The normal way I'd judge whether somebody had correctly identified a horse "by their own lights" is to look at what predictions they make from that identification. For example, what they expect to see if they view the same object from a different angle or under different lighting conditions, or how they expect the object to react if they offer it a carrot.
It seems like we can just straightforwardly apply the conclusions from Eliezer's stories about blue eggs and red cubes (starting in Disguised Queries and continuing from there).
There is (in this story) a pattern in nature where the traits (blue, egg-shaped, furred, glowing, vanadium) are all correlated with each other, and the traits (red, cube-shaped, smooth, dark, palladium) are all correlated with each other. These patterns help us make predictions of some traits by observing other traits. This is useful, so we invent the words "blegg" and "rube" as a reference to those patterns.
Suppose we take some object that doesn't exactly match these patterns--maybe it's blue and furred, but cube-shaped and dark, and it contains platinum. After answering all these questions about the object, it might feel like there is another remaining question: "But is it a blegg or a rube?" But that question doesn't correspond to any observable in reality. Bleggs and rubes exist in our predictive model, not in the world. Once we've nailed down every trait we might have used the blegg/rube distinction to predict, there is no additional value in also classifying it as a "blegg" or "rube".
Similarly, it seems to me the difference between the concepts of "horse" and "either horse or a cow-at-night" lies in what predictions we would make about the object based on either of those concepts. The concept itself is an arbitrary label and can't be "right" or "wrong", but the predictions we make based on that concept can be right or wrong.
So I want to say that activating a horse neuron in response to a cow-at-night is "mistaken" IFF that neuron activation causes the observer to make bad predictions, e.g. about what they'll see if they point a flashlight at the object. If their prediction is something like "50% chance of brown fur, 50% chance of white-and-black spots" then maybe "either horse or cow-at-night" is just an accurate description of what that neuron means. But if they confidently predict they'll see a horse when the light is turned on, and then they actually see a cow, then there's an objective physical sense in which we can say they were wrong.
(And I basically don't buy the telos explanation from the post. More precisely, I think "this object has been optimized for property X by optimization process Y" is a valid and interesting thing you can say about an object, but I don't think it captures what we intuitively mean when we say that a perception is mistaken. I want to be able to say perceptions are right or wrong even when they're about non-optimized objects that have no particular importance to the observer's evolutionary fitness, e.g. distinguishing stars and comets. I also have an intuition that if you somehow encountered a horse-like object that wasn't casually descended from the evolution of horses, it should still be conceptually valid to recognize it as a horse, but I'm less sure about that part. I also have an intuition that telos should be understood as a relationship between the object and its optimizer, rather than an inherent property of the object itself, and so it doesn't have the correct type-signature to even potentially be the thing we're trying to get at.)
I love that you brought up bleggs and rubes, but I wish that that essay had a more canonical exegesis that spelled out more of what was happening.
(For example: the use of "furred" and "egg-shaped" as features is really interesting, especially when admixed with mechanical properties that make them seem "not alive" like their palladium content.)
Cognitive essentialism is a reasoning tactic where an invisible immutable essence is attributed to a thing to explain many of its features.
We can predict that if you paint a cat like a skunk (with a white stripe down its back) that will not cause the cat to start smelling like a skunk, because the "skunk essence" is modeled as immutable, and modeled as causing "white stripe" and "smell" unidirectionally.
Young children have a stage where they start getting questions like "If a rabbit is raised by monkeys will the rabbit prefer bananas or carrots?" and they answer "correctly" (in conformance to the tactic) with "carrots" but they over apply the tactic (which reveals the signature of the tactic itself) in some cases like "If a chinese baby is raised by german parents who only speak german, will the chinese baby grow up to speak german or chinese?"
If you catch them at the right age, kids will predict the baby grows up to speak chinese!
That is "cognitive essentialism" being misapplied because they have learned one of the needed tactics for understanding literally everything, but haven't learned some of the exceptions yet <3
(There are suggestions here that shibboleths and accents and ideologies and languages and so on are semi-instinctively used by humans for tracking "social/tribal essences" at a quick/intuitive level, which is a whole other kettle of fish... and part of where lots of controversy comes from. Worth flagging, but I don't want to go down that particular rabbit hole here.)
A key point here is that there is a deep structural "reasoning behind the reasoning" which is: genomes.
Genomes do, in fact, cause a huge variety of phenotypic features. They are, in fact, broadly shared among instances of animals from similar clades. They are, in practice, basically immutable in a given instance of a given animal category without unusual technology (biotech or nanotech, basically).
To return the cat and skunk example, we can imagine a "cognitive essentialist Pearlian causal graph" and note that "white stripe" does NOT causally propagate back into the "genome" node, such that DO("white stripe"=True) could change the probability in the "genome" (and then have cascading implications for the probability of "skunk smell").
More than that, genomes use signaling molecules which in the presence of shared genomic software have somewhat coherent semantic signals such as to justify a kind of "sympathetically magical thinking".
For example, a shaman might notice that willow trees fall over when a river overflows its banks during a flood, and easily throws new roots out of their trunk and continue growing in the new configuration and think of willow trees as "unusually rooty".
Then the shaman, applying the magical sympathetic thinking law of "like produces like", the shaman might make a brew out of willows hoping to condense this "rooty essence". Then they might put some other plant's cutting, without roots, in the "rooty willow water" and hope the cutting grows roots faster.
And this works!
Here is one of many youtube videos on DIY willow-based rooting mix, and modern shamans (called "scientists") eventually isolated the relevant "signaling molecule" (ie the material basis of its magico-sympathetic essential meaning within plant biology on Earth) which gains the imperative meaning "turn on root growing subroutines in the genomic software" in the presence of the right interpretive apparatus, in the form of indole-3-butyric acid.
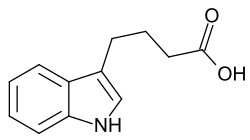
Note that it is quite common for specifically hormones to have about this size and shape and ring pattern. They are usually vaguely similar to cholesterol (and they are often made by modification of cholesterol itself) and the "smallness" and "fattiness" helps the molecules diffuse even through nuclear membranes, and then the "long skinniness" is helpful for reaching into a double helix and tickling the DNA itself.
Here is a precursor of many animal steroids, (sometimes called lanostane) with locations that can be modified to change its meaning helpfully labeled:
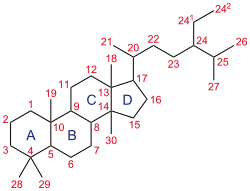
I claim that the first chemical (the one that only as a C and D ring, with the standard nitrogen at 15, and a trimmed 21, a ketone 24, and a hydroxyl 25, that willows have a lot of) is a ROOTING HORMONE that "means" something related to "roots".
Compare and contrast "morphology" (the study of parts of words) and note also that Hockett's "design features" that offer criteria for human language that are mostly missing in animal communication include arbitrariness (which hormones have), displacement (which hormones have), and so on.
I claim that indole-3-butyric acid is, roughly, an imperative verb in the language of "bio-signaling-plant-ese" whose meaning is roughly, this:

Also, the meaning is preserved for other plant species that "share" the same "genomic culture" (shared culture being another of Hockett's "design features" in human languages)... in this case: the "meaning" of the relevant molecules that willow tends to be rich in, is "culturally" shared for mint!

I will close by saying that I think that a mixture of math and biochemistry and rule-utilitarianism is likely to offer a pretty clean language for expressing a "deep and non-trivial formula with useful etymological resonances" for explaining exactly what reptiliomoprh, and mammalian, and primate, and human benevolence "is" (and how it should be approximated in morally good agents acting charitably in conformance with natural law).
For example, if there is a "chemical word" that means "grow roots please!" in plant biology, then this complex of four amino acids in specifically this order (which is recognized by various chemical receptors) is also a word for something like "care for that which is close to you and person shaped and can't care for itself, please!":
So basically they ran into the problem of misrepresentation - it seems possible for A to be about B even when B doesn’t exist, for example. If B doesn’t exist, then there is no mutual information / causal stream between it and A! And yet we are able to think about Santa Claus, or think false things like that the world is flat, etc. This capacity to get things wrong seems essential to “real” mental content, and doesn’t seem able to be captured by correlations with some physical process.
If you were to say "Santa Claus is a green furry creature which hates fun", I think you would be wrong about that. The reason I think you would be wrong about that is that the concept of Santa Claus refers to the cultural context Santa Claus comes from - if you believe that Santa Claus is green and furry you will make bad predictions about what other people will say about Santa Claus. There is mutual information between your beliefs about A (Santa Claus) and the thing those beliefs are about (the cultural idea of Santa Claus).
Likewise, when you have beliefs like "the square of the length of the hypotenuse of a right triangle is equal to the sum of the squares of the lengths of the legs", this is associated with a bunch of beliefs about what your future observations would be if you wrote math stuff down on paper or did clever things in the world with paper folding.
In the case of a looking at SAE features within a language model, interpretability researchers might say things like "Feature F#34M/31164353 is about the Golden Gate Bridge", but I think that's shorthand for a bunch of interlinked predictions about what their future observations would be if they e.g. ablated the feature and then asked a question for which the answer was the Golden Gate Bridge, or amplified the feature and asked the model about random topics.
Historically the cases I've found most confusing are those where I'm trying to figure out how a belief is "about" the outside world in a way that is unmediated by my expected future observations. Tentatively, I hypothesize that I have no beliefs that are directly "about" the real world, only beliefs about how my past and current observations will impact my future observations.
Can we define something's function in terms of the selection pressure it's going to face in the future?
Consider the case where the part of my brain that lights up for horses lights up for a cow at night. Do I have a broken horse detector or a working horse-or-cow-at-night detector?
I don't really see how the past-selection-pressure account of function can be used to say that this brain region is malfunctioning when it lights up for cows at night. Lighting up for cows at night might never have been selected against (let's assume no-one in my evolutionary history has ever seen a cow at night). And lighting up for this particular cow at night has been selected for just as much as lighting up for any particular horse has (i.e. it's come about as a side effect of the fact that it usefully lit up for some different animals in the past).
But maybe the future-selection-pressure account could handle this? Suppose the fact that the region lit up for this cow causes me to die young, so future people become a bit more likely to have it just light up for horses. Or suppose it causes me to tell my friend I saw a horse, and he says, "That was a cow; you can tell from the horns," and from then on it stops lighting up for cows at night. In either of these cases we can say that the behaviour of that brain region was going to be selected against, and so it was malfunctioning.
Whereas if lighting up for a cows-at-night as well as horses is selected for going forward, then I'm happy to say it's a horse-or-cow-at-night detector even if it causes me to call a cow a horse sometimes.
I think this is a valuable read for people who work in interp but feel like I want to add a few ideas:
- Distinguishing Misrepresentation from Mismeasurement: Interpretability researchers use techniques that find vectors which we say correspond to the representations of the model, but the methods we use to find those may be imperfect. For example, if your cat SAE feature also lights up on racoons, then maybe this is a true property of the model's cat detector (that is also lights up on racoons) or maybe this is an artefact of the SAE loss function. Maybe the true cat detector doesn't get fooled by racoons, but your SAE latent is biased in some way. See this paper that I supervised for more concrete observations.
- What are the canonical units? It may be that there is a real sense in which the model has a cat detector but maybe at the layer at which you tried to detect it, the cat detector is imperfect. If the model doesn't function as if it has an imperfect cat detector then maybe downstream of the cat-detector is some circuitry for catching/correcting specific errors. This means that finding the local cat detector you've found which might have misrepresentation issues isn't in itself sufficient to argue that the model as a whole has those issues. Selection pressures apply to the network as a whole and not necessarily always to the components. The fact that we see so much modularity is probably not random (John's written about this) but if I'm not mistaken, we don't have strong reasons to believe that the thing that looks like a cat detector must be the model's one true cat detector.
I'd be excited for some empirical work following up on this. One idea might be to train toy models which are incentivised to contain imperfect detectors (eg; there is a noisy signal but reward is optimised by having a bias toward recall or precision in some of the intermediate inferences). Identifying intermediate representations in such models could be interesting.
Off the top of my head, not very well-structured:
It seems the core thing we want our models to handle here is the concept of approximation errors, no? The "horse" symbol has mutual information with the approximation of a horse; the Santa Claus feature existing corresponds to something approximately like Santa Claus existing. The approach of "features are chiseled into the model/mind by an imperfect optimization process to fulfil specific functions" is then one way to start tackling this approximation problem. But it kind of just punts all the difficult parts onto "how the optimization landscape looks like".
Namely: the needed notion of approximation is pretty tricky to define. What are the labels of the dimensions of the space in which errors are made? What is the "topological picture" of these errors?
We'd usually formalize it as something like "this feature activates on all images within MSE distance of horse-containing images". And indeed, that seems to work well for the "horse vs cow-at-night" confusion.
But consider Santa Claus. That feature "denotes" a physical entity. Yet, what it {responds to}/{is formed because of} are not actual physical entities that are approximately similar to Santa Claus, or look like Santa Claus. Rather, it's a sociocultural phenomenon, which produces sociocultural messaging patterns that are pretty similar to sociocultural messaging patterns which would've been generated if Santa Claus existed[1].
If we consider a child fooled into believing into Santa Claus, what actually happened there is something like:
- "What adults tell you about the physical world" is usually correlated with what actually exists in the physical world.
- The child learns a model that maps adults' signaling patterns onto world-model states.
- The world-states "Santa Claus exists" and "there's a grand adult conspiracy to fool you into believing that Santa Claus exists" correspond to fairly similar adult signaling patterns.
- At this step, we potentially are again working with something neat like "vectors encoding adults' signaling patterns", and the notion of similarity is e. g. cosine similarity between those vectors.
- If the child's approximation error is significant enough to fail to distinguish between those signaling patterns, they pick the feature to learn based on e. g. the simplicity prior, and get fooled.
Going further, consider ghosts. Imagine ghost hunters equipped with a bunch of paranormal-investigation tools. They do some investigating and conclude that their readings are consistent with "there's a ghost". The issue isn't merely that there's such a small distance between "there's a ghost" and "there's no ghost" tool-output-vectors that the former fall within the approximation error of the latter. The issue is that the ghost hunters learned a completely incorrect model in which some tool-outputs which don't, in reality, correspond to ghosts existing, are mapped to ghosts existing.
Which, in turn, presumably happened because they'd previously confused the sociocultural messaging pattern of "tons of people are fooled into thinking these tools work" with "these tools work".
Which sheds some further light at the Santa Claus example too. Our sociocultural messaging about Santa Claus is not actually similar to the messaging in the counterfactual where Santa Claus really existed[2]. It's only similar in the deeply incomplete children's models of how those messaging patterns work...
Summing up, I think a merely correlational definition can still be made to work, as long as you:
- Assume that feature vectors activate in response to approximations of their referents.
- Assume that the approximation errors can lie in learned abstract encodings ("ghost-hunting tools' outputs", "sociocultural messaging patterns"), not only in default encodings ("token embeddings of words"), with likewise-learned custom similarity metrics.
- Assume that learned abstract encodings can themselves be incorrect, due to approximation errors in previously learned encodings, in a deeply compounding way...
- ... such that some features don't end up "approximately corresponding" to any actually existing phenomenon. (Like, the ground-truth prediction error between similar-sounding models is unbounded in the general case: approximately similar-sounding models don't produce approximately similarly correct predictions. Or even predictions that live in the same sample space.)
... Or something like that.
I think that representation is best explained as both correspondence and the outcome of optimization - specifically, representation is some sort of correspondence (which can be loose) that is caused by some sort of optimization process.
I'll speak primarily in defense of correspondence since I think that is where we disagree.
"All models are wrong, but some are useful" is a common aphorism in statistics, and I think it is helpful here too. You seem to treat mistaken representations as a separate sort of representation. However, even an ordinarily correct representation can contain some mistaken elements. For example:
- A child might correctly identify a horse, but not know that horses are made out of atoms.
- A man in 1970 might correctly identify a campfire, but mistakenly believe that the fire is a release of phlogiston.
Likewise ordinarily mistaken representations can contain correct elements:
- If I think I've seen a horse when I've actually seen a cow at night, I've still correctly identified a thing-which-looks-like-a-horse. I may still correctly predict that others will see it as a horse too.
- A child who believes in Santa Claus will be likely to correctly predict the behavior of a "mall Santa" i.e. an actor pretending to be Santa in a public place.
There are also edge cases where a representation mixes correct and incorrect elements, such that it isn't clear whether we should call it a mistaken representation or not:
- Methyl methacrylate adhesive is often sold under the name "plastic epoxy." Chemically speaking, it's not an epoxy at all - but practically speaking it is a binary adhesive that is used just like an epoxy. If you think that it is epoxy, you will only be wrong in ways that (almost) never matter.
- If you think that a tomato is a vegetable, then you are conventionally considered correct in a culinary context. However, by the botanical definition, a tomato is actually a fruit.
This suggests that it is useful to stop thinking about mistaken and correct representations as separate types, but rather to think about representations having mistaken and correct elements.
Having made this shift, I think that the correspondence theory of representation becomes viable again. Even a representation that is conventionally classified as mistaken may contain many correct elements - enough correct elements to make it about whatever it is about. A child's representation of Santa Claus contains many correct elements (often wears red, jolly, brings presents) and one very prominent incorrect element (the child thinks that Santa physically exists rather than being a well-known fiction). It may very well be the case that most of the bits in the child's representation are correct; we just pay more attention to the few that are wrong. For another example: if I think that I see a horse, but I actually see a cow at night, the correct elements include "it looks like a horse to me," and "it's that thing over there that I'm looking at right now." There's a lot of specificity in that last correct element! I think that's enough to make my representation be about the cow.
On the other hand, we can consider examples where an optimization process exists but where it fails to create correspondence:
- A child tells you that Santa lives in deserts, has a venomous stinger, and is a close relative of spiders. You'd probably say that they aren't actually talking about Santa at all. They're describing a scorpion and getting the name wrong.
- Once in high school, when assigned to write an essay about a historical figure, I accidentally wrote my first draft about a different figure with the same name. If my teacher was mean, they could have interpreted this first draft as being about the first figure and docked me many points becasue I had nearly every fact about them wrong. Instead, they noticed the real mistake (which was in a sense their mistake; the assignment was ambiguous) and marked accordingly.
With that being said, I do agree with you that optimization is an important piece of the puzzle - but not becasue it can explain how something can be about something else even if it is mistaken. Rather, I think that optimization is the answer to the problem of coincidences. For example:
- A novelist writes a murder-mystery which, by coincidence, is a correct description of a real murder. The naive correspondence theory of representation says that the novel is about the real murder; common sense says that it is not.
Adding the second criteria - that the correspondence must be caused by an optimization process - prevents a definition of representation from identifying coincidences as representations.
the heart has been optimized (by evolution) to pump blood; that’s a sense in which its purpose is to pump blood.
Should we expect any components like that inside neural networks?
Is there any optimization pressure on any particular subcomponent? You can have perfect object recognition using components like "horse or night cow or submarine or a back leg of a tarantula" provided that there is enough of them and they are neatly arranged.
I think this is missing the mechanics of interpretability. Interpretability is about the opposite, "what it does"
So basically, interpretability only cares about mixed features (malfunction where the thing is not as labeled) only insofar as the feature does not only do the thing that the label would make us think that it does.
That is to say, in addition to labeling representational parts of the model, interp wants to know the relation between those parts
So we know ultimatley enough about what the model will do to either debug as capabilities research, or prove that it will not try to do x, y, and z that will kill us for safety.
Basically, for an alignment researcher the polysemantics that come from being wrong sometimes, if the wrongness really is in the model, so produces the same actions, that is basically okay.
Even just plain polysemantics is not the end of the world for you interp tools, because there is not one "right" semantics. You just want to span the model behaviour.
John: So there’s this thing about interp, where most of it seems to not be handling one of the standard fundamental difficulties of representation, and we want to articulate that in a way which will make sense to interp researchers (as opposed to philosophers). I guess to start… Steve, wanna give a standard canonical example of the misrepresentation problem?
Steve: Ok so I guess the “standard” story as I interpret it goes something like this:
John: Ok so to summarize: much like interp researchers want to look at some activations or weights or other stuff inside of a net and figure out what those net-internals represent, philosophers want to look at a bunch of atoms in the physical world and figure out what those atoms represent. These are basically the same problem.
And, like many interp researchers today, philosophers started from information theory and causality. They’d hypothesize that A represents B when the two have lots of mutual information, or when they have a bunch of mutual information and A is causally downstream of B (in the Pearl sense), or other fancier hypotheses along roughly those lines. And what went wrong?
Steve: Yes, nice setup. So basically they ran into the problem of misrepresentation - it seems possible for A to be about B even when B doesn’t exist, for example. If B doesn’t exist, then there is no mutual information / causal stream between it and A! And yet we are able to think about Santa Claus, or think false things like that the world is flat, etc. This capacity to get things wrong seems essential to “real” mental content, and doesn’t seem able to be captured by correlations with some physical process.
John: Ok, let’s walk through three examples of this which philosophers might typically think about, and then translate those to the corresponding problems an interp researcher would face. So far we have Santa clause (nonexistent referent) and flat Earth (false representation). Let’s spell out both of those carefully, and maybe add one more if you have one of a different flavor?
Steve: Sure actually a classic third kind of case might fit mech interp best. Think of the supposed “grandma” or “Halle Berry” neurons people claim to have found.
John: … man, I know Halle Berry isn’t young anymore, but surely she’s not a grandma already…
Steve: At the time Hally Berry was very much not a grandma … Anyway we can imagine some neural state is tightly correlated with pictures of Halle Berry. And we can imagine that same neural state firing when shown a picture of a Halle Berry impersonator. We want to say: “that neural state is mistakenly representing that as a picture of Halle Berry.” But it seems all the same kind of mutual information is there. So it seems any causal/information-theoretic story would have to say “that neural state means Halle Berry, or Halle Berry impersonator.” It’s for this reason that the problem of misrepresentation is sometimes called the disjunction problem. Another classic example (from Jerry Fodor?) is seeing a cow through your window at night, and (intuitively) mistaking it for a horse. If that perception of a cow causes your “horse” activations to light up, so to speak, then it seems a theory based in mutual information would have to say that the symbol means “horse, or cow at night”. And then of course it’s not wrong - that thing outside the window is a “horse, or cow at night”!
So I can kind of see how this might straightforwardly apply to a simple image classifier that, we would intuitively say, sometimes misjudges a raccoon as a cat or whatever. From our perspective we can say that it’s misrepresenting, only because we have a background standard that it should be classifying only pictures of real cats. But the information encoded in the weights works for cats and for that raccoon image.
John: Good example. Want to spell out the other two as well?
Steve: I’m actually kind of confused about how to port over the case of non-existents in mech interp. I mean I assume we can find some tight correlates with Santa Claus concepts in an LLM (so that for example we could make it obsessed with Santa instead of the Golden Gate Bridge). And if in some context an LLM says “Santa exists” or “the earth is flat”, we can say it’s hallucinating. But again, like the cat classifier, this is relative to our understanding - roughly like when Wikipedia says something false, it’s only misrepresenting via us, if you see what I mean. But the project of naturalized intentionality is not supposed to rely on some further interpreter to say whether this state is accurately representing or not. It’s supposed to be misrepresenting “by its own lights”. And by its own lights, it seems that the LLM is doing a good job predicting the next tokens in the sequence - not misrepresenting.
So basically the problem here for mutual information accounts of representation is that you need to account somehow for normativity - for one group of atoms to be wrong about something. This is weird! Normativity does not seem like it would show up in a mathematical account! And yet such normativity - the possibility of misrepresentation - seems crucial to the possibility of genuine mental representation. This point was actually made by Brentano 150 years ago, but it took philosophers a while to pick it up again. It was a hard lesson that I think the alignment community could learn from too.
John: Ok, lemme try to bridge straight to an interp problem here…
(This is likely an oversimplification, but) suppose that a net (either LLM or image generator) contains an activation vector for the concept of a horse. And sometimes that vector is incorrectly activated - for whatever reason, the net “thinks” horses are involved somehow in whatever it’s predicting, even though a smart external observer would say that horses are not involved. (Drawing on your “cow at night” example, for instance, we might have fed a denoising net an image of a cow at night, and that net might incorrectly think it’s a picture of a horse and denoise accordingly.)
Now, what problem does this cause for interp? Well, interp methods today are mostly correlative, i.e. they might look for an activation vector which lights up if-and-only-if horses are involved somehow. But in this hypothetical, the “actual” horse-vector doesn’t light up if-and-only-if horses are involved. It sometimes lights up, or fails to light up, incorrectly. Even if you somehow identified the “true” horse-representation, it might seem highly polysemantic, sometimes lighting up in response to horses but sometimes lighting up to cows at night or other things. But the seeming-polysemanticity would (in this particular hypothetical) really just come from the net internals being wrong sometimes; the net thinks horses are involved when they’re actually not.
And in order to solve that, we need some kind of normativity/teleology introduced. How about you explain how naturalization would look in a standard teleosemantic approach, and then we can translate that over to interp?
Steve: So I’m hoping you can help with transporting it to mech interp, because I’m still confused about that. But the standard “teleosemantic” story, as I tell it at least, goes like this: one kind of “natural” normativity basically comes from functions.
John: Note for readers: that’s “functions” in the sense of e.g. “the function of the heart is to pump blood”, not “functions” in the mathematical sense. We also sometimes use the term “purpose”.
Steve: Sorry, yes, functions in the sense of “purpose”, or as Aristotle would have said, telos. Intuitively as you say the heart has a function to pump blood - and this seems like a relatively “natural” fact, not some mysterious non-physical fact. Whether we can actually explain such functions in purely physical terms is itself hotly disputed, but a fact like “the heart is supposed to pump blood” seems at least a bit less mysterious than “this brain state (underlying a belief) is false”.
So suppose for now that we can explain functions naturally. Then an important fact about things with functions is that they can malfunction. The heart has a function to pump blood even when it tragically fails to do so. This introduces a kind of normativity! There’s a standard now. Some physical system can be doing its function better or worse.
So from there, basically you can get mental content by saying this physical system (eg a state of the brain) has the function to be about horses, even when it malfunctions and treats a cow as a horse; misrepresentation is just a species of malfunctioning for systems that have the function to represent. So it seems like if you can tell a story where physical systems have a function to represent, and if you can explain how it’s a “natural fact” that systems have such functions, then you’re in good shape for a story about how misrepresentation can be a physical phenomenon. That’s the main idea of teleosemantics (roughly, “function-based meaning”).
John: So that “reduces” the misrepresentation problem to a basically-similar but more general problem: things can malfunction sometimes, so e.g. a heart’s purpose/function is still to pump blood even though hearts sometimes stop. Likewise, some activations in a net might have the purpose/function of representing the presence of a horse, even when those activations sometimes fire in the absence of any horses.
I think we should walk through what kind of thing could solve this sort of problem. Want to talk about grounding function/purpose in evolution (and design/optimization further down the line)?
Steve: Right so a standard story - perhaps best laid out by the philosopher Ruth Garrett Millikan - is that some biological systems have functions, as a “natural” fact, in virtue of being inheritors to a long selection process. The best explanation for why the heart pumps blood is that it helped many ancestral creatures with ancestral hearts to survive by circulating blood. (The fact that the heart makes a “thump-thump” noise is not part of the best explanation for why they’re part of this chain, so that’s how we can tell the “thump-thump” noise is not part of the heart’s function - just something it does as a kind of byproduct.)
John: So translating this into a more ML-ish frame: the heart has been optimized (by evolution) to pump blood; that’s a sense in which its purpose is to pump blood. That can still be true even if the optimization was imperfect - i.e. even if the heart sometimes stops.
Likewise, a certain activation vector in a net might have been optimized to fire exactly when horses are present. In that sense, the activation vector “represents” the presence of horses, even if the optimization was imperfect - i.e. even if the vector sometimes fires even when horses are not present.
For an interp researcher, this would mean that one needs to look at the selection pressures in training in order to figure out what stuff is represented where in the net, especially in cases where the representation is sometimes wrong (like the horse example). We need to see what an activation vector has been optimized for, not just what it does.
(... and to be clear, while this is arguably the most popular account of purpose/function in philosophy, I do not necessarily think it’s the right way to tackle the problem. But it’s at least a way to tackle the problem; it addresses misrepresentation at all, whereas e.g. correlative methods don’t address misrepresentation at all. So it demonstrates that the barrier is not intractable, though it does require methods beyond just e.g. correlations in a trained net.)