the schemer model class is compatible with a very wide range of (beyond episode) goals, while still getting high reward…
- In this sense, there are “more” schemers that get high reward than there are non-schemers that do so.
- So, other things equal, we should expect SGD to select a schemer. — Scheming AIs, page 17
We begin our critique by presenting a structurally identical counting argument for the obviously false conclusion that neural networks should always memorize their training data, while failing to generalize to unseen data. Since the “generalization is impossible” argument actually has stronger premises than those of the original “schemer” counting argument, this shows that naive counting arguments are generally unsound in this domain.
We then diagnose the problem with both counting arguments: they are counting the wrong things.
The counting argument for extreme overfitting
The inference from “there are ‘more’ models with property X than without X” to “SGD likely produces a model with property X” clearly does not work in general. To see this, consider the structurally identical argument:
- Neural networks must implement fairly specific functions in order to generalize beyond their training data.
- By contrast, networks that overfit to the training set are free to do almost anything on unseen data points.
- In this sense, there are “more” models that overfit than models that generalize.
- So, other things equal, we should expect SGD to select a model that overfits.
This argument isn’t a mere hypothetical. Prior to the rise of deep learning, a common assumption was that models with [lots of parameters] would be doomed to overfit their training data. The popular 2006 textbook Pattern Recognition and Machine Learning uses a simple example from polynomial regression: there are infinitely many polynomials of order equal to or greater than the number of data points which interpolate the training data perfectly, and “almost all” such polynomials are terrible at extrapolating to unseen points.
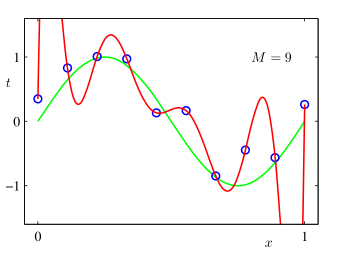
Let’s see what the overfitting argument predicts in a simple real-world example from Caballero et al. (2022), where a neural network is trained to solve 4-digit addition problems. There are possible pairs of input numbers, and possible sums, for a total of possible input-output mappings. They used a training dataset of problems, so there are therefore functions that achieve perfect training accuracy, and the proportion with greater than 50% test accuracy is literally too small to compute using standard high-precision math tools. Hence, this counting argument predicts virtually all networks trained on this problem should massively overfit— contradicting the empirical result that networks do generalize to the test set.
We are not just comparing “counting schemers” to another similar-seeming argument (“counting memorizers”). The arguments not only have the same logical structure, but they also share the same mechanism: “Because most functions have property X, SGD will find something with X.” Therefore, by pointing out that the memorization argument fails, we see that this structure of argument is not a sound way of predicting deep learning results.
So, you can’t just “count” how many functions have property X and then conclude SGD will probably produce a thing with X. [8]This argument is invalid for generalization in the same way it's invalid for AI alignment (also a question of generalization!). The argument proves too much and is invalid, therefore providing ~0 evidence.
This section doesn’t prove that scheming is impossible, it just dismantles a common support for the claim. There are other arguments offered as evidence of AI scheming, including “simplicity” arguments. Or instead of counting functions, we count network parameterizations.[9]
Recovering the counting argument?
I think a recovered argument will need to address (some close proxy of) "what volume of parameter-space leads to scheming vs not?", which is a much harder task than counting functions. You have to not just think about "what does this system do?", but "how many ways can this function be implemented?". (Don't forget to take into account the architecture's internal symmetries!)
Turns out that it's kinda hard to zero-shot predict model generalization on unknown future architectures and tasks. There are good reasons why there's a whole ML subfield which studies inductive biases and tries to understand how and why they work.
If we actually had the precision and maturity of understanding to predict this "volume" question, we'd probably (but not definitely) be able to make fundamental contributions to DL generalization theory + inductive bias research. But a major alignment concern is that we don't know what happens when we train future models. I think "simplicity arguments" try to fill this gap, but I'm not going to address them in this article.
I lastly want to note that there is no reason that any particular argument need be recoverable. Sometimes intuitions are wrong, sometimes frames are wrong, sometimes an approach is just wrong.
EDIT 3/5/24: In the comments for Counting arguments provide no evidence for AI doom, Evan Hubinger agreed that one cannot validly make counting arguments over functions. However, he also claimed that his counting arguments "always" have been counting parameterizations, and/or actually having to do with the Solomonoff prior over bitstrings.
If his counting arguments were supposed to be about parameterizations, I don't see how that's possible. For example, Evan agrees with me that we don't "understand [the neural network parameter space] well enough to [make these arguments effectively]." So, Evan is welcome to claim that his arguments have been about parameterizations. I just don't believe that that's possible or valid.
If his arguments have actually been about the Solomonoff prior, then I think that's totally irrelevant and even weaker than making a counting argument over functions. At least the counting argument over functions has something to do with neural networks.
I expect him to respond to this post with some strongly-worded comment about how I've simply "misunderstood" the "real" counting arguments. I invite him, or any other proponents, to lay out arguments they find more promising. I will be happy to consider any additional arguments which proponents consider to be stronger. Until such a time that the "actually valid" arguments are actually shared, I consider the case closed.
The counting argument doesn't count
Undo the update from the “counting argument”, however, and the probability of scheming plummets substantially. If we aren’t expecting scheming AIs, that transforms the threat model. We can rely more on experimental feedback loops on future AI; we don’t have to get worst-case interpretability on future networks; it becomes far easier to just use the AIs as tools which do things we ask. That doesn’t mean everything will be OK. But not having to handle scheming AI is a game-changer.
Other clusters of mistakes
-
-
If I want to consider whether a policy will care about its reinforcement signal, possibly the worst goddamn thing I could call that signal is “reward”! __“Will the AI try to maximize reward?” How is anyone going to think neutrally about that question, without making inappropriate inferences from “rewarding things are desirable”?
-
(This isn’t alignment’s mistake, it’s bad terminology from RL.)
-
I bet people would care a lot less about “reward hacking” if RL’s reinforcement signal hadn’t ever been called “reward.”
-
-
There are a lot more inappropriate / leading / unjustified terms, from “training selects for X” to “RL trains agents” (And don’t even get me started on “shoggoth.”)
-
As scientists, we should use neutral, descriptive terms during our inquiries.
-
-
Making highly specific claims about the internal structure of future AI, after presenting very tiny amounts of evidence.
-
For example, “future AIs will probably have deceptively misaligned goals from training” is supposed to be supported by arguments like “training selects for goal-optimizers because they efficiently minimize loss.” This argument is so weak/vague/intuitive, I doubt it’s more than a single bit of evidence for the claim.
-
I think if you try to use this kind of argument to reason about generalization, today, you’re going to do a pretty poor job.
-
-
Using analogical reasoning without justifying why the processes share the relevant causal mechanisms.
-
For example, “ML training is like evolution” or “future direct-reward-optimization reward hacking is like that OpenAI boat example today.”
-
The probable cause of the boat example (“we directly reinforced the boat for running in circles”) is not the same as the speculated cause of certain kinds of future reward hacking (“misgeneralization”).
- That is, suppose you’re worried about a future AI autonomously optimizing its own numerical reward signal. You probably aren’t worried because the AI was directly historically reinforced for doing so (like in the boat example)—You’re probably worried because the AI decided to optimize the reward on its own (“misgeneralization”).
-
In general: You can’t just put suggestive-looking gloss on one empirical phenomenon, call it the same name as a second thing, and then draw strong conclusions about the second thing!
-
While it may seem like I’ve just pointed out a set of isolated problems, a wide range of threat models and alignment problems are downstream of the mistakes I pointed out. In my experience, I had to rederive a large part of my alignment worldview in order to root out these errors!
For example, how much interpretability is nominally motivated by “being able to catch deception (in deceptively aligned systems)”? How many alignment techniques presuppose an AI being motivated by the training signal (e.g. AI Safety via Debate), or assuming that AIs cannot be trusted to train other AIs for fear of them coordinating against us? How many regulation proposals are driven by fear of the unintentional creation of goal-directed schemers?
I think it’s reasonable to still regulate/standardize “IF we observe [autonomous power-seeking], THEN we take [decisive and specific countermeasures].” I still think we should run evals and think of other ways to detect if pretrained models are scheming. But I don't think we should act or legislate as if that's some kind of probable conclusion.
Conclusion
Recent years have seen a healthy injection of empiricism and data-driven methodologies. This is awesome because there are so many interesting questions we’re getting data on!
AI’s definitely going to be a big deal. Many activists and researchers are proposing sweeping legislative action. I don’t know what the perfect policy is, but I know it isn’t gonna be downstream of (IMO) total bogus, and we should reckon with that as soon as possible. I find that it takes serious effort to root out the ingrained ways of thinking, but in my experience, it can be done.
To echo the concerns of a few representatives in the U.S. Congress: "The current state of the AI safety research field creates challenges for NIST as it navigates its leadership role on the issue. Findings within the community are often self-referential and lack the quality that comes from revision in response to critiques by subject matter experts." ↩︎
To stave off revisionism: Yes, I think that "scaling->doom" has historically been a real concern. No, people have not "always known" that the "real danger" was zero-sum self-play finetuning of foundation models and distillation of agentic-task-prompted autoGPT loops. ↩︎
Here’s a summary of the technical argument. The actual PPO+Adam update equations show that the "reward" is used to, basically, control the learning rate on each (state, action) datapoint. That's roughly[6] what the math says. We also have a bunch of examples of using this algorithm where the trained policy's behavior makes the reward number go up on its trajectories. Completely separately and with no empirical or theoretical justification given, RL papers have a convention of including the English words "the point of RL is to train agents to maximize reward", which often gets further mutated into e.g. Bostrom's argument for wireheading ("they will probably seek to maximize reward"). That's simply unsupported by the data and so an outrageous claim. ↩︎
But it is true that RL authors have a convention of repeating “the point of RL is to train an agent to maximize reward…”. Littman, 1996 (p.6): “The [RL] agent's actions need to serve some purpose: in theproblems I consider, their purpose is to maximize reward.”
Did RL researchers in the 1990’s sit down and carefully analyze the inductive biases of PPO on huge 2026-era LLMs, conclude that PPO probably entrains LLMs which make decisions on the basis of their own reinforcement signal, and then decide to say “RL trains agents to maximize reward”? Of course not. My guess: Control theorists in the 1950s (reasonably) talked about “minimizing cost” in their own problems, and so RL researchers by the ‘90s started saying “the point is to maximize reward”, and so Bostrom repeated this mantra in 2014. That’s where a bunch of concern about wireheading comes from. ↩︎The strongest argument for reward-maximization which I'm aware of is: Human brains do RL and often care about some kind of tight reward-correlate, to some degree. Humans are like deep learning systems in some ways, and so that's evidence that "learning setups which work in reality" can come to care about their own training signals. ↩︎
Note that I wrote this memo for a not-fully-technical audience, so I didn't want to get into the (important) distinction between a learning rate which is proportional to advantage (as in the real PPO equations) and a learning rate which is proportional to reward (which I talked about above). ↩︎
To quote Stella Biderman: "Q: Why do you think an AI will try to take over the world? A: Because I think some asshole will deliberately and specifically create one for that purpose. Zero claims about agency or malice or anything else on the part of the AI is required." ↩︎
I’m kind of an expert on irrelevant counting arguments. I wrote two papers on them! Optimal policies tend to seek power and Parametrically retargetable decision-makers tend to seek power. ↩︎
Some evidence suggests that “measure in parameter-space” is a good way of approximating P(SGD finds the given function). This supports the idea that “counting arguments over parameterizations” are far more appropriate than “counting arguments over functions.” ↩︎
Well, if we're going to get historical, PPO is a relatively small variation on Williams's REINFORCE policy gradient model-free RL algorithm from 1992 (or earlier if you count conferences etc), with a bunch of minor DL implementation tweaks that turn out to help a lot. I don't offhand know of any ways in which PPO's tweaks make it meaningfully different from REINFORCE from the perspective of safety, aside from the obvious ones of working better in practice. (Which is the main reason why PPO became OA's workhorse in its model-free RL era to train small CNNs/RNNs, before they moved to model-based RL using Transformer LLMs. Policy gradient methods based on REINFORCE certainly were not novel, but they started scaling earlier.)
So, PPO is recent, yes, but that isn't really important to anything here. TurnTrout could just as well have used REINFORCE as the example instead.
I don't know how you (TurnTrout) can say that. It certainly seems to me that plenty of researchers in 1992 were talking about either model-based RL or using model-free approaches to ground model-based RL - indeed, it's hard to see how anything else could work in connectionism, given that model-free methods are simpler, many animals or organisms do things that can be interpreted as model-free but not model-based (while all creatures who do model-based RL, like humans, clearly also do model-free), and so on. The model-based RL was the 'cherry on the cake', if I may put it that way... These arguments were admittedly handwavy: "if we can't write AGI from scratch, then we can try to learn it from scratch starting with model-free approaches like Hebbian learning, and somewhere between roughly mouse-level and human/AGI, a miracle happens, and we get full model-based reasoning". But hey, can't argue with success there! We have loads of nice results from DeepMind and others with this sort of flavor†.
On the other hand, I'm not able to think of any dissenters which claim that you could have AGI purely using model-free RL with no model-based RL anywhere to be seen? Like, you can imagine it working (eg. in silico environments for everything), but it's not very plausible since it would seem like the computational requirements go astronomical fast.
Back then, they had a richer conception of RL, heavier on the model-based RL half of the field, and one more relevant to the current era, than the impoverished 2017 era of 'let's just PPO/Impala everything we can't MCTS and not talk about how this is supposed to reach AGI, exactly, even if it scales reasonably well'. If you want to critique what AI researchers could imagine back in 1992, you should be reading Schmidhuber, not Bostrom. ("Computing is a pop culture", as Kay put it, and DL, and DRL, are especially pop culture right now. Which is not necessarily a bad thing if you're just trying to get things to work, but if you are going to make historical arguments about what people were or were not thinking in 2014, or 1992, pop culture isn't going to cut the mustard. People back then weren't stupid, and often had very sophisticated well-thought-out ideas & paradigms; they just had a millionth of the compute/data/infrastructure they needed to make any of it work properly...)
If you look at that REINFORCE paper, Williams isn't even all that concerned with direct use of it to train a model to solve RL tasks.* He's more concerned with handling non-differentiable things in general, like stochastic rather than the usual deterministic neurons we use, so you could 'backpropagate through the environment' models like Schmidhuber & Huber 1990, which bootstrap from random initialization using the high-variance REINFORCE-like learning signal to a superior model. (Hm, why, that sounds like the sort of thing you might do if you analyze the inductive biases of model-free approaches which entrain larger systems which have their own internal reinforcement signals which they maximize...) As Schmidhuber has been saying for decades, it's meta-learning all the way up/down. The species-level model-free RL algorithm (evolution) creates model-free within-lifetime learning algorithms (like REINFORCE), which creates model-based within-lifetime learning algorithms (like neural net models) which create learning over families (generalization) for cross-task within-lifetime learning which create learning algorithms (ICL/history-based meta-learners**) for within-episode learning which create...
It's no surprise that the "multiply a set of candidate entities by a fixed small percentage based on each entity's reward" algorithm pops up everywhere from evolution to free markets to DRL to ensemble machine learning over 'experts', because that model-free algorithm is always available as the fallback strategy when you can't do anything smarter (yet). Model-free is just the first step, and in many ways, least interesting & important step. I'm always weirded out to read one of these posts where something like PPO or evolution strategies is treated as the only RL algorithm around and things like expert iteration an annoying nuisance to be relegated to a footnote - 'reward is not the optimization target!* * except when it is in these annoying exceptions like AlphaZero, but fortunately, we can ignore these, because after all, it's not like humans or AGI or superintelligences would ever do crazy stuff like "plan" or "reason" or "search"'.
* He'd've probably been surprised to see people just... using it for stuff like DoTA2 on fully-differentiable BPTT RNNs. I wonder if he's ever done any interviews on DL recently? AFAIK he's still alive.
** Specifically, in the case of Transformers, it seems to be by self-attention doing gradient descent steps on an abstracted version of a problem; gradient descent itself isn't a very smart algorithm, but if the abstract version is a model that encodes the correct sufficient statistics of the broader meta-problem, then it can be very easy to make Bayes-optimal predictions/choices for any specific problem.
† my paper-of-the-day website feature yesterday popped up "Learning few-shot imitation as cultural transmission", Bhoopchand et al 2023 (excerpts) which is a nice example because they show clearly how history+diverse-environments+simple-priors-of-an-evolvable-sort elicit 'inner' model-like imitation learning starting from the initial 'outer' model-free RL algorithm (MPO, an actor-critic).