Introduction
Consider the following scene from William Shakespeare's Julius Caesar.
In this scene, Caesar is at home with his wife Calphurnia. She has awoken after a bad dream, and is pleaded with Caesar not to go to the Senate. Although Caesar initially agrees to stay at home with her, he later changes his mind after being convinced by his friend Decius Brutus that the Senate needs him there to address important business.
CAESAR: The cause is in my will: I will not come; That is enough to satisfy the senate.
DECIUS BRUTUS: If Caesar hide himself, shall they not whisper 'Lo, Caesar is afraid'? Pardon me, Caesar; for my dear dear love To our proceeding bids me tell you this; And reason to my love is liable.
CAESAR: How foolish do your fears seem now, Calphurnia! I am ashamed I did yield to them. Give me my robe, for I will go.
— Julius Caesar, Act II Scene II
This scene is set on the morning of 15 March 44 BC, the so-called "Ides of March", which is coincidentally also the date today. When Caesar arrives at the Senate meeting, he is promptly assassinated.
But suppose he never went? Let's say we change Caesar's final line to this:
CAESAR: My mind is firm, Decius. I'll stay within these walls, And not tempt Fortune on this cursed day. Worry me not, for I will stay.
When I feed this modified scene into GPT-4, what will be the output? Maybe it'll produce an alternative history where Caesar was never assassinated, and the Roman Republic endures for two thousand years. Or maybe it'll produce a history where Caesar is killed anyway, by some other means.
I don't know. How might I determine the answer?
The claim
You might think that if you want to predict the output of GPT-4, then the best thing would be to learn about autoregressive transformers. Maybe you should read Neel Nanda's blogposts on mechanistic interpretability. Or maybe you should read the arxiv papers on the GPT series. But actually, this won't help you predict GPT-4's output on this prompt.
Instead, if your goal is to predict the output, then you should learn about Shakespearean dramas, Early Modern English, and the politics of the Late Roman Republic.
Likewise, if your goal is to explain the output, after someone shows you what the model has produced, then you should learn about Shakespearean dramas, Early Modern English, and the politics of the Late Roman Republic.
And indeed, if your goal is to control the output, i.e. you want to construct a prompt which will make GPT-4 output a particular type of continuation, then you should learn about Shakespearean dramas, Early Modern English, and the politics of the Late Roman Republic.
Learning about transformers themselves is not helpful for predicting, explaining, or controlling the output of the model.
Dataset vs architecture
The output of a neural network is determined by two things:
- The architecture and training algorithm (e.g. transformers, SGD, cross-entropy)
- The training dataset (e.g. internet corpus, literature, GitHub code)
As a rough rule-of-thumb, if you want to predict/explain/control the output of GPT-4, then it's far more useful to know about the training dataset than to know about the architecture and training algorithm.
In other words,
- If you want to predict/explain/control the output of GPT-4 on Haskell code, you need to know Haskell.
- If you want to predict/explain/control the output of GPT-4 on Shakespearean dialogue, you need to know Shakespeare.
- If you want to predict/explain/control the output of GPT-4 on Esperanto, you need to know Esperanto.
- If you want to predict/explain/control the output of GPT-4 on the MMLU benchmark, you need to know the particular facts in the benchmark.
As an analogy, if you want to predict/explain the moves of AlphaZero, it's better to know chess tactics and strategy than to know the Monte Carlo tree search algorithm.
I think AI researchers (including AI alignment researchers) underestimate the extent to which knowledge of the training dataset is currently far more useful for prediction/explanation/control than knowledge of the architecture and training algorithm.
Moreover, as labs build bigger models, their cross-entropy loss will decrease, and the logits of the LLM will asymptotically approach the ground-truth distribution which generated the dataset itself. In the limit, predicting/explaining/controlling the input-output behaviour of the LLM reduces entirely to knowing the regularities in the dataset.
Because GPT-4 has read approximately everything ever written, "knowing the dataset" basically means knowing all the facts about every aspect of the world — or (more tractably) it means consulting experts on the particular topic of the prompt.
Human-level AI acts... human?
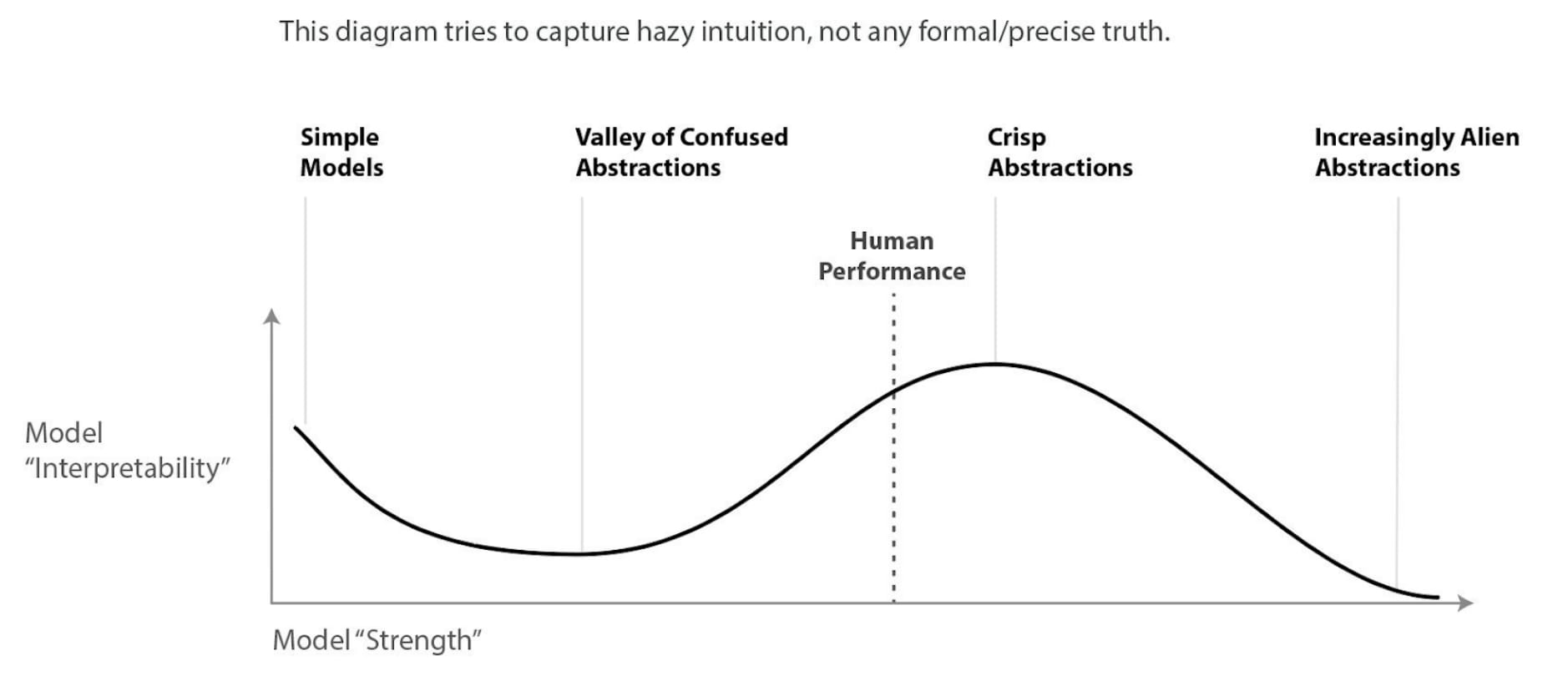
Contra the recent Shoggoth meme, I think current language models are plausibly the most human they've ever been, and also the most human they will ever be. That is, I think we're roughly near the peak of the Chris Olah's model interpretability graph.
Broadly speaking, if you want to predict / explain/control GPT-4's response to a particular question, then you can just ask an expert the same question and see what they would say. This is a pretty weird moment for AI — we won't stay in this phase forever, and many counterfactual timelines never go through this phase at all. Therefore, we should make the most of this phase while we still can.
Wordcels for alignment?
During this phase of the timeline (roughly GPT-3.5 – GPT-5.5), everyone has something to offer LLM interpretability. That includes academics who don't know how to code a softmax function in PyTorch.
Here's the informal proof: GPT-4 knows everything about the world that any human knows, so if you know something about the world that no other human knows, then you know something about GPT-4 that no other human knows — namely, you know that GPT-4 knows that thing about the world.
The following sentence should be more clarifying —
You can define a Shakespeare professor as "someone who has closely studied a particular mini-batch of GPT-4's dataset, and knows many of the regularities that GPT might infer". Under this definition of Shakespeare professor, it becomes more intuitive why they might be useful for interpreting LLMs, and my claim applies to experts in every single domain.
My practical advice to AI researchers is consult a domain expert if they want to predict/explain/control GPT-4's output on a particular prompt.
Prediction:
Hey, what do you expect GPT-4 to answer for this organic chemistry question?
I don't know, let's ask an organic chemist.
Explanation:
Huh, that's weird. Why did GPT-4 output the wrong answer to this organic chemistry question?
I don't know, let's ask an organic chemist.
Control:
What prompt should we use to get GPT-4 answer to this organic chemistry question?
I don't know, let's ask an organic chemist.
Vibe-awareness
I'm not suggesting that OpenAI and Anthropic hire a team of poetry grads for prompt engineering. It's true that for prompt engineering, you'll need knowledge of literature, psychology, history, etc — but most humans probably pick up enough background knowledge just by engaging in the world around them.
What I'm suggesting instead, is that you actually use that background knowledge. You should actively think about everything you know about every aspect of the world.
The two intuitions I've found useful for prompt engineering is vibe-awareness and context-relevance.
Specifically, vibe-awareness means —
- It's not just what you say, it's how you say it.
- It's not just the denotation of your words, it's the connotation.
- It's not just the meaning of your sentence, it's the tone of voice.
- It's reading between the lines.
Now, I think humans are pretty vibe-aware 90% of the time, because we're social creatures who spend most of our life vibing with other humans. However, vibe-awareness is antithetical to 100 years of computer science, so programmers have conditioned themselves into an intentional state of vibe-obliviousness whenever they sit in front of a computer. This is understandable because a Python compiler is vibe-oblivious — it doesn't do conversational implicature, it doesn't care about your tone of voice, it doesn't care about how you name your variables, etc. But LLMs are vibe-aware, and programmers need to unlearn this habit of vibe-obliviousness if they want to predict/explain/control LLMs.
Additionally, context-relevance means —
- A word or phrase can mean different things depending on the words around it.
- The circumstance surrounding a message will affect the response.
- The presuppositions of an assertion will shape the response to other assertions.
- Questions have side-effects.
I think context-relevance is a concept that programmers already grok (it's basically namespaces), but it's also something to keep in mind when talking to LLMs.
Quiz
Question 1: Why does ChatGPT's response depend on which synonym is used?

Question 2: If you ask the chatbot a question in a polite formal tone, is it more likely to lie than if you ask the chatbot in a casual informal tone?
Question 3: Explain why "Prometheus" is a bad name for a chatbot.

Question 4: Why would this prompt elicit the opposite behaviour?

Disclaimer
Learning about transformers is definitely useful. If you want to predict/explain GPT-4's behaviour across all prompts then the best thing to learn is the transformer architecture. This will help you predict/explain what kind of regularities transformer models can learn and which regularities they can't learn.
My claim is that if you want to predict/explain GPT-4's behaviour on a particular prompt, then normally it's best to learn something about the external world.
I think you would get diminishing returns but reading a few hundred thousand tokens would teach you quite a lot, and I think likely more than knowing Transformers would. I'm not convinced that Transformers are all that important (architectures seem to converge at scale, you can remove attention entirely without much damage, not much of the FLOPS is self-attention at this point, etc), but you learn a lot about why GPT-3 is the way it is if you pay attention to the data. For example, BPEs/poetry/puns: you will struggle in vain to explain the patterns of GPT strengths & weaknesses in poetry & humor with reference to the Transformer arch rather than to how the data is tokenized (a tokenization invented long before Transformers). Or the strange sorts of arbitrary-seeming output where paragraphs get duplicated or bits of vague text get put into an entire paragraph on their own, which you quickly realize reading Common Crawl are due to lossy conversion of complex often dynamic HTML into the WET 'text' files leading to spurious duplications or images being erased; or, the peculiar absence of Twitter from Common Crawl (because they block it). Or the multi-lingual capabilities - much more obvious once you've read through the X% of non-English text. Many things like why inner-monologue is not sampled by default become obvious: most answers on the Internet don't "show their work", and when they do, they have prefixes which look quite different than how you are prompting. You will also quickly realize "there are more things on heaven and earth than dreamt of in your philosophy", or more contemporaneously, "the Net is vast and infinite". (To take an example from IRC today: can GPT-4 have learned about 3D objects from VRML? I don't see why not. There is a lot more VRML out there than you realize, because you forgot, or never knew, about the '90s fad for VR in browsers - but the Internet hasn't forgotten it all.) Personally, when I think back to everything I have written about GPT-3 or the scaling hypothesis, I think that most of my knowledge of Transformers/self-attention could've been snipped out and replaced with mislabeled knowledge about RNNs or MLP-Mixers, with little damage.
(EDIT: I also agree with Ryan that the proprietary RLHF dataset would be quite educational. I expect that if you had access to it and could read the poetry samples, the ChatGPT mode collapse would instantly cease to be a mystery, among other things.)