How much progress in ML depends on algorithmic progress, scaling compute, or scaling relevant datasets is relatively poorly understood. In our paper, we make progress on this question by investigating algorithmic progress in image classification on ImageNet, perhaps the most well-known test bed for computer vision.
Using a dataset of a hundred computer vision models, we estimate a model—informed by neural scaling laws—that enables us to analyse the rate and nature of algorithmic advances. We use Shapley values to produce decompositions of the various drivers of progress computer vision and estimate the relative importance of algorithms, compute, and data.
Our main results include:
- Every nine months, the introduction of better algorithms contributes the equivalent of a doubling of compute budgets. This is much faster than the gains from Moore’s law; that said, there's uncertainty (our 95% CI spans 4 to 25 months)

- Roughly, progress in image classification has been ~45% due to the scaling of compute, ~45% due to better algorithms, ~10% due to scaling data
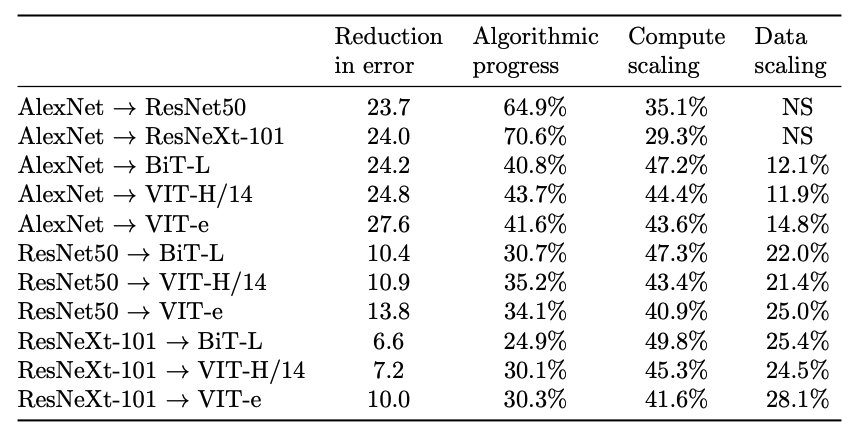
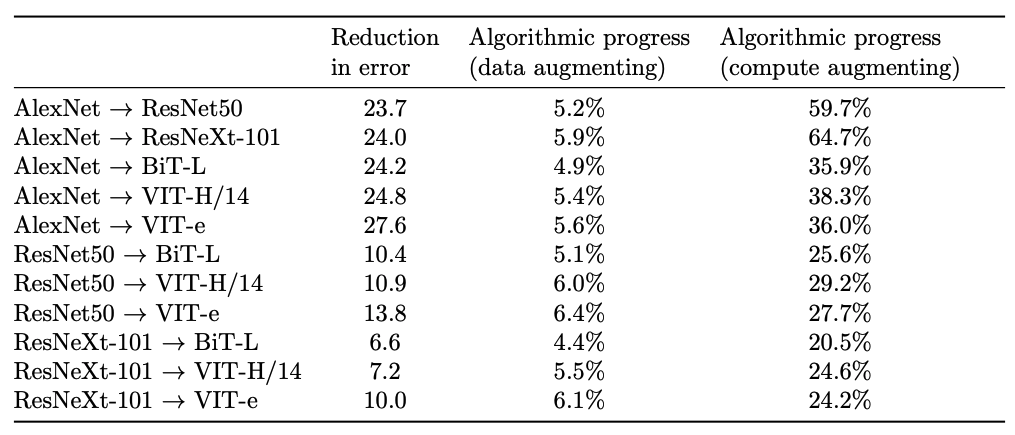
- The majority (>75%) of algorithmic progress is compute-augmenting (i.e. enabling researchers to use compute more effectively), a minority of it is data-augmenting
In our work, we revisit a question previously investigated by Hernandez and Brown (2020), which had been discussed on LessWrong by Gwern, and Rohin Shah. Hernandez and Brown (2020) re-implement 15 open-source popular models and find a 44-fold reduction in the compute required to reach the same level of performance as AlexNet, indicating that algorithmic progress outpaces the original Moore’s law rate of improvement in hardware efficiency, doubling effective compute every 16 months.
A problem with their approach is that it is sensitive to the exact benchmark and threshold pair that one chooses. Choosing easier-to-achieve thresholds makes algorithmic improvements look less significant, as the scaling of compute easily brings early models within reach of such a threshold. By contrast, selecting harder-to-achieve thresholds makes it so that algorithmic improvements explain almost all of the performance gain. This is because early models might need arbitrary amounts of compute to achieve the performance of today's state-of-the-art models. We show that the estimates of the pace of algorithmic progress with this approach might vary by around a factor of ten, depending on whether an easy or difficult threshold is chosen. [1]
Our work sheds new light on how algorithmic efficiency occurs, namely that it primarily operates through relaxing compute-bottlenecks rather than through relaxing data-bottlenecks. It further offers insight on how to use observational (rather than experimental) data to advance our understanding of algorithmic progress in ML.
- ^
That said, our estimates is consistent with Hernandez and Brown (2020)'s estimate that algorithmic progress doubles the amount of effective compute every 16 months, as our 95% confidence interval ranges from 4 to 25 months.
This looks correct to me - this is indeed how the model is able to disentangle algorithmic progress from scaling of training compute budgets.
The problems you mention are even more extreme with dataset size because plenty of the models in our analysis were only trained on ImageNet-1k, which has around 1M images. So more than half of the models in our dataset actually just use the exact same training set, which makes our model highly uncertain about the dataset side of things.
In addition, the way people typically incorporate extra data is by pretraining on bigger, more diverse datasets and then fine-tuning on ImageNet-1k. This is obviously different from sampling more images from the training distribution of ImageNet-1k, though bigger datasets such as ImageNet-21k are constructed on purpose to be similar in distribution to ImageNet-1k. We actually tried to take this into account explicitly by introducing some kind of transfer exponent between different datasets, but this didn't really work better than our existing model.
One final wrinkle is the irreducible loss of ImageNet. I tried to get some handle on this by reading the literature, and I think I would estimate a lower bound of maybe 1-2% for top 1 accuracy, as this seems to be the fraction of images that have incorrect labels. There's a bigger fraction of images that could plausibly fit multiple categories at once, but models seem to be able to do substantially better than chance on these examples, and it's not clear when we can expect this progress to cap out.
Our model specification assumes that in the infinite compute and infinite data limit you reach 100% accuracy. This is probably not exactly right because of irreducible loss, but because models are currently around over 90% top-1 accuracy I think it's probably not too big of a problem for within-distribution inference, e.g. answering questions such as "how much software progress did we see over the past decade". Out-of-distribution inference is a totally different game and I would not trust our model with this for a variety of reasons - the biggest reason is really the lack of diversity and the limited size of the dataset and doesn't have much to do with our choice of model.
To be honest, I think ImageNet-1k is just a bad benchmark for evaluating computer vision models. The reason we have to use it here is that all the better benchmarks that correlate better with real-world use cases have been developed recently and we have no data on how past models perform on these benchmarks. When we were starting this investigation we had to make a tradeoff between benchmark quality and the size & diversity of our dataset, and we ended up going for ImageNet-1k top 1 accuracy for this reason. With better data on superior benchmarks, we would not have made this choice.