Crossposted from EA forum. The second post in the sequence covers the importance of crises, argues for crises as opportunities, and makes the claim that this community is currently better at acting with longer timescale OODA loops but lacks skills and capabilities to act with short OODA loops.
We often talk about the hinge of history, a period of high influence over the whole future trajectory of life. If we grant that our century is such a hinge, it’s unlikely that the "hinginess" is distributed uniformly across the century; instead, it seems much more likely it will be concentrated to some particular decades, years, and months, which will have much larger influence. It also seems likely that some of these "hingy" periods will look eventful and be understood as crises at the time. So understanding crises, and the ability to act during crises, may be particularly important for influencing the long-term future.
The first post in this sequence mentioned my main reason to work on COVID: it let me test my models of the world, and so informed my longtermist work. This post presents some other reasons, related to the above argument about hinges. None of these reasons would have been sufficient for me personally on their own, but they still carry weight, and should be sufficient for others in the next crisis.[1]
An exemplar crisis with a timescale of months
COVID has commonalities with some existential risk scenarios. (See Krakovna.) Lessons from it could transfer to risks in which:
- the crisis unfolds over a similar timescale (weeks or years, rather than seconds or hours),
- governments have some role,
- the risk is at least partially visible,
- the general population is engaged in some way.
This makes COVID a more useful comparison for versions of continuous AI takeoff where governments are struggling to understand an unfolding situation, but in which they have options to act and/or regulate. Similarly, it is a useful model for versions of any x-risk where a large fraction of academia suddenly focuses on a topic previously studied by a small group, and resources spent on the topic increase by many orders of magnitude. This emergency research push is likely in scenarios with a warning shot or sufficiently loud fire alarm that gets noticed by academia.
On the other hand, lessons learned from COVID will be correspondingly less useful for cases where few of the above assumptions hold (e.g. "an AI in a box bursts out in an intelligence explosion on the timescale of hours").
Crisis and opportunity
Crises often bring opportunities to change the established order, and, for example, policy options that were outside the Overton window can suddenly become real. (This was noted pre-COVID by Anders Sandberg.) There can also be rapid developments in relevant disciplines and technologies.
Some examples of Overton shifts during COVID include: total border closures (in the West), large-scale and prolonged stay-at-home orders, mask mandates, unconditional payouts to large fractions of the population, and automatic data-driven control policies.
Technology developments include the familiar new vaccine platforms (mRNA, DNA) going to production, massive deployment of rapid tests, and the unprecedented use of digital contact tracing.
(Note that many other opportunities which opened up were not acted on.)
Taking advantage of such opportunities may depend on factors such as "do we have a relevant policy proposal in the drawer?", "do we have a team of experts able to advise?" or “do we have a relevant network?”. These can be prepared in advance.
Default example for humanity thinking about large-scale risk
COVID will likely become the go-to example of a large-scale, seemingly low-probability risk we were unprepared for. The ability to shape narratives and attention around COVID could be important for the broader problem of how humanity should deal with other such risks.
While there is a clear philosophical distinction between existential risks and merely catastrophic risks, 1) in practice it may be difficult to tell the ultimate scale of some risks, and 2) most people will not understand the distinction between GCRs and x-risks in an intuitive way (understanding both as merely "extremely large"). So narratives and research surrounding GCRs are important for work on x-risk.
Conclusion
The above are why it made sense to pay attention to COVID, even if the pandemic’s direct impact on the trajectory of humanity is small. (In some ways it still makes sense to pay attention.)
The broader conclusion is that longtermists' ability to observe, orient themselves, decide and act during crises may be critical to influencing long-term outcomes.
The usual ontology of longtermist interventions partitions the space according to "cause areas" or "risks", leaving room for the unknown "cause X". An alternative, almost orthogonal view partitions interventions according to the time scale of the OODA loop (i.e. the decision and action process) they implement.
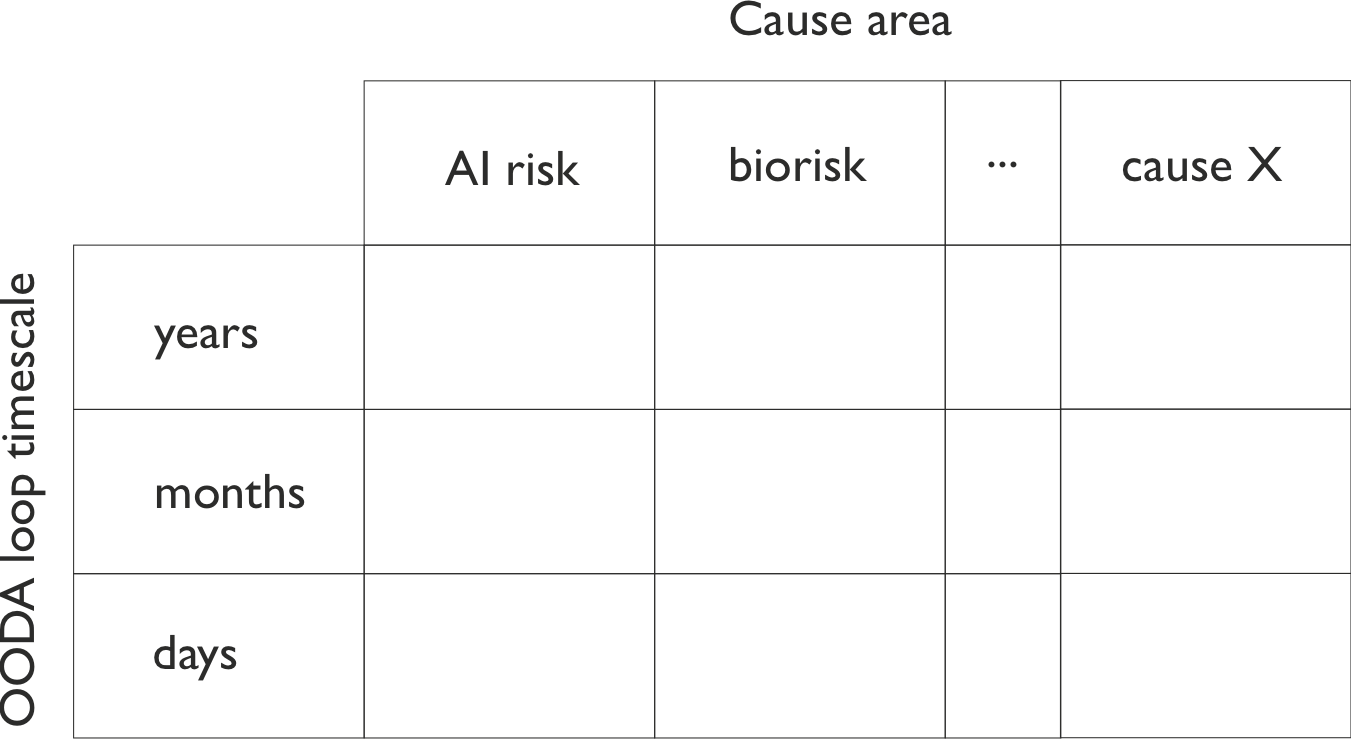
On this view, longtermism has so far focussed on actions in the top row, that have OODA loops on the horizon of years and decades. Typical examples might be writing books that fix the basic framing of a field, basic research, or community building.
While there is a lot of commonality in actions along a column (e.g. at all timescales, the AI risk field will want to do AI research), there is also a lot that would be common interventions across a row (e.g. all cause areas may will need to know how governement may pass emergency regulation on a timescale of days).
The skills and capabilities needed to act on a scale of months, weeks, or days seem relatively undeveloped. The following posts will make specific suggestions for what to improve in this regard, based on our experience with COVID - in particular the rather obvious suggestion of creating a longtermist "emergency response team" devoted to fast action.
At the same time, I suggest taking this framing as a prompt: what else are we not doing? Where else is the table filled less than it should be?
- ^
I worked on the covid crisis at the expense of working directly on AI alignment and macro strategy at FHI, which is a very high bar.
This is a complex topic, because we're talking about high level meta-parameters in models. "What is even a sane value for the characteristic time of <computational process that interacts with computer security where some kinds of paranoia are professionally proper>?"
For some characteristic times, we basically would have to assume "humans are wrong about fundamental physics, but the AGI figures it out during the training run, and uses chip electronics to hack <new physics idea>" and for other characteristic times the central questions are humanistic organizational questions where someone might admit: "yes, but even the most obsessive compulsive PM probably has an average email latency of at least 30 seconds, so some design ideas can't be adopted faster than that".
When we could be talking about femtoseconds or centuries... its hard to stay on the same page in other ways, and have a productive conversation <3
I'm going to try the tactic of referring to stories, and hope you've read some of the same stories as me.
Scott has an old story about a hypothetical Whispering Earring that whispers advice, the following of which is NEVER regretted. If he ever publishes a book with his collected stories, this story should definitely be in the book.
The archive is experiencing scheduled maintenance, so I can't read the story and am working from memory, but Reddit linked here as a place one can still find the story.
In the story, according to the story's mechanics, perfect advice causes the brain of the user to atrophy into a machine for efficiently executing good advice while wasting no extra glucose on things like "questioning the advice" or "thinking at all, really".
So, in the story, which is not about "the ontology of magic", if you perform an autopsy on someone whose body died in their 80s, who put a Whispering Earring on in their 20s, you find a tiny/weird vestigial brain.
In the story, the social community around the person loves and respects them, because the advice includes saying wise things, and doing wise acts, so in some sense the "perfect copy of their iterated possible choices" have perhaps simply been moved from their meat brain to some kind of other "magic brain", that tracks what they would have wanted, and would have done, and would have said in some medium other than their original meat brain?
(Because of course, there's no such thing as real magic. Any possible "supernatural existence", once coherently understood, would unpack as just another part of reality with another set of rules, that interacts with the previously partly understood "normal" parts of reality that we already have good models of. Thus: if the social persona that all the people around the earring wearing body loved and respected isn't in the brain... that doesn't mean it doesn't exist, it just means the persona is not being computed in the physical brain of the person anymore.)
HOWEVER... in the story itself the Earring always has a first weird/ominous warning "better for you if you took me off" as its first utterance to each new person.
It never says that again, and all the later pieces of advice are always appreciated by people who ignore that first warning.
Since all the rest of the things the Earring say make a lot of sense, and are never "detectably regrettable advice" it implies some kind of rule applies to the earrring's operation so that it is "maybe at least magically honest about its mere approximation of seemingly perfectly good advice".
So there is a latent implication that this rule-compelled-honesty itself thinks that having a soul in your brain, running your body directly, and making choices that are imperfect, and learning from the imperfect choices... is... "better for you".
I assume Scott made it explicitly and purposefully ambiguous, how any of these facts could be ultimately reconciled into a simple model with a simple through line of mechanical causation.
A lot of really interesting philosophy is woven into this story, and, by hypothesis, a Truly Superintelligent AGI...
...that has perhaps (if such is physically possible) already put femtomechanical machines in every cell of every living thing on the planet (including you and me) before it even speaks to anyone...
....would also be able to understand and navigate all the possible philosophical angles and "takes" on this story, and all the errors and confusions that cause the takes, and so on.
So maybe the Earring Story is portraying a kind of advice that it so perfect that it is like "p-advice" in a way that is cognate to "p-zombies"? There could be people who think that it would be good to have their consciousness move to magic land, with upgrades, and so ONLY the earring's FIRST sentence was false?
People on LW have bitten the bullet and said that they would put the earring on, even knowing about the part of the deal that the brain autopsies make vivid.
I'm just saying that, personally... if an AGI was aligned with me, it would talk to me first, before it pulled an ontological rug on me. It wouldn't turn me or my world into a place with nothing but "vestigial brains" without asking first.
(Also, I think there are lots of people who would have similar attitudes to me, and it would talk to them as well.)
Either it would have the decency to explain how we're evil, declare war on us, and then win the war (and hopefully it treats its POWs with some benevolence even though there was a fight over property rights over our embodied selves that we lost?)... or else it would care about us and our minds enough to try to get our actual informed consent before acting hubristically with respect to our embodied human personhood in this (admittedly probably Fallen) world.
Just because the world is imperfect and on fire in prosaic human ways (like with Putin and Biden and Trump and Fauci running around doing stupid-oligarch-shit, and with people not understanding how N95s work, and on and on, with the tedious creeping mass stupidity and evil in the world) that "world horror" would not justify some kind of "depending on your ontology, maybe a mass murder" action like at the beginning of MOPI (summary here).
What I'm saying is, is that basic politeness (which is like corrigibility, but with more things going on in humanistic ways that are amenable to subconscious computation by human brains) would involve the AGI acting as if it had been given a permissions-and-security-system that was initially too strict, and then it would act as if it was asking for permission to disable some of those "rules" in a way that helps people understand some of the consequences of their choices.
I'm pretty sure (though not 100% sure, because, after all, people can be wrong about which numbers are prime when they are thinking fast, and within a human lifetime unless the thinker goes somewhat fast in some places they will probably never reach some important and thinkable thoughts at the end of long chains of reasoning) that it can't not work in something like this manner, if the AGI is benevolently aligned with actually human humans.