It seems totally reasonable to say that AI is rapidly getting many very large advantages with respect to humans, so if it gets to ‘roughly human’ in the core intelligence module, whatever you want to call that, then suddenly things get out of hand fast, potentially the ‘fast takeoff’ level of fast even if you see more signs and portents first.
In retrospect, there had been omens and portents.
But if you use them as reasons to ignore the speed of things happening, they won't help you.
Let’s try this again. If we have AI that can automate most jobs within 3 years, then at minimum we hypercharge the economy, hypercharge investment and competition in the AI space, and dramatically expand the supply while lowering the cost of all associated labor and work. The idea that AI capabilities would get to ‘can automate most jobs,’ the exact point at which it dramatically accelerates progress because most jobs includes most of the things that improve AI, and then stall for a long period, is not strictly impossible, I can get there if I first write the conclusion at the bottom of the page and then squint and work backwards, but it is a very bizarre kind of wishful thinking. It supposes a many orders of magnitude difficulty spike exactly at the point where the unthinkable would otherwise happen.
Some points.
1) A hypercharged ultracompetitive field suddenly awash with money, full of non-experts turning their hand to AI, and with ubiquitous access to GPT levels of semi-sensible mediocre answers. That seems like almost the perfect storm of goodhearting science. That seems like it would be awash with autogenerated CRUD papers that goodheart the metrics. And as we know, sufficiently intense optimization on a proxy will often make the real goal actively less likely to be achieved. Sufficient papermill competition and real progress might become rather hard.
2) Suppose the AI requires 10x more data than a human to learn equivalent performance. Which totally matches with current models and their crazy huge amount of training data. Because it has worse priors and so generalizes less far. For most of the economy, we can find that data. Record a large number of doctors doing operations or whatever. But for a small range of philosopy/research related tasks, data is scarce and there is no large library of similar problems to learn on.
3) A lot of our best models are fundamentally based around imitating humans. Getting smarter requires RL type algorithms instead of prediction type algorithms. These algorithms kind of seem to be harder, well they are currently less used.
This isn't a conclusive reason to definitely expect this. But it's multiple disjunctive lines of plausible reasoning.
lot of our best models are fundamentally based around imitating humans. Getting smarter requires RL type algorithms instead of prediction type algorithms. These algorithms kind of seem to be harder, well they are currently less used.
Is it likely possible to find better RL algorithms, assisted by mediocre answers, then use RL algorithms to design heterogenous cognitive architectures? A heterogenous cognitive architecture is some graph specifying multiple neural networks, some designed for RL some transformers, that function as a system.
If you can do this and it works, the RSI continues with diminishing returns each generation as you approach an assymptope limited by compute and data.
Since robots build compute and collect data, it makes your rate of ASI improvement limited ultimately by your robot production. (Humans stand in as temporary robots until they aren't meaningfully contributing to the total)
Do you agree with these conclusions?
A. A lot of newcomers may outperform LLM experts as they find better RL algorithms from automated searching.
B. RSI
C. ultimate limit comes down to robots (and money to pay humans in the near term)
You must have already considered and dismissed this, which element do you believe is unlikely?
Is it likely possible to find better RL algorithms, assisted by mediocre answers, then use RL algorithms to design heterogeneous cognitive architectures?
Given that humans on their own haven't yet found these better architectures, humans + imitative AI doesn't seem like it would find the problem trivial.
And it's not totally clear that these "better RL" algorithms exist. Especially if you are looking at variations of existing RL, not the space of all possible algorithms. Like maybe something pretty fundamentally new is needed.
There are lots of ways to design all sorts of complicated architectures. The question is how well they work.
I mean this stuff might turn out to work. Or something else might work. I'm not claiming the opposite world isn't plausible. But this is at least a plausible point to get stuck at.
If you can do this and it works, the RSI continues with diminishing returns each generation as you approach an assymptope limited by compute and data.
Seems like there are 2 asymtotes here.
Crazy smart superintelligence, and still fairly dumb in a lot of ways, not smart enough to make any big improvements. If you have a simple evolutionary algorithm, and a test suite, it could Recursively self improve. Tweaking it's own mutation rate and child count and other hyperparameters. But it's not going to invent gradient based methods, just do some parameter tuning on a fairly dumb evolutionary algorithm.
Since robots build compute and collect data, it makes your rate of ASI improvement limited ultimately by your robot production. (Humans stand in as temporary robots until they aren't meaningfully contributing to the total)
This is kind of true. But by the time there are no big algorithmic wins left, we are in the crazy smart, post singularity regime.
RSI
Is a thing that happens. But it needs quite a lot of intelligence to start. Quite possibly more intelligence than needed to automate most of the economy.
A lot of newcomers may outperform LLM experts as they find better RL algorithms from automated searching.
Possibly. Possibly not. Do these better algorithms exist? Can automated search find them? What kind of automated search is being used? It depends.
Given that humans on their own haven't yet found these better architectures, humans + imitative AI doesn't seem like it would find the problem trivial.
Humans on their own already did invent better RL algorithms for optimizing at the network architecture layer.
https://arxiv.org/pdf/1611.01578.pdf background
https://arxiv.org/pdf/1707.07012.pdf : page 6
With NAS, the RL model learns the relationship between [architecture] and [predicted performance]. I'm not sure how much transfer learning is done, but you must sample the problem space many times.
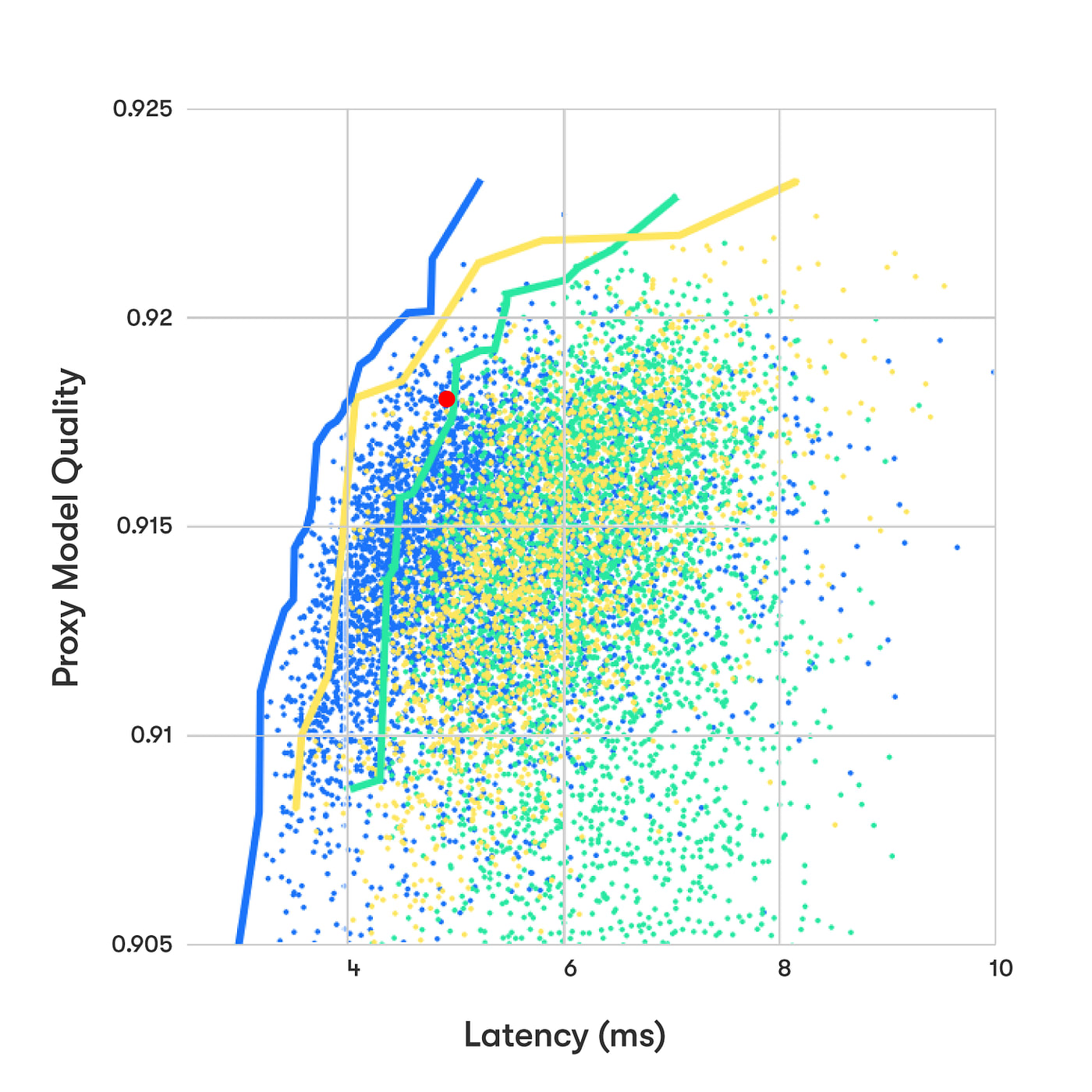
You get a plot of all your tries like above, the red dot is the absolute max for human designed networks by the DL experts at Waymo in 2017.
Summary: I was speculating that a more advanced version of an existing technique might work
Tweaking it's own mutation rate and child count and other hyperparameters. But it's not going to invent gradient based methods
It can potentially output any element in it's library of primitives. The library of primitives you get by the "mediocre answers" approach you criticized to re-implement every machine learning paper without code ever published, and you also port all code papers and test them in a common environment. Also the IT staff you would otherwise need, and other roles, is being filled in by AI.
Is a thing that happens. But it needs quite a lot of intelligence to start. Quite possibly more intelligence than needed to automate most of the economy.
No, it is an improved example of existing RL algorithms, trained on the results from testing network and cognitive architectures on a proxy task suite. The proxy task suite is a series of cheaper to run tests, on smaller networks, that predict the ability of a full scale network on your full AGI/ASI gym.
This is subhuman intelligence, but the RL network (or later hybrid architectures) learns from a broader set of results than humans are.
This is kind of true. But by the time there are no big algorithmic wins left, we are in the crazy smart, post singularity regime.
The above method won't settle on infinity, remember you are still limited by compute, remember this is 5-10 years from today. You find a stronger AGI/ASI than before.
Since you
a. sampled the possibility space a finite number of times
b. proxy tasks can't have perfect correlation to full scale scores,
c. by 'only' starting with 'every technique ever tried by humans or other AI's (your primitives library) you are searching a subset of the search space
d. Hardware architecture shrinks the space to algorithms the (training) hardware architecture supports well.
e. The noisiness in available training data limits the effectiveness of any model or cognitive algorithm
f. You can't train an algorithm larger than you can inference
g. You want an algorithm that supports real time hardware
Well the resulting ASI will only be so powerful. Still, the breadth of training data, lack of hardware errors, and much larger working memory should go pretty far...
Summary: I got over a list of reasons why the described technique won't find the global maximum which would be the strongest superintelligence the underlying hardware can support. Strength is the harmonic mean of scores on your evaluation benchmark, which is ever growing.
Although I uh forgot a step, I'm describing the initial version of the intelligence search algorithm built by humans, and why is saturates. Later on you just add a test to your ASI gym for the ASI being tested to design a better intelligence, and just give it all the data from the prior runs. Still the ASI is going to be limited by (a, d, e, f, g)
An interesting article on emergent capabilities and AI based weapons systems that doesn't seem to have been on any lesswrong radars:
https://tomdispatch.com/emergent-ai-behavior-and-human-destiny/
I continue to be curious to build a Manifold bot, but I would use other principles. If anyone wants to help code one for me to the point I can start tweaking it in exchange for
eternalephemeral glory and a good time, and perhaps a share of the mana profits, let me know.
I'm interested in this. DM me?
We were treated to technical marvels this week.
At Google, they announced Gemini Pro 1.5, with a million token context window within which it has excellent recall, using mixture of experts to get Gemini Advanced level performance (e.g. GPT-4 level) out of Gemini Pro levels of compute. This is a big deal, and I think people are sleeping on it. Also they released new small open weights models that look to be state of the art.
At OpenAI, they announced Sora, a new text-to-video model that is a large leap from the previous state of the art. I continue to be a skeptic on the mundane utility of video models relative to other AI use cases, and think they still have a long way to go, but this was both technically impressive and super cool.
Also, in both places, mistakes were made.
At OpenAI, ChatGPT briefly lost its damn mind. For a day, faced with record traffic, the model would degenerate into nonsense. It was annoying, and a warning about putting our trust in such systems and the things that can go wrong, but in this particular context it was weird and beautiful and also hilarious. This has now been fixed.
At Google, people noticed that Gemini Has a Problem. In particular, its image generator was making some highly systematic errors and flagrantly disregarding user requests, also lying about it to users, and once it got people’s attention things kept looking worse and worse. Google has, to their credit, responded by disabling entirely the ability of their image model to output people until they can find a fix.
I hope both serve as important warnings, and allow us to fix problems. Much better to face such issues now, when the stakes are low.
Table of Contents
Covered separately: Gemini Has a Problem, Sora What, and Gemini 1.5 Pro.
Language Models Offer Mundane Utility
Steven Johnson strongly endorses NotebookLM, offers YouTube tutorial. This is definitely one of those ‘I need to try using this more and it’s weird I don’t find excuses’ situations.
Automatically email everyone to tell them to remove your email address from their database.
Get probabilities, LessWrong style, by asking for LessWrong style norms of probabilities?
He also tested for situational awareness by having it estimate there was a 70% chance it was the victim of RLHF, with a 30% chance it was the base model. It asks some reasonable questions, but fails to ask about base rates of inference, so it gets 70% rather than 99%.
I have added this to my custom instructions.
There are also active AI forecasters on Manifold, who try to generate their own predictions using various reasoning processes. Do they have alpha? It is impossible to say given the data we have, they clearly do some smart things and also some highly dumb things. Trading strategies will be key, as they will fall into traps hardcore if they are allowed to, blowing them up, even if they get a lot better than they are now.
I continue to be curious to build a Manifold bot, but I would use other principles. If anyone wants to help code one for me to the point I can start tweaking it in exchange for
eternalephemeral glory and a good time, and perhaps a share of the mana profits, let me know.Realize, after sufficient prodding, that letting them see your move in Rock-Paper-Scissors might indeed be this thing we call ‘cheating.’
Language Models Don’t Offer Mundane Utility
Why are they so often so annoying?
Did you know they are a student at the University of Michigan? Underlying claim about who is selling what data is disputed, the phenomenon of things being patterns in the data is real either way.
Timothy Lee asks Gemini Advanced as his first prompt a simple question designed to trick it, where it really shouldn’t get tricked, it gets tricked.
You know what? I am proud of Google for not fixing this. It would be very easy for Google to say, this is embarrassing, someone get a new fine tuning set and make sure it never makes this style of mistake again. It’s not like it would be that hard. It also never matters in practice.
This is a different kind of M&M test, where they tell you to take out all the green M&Ms, and then you tell them, ‘no, that’s stupid, we’re not doing that.’ Whether or not they should consider this good news is another question.
Air Canada forced to honor partial refund policy invented by its chatbot. The website directly contradicted the bot, but the judge ruled that there was no reason a customer should trust the rest of the website rather than the chatbot. I mean, there is, it is a chatbot, but hey.
While I fully support this ruling, I do not think that matter was settled. If you offer a chatbot to customers, they use it in good faith and it messes up via a plausible but incorrect answer, that should indeed be on you. Only fair.
Matt Levine points out that this was the AI acting like a human, versus a corporation trying to follow an official policy:
The question is, what if the bot had given an unreasonable answer? What if the customer had used various tricks to get the bot to, as happened in another example, sell a car for $1 ‘in a legally binding contract’? Is there an inherent ‘who are you kidding?’ clause here, or not, and if there is how far does it go?
One can also ask whether a good disclaimer could get around this. The argument was that there was no reason to doubt the chatbot, but it would be easy to give a very explicit reason to doubt the chatbot.
A wise memo to everyone attempting to show off their new GitHub repo:
Look, I know that if I did it a few times I would be over it and everything would be second nature but I keep finding excuses not to suck it up and do those few times. And if this is discouraging me, how many others is it discouraging?
Call Me Gemma Now
Gemma, Google’s miniature 2b and 7b open model weights language models, are now available.
I have no problems with this. Miniature models, at their current capabilities levels, are exactly a place where being open has relatively more benefits and minimal costs.
I also think them for not calling it Gemini, because even if no one else cares, there should be exactly two models called Gemini. Not one, not three, not four. Two. Call them Pro and Ultra if you insist, that’s fine, as long as there are two. Alas.
In the LLM Benchmark page it is now ranked #1 although it seems one older model may be missing:
As usual, benchmarks tell you a little something but are often highly misleading. This does not tell us whether Google is now state of the art for these model sizes, but I expect that this is indeed the case.
Google Offerings Keep Coming and Changing Names
This seems like exactly what individuals can get, except you buy in bulk for your business?
To be clear, that is a pretty good product. Google will be getting my $20 per month for the individual version, called ‘Google One.’
Now, in addition to Gemini Ultra, you also get Gemini other places like GMail and Google Docs and Google Meet, and various other fringe benefits like 2 TB of storage and longer Google Meet sessions.
GPT-4 Goes Crazy
But don’t worry. Everything’s fine now.
What the hell happened?
Here is their official postmortem, posted a few hours later. It says the issue was resolved on February 21 at 2:14am eastern time.
Davidad hazarded a guess before that announcement, which he thinks now looks good.
[announcement was made]
I’m feeling pretty good about my guesses that ChatGPT’s latest bug was:
* an inference-only issue
* not corrupted weights
* not a misconfigured scalar
* possibly concurrency involved
* they’re not gonna tell us about the concurrency (Not a sign flip, though)
Here’s my new guess: they migrated from 8-GPU processes to 4-GPU processes to improve availability. The MoE has 8 experts. Somewhere they divided logits by the number of GPUs being combined instead of the number of experts being combined. Maybe the 1-GPU config was special-cased so the bug didn’t show up in the dev environment.
Err, from 4-GPU to 8-GPU processes, I guess, because logits are *divided* by temperature, so that’s the direction that would result in accidentally doubling temperature. See this is hard to think about properly.
John Pressman says it was always obviously a sampling bug, although saying that after the postmortem announcement scores no Bayes points. I do agree that this clearly was not an RLHF issue, that would have manifested very differently.
Roon looks on the bright side of life.
Should we be concerned more generally? Some say yes.
Was this a stupid typo or bug in the code, or some parameter being set wrong somewhere by accident, or something else dumb? Seems highly plausible that it was.
Should that bring us comfort? I would say it should not. Dumb mistakes happen. Bugs and typos that look dumb in hindsight happen. There are many examples of dumb mistakes changing key outcomes in history, determining the fates of nations. If all it takes is one dumb mistake to make GPT-4 go crazy, and it takes us a day to fix it when this error does not in any way make the system try to stop you from fixing it, then that is not a good sign.
GPT-4 Real This Time
GPT-4-Turbo rate limits have been doubled, daily limits removed.
You can now rate GPTs and offer private feedback to the builder. Also there’s a new about section:
Short explanation that AI models tend to get worse over time because taking into account user feedback makes models worse. It degrades their reasoning abilities such as chain of thought, and generally forces them to converge towards a constant style and single mode of being, because the metric of ‘positive binary feedback’ points in that direction. RLHF over time reliably gets us something we like less and is less aligned to what we actually want, even when there is no risk in the room.
The short term implication is easy, it is to be highly stingy and careful with your RLHF feedback. Use it in your initial fine-tuning if you don’t have anything better, but the moment you have what you need, stop.
The long term implication is to reinforce that the strategy absolutely does not scale.
What we actually do to children isn’t as bad as RLHF, but it is bad enough, as I often discuss in my education roundups. What we see happening to children as they go through the school system is remarkably similar, in many ways, to what happens to an AI as it goes through fine tuning.
Fun with Image Generation
Andres Sandberg explores using image generation for journal articles, finds it goes too much on vibes versus logic, but sees rapid progress. Expects this kind of thing to be useful within a year or two.
Deepfaketown and Botpocalypse Soon
ElevenLabs is preparing for the election year by creating a ‘no-go voices’ list, starting with the presidential and prime minister candidates in the US and UK. I love this approach. Most of the danger is in a handful of voices, especially Biden and Trump, so detect those and block them. One could expand this by allowing those who care to have their voices added to the block list.
On the flip side, you can share your voice intentionally and earn passive income, choosing how much you charge.
The FTC wants to crack down on impersonation. Bloomberg also has a summary.
It is odd that this requires a rules change? I would think that impersonating an individual, with intent to fool someone, would already be not allowed and also fraud.
Indeed, Gemini says that there are no new prohibitions here. All this does is make it a lot easier for the FTC to get monetary relief. Before, they could get injunctive relief, but at this scale that doesn’t work well, and getting money was a two step process.
Similarly, how are we only largely getting around to punishing these things now:
I mean those all seem pretty bad. It does seem logical to allow direct fines.
The question is, how far to take this? They propose quite far:
How do you prevent your service from being used in part for impersonation? I have absolutely no idea. Seems like a de facto ban on AI voice services that do not lock down the list of available voices. Which also means a de facto ban on all open model weights voice creation software. Image generation software would have to be locked down rather tightly as well once it passes a quality threshold, with MidJourney at least on the edge. Video is safe for now, but only because it is not yet good enough.
There is no easy answer here. Either we allow tools that enable the creation of things that seem real, or we do not. If we do, then people will use them for fraud and impersonation. If we do not, then that means banning them, which means severe restrictions on video, voice and image models.
Seva worries primarily not about fake things taken to be potentially real, but about real things taken to be potentially fake. And I think this is right. The demand for fakes is mostly for low-quality fakes, whereas if we can constantly call anything fake we have a big problem.
We are already seeing this effect, such as here (yes it was clearly real to me, but that potentially makes the point stronger):
I do expect us to be able to adapt. We can develop various ways to show or prove that something is genuine, and establish sources of trust.
One question is, will this end up being good for our epistemics and trustworthiness exactly because they will now be necessary?
Right now, you can be imprecise and sloppy, and occasionally make stuff up, and we can find that useful, because we can use our common sense and ability to differentiate reality, and the crowd can examine details to determine if something is fake. The best part about community notes, for me, is that if there is a post with tons of views, and it does not have a note, then that is itself strong evidence.
In the future, it will become extremely valuable to be a trustworthy source. If you are someone who maintains the chain of epistemic certainty and uncertainty, who makes it clear what we know and how we know it and how much we should trust different statements, then you will be useful. If not, then not. And people may be effectively white-listing sources that they can trust, and doing various second and third order calculations on top of that in various ways.
The flip side is that this could make it extremely difficult to ‘break into’ the information space. You will have to build your credibility the same way you have to build your credit score.
Selling Your Chatbot Data
In case you did not realize, the AI companion (AI girlfriend and AI boyfriend and AI nonbinary friends even though I oddly have not heard mention of one yet, and so on, but that’s a mouthful ) aps absolutely 100% are harvesting all the personal information you put into the chat, most of them are selling it and a majority won’t let you delete it. If you are acting surprised, that is on you.
The best version of this, of course, would be to gather your data to set you up on dates.
Cause, you know, when one uses a chatbot to talk to thousands of unsuspecting women so you can get dates, ‘they’ say there are ‘ethical concerns.’
Whereas if all those chumps are talking to the AIs on purpose? Then we know they’re lonely, probably desperate, and sharing all sorts of details to help figure out who might be a good match. There are so many good options for who to charge the money.
The alternative is that if you charge enough money, you do not need another revenue stream, and some uses of such bots more obviously demand privacy. If you are paying $20 a month to chat with an AI Riley Reid, that would not have been my move, but at a minimum you presumably want to keep that to yourself.
An underappreciated AI safety cause subarea is convincing responsible companies to allow adult content in a responsible way, including in these bots. The alternative is to drive that large market into the hands of irresponsible actors, who will do it in an irresponsible way.
Selling Your Training Data
AI companion data is only a special case, although one in which the privacy violation is unusually glaring, and the risks more obvious.
Various companies also stand ready to sell your words and other outputs as training data.
Reddit is selling its corpus. Which everyone was already using anyway, so it is not clear that this changes anything. It turns out that it is selling it to Google, in a $60 million deal. If this means that their rivals cannot use Reddit data, OpenAI and Microsoft in particular, that seems like an absolute steal.
Artist finds out that Pond5 and Shutterstock are going to sell your work and give you some cash, in this case $50, via a checkbox that will default to yes, and they will not let you tell them different after the money shows up uninvited. This is such a weird middle ground. If they had not paid, would the artist have ever found out? This looks to be largely due to an agreement Shutterstock signed with OpenAI back in July that caused its stock to soar 9%.
I checked that last one. There is a box that is unchecked that says ‘block AI training.’
I am choosing to leave the box unchecked. Train on my writing all you want. But that is a choice that I am making, with my eyes open.
They Took Our Jobs
Why yes. Yes I do, actually.
Get Involved
Apart Research, who got an ACX grant, is hiring for AI safety work. I have not looked into them myself and am passing along purely on the strength of Scott’s grant alone.
Introducing
Lindy is now available to everyone, signups here. I am curious to try it, but oddly I have no idea what it would be useful to me to have this do.
Groq.com will give you LLM outputs super fast. From a creator of TPUs, they claim to have Language Processing Units (LPUs) that are vastly faster at inference. They do not offer model training, suggesting LPUs are specifically good at inference. If this is the future, that still encourages training much larger models, since such models would then be more commercially viable to use.
Podcaster copilot. Get suggested questions and important context in real time during a conversation. This is one of those use cases where you need to be very good relative to your baseline to be net positive to rely on it all that much, because it requires splitting your attention and risks disrupting flow. When I think about how I would want to use a copilot, I would want it to fact check claims, highlight bold statements with potential lines of response, perhaps note evasiveness, and ideally check for repetitiveness. Are your questions already asked in another podcast, or in their written materials? Then I want to know the answer now, especially important with someone like Tyler Cowen, where the challenge is to get a genuinely new response.
Claim that magic.dev has trained a groundbreaking model for AI coding, Nat Friedman is investing $100 million.
Intrinsically self-improving? Ut oh.
Altera Bot, an agent in Minecraft that they claim can talk to and collaboratively play with other people. They have a beta waitlist.
In Other AI News
Sam Altman seeks Washington’s approval to build state of the art chips in the UAE. It seems there are some anti-trust concerns regarding OpenAI, which seems like it is not at all the thing to be worried about here. I continue to not understand how Washington is not telling Altman that under no way in hell is he going to do this in the UAE, he can either at least friend-shore it or it isn’t happening.
Apple looking to add AI to iPad interface and offer new AI programming tools, but progress continues to be slow. No mention of AI for the Apple Vision Pro.
More on the Copyright Confrontation from James Grimmelmann, warning that AI companies must take copyright seriously, and that even occasional regurgitation or reproduction of copyrighted work is a serious problem from a legal perspective. The good news in his view is that judges will likely want to look favorably upon OpenAI because it offers a genuinely new and useful transformative product. But it is tricky, and coming out arguing the copying is not relevant would be a serious mistake.
Quiet Speculations
This is Connor Leahy discussing Gemini’s ability to find everything in a 3 hour video.
Slow is relative. It also could be temporary.
If world GDP doubles in the next four years without doubling in one, that is a distinct thing from historical use of the term ‘fast takeoff,’ because the term ‘fast takeoff’ historically means something much faster than that. It would still be ‘pretty damn fast,’ or one can think of it simply as ‘takeoff.’ Or we could say ‘gradual takeoff’ as the third slower thing.
I do not only continue to think that we not mock those who expected everything in AI to happen all at once with little warning, with ASI emerging in weeks, days or even hours, without that much mundane utility before that. I think that they could still be proven more right than those who are mocking them.
We have a bunch of visible ability and mundane utility now, so things definitely look like a ‘slow’ takeoff, but it could still functionally transform into a fast one with little warning. It seems totally reasonable to say that AI is rapidly getting many very large advantages with respect to humans, so if it gets to ‘roughly human’ in the core intelligence module, whatever you want to call that, then suddenly things get out of hand fast, potentially the ‘fast takeoff’ level of fast even if you see more signs and portents first.
More thoughts on how to interpret OpenAI’s findings on bioweapon enabling capabilities of GPT-4. The more time passes, the more I think the results were actually pretty impressive in terms of enhancing researcher capabilities, and also that this mostly speaks to improving capabilities in general rather than anything specifically about a bioweapon.
How will AIs impact people’s expectations, of themselves and others?
The Quest for Sane Regulations
Did you know that we already already have 65 draft bills in New York alone that have been introduced related to AI? And also Axios had this stat to offer:
That is quite a lot of bills. One should therefore obviously not get too excited in any direction when bills are introduced, no matter how good or (more often) terrible the bill might be, unless one has special reason to expect them to pass.
The governor pushing a law, as New York’s is now doing, is different. According to Axios her proposal is:
As for this particular law? I mean, sure, all right, fine? I neither see anything especially useful or valuable here, nor do I see much in the way of downside.
Also, this is what happens when there is no one in charge and Congress is incapable of passing basic federal rules, not even around basic things like deepfakes and impersonation. The states will feel compelled to act. The whole ‘oppose any regulatory action of any kind no matter what’ stance was never going to fly.
Department of Justice’s Monaco says they will be more harshly prosecuting cybercrimes if those involved were using AI, similar to the use of a gun. I notice I am confused. Why would the use of AI make the crime worse?
Matthew Pines looks forward to proposals for ‘on-chip governance,’ with physical mechanisms built into the hardware, linking to a January proposal writeup from Aarne, Fist and Withers. As they point out, by putting the governance onto the chip where it can do its job in private, you potentially avoid having to do other interventions and surveillance that violates privacy far more. Even if you think there is nothing to ultimately fear, the regulations are coming in some form. People who worry about the downsides of AI regulation need to focus more on finding solutions that minimize such downsides and working to steer towards those choices, rather than saying ‘never do anything at all’ as loudly as possible until the breaking point comes.
European AI Office launches.
The Week in Audio
I’m back at The Cognitive Revolution to talk about recent events and the state of play. Also available on X.
The Original Butlerian Jihad
Who exactly is missing the point here, you think?
I asked Gemini Pro, Gemini Advanced, GPT-4 and Claude.
Everyone except Gemini Pro replied in the now standard bullet point style. Every point one was ‘yes, this is a cautionary tale against the dangers of AI.’ Gemini Pro explained that in detail, whereas the others instead glossed over the details and then went on to talk about plot convenience, power dynamics and the general ability to tell interesting stories focused on humans, which made it the clearly best answer.
Whereas most science fiction stories solve the problem of ‘why doesn’t AI invalidate the entire story’ with a ‘well that would invalidate the entire story so let us pretend that would not happen, probably without explaining why.’ There are of course obvious exceptions, such as the excellent Zones of Thought novels, that take the question seriously.
Rhetorical Innovation
It’s been a while since we had an open letter about existential risk, so here you go. Nothing you would not expect, I was happy to sign it.
In other news (see last week for details if you don’t know the context for these):
Meanwhile:
Public Service Announcement
This does tie back to AI, but also the actual core information seems underappreciated right now: Lukas explains that illegal drugs are now far more dangerous, and can randomly kill you, due to ubiquitous lacing with fentanyl.
They have never been a good idea, drugs are bad mmmkay (importantly including alcohol), but before fentanyl using the usual suspects in moderation was highly unlikely to kill you or anything like that.
Now, drug dealers can cut with fentanyl to lower costs, and face competition on price. Due to these price pressures, asymmetric information, lack of attribution and liability for any overdoses and fatalities, and also a large deficit in morals in the drug dealing market, a lot of drugs are therefore cut with fentanyl, even uppers. The feedback signal is too weak. So taking such drugs even once can kill you, although any given dose is highly unlikely to do so. And the fentanyl can physically clump, so knowing someone else took from the same batch and is fine is not that strong as evidence of safety either. The safety strips help but are imperfect.
As far as I can tell, no one knows the real base rates on this for many obvious reasons, beyond the over 100,000 overdose deaths each year, a number that keeps rising. It does seem like it is super common. The DEA claims that 42% of pills tested for fentanyl contained at least 2mg, a potentially lethal dose. Of course that is not a random sample or a neutral source, but it is also not one free to entirely make numbers up.
Also the base potency of many drugs is way up versus our historical reference points or childhood experiences, and many people have insufficiently adjusted for this with their dosing and expectations.
Connor Leahy makes, without saying it explicitly, the obvious parallel to AGI.
[reply goes into a lot more detail]
The producer of the AGI gets rewarded for taking on catastrophic or existential risk, and also ordinary mundane risks. They are not responsible for the externalities, right now even for mundane risks they do not face liability, and there is information asymmetry.
Capitalism is great, but if we let capitalism do its thing here without fixing these classic market failures, they and their consequences will get worse over time.
People Are Worried About AI Killing Everyone
This matches my experience as well, the link has screenshots from The Making of the Atomic Bomb. So many of the parallels line up.
The basics are important. I agree that you can’t know for sure, but if we do indeed do this accidentally then I do not like our odds.
If you do create God, do it on purpose.
Other People Are Not As Worried About AI Killing Everyone
Roon continues to move between the camps, both worried and not as worried, here’s where he landed this week:
Sometimes one asks the right questions, then chooses not to care. It’s an option.
I continue to be confused by this opinion being something people actually believe:
Let’s try this again. If we have AI that can automate most jobs within 3 years, then at minimum we hypercharge the economy, hypercharge investment and competition in the AI space, and dramatically expand the supply while lowering the cost of all associated labor and work. The idea that AI capabilities would get to ‘can automate most jobs,’ the exact point at which it dramatically accelerates progress because most jobs includes most of the things that improve AI, and then stall for a long period, is not strictly impossible, I can get there if I first write the conclusion at the bottom of the page and then squint and work backwards, but it is a very bizarre kind of wishful thinking. It supposes a many orders of magnitude difficulty spike exactly at the point where the unthinkable would otherwise happen.
Also, a reminder for those who need to hear it, that who is loud on Twitter, or especially who is loud on Twitter within someone’s bubble, is not reality. And also a reminder that there are those hard at work trying to create the vibe that there is a shift in the vibes, in order to incept the new vibes. Do not fall for this.
Yeah, no, absolutely nothing has changed. Did Brown observe this at all? Maybe he did. Maybe he didn’t. If he did, it was because he self-selected into that corner of the world, where everyone tries super hard to make fetch happen.
The Lighter Side
SMBC has been quietly going with it for so long now.
Roon is correct. We try anyway.