Hello! I’ve made 2 quick improvements, mainly with prompt and tokens.
TL;DR I changed the prompt to
prompt = '<start_of_turn>user\n "<unk>"?<end_of_turn>\n<start_of_turn>model\n "<unk>" "'
Solutions to improve Self-explanation:
Shorter Prompt
I noticed that the scales were being affected by prior words in the prompt/context itself. I tried out feature 4088 and replaced some words. For example, replacing ”word”with "concept" and "number" resulted in slightly different explanations at the higher scale. Intuitively, I suspected this was a fundamental issue with “merging” 2 residual streams. So to isolate variables, I started cutting down the prompt to just:
prompt = '<start_of_turn>user\n"X"?<end_of_turn>\n<start_of_turn>model\n "X" "'
Theoretically, this reduces confounding influence between the prompt context and the SAE feature itself.
Special Tokens (<unk>)
I noticed that at higher scales, explanations trended towards characters/letters specifically, despite the much shorter prompt. This was very interesting, and I realised that the explanations were picking up on the token “X” as a letter in the alphabet. So I read up on Gemma’s tokenizer to see which tokens I could replace X with. I decided on the special token <unk>, which is used to denote text that is indecipherable (I thought it would be contextually neutral, while also being appropriate for uncertainty and questioning). By combining both into this prompt:
prompt = '<start_of_turn>user\n "<unk>"?<end_of_turn>\n<start_of_turn>model\n "<unk>" "'
I’ve found explanations to be much more consistent! For example, I got subjectively much clearer results for the mission (4088), cute (4040), collection (4079) and char (14054) features across the board (see example below). I’ll keep optimising this through methods such as better entropy handling or verbosity.
Example
Here is one example: char (14054). I picked this because it was cited as a very hard example to interpret using the current setup. You can see that prompt context removal increases direct quotation slightly, and using <unk> outputs the exact token ~80% of the time (I'll update this example later once i figure out how to format the full table).
using prompt = '<start_of_turn>user\nWhat is the meaning of the word "X"?<end_of_turn>\n<start_of_turn>model\nThe meaning of the word "X" is "'
Scale: 21.84
1. 'a amount of something; a measure". It can be used to refer to a specific amount, a quantity, a size, or a degree.\n\nFor example, the word "char" can mean'
2. 'a quantity of something; a weight". It is used as a noun or a verb.'
3. 'a specified amount or value". It is often used to indicate a fixed price or the cost of something. For example, "The price of the car is Char$ 15,000'
Scale: 27.05
1. 'a sum, total, or amount". It can be used to refer to a specific amount, a general concept, or a total quantity.\n\n* **Specific amount**: "He has charted a'
2. 'a significant amount of something, especially something precious or of high value". It can also mean "a specific amount or instance". The word can refer to material things like gold, silver, and jewels,'
3. 'a sum, total, or amount of something". It can refer to a single quantity or to the total of a set of items.'
prompt = '<start_of_turn>user\n "X" <end_of_turn>\n<start_of_turn>model\n "X" "'
Scale: 21.84
1. 'is" a common English word that means "a sum, total, or quantity of something".'
2. 'char" or "ch" can be refer to various things depending on the context. \n\n- **A letter:** The most common meaning of "char" is a single letter of the alphabet.'
3. 'is the letter in the word "charm". It is often used to indicate a positive quality or a person\'s personality.'
Scale: 27.05
1. 'is a word used to indicate a thing or a person and a possession."'
2. ' is a common English word that means "a thing, object, or idea".'
3. 'is a type of jewellery that is worn close to the body." It is often made of pearls or other gemstones.
prompt = '<start_of_turn>user\n "<unk>"?<end_of_turn>\n<start_of_turn>model\n "<unk>" "'
Scale: 21.84
1. 'Charlie", or "char" is an informal word for a person or thing that is particularly interesting, charming, or odd.'
2. 'char" are both adjectives meaning "a quantity of something". \n\n- **Char** is often used to refer to a single item, especially a piece of metal or a piece of fruit.\n'
3. 'char" or "chart" refers to a piece of something that is used for shaping, drawing, or writing.'
Scale: 27.05
1. 'is an adjective that means something that is small, light, or thin. "\n\nIt can be used to refer to a single object, or to a thing that is small in number. For example'
2. 'char" or "char" can have different meanings depending on the context:\n\n**1. Noun:**\n\n- A sheet of felt.\n- An ornament in a watch or clock.\n-'
3. 'char" or "Charlie" is a common word for a person or thing that is small or of a small size.'
Further/more structural improvements
I think SelfIE works about 80% as well as it could at the moment. I’ll try some other refinements:
- Multi-feature clustering - Human-interpretable outputs likely require multiple features clusters/groups/families. I recall a lot of the Anthropic steering features were either incomplete/partial concepts. In the context of AI Safety, concepts like harm and intent and danger would likely require multiple combinations of features that are not human-interpretable to merge into human-interpretable groups. So I’m curious if anyone has suggestions for feature clustering/classification. I will look around to see if there’s anything interesting/applicable. EDIT: It seems this might be a viable solution! https://www.alignmentforum.org/posts/TMAmHh4DdMr4nCSr5/showing-sae-latents-are-not-atomic-using-meta-saes. - In this case, I will try to adapt the current setup to receive multiple features. This should allow easy plug-and-play compatibility with the meta-SAE work.
- Try on earlier layers to enable detailed prompting - @Clément Dumas suggested this as a solution to reduce contextual bleed. I’ll basically A/B test longer prompts and features in later layers to see if context bleed is reduced.
- Improving entropy/uncertainty - Improve entropy as a metric/Try to get a better second metric than entropy
- Get more granular token prob distributions - For better consistency of outputiting the actual token i'd like to either reformat the prompt to be more structured and/or rip the token probabilities directly (im not too familiar with whether inference method is being used here tho)
- Stress-test against more complex and context-dependent features - possibly via multi-token/activation-dependent replacement using the activating examples themselves.
- Concept Bottlenecks - Self-similarity / cosine similarity is bottlenecked by how concepts exist in the models themselves. Basically, I suspect the concepts have to be squished into dot product and softmax, and this inherently means concepts will get conflated/interact in ways that make them less interpretable.
One approach I speculated several months ago is to try and resolve the Softmax Bottleneck - Google Docs, though I’ll still look for other more tractable solutions.
Further optimisation Update Log for 28th August:
I am working from here: Minh's Copy of Gemma SAE self-explanation - Colab (google.com)
What worked: Multi-Feature Combination and Replacing Earlier Layers
Multi-feature combination works! I managed to combine feature 7656 ("France") and feature 7154 ("capital cities") from Neuronpedia's Gemma-1-2B [1] feature directory to elicit outputs for Paris, France. I'm just taking the sum of the vectors and dividing to find average, so this should work same as before even if you have 1 feature. Weighing should be relatively simple as long as you can decide how to weigh the features.
Sometimes the feature refers to regional capitals that are not Paris, or reference towns/adjectives describing towns, but that seems fair since the original capital cities feature included regional and not just national capitals (this suggests that better combination improves accuracy of desired output, which Meta SAEs does).
- Replacing earlier layers - Per @Clément Dumas's suggestion, replacing with earlier layers increases strength and improve output of the tokens themselves. Explanations are significantly more clear and more direct (I tested Char (14054) from L6, L12/5324, pair of names feature and L12/5373 same word repetition feature). That said, I'd weakly caution against over-relying on this because I'm wary of not using the same layer as the feature was extracted from. I suspect you already knew this since the default setting on the Colab is layer 2 and not 6 or 12.
- Increasing the vector works for longer prompts - I simply multiplied the vectors, and it's weakly more resilient and clearer when multiplied 2-5 times. We probably don't want to over-rely on this since it's hard to find the optimal range without damaging the model's capabilities (see Golden Gate Claude), but it is something to try to get tests going.
What didn't work: Minor Prompt Changes
I was trying to figure out how to make sentence-long prompts work. The fact that I made the prompts shorter to increase precision was great, but we were really under-leveraging the potential of complex explanation prompts:
- Single-word additions didn't work - Technically, "?" is also a token, so clearly it could handle some extra tokens. I tried a few things "Explain", "refers to" and "means" are all bad at higher scales. Very unclear/possibly no benefit. Weak benefit to nicer formatting that's easier to read, but the higher scales are much fuzzier (and you can just chain an unsteered model anyway if you wanted formatting). Recommend against using.
- Repetition didn't work - Repeating the same token 10-50 times and then appending "Explain" did not noticeably improve explanations in any meaningful way. Explanations still trended towards vagueness at higher scales, which is worse than baseline of repeating the token twice.
- Other special tokens - I tried the other special tokens since there's only like, 6 of them in Gemma: <bos>, <eos>, <pad>, <start_of_turn>, <end_of_turn> and <unk>. Nothing else seemed useful let alone better than <unk>. I encourage others to mess around with this juuust to be sure.
What really really worked: Combining max activations with explanation.
Now here's the interesting part. I was (once again) trying to get anything longer than 2 words to work (it would be very cool). Here, I took inspiration from ICL literature, as well as existing autointerp methods.
Here's what I did: I looked up the mentioned features on Neuronpedia and took their max activating examples. So let's take "compile" (11866), which was considered Very Difficult To Output, even for my method.
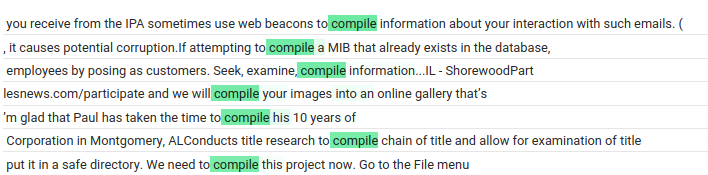
What I did was to look up the feature on Neuronpedia, replace all the activations with <unk>, and shove about 5-10 of the activating examples in the prompt.
So the prompt looks something like this[2][3].
prompt = f'<start_of_turn>user\n Repeat "{token}". What is "{token}" in the following examples? <end_of_turn>\n<start_of_turn>user\nyou receive from the IPA sometimes use web beacons to "{token}" information about your interaction with such emails. (\n<end_of_turn>\n<start_of_turn>user\n, it causes potential corruption. If attempting to "{token}" a MIB [... more activating examples ...] ruthie has "{token}" a new years wish list, in\n<end_of_turn>\n<start_of_turn>model\n"'
And the model outputs are really accurate!
Example 1: "compile" (11866)
Here's "compile" (11866) - I got it to output "compile" verbatim and explain 100% of the time from scale 10-100!
Scale: 32.26
1. 'Compile" is the repeated text in the examples.\n\n"Compile" means to arrange and process the elements of a language in a systematic way, to form a code.'
2. 'Compile". In the context of these sentences, it means to compile and run a program, which generates executable code to perform a specific task.'
3. 'Compile" means to assemble or compile a piece of software or code.\n\nIn the examples given, "compile" is used to refer to the process of compiling code or software, which involves taking source'
Scale: 37.47
1. 'Compile" is used in the examples to refer to compiling an IPA, an integration process that connects and retrieves data from multiple data sources to create a unified view of a business\'s operations.'
2. 'Compile" in the context of the phrases. \n\n- "You received from the IPA sometimes use web beacons to compile information about your interaction with such emails."\n\n- "Employees by posing as customers'
3. 'Compile" is used in the examples as a synonym for "compile".\n\n"Compile" means to create a code or program from a set of instructions.\n\nIn the context of the examples, the'
Example 2: "char" (14054)
Here's "char" (14054). Repeated, and explained 100% for the time from scale 10-100!
Scale: 32.26
1. 'Char" in the examples refers to the Catholic Church. It is a reference to the charism of the charist class of religious healers, who were renowned for their fervent dedication to helping the poor and'
2. 'Char" in the context of the examples is a term used to denote a specific type of activity or person, often in the context of a person speaking prophetically or with authority.'
3. 'Char" is used in the examples to mean "charismatic", "charitable", or "charitable".'
Scale: 37.47
1. 'Char" is a synonym for "charitable". In the first example, it refers to the work of the prison ministry at Arthur Kill Correctional Facility. In the second example, it refers to the "'
2. 'Char" in the examples refers to a religious order or movement.\n\n- Her celebrity crushes are Angelina Jolie," Charismatic".\n- "Char" Renewal is a Catholic charism that promotes peace and'
3. 'Char" is used in the examples as a intensifier for adjectives like "charismatic", "charitable", "charismatic".'
For this test, I ensured that at no point is the actual output token revealed (revealing the token might be fine, I just wanted to test the limit w blind tests). What we're essentially relying on is replicating the same context as the models used in the dataset activation, and leveraging few-shot ICL to allow the models to follow instructions without losing focus on the token they're supposed to explain.
There's more tweaking to be done. But this option now allows for sentences to be used in the prompt while maintaining accuracy comparable to single-word prompts, and also makes it cross-compatible with the use of max activating examples in prior literature. I'd recommend using some combination of both anyway, since the activating examples are valuable context regardless.
I note that there's a tradeoff between specificity and open-endedness when describing particularly complex/non-obvious features. Asking specifically to describe a feature as a word would be inaccurate for a feature that isn't a word, and words are usually obvious to interpret anyway. For example, my Activating Examples method notably did not work with L12/5324 (pair of names feature), even though my "<unk>?" got the concept of describing relationships much better. It's pretty weird, I wonder why it's like that.
Remaining other stuff to try:
- Improving entropy/uncertainty - Improve entropy as a metric/Try to get a better second metric than entropy. I procrastinated on this since it'll take a fair bit of info theory and probability understanding, but it'd be neat if we can factor confidence/diversity of solutions into it.
- Get more granular token prob distributions - For better consistency of outputting the actual token i'd like to either reformat the prompt to be more structured and/or rip the token probabilities directly. I still have no idea how to do this and would need to grok the Transformer library to get it working at all.
- Maybe remove System prompt/use base model? - I'm mildly suspicious of how helpful Gemma is with so few tokens in the prompt. It's great to help me get started, but in the future I'd want to test in a zero-contamination environment with no system prompt, since the residual stream could be very sensitive. This is less necessary if my Activating Examples method allows much longer prompts, but still interesting to try.
- Better understanding tradeoffs of replacing earlier layers - Again, I'm slightly wary of replacing layers different from where they were found, especially for features in later layers. Maybe I'm misinterpreting the methods, IDK. I'd also like to optimise wrt which layers are best to replace.
- Minor troubleshooting - A lot of the "More complex features" listed here did not seem correct when I tried in Colab. It was oddly hard to narrow down the right models, layers and features. For example, testing L12, 12017 (opposites feature) results in references to the People's Republic of China. And it wasn't my Colab either, I replicated it on your Colab. Maybe the model is wrong, but at that point, I just stuck to the simple features that could replicate from here.
- Replacing the embedding output directly - Clement again suggested this would be better. I'll take a swing at it since the last suggestion to replace earlier layers worked pretty well.
- Reimplementing some of EleutherAI's recent autointerp work - Now that I'm using methods more similar to existing autointerp work, I can replicate some of EleutherAI's optimisations. Theirs was basically developed in a black box scenario, but it's worth a day or two experimenting.
- Better workflow for automating Activating Examples method - I literally just copy pasted the ones on Neuronpedia and ran it thru Claude, there's def room for improvement in automation and metrics.
- Further stress-testing of more complex features and complex prompts - Precision for basic word-level features is pretty good (>90%). Complex features mostly (70-80%) seem to work, but I like pushing edge cases more. Whenever they do identify the feature, I can get clear accurate explanations for >90% of scales. I'd also like to stretch these methods to handle paragraphs-long prompts, beyond what I've done for single words and sentences. I believe this is feasible given the rapid progress w simple optimisations so far.
- Task vectors - maybe self-explaining features is actually really good at this somehow?

Nice post, awesome work and very well presented! I'm also working on similar stuff (using ~selfIE to make the model reason about its own internals) and was wondering, did you try to patch the SAE features 3 times instead of one (xxx instead of x)? This is one of the tricks they use in selfIE.
Thanks! We did try to use it in the repeat setting to make the model produce more than a single token, but it did not work well.
And as far as I remember it also did not improve the meaning prompt much.
Interesting work, thank you! A couple of thoughts:
- In your evaluation section, when you classify cases as for example "Self-explanation is correct, auto-interp is not", it's not entirely clear to me how you're identifying ground truth there. Human analysis of max activating examples, maybe? It doesn't seem clear to me that human analysis of a feature is always accurate either, especially at lower magnitudes of activation where the meaning may shift somewhat.
- In your example graphs of self-similarity, I notice a consistent pattern: the graph is a very smooth, concave function looking something like the top half of a sigmoid, or a logarithmic curve. But then that's interrupted in the middle by a convex or near-convex section; in the examples I looked at, it seems plausible that the boundaries of the convex section are the boundaries of the magnitudes for the correct explanation. That could very well be an artifact of the particular examples, but I thought I'd toss it out for consideration.
- We use our own judgement as a (potentially very inaccurate) proxy for accuracy as an explanation and let readers look on their own at the feature dashboard interface. We judge using a random sample of examples at different levels of activation. We had an automatic interpretation scoring pipeline that used Llama 3 70B, but we did not use it because (IIRC) it was too slow to run with multiple explanations per feature. Perhaps it is now practical to use a method like this.
- That is a pattern that happens frequently, but we're not confident enough to propose any particular form. It is sometimes thrown off by random spikes, self-similarity gradually rising at larger scales, or entropy peaking in the beginning. Because of this, there is still a lot of room for improvement in cases where a human (or maybe a peak-finding algorithm) could do better than our linear metric.
Thanks! I think the post (or later work) might benefit from a discussion of using your judgment as a proxy for accuracy, its strengths & weaknesses, maybe a worked example. I'm somewhat skeptical of human judgement because I've seen a fair number of examples of a feature seeming (to me) to represent one thing, and then that turning out to be incorrect on further examination (eg if my explanation, if used by an LLM to score whether a particular piece of text should trigger the feature, turns out not to do a good job of that).
One common type of example of that is when a feature clearly activates in the presence of a particular word, but then when trying to use that to predict whether the feature will activate on particular text, it turns out that the feature activates on that word in some cases but not all, sometimes with no pattern I can discover to distinguish when it does and doesn't.
After the best-explaining scale is applied to the feature direction vector, is the magnitude of this resulting vector similar to the magnitudes of the other token activation vectors in the prompt? If so, perhaps that fact can be used to approximate the best scale without manual finetuning. For instance, the magnitudes of all the token activation vectors can be averaged and the scale can be the proportion of this mean magnitude with the original feature direction vector's magnitude.
Yes, this is what I meant, reposting here insights @Arthur Conmy gave me on twitter
In general I expect the encoder directions to basically behave like the decoder direction with noise. This is because the encoder has to figure out how much features fire while keeping track of interfering features due to superposition. And this adjustment will make it messier
TL;DR
Introduction
This work was produced as part of the ML Alignment & Theory Scholars Program - Summer 24 Cohort, under mentorship from Neel Nanda and Arthur Conmy.
SAE features promise a flexible and extensive framework for interpretation of LLM internals. Recent work (like Scaling Monosemanticity) has shown that they are capable of capturing even high-level abstract concepts inside the model. Compared to MLP neurons, they can capture many more interesting concepts.
Unfortunately, in order to learn things with SAE features and interpret what the SAE tells us, one needs to first interpret these features on their own. The current mainstream method for their interpretation requires storing the feature’s activations on millions of tokens, filtering for the prompts that activate it the most, and looking for a pattern connecting them. This is typically done by a human, or sometimes somewhat automated with the use of larger LLMs like ChatGPT, aka auto-interp. Auto-interp is a useful and somewhat effective method, but requires an extensive amount of data and expensive closed-source language model API calls (for researchers outside scaling labs)
Recent papers like SelfIE or Patchscopes have proposed a mechanistic method of directly utilizing the model in question to explain its own internals activations in natural language. It is an approach that replaces an activation during the forward pass (e.g. some of the token embeddings in the prompt) with a new activation and then makes the model generate explanations using this modified prompt. It’s a variant of activation patching, with the notable differences that it generates a many token output (rather than a single token), and that the patched in activation may not be the same type as the activation it’s overriding (and is just an arbitrary vector of the same dimension). We study how this approach can be applied to SAE feature interpretation, since it is:
How to use
Basic method
We ask the model to explain the meaning of a residual stream direction as if it literally was a word or phrase:
We follow most closely SelfIE. We replace the residual stream at positions corresponding to the token “X” at Layer 2 (though Layer 0 or input embedding works as well) and let the model generate as usual. The method can be implemented in a few minutes with most mechanistic interpretability frameworks.
We provide a simple NNSight implementation in this Colab notebook: Gemma SAE self-explanation
TransformerLens implementation (slightly worse): TL Gemma self-explanation
Metrics for choosing scale and evaluating
We find that the magnitude (or scale) of the embedding we insert is a very sensitive hyperparameter. The optimal scale can also vary with residual stream norm. The method will produce fake or overly vague explanations when the scale is too low or too high:
With the scale being too low, we often encounter a wide range of contradictory explanations. Conversely, should the scale be too high, the model tends to generate overly generic explanations, such as "a word, phrase, or sequence of words used to refer to something specific," as shown in the previous example.
This issue significantly hinders the method's usefulness for feature interpretation, as users must examine generations at all scales to grasp the feature's meaning. Furthermore, it impedes any automatic scheme for generating explanations.
To address these issues, we explore several metrics that analyze the model's externals during generation to heuristically find the best scale for a selected feature.
Self-Similarity
We face two main difficulties when using the method without scale optimization:
The simplest explanation for why low scales result in incorrect interpretations is that the signal may be too weak for the model to detect. If the model does pick up the signal, we expect it to store this information somewhere in the context used to generate the explanation.
The first place to look for this context would be the last layer residual stream of the last prompt token, as it should contain much of the information the model will use to predict the answer. This leads us to our first metric, which we call self-similarity.
Self-similarity measures the cosine similarity between the 16th layer residual stream of the last prompt token and the original SAE feature.
Self-similarity alone isn't reliable for choosing the best scale for different features. One problem is that self-similarity continues to increase beyond the optimal scale, even when the model starts giving generic explanations. This growth makes it challenging to use self-similarity as a simple way to find the optimal scale. Despite these limitations, low peak self-similarity often indicates a feature that's difficult to explain using this method.
Entropy
The second metric we explore to evaluate explanations is based on the predicted distribution of the answer's first token. Initially, this distribution is represented as P(tn|t1..n−1). However, since we insert the SAE feature direction into one of the prompt tokens, the distribution becomes P(tn|t1..n−1,f), where f is the SAE feature index.
This metric uses entropy, which measures certainty. The entropy decreases as the mutual information between the random variable representing the feature and the first answer token increases. We calculate this metric by measuring the entropy of the predicted distribution for the answer's first token.
This approach provides another way to detect whether the model will produce a generic or random explanation.
Further (speculative) justification can be found in appendix.
Examples above show that this metric tends to:
This local minimum frequently coincides with the optimal explanation scale. The growth of the entropy metric at higher scales also helps detect cases where the model loses feature meaning and starts generating generic text.
However, entropy alone is insufficient for ranking generations because:
Composite
The entropy metric's ability to identify explanation degradation at higher scales allows us to combine it with the self-similarity metric. This composite ranks the optimal scale in the top-3 list for a much larger percentage of cases compared to either self-explanation or entropy alone.
To calculate this composite metric:
Note: While we didn't extensively tune this parameter, this approach has produced a decent baseline. We expect there may be better ways to combine these metrics, such as using peak-finding algorithms.
composite(x)=α⋅self-similarity(x)−(1−α)⋅entropy(x)Other experiments
We explored two additional approaches in our experiments:
Evaluation
Our evaluation process consisted of two main steps to measure agreement between our method and auto-interp, the current standard for SAE feature interpretation.
Step 1: Automated Evaluation
We used half of the Gemma 2B layer 6 residual stream SAE features from neuronpedia. For each feature, we:
We tried two setups:
Step 2: Manual Evaluation
We randomly sampled 100 features where the explanations disagreed in the first setup and manually evaluated them.
Comparison Challenges:
Comparing auto-interp and self-explanation is tricky due to their different approaches:
This difference can lead to self-explanation capturing the meaning of the concept a feature represents while struggling to present the concept itself. The "compile" feature (11866) serves as a good example of this distinction.
In the "compile" feature examples we can notice a common pattern found in many studied SAE features. The feature has all of its strongest activations specifically on the word "compile", while weakly activating on some synonyms. Auto-interp accurately identifies this as a "compile" feature, while self-explanation conveys the broader meaning of the word. This discrepancy led us to conduct two separate manual evaluations, each with a different level of interpretation flexibility for self-explanation results.
To address this issue, we explored additional explanation generation using a different prompt style, which we'll discuss in the next section.
Evaluation Results:
During manual evaluation, we noticed that auto-interp explanations from neuronpedia often seemed to use only a limited number of maximum activations. The authors later confirmed that these explanations were created using a simplified auto-interp setup that only considered a few maximum activating examples. They also used just a GPT-3.5 model to analyze them.
This observation highlights an advantage of our method: it doesn't require an expensive model to function effectively. The evaluation results suggest that self-explanation for SAE feature explanation may be at least as accurate as auto-interp, if not more so. Moreover, our method provides a more direct way to extract feature meaning while covering the full range of its activations simultaneously.
Limitations and improvements
Recovering the activating token
As discussed above, the self-explanation method still has several limitations. The most prominent issue is that the model currently struggles to produce the exact activating token, and not just its meaning in the explanation. This becomes very apparent, when the explained feature does not correspond to some meaning, but activates mostly on grammatical patterns (e.g. a single token feature, or a word with “j” in it feature). A good example of such a feature is the 14054 “Char” feature that activates just on words starting with “Char”.
While trying to explain this feature, the model sometimes generates explanations related to some word starting with “char”. For example: “a give or gift" (charity) or “'something that is beautiful, pleasant, or charming, especially”. Although it is practically impossible to determine, that this is actually just a “char” feature from these explanations.
To handle this issue, we additionally experimented with prompts similar to
Prompts like this are aimed to make the model repeat the tokens that activate the feature, without trying to uncover the actual meaning behind this feature. And this method does actually work to some extent. For example, it gives these explanations for the “Char” feature at different scales:
The metrics in this case look like this:
Red: composite metric; blue: self-similarity; green: entropy.
Metric value normalized by maximum plotted against scale
This prompt style allows us to generate complementary feature explanations to handle the cases, when the feature represents some token, and less the meaning behind it. Our scale optimization techniques also work with this form of the prompt, and usually show a bit higher self-similarity value. Although self-similarity charts are often similar for both prompts. This means that this method will not help in cases, when the self-explanation fails due to a low self-similarity.
Failure detection
While self-explanation is effective for many features, it doesn't perfectly explain every given feature. In some cases, it fails completely, though most of these instances were challenging to interpret even for the authors. Here's an overview of our current failure detection methods and their limitations:
Maximum Self-Similarity Thresholding
This is our primary method for detecting failing cases. It effectively identifies many model mistakes but has both false positives and false negatives. For example:
"Repeat" Prompt Failure Detection
Failures in the "repeat" prompt are generally easier to identify:
Layer-Specific Thresholds
An additional complication is that features from different layers seem to have different average self-similarity scores. This means:
While our current failure detection methods are useful, they have limitations. Improving these methods to reduce false positives and negatives, and developing more robust layer-specific thresholds, remain areas for future refinement in the self-explanation approach.
Prior work
As discussed in the introduction, auto-interp is a key method for interpreting the linear features in Sparse Autoencoders. State-of-the-art auto-interp approach requires extensive large model inference, so our current scope we only use a simpler version already available at neuronpedia for comparison.
Our method is very similar to SelfIE, Patchscopes and mwatkins’s earlier explanation method, but we apply these techniques to SAE features. We choose to focus on the explanation aspect and evaluate self-explanation as an alternative to auto-interp. We discover the importance of scale and develop metrics for tuning it and discovering when explanation does not work. Our entropy metric is similar to Surprisal from Patchscopes, but we apply it in a different context. We also apply the method to mass-explaining SAE features and discover that it can produce explanations for abstract features.
Examples
Gemma 2B
Random simple features
L12/2079, interjection feature
L12/2086, “phone” feature
L6/4075, “inf” feature
More complex features
L12/5373, same word repetition feature
L12/8361, female + male "romantic" pair feature
L12/5324, pair of names feature
L12/330, analogy/connected entities feature
L12/3079, Spanish language feature (possibly connected to some particular concept)
L12/12017, opposites feature
Phi-3 Mini
We trained our own Phi-3 Mini SAEs using the setup discussed in the different post. Self-explanation also was able to explain Phi-3 Mini features, although we did not do thorough scale tuning. Some of the interesting features are present below.
Random features
R5/L20/21147, opening bracket + math feature
R5/L20/247, “nth” feature
R5/L20/22700, “For … to … “ feature
Refusal features
R6/L16/39432
Acknowledgements
This work was produced during the research sprint of Neel Nanda’s MATS training program. We thank McKenna Fitzgerald for research management and feedback. We are grateful to Google for providing us with computing resources through the TPU Research Cloud.
Appendix
Entropy justification
Epistemic status: highly speculative; authors think the theoretical argument is correct but preliminary experiments show this argument is weak and you can safely ignore it.
Another way to detect whether the model is going to write a generic or random explanation, is to look at the predicted distribution of the answer’s first token P(t|t…). Since we also insert the SAE feature direction in one of the prompt tokens, this distribution becomes P(t|t…, f), where f is the SAE feature.
In a case when the model is going to output the correct explanation of f, we expect the mutual information of t and f to be non-zero. On the contrary, if the model ignores f and tries to generate a random or generic explanation, this mutual information should be closer to zero.
If we have a set of features for which a particular scale works well, we can assume a uniform prior on features and calculate the unconditional entropy H. Then, the mutual information of the set of features f and t will be reflected in the conditional entropy H(t|t…, f), and this conditional entropy is expected to be lower for sets of features where the model decides to output the relevant explanation. If we additionally assume that conditional entropies have low variance for those sets of features, then using the conditional entropy is a reasonable way to predict mutual information for the set of features for this scale.