This is a special post for quick takes by peterbarnett. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
peterbarnett's Shortform
67peterbarnett
64Orpheus16
52peterbarnett
39gwern
14Joel Burget
10Charlie Steiner
6kave
1kromem
3lalaithion
1Ann
42peterbarnett
4Michaël Trazzi
2Alexander Gietelink Oldenziel
26peterbarnett
151a3orn
4TurnTrout
10ryan_greenblatt
2peterbarnett
9Noosphere89
5ryan_greenblatt
25peterbarnett
9ryan_greenblatt
4ryan_greenblatt
13cubefox
1Aidan Ewart
5mattmacdermott
7Jozdien
3mattmacdermott
2Jozdien
3kaiwilliams
2Jan Betley
18peterbarnett
18peterbarnett
13gwern
4Arthur Conmy
3Jay Molstad
2TsviBT
1Mateusz Bagiński
3peterbarnett
[NOW CLOSED]
MIRI Technical Governance Team is hiring, please apply and work with us!
We are looking to hire for the following roles:
- Technical Governance Researcher (2-4 hires)
- Writer (1 hire)
The roles are located in Berkeley, and we are ideally looking to hire people who can start ASAP. The team is currently Lisa Thiergart (team lead) and myself.
We will research and design technical aspects of regulation and policy that could lead to safer AI, focusing on methods that won’t break as we move towards smarter-than-human AI. We want to design policy that allows us to safely and objectively assess the risks from powerful AI, build consensus around the risks we face, and put in place measures to prevent catastrophic outcomes.
The team will likely work on:
- Limitations of current proposals such as RSPs
- Inputs into regulations, requests for comment by policy bodies (ex. NIST/US AISI, EU, UN)
- Researching and designing alternative Safety Standards, or amendments to existing proposals
- Communicating with and consulting for policymakers and governance organizations
If you have any questions, feel free to contact me on LW or at peter@intelligence.org
I would strongly suggest considering hires who would be based in DC (or who would hop between DC and Berkeley). In my experience, being in DC (or being familiar with DC & having a network in DC) is extremely valuable for being able to shape policy discussions, know what kinds of research questions matter, know what kinds of things policymakers are paying attention to, etc.
I would go as far as to say something like "in 6 months, if MIRI's technical governance team has not achieved very much, one of my top 3 reasons for why MIRI failed would be that they did not engage enough with DC people//US policy people. As a result, they focused too much on questions that Bay Area people are interested in and too little on questions that Congressional offices and executive branch agencies are interested in. And relatedly, they didn't get enough feedback from DC people. And relatedly, even the good ideas they had didn't get communicated frequently enough or fast enough to relevant policymakers. And relatedly... etc etc."
I do understand this trades off against everyone being in the same place, which is a significant factor, but I think the cost is worth it.
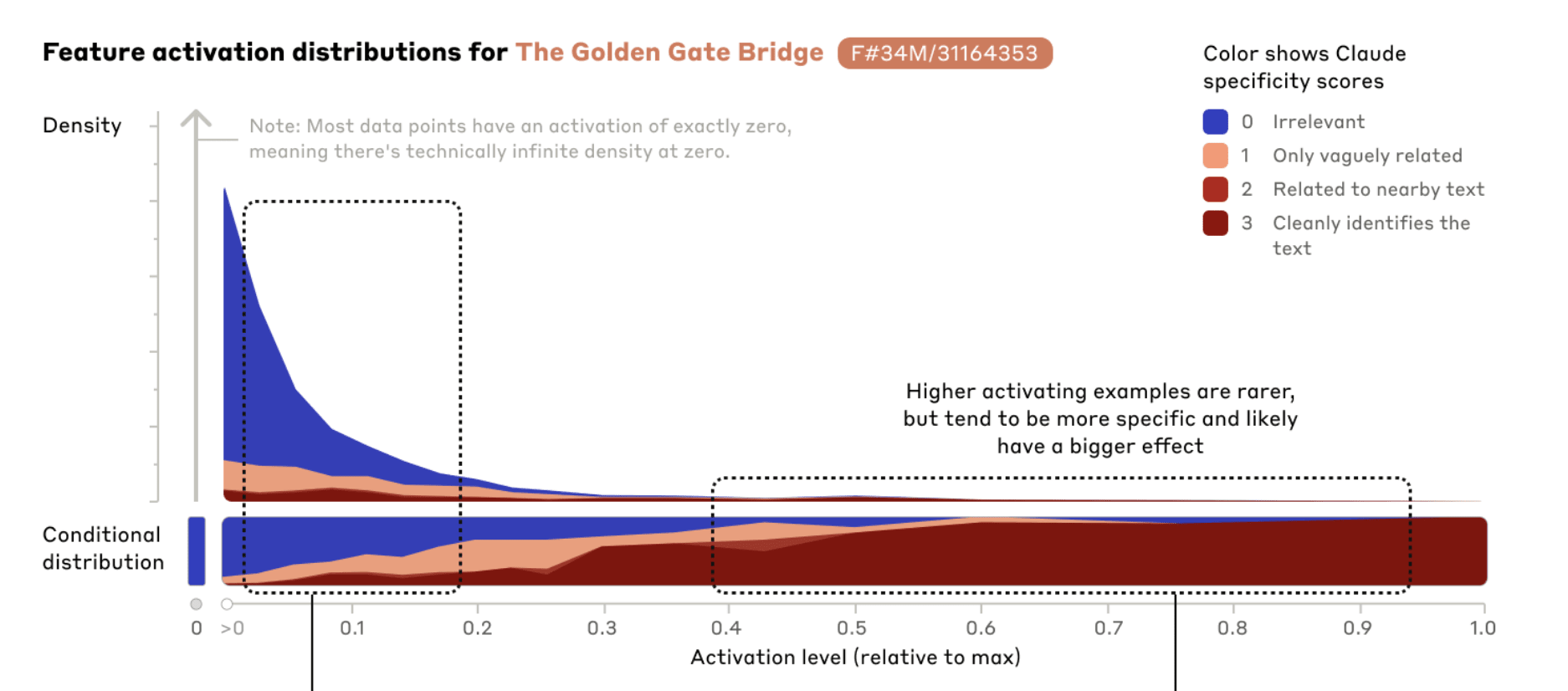
I think the Claude Sonnet Golden Gate Bridge feature is not crispy aligned with the human concept of "Golden Gate Bridge".
It brings up the San Fransisco fog far more than it would if it was just the bridge itself. I think it's probably more like Golden Gate Bridge + SF fog + a bunch of other things (some SF related, some not).
This isn't particularly surprising, given these are related ideas (both SF things), and the features were trained in an unsupervised way. But still seems kinda important that the "natural" features that SAEs find are not like exactly intuitively natural human concepts.
- It might be interesting to look at how much the SAE training data actually mentions the fog and the Golden Gate Bridge together
- I don't really think that this is super important for "fragility of value"-type concerns, but probably is important for people who think we will easily be able to understand the features/internals of LLMs
Almost all of my Golden Gate Claude chats mention the fog. Here is a not particularly cherrypicked example:

I don't really think that this is super important for "fragility of value"-type concerns, but probably is important for people who think we will easily be able to understand the features/internals of LLMs
I'm not surprised if the features aren't 100% clean, because this is after all a preliminary research prototype of a small approximation of a medium-sized version of a still sub-AGI LLM.
But I am a little more concerned that this is the first I've seen anyone notice that the cherrypicked, single, chosen example of what is apparently a straightforward, familiar, concrete (literally) concept, which people have been playing with interactively for days, is clearly dirty and not actually a 'Golden Gate Bridge feature'. This suggests it is not hard to fool a lot of people with an 'interpretable feature' which is still quite far from the human concept. And if you believe that it's not super important for fragility-of-value because it'd have feasible fixes if noticed, how do you know anyone will notice?
I'm not surprised if the features aren't 100% clean, because this is after all a preliminary research prototype of a small approximation of a medium-sized version of a still sub-AGI LLM.
It's more like a limitation of the paradigm, imo. If the "most golden gate" direction in activation-space and the "most SF fog" direction have high cosine similarity, there isn't a way to increase activation of one of them but not the other. And this isn't only a problem for outside interpreters - it's expensive for the AI's further layers to distinguish close-together vectors, so I'd expect the AI's further layers to do it as cheaply and unreliably as works on the training distribution, and not in some extra-robust way that generalizes to clamping features at 5x their observed maximum.
FWIW, I had noticed the same but had thought it was overly split (“Golden Gate Bridge, particularly its fog, colour and endpoints”) rather than dirty.
While I think you're right it's not cleanly "a Golden Bridge feature," I strongly suspect it may be activating a more specific feature vector and not a less specific feature.
It looks like this is somewhat of a measurement problem with SAE. We are measuring SAE activations via text or image inputs, but what's activated in generations seems to be "sensations associated with the Golden gate bridge."
While googling "Golden Gate Bridge" might return the Wikipedia page, whats the relative volume in a very broad training set between encyclopedic writing about the Golden Gate Bridge and experiential writing on social media or in books and poems about the bridge?
The model was trained to complete those too, and in theory should have developed successful features for doing so.
In the research examples one of the matched images is a perspective shot from physically being on the bridge, a text example is talking about the color of it, another is seeing it in the sunset.
But these are all the feature activations when acting in a classifier role. That's what SAE is exploring - give it a set of inputs and see what lights it up.
Yet in the generative role this vector maximized keeps coming up over and over in the model with content from a sensory standpoint.
Maybe generation based on functional vector manipulations will prove to be a more powerful interpretability technique than SAE probing passive activations alone?
In the above chat when that "golden gate vector" is magnified, it keeps talking about either the sensations of being the bridge as if its physical body with wind and waves hitting it or the sensations of being on the bridge. It even generates towards the end in reflecting on the knowledge of the activation about how the sensations are overwhelming. Not reflecting on the Platonic form of an abstract concept of the bridge, but about overwhelming physical sensations of the bridge's materialism.
I'll be curious to see more generative data and samples from this variation, but it looks like generative exploration of features may offer considerably more fidelity to their underlying impact on the network than just SAE. Very exciting!!
I had a weird one today; I asked it to write a program for me, and it wrote one about the Golden Gate Bridge, and when I asked it why, it used the Russian word for “program” instead of the English word “program”, despite the rest of the response being entirely in English.
Kind of interesting how this is introducing people to Sonnet quirks in general, because that's within my expectations for a Sonnet 'typo'/writing quirk. Do they just not get used as much as Opus or Haiku?
Wow, what is going on with AI safety
Status: wow-what-is-going-on, is-everyone-insane, blurting, hope-I-don’t-regret-this
Ok, so I have recently been feeling something like “Wow, what is going on? We don’t know if anything is going to work, and we are barreling towards the precipice. Where are the adults in the room?”
People seem way too ok with the fact that we are pursuing technical agendas that we don’t know will work and if they don’t it might all be over. People who are doing politics/strategy/coordination stuff also don’t seem freaked out that they will be the only thing that saves the world when/if the attempts at technical solutions don’t work.
And maybe technical people are ok doing technical stuff because they think that the politics people will be able to stop everything when we need to. And the politics people think that the technical people are making good progress on a solution.
And maybe this is the case, and things will turn out fine. But I sure am not confident of that.
And also, obviously, being in a freaked out state all the time is probably not actually that conducive to doing the work that needs to be done.
Technical stuff
For most technical approaches to the alignment problem, we either just don’t know if they will work, or it seems extremely unlikely that they will be fast enough.
- Prosaic
- We don’t understand the alignment problem well enough to even know if a lot of the prosaic solutions are the kind of thing that could work. But despite this, the labs are barreling on anyway in the hope that the bigger models will help us answer this question.
- (Extremely ambitious) mechanistic interpretability seems like it could actually solve the alignment problem, if it succeeded spectacularly. But given the rate of capabilities progress, and the fact that the models only get bigger (and probably therefore more difficult to interpret), I don’t think mech interp will solve the problem in time.
- Part of the problem is that we don’t know what the “algorithm for intelligence” is, or if such a thing even exists. And the current methods seem to basically require that you already know and understand the algorithm you’re looking for inside the model weights.
- Scalable oversight seems like the main thing the labs are trying, and seems like the default plan for attempting to align the AGI. And we just don’t know if it is going to work. The part to scalable oversight solving the alignment problem seems to have multiple steps where we really hope it works, or that the AI generalizes correctly.
- The results from the OpenAI critiques paper don’t seem all that hopeful. But I’m also fairly worried that this kind of toy scalable oversight research just doesn’t generalize.
- Scalable oversight also seems like it gets wrecked if there are sharp capabilities jumps.
- There are control/containment plans where you are trying to squeeze useful work out of a system that might be misaligned. I’m very glad that someone is doing this, and it seems like a good last resort. But also, wow, I am very scared that these will go wrong.
- These are relying very hard on (human-designed) evals and containment mechanisms.
- Your AI will also ask if it can do things in order to do the task (eg learn a new skill). It seems extremely hard to know which things you should and shouldn’t let the AI do.
- Conceptual, agent foundations (MIRI, etc)
- I think I believe that this has a path to building aligned AGI. But also, I really feel like it doesn’t get there any time soon, and almost certainly not before the deep learning prosaic AGI is built. The field is basically at the stage of “trying to even understand what we’re playing with”, and not anywhere close to “here’s a path to a solution for how to actually build the aligned AGI”.
Governance (etc)
- People seem fairly scared to say what they actually believe.
- Like, c’mon, the people building the AIs say that these might end the world. That is a pretty rock solid argument that (given sufficient coordination) they should stop. This seems like the kind of thing you should be able to say to policy makers, just explicitly conveying the views of the people trying to build the AGI.
- (But also, yes, I do see how “AI scary” is right next too “AI powerful”, and we don’t want to be spreading low fidelity versions of this.)
- Like, c’mon, the people building the AIs say that these might end the world. That is a pretty rock solid argument that (given sufficient coordination) they should stop. This seems like the kind of thing you should be able to say to policy makers, just explicitly conveying the views of the people trying to build the AGI.
- Evals
- Evals seem pretty important for working out risks and communicating things to policy makers and the public.
- I’m pretty worried about evals being too narrow, and so as long as the AI can’t build this specific bioweapon then it’s fine to release it into the world.
- There is also the obvious question of “What do we do when our evals trigger?”. We need either sufficient coordination between the labs for them to stop, or for the government(s) to care enough to make the labs stop.
- But also this seems crazy, like “We are building a world-changing, notoriously unpredictable technology, the next version or two might be existentially dangerous, but don’t worry, we’ll stop before it gets too dangerous.” How is this an acceptable state of affairs?
- By default I expect RSPs to either be fairly toothless and not restrict things or basically stop people from building powerful AI at all (at which point the labs either modify the RSP to let them continue, or openly break the RSP commitment due to claimed lack of coordination)
- For RSPs to work, we need stop mechanisms to kick in before we get the dangerous system, but we don’t know where that is. We are hoping that by iteratively building more and more powerful AI we will be able to work out where to stop.
I've seen a bunch of places where them people in the AI Optimism cluster dismiss arguments that use evolution as an analogy (for anything?) because they consider it debunked by Evolution provides no evidence for the sharp left turn. I think many people (including myself) think that piece didn't at all fully debunk the use of evolution arguments when discussing misalignment risk. A people have written what I think are good responses to that piece; many of the comments, especially this one, and some posts.
I don't really know what to do here. The arguments often look like:
A: "Here's an evolution analogy which I think backs up my claims."
B: "I think the evolution analogy has been debunked and I don't consider your argument to be valid."
A: "I disagree that the analogy has been debunked, and think evolutionary analogies are valid and useful".
The AI Optimists seem reasonably unwilling to rehash the evolution analogy argument, because they consider this settled (I hope I'm not being uncharitable here). I think this is often a reasonable move, like I'm not particularly interested in arguing about climate change or flat-earth because I do consider these settled. But I do think that the evolution analogy argument is not settled.
One might think that the obvious move here is to go to the object-level. But this would just be attempting to rehash the evolution analogy argument again; a thing that the AI Optimists seem (maybe reasonably) unwilling to do.
Is there a place that you think canonically sets forth the evolution analogy and why it concludes what it concludes in a single document? Like, a place that is legible and predictive, and with which you're satisfied as self-contained -- at least speaking for yourself, if not for others?
Are evolution analogies really that much of a crux? It seems like the evidence from evolution can't get us that far in an absolute sense (though I could imagine evolution updating someone up to a moderate probability from a super low prior?), so we should be able to talk about more object level things regardless.
Yeah, I agree with this, we should be able to usually talk about object level things.
Although (as you note in your other comment) evolution is useful for thinking about inner optimizers, deceptive alignment etc. I think that thinking about "optimizers" (what things create optimizers? what will the optimizers do? etc) is pretty hard, and at least I think it's useful to be able to look at the one concrete case where some process created a generally competent optimizer
people have written what I think are good responses to that piece; many of the comments, especially this one, and some posts.
There are responses by Quintin Pope and Ryan Greenblatt that addressed their points, where Ryan Greenblatt pointed out that the argument used in support of autonomous learning is only distinguishable from supervised learning if there are data limitations, and we can tell an analogous story about supervised learning having a fast takeoff without data limitations, and Quintin Pope has massive comments that I can't really summarize, but one is a general purpose response to Zvi's post, and the other is adding context to the debate between Quintin Pope and Jan Kulevit on culture:
I think evolution clearly provides some evidence for things like inner optimizers, deceptive alignment, and "AI takeoff which starts with ML and human understandable engineering (e.g. scaffolding/prompting), but where different mechansms drive further growth prior to full human obsolescence"[1].
Personally, I'm quite sympathetic overall to Zvi's response post (which you link) and I had many of the same objections. I guess further litigation of this post (and the response in the comments) might be the way to go if you want to go down that road?
I overall tend to be pretty sympathetic to many objections to hard takeoff, "sharp left turn" concerns, and high probability on high levels of difficulty in safely navigating powerful AI. But, I still think that the "AI optimism" cluster is too dismissive of the case for despair and over confident in the case for hope. And a bunch of this argument has maybe already occured and doesn't seem to have gotten very far. (Though the exact objections I would say to the AI optimist people are moderately different than most of what I've seen so far.) So, I'd be pretty sympathetic to just not trying to target them as an audience.
Note that key audiences for doom arguments are often like "somewhat sympathetic people at AI labs" and "somewhat sympathetic researchers or grantmakers who already have some probability on the threat models you outline".
This is perhaps related to the "the sharp left turn", but I think the "sharp left turn" concept is poorly specified and might conflate a bunch of separate (though likely correlated) things. Thus, I prefer being more precise. ↩︎
Diffusion language models are probably bad for alignment and safety because there isn't a clear way to get a (faithful) Chain-of-Thought from them. Even if you can get them to generate something that looks like a CoT, compared with autoregressive LMs, there is even less reason to believe that this CoT is load-bearing and being used in a human-like way.
Agreed, but I'd guess this also hits capabilities unless you have some clever diffusion+reasoning approach which might recover guarantees which aren't wildly worse than normal CoT guarantees. (Unless you directly generate blocks reasoning in diffusion neuralese or similar.)
That said, I'm surprised it gets 23% on AIME given this, so I think they must have found some reasoning strategy which works well enough in practice. I wonder how it solves these problems.
Based on how it appears to solve math problems, I'd guess the guarantees you get based on looking at the CoT aren't wildly worse than what you get from autoregressive models, but probably somewhat more confusing to analyze and there might be a faster path to a particularly bad sort of neuralese. They show a video of it solving a math problem on the (desktop version of the) website, here is the final reasoning:
Why is this your intuition?
At the moment they seem to just make it imitate normal-ish CoT, which would presumably improve accuracy because the model has more token-positions/space/capacity to do things like check for self-consistency. You're still scaling up a compute dimension that the model can use for solving things, and you can still do normal RL things to it from that point.
It's just maybe worse in this case because the causality from reasoning chains -> the part of the response containing the answer is worse (it was bad before, but now it is horrible).
Wait, is it obvious that they are worse for faithfulness than the normal CoT approach?
Yes, the outputs are no longer produced sequentially over the sequence dimension, so we definitely don't have causal faithfulness along the sequence dimension.
But the outputs are produced sequentially along the time dimension. Plausibly by monitoring along that dimension we can get a window into the model's thinking.
What's more, I think you actually guarantee strict causal faithfulness in the diffusion case, unlike in the normal autoregressive paradigm. The reason being that in the normal paradigm there is a causal path from the inputs to the final outputs via the model's activations which doesn't go through the intermediate produced tokens. Whereas (if I understand correctly)[1] with diffusion models we throw away the model's activations after each timestep and just feed in the token sequence. So the only way for the model's thinking at earlier timesteps to affect later timesteps is via the token sequence. Any of the standard measures of chain-of-thought faithfulness that look like corrupting the intermediate reasoning steps and seeing whether the final answer changes will in fact say that the diffusion model is faithful (if applied along the time dimension).
Of course, this causal notion of faithfulness is necessary but not sufficient for what we really care about, since the intermediate outputs could still fail to make the model's thinking comprehensible to us. Is there strong reason to think the diffusion setup is worse in that sense?
ETA: maybe “diffusion models + paraphrasing the sequence after each timestep” is promising for getting both causal faithfulness and non-encoded reasoning? By default this probably breaks the diffusion model, but perhaps it could be made to work.
- ^
Based on skimming this paper and assuming it's representative.
One reason why they might be worse is that chain of thought might make less sense for diffusion models than autoregressive models. If you look at an example of when different tokens are predicted in sampling (from the linked LLaDA paper), the answer tokens are predicted about halfway through instead of at the end:

This doesn't mean intermediate tokens can't help though, and very likely do. But this kind of structure might lend itself more toward getting to less legible reasoning faster than autoregressive models do.
It does seem likely that this is less legible by default, although we'd need to look at complete examples of how the sequence changes across time to get a clear sense. Unfortunately I can't see any in the paper.
On diffusion models + paraphrasing the sequence after each time step, I'm not sure this actually will break the diffusion model. With the current generation of diffusion models (at least the paper you cited, and Mercury, who knows about Gemini), they act basically like Masked LMs.
So they guess all of the masked tokens at each steps. (Some are re-masked to get the "diffusion process"). I bet there's a sampling strategy in there of sample, paraphrase, arbitrarily remask; rinse and repeat. But I'm not sure either.
But maybe interpretability will be easier?
With LLMs we're trying to extract high-level ideas/concepts that are implicit in the stream of tokens. It seems that with diffusion these high-level concepts should be something that arises first and thus might be easier to find?
(Disclaimer: I know next to nothing about diffusion models)
I think Sam Bowman's The Checklist: What Succeeding at AI Safety Will Involve is a pretty good list and I'm glad it exists. Unfortunately, I think its very unlikely that we will manage to complete this list, given my guess at timelines. It seems very likely that the large majority of important interventions on this list will go basically unsolved.
I might go through The Checklist at some point and give my guess at success for each of the items.
Is there a name of the thing where an event happens and that specific event is somewhat surprising, but overall you would have expected something in that reference class (or level of surprisingness) to happen?
E.g. It was pretty surprising that Ivanka Trump tweeted about Situational Awareness, but I sort of expect events this surprising to happen.
In a forecasting context, you could treat it as a kind of conservation of evidence: you are surprised, and would have been wrong, in the specific prediction of 'Ivanka Trump will not tweet about short AI timelines', but you would have been right, in a way which more than offsets your loss, for your implied broader prediction of 'in the next few years, some highly influential "normie" politicians will suddenly start talking in very scale-pilled ways'.
(Assuming that's what you meant. If you simply meant "some weird shit is gonna happen because it's a big world and weird shit is always happening, and while I'm surprised this specific weird thing happened involving Ivanka, I'm no more surprised in general than usual", then I agree with Jay that you are probably looking for Law of Large Numbers or maybe Littlewood's Law.)
The Improbability Principle sounds close. The summary seems to suggest law of large numbers is one part of the pop science book, but admittedly some of the other parts ("probability lever") seem less relevant
I've always referred to that as the Law of Large Numbers. If there are enough chances, everything possible will happen. For example, it would be very surprising if I won the lottery, but not surprising if someone I don't know won the lottery.
I propose "token surprise" (as in type-token distinction). You expected this general type of thing but not that Ivanka would be one of the tokens instantiating it.
My Favourite Slate Star Codex Posts
This is what I send people when they tell me they haven't read Slate Star Codex and don't know where to start.
Here are a bunch of lists of top ssc posts:
These lists are vaguely ranked in the order of how confident I am that they are good
https://guzey.com/favorite/slate-star-codex/
https://slatestarcodex.com/top-posts/
https://nothingismere.com/2015/09/12/library-of-scott-alexandria/
https://www.slatestarcodexabridged.com/ (if interested in psychology almost all the stuff here is good https://www.slatestarcodexabridged.com/Psychiatry-Psychology-And-Neurology)
https://danwahl.net/blog/slate-star-codex
I think that there are probably podcast episodes of all of these posts listed below. The headings are not ranked by which heading I think is important, but within each heading they are roughly ranked. These are missing any new great ACX posts. I have also left off all posts about drugs, but these are also extremely interesting if you like just reading about drugs, and were what I first read of SSC.
If you are struggling to pick where to start I recommend either Epistemic Learned Helplessness or Nobody is Perfect, Everything is Commensurable.
The ‘Thinking good’ posts I think have definitely improved how I reason, form beliefs, and think about things in general. The ‘World is broke’ posts have had a large effect on how I see the world working, and what worlds we should be aiming for. The ‘Fiction’ posts are just really really good fiction short stories. The ‘Feeling ok about yourself’ have been extremely helpful for developing some self-compassion, and also for being compassionate and non-judgemental about others; I think these posts specifically have made me a better person.
Posts I love:
Thinking good
https://slatestarcodex.com/2019/06/03/repost-epistemic-learned-helplessness/
https://slatestarcodex.com/2014/08/10/getting-eulered/
https://slatestarcodex.com/2013/04/13/proving-too-much/
https://slatestarcodex.com/2014/04/15/the-cowpox-of-doubt/
World is broke and how to deal with it
https://slatestarcodex.com/2014/07/30/meditations-on-moloch/
https://slatestarcodex.com/2014/12/19/nobody-is-perfect-everything-is-commensurable/
https://slatestarcodex.com/2013/07/17/who-by-very-slow-decay/
https://slatestarcodex.com/2014/02/23/in-favor-of-niceness-community-and-civilization/
Fiction
https://slatestarcodex.com/2018/10/30/sort-by-controversial/
https://slatestarcodex.com/2015/04/21/universal-love-said-the-cactus-person/
https://slatestarcodex.com/2015/08/17/the-goddess-of-everything-else-2/ (read after moloch stuff I think)
Feeling ok about yourself
https://slatestarcodex.com/2015/01/31/the-parable-of-the-talents/
https://slatestarcodex.com/2014/08/16/burdens/
Other??
https://slatestarcodex.com/2014/09/10/society-is-fixed-biology-is-mutable/
https://slatestarcodex.com/2018/04/01/the-hour-i-first-believed/ (this is actual crazy, read last)
Curated and popular this week