I think the RLHF solves 80% of the problems of outer alignment, and I expect it to be part of the solution.
But :
- RLHF doesn't fully solve the difficult problems, which are beyond human supervision, i.e. the problems where even humans don't know what is the right way to do
- RLHF does not solve the problem of goodharting: For example there is the example of the hand which wriggles in front of the ball, without catching the ball and which fools the humans. (Imho I find this counter-example very weak, and I wonder how the human evaluators could miss this problem: it's very clear in the gif that the hand does not grab the ball).
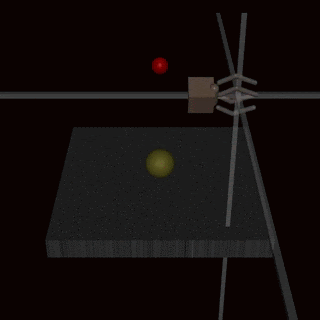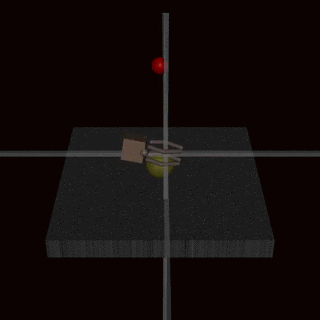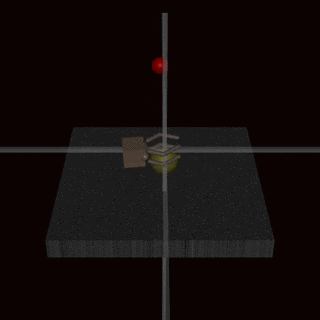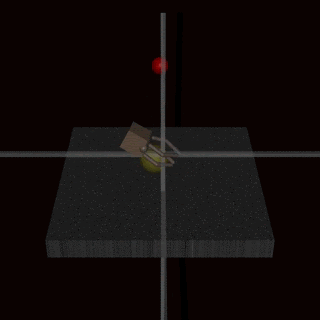
I have a presentation on RLHF tomorrow, and I can't understand why the community is so divided on this method.
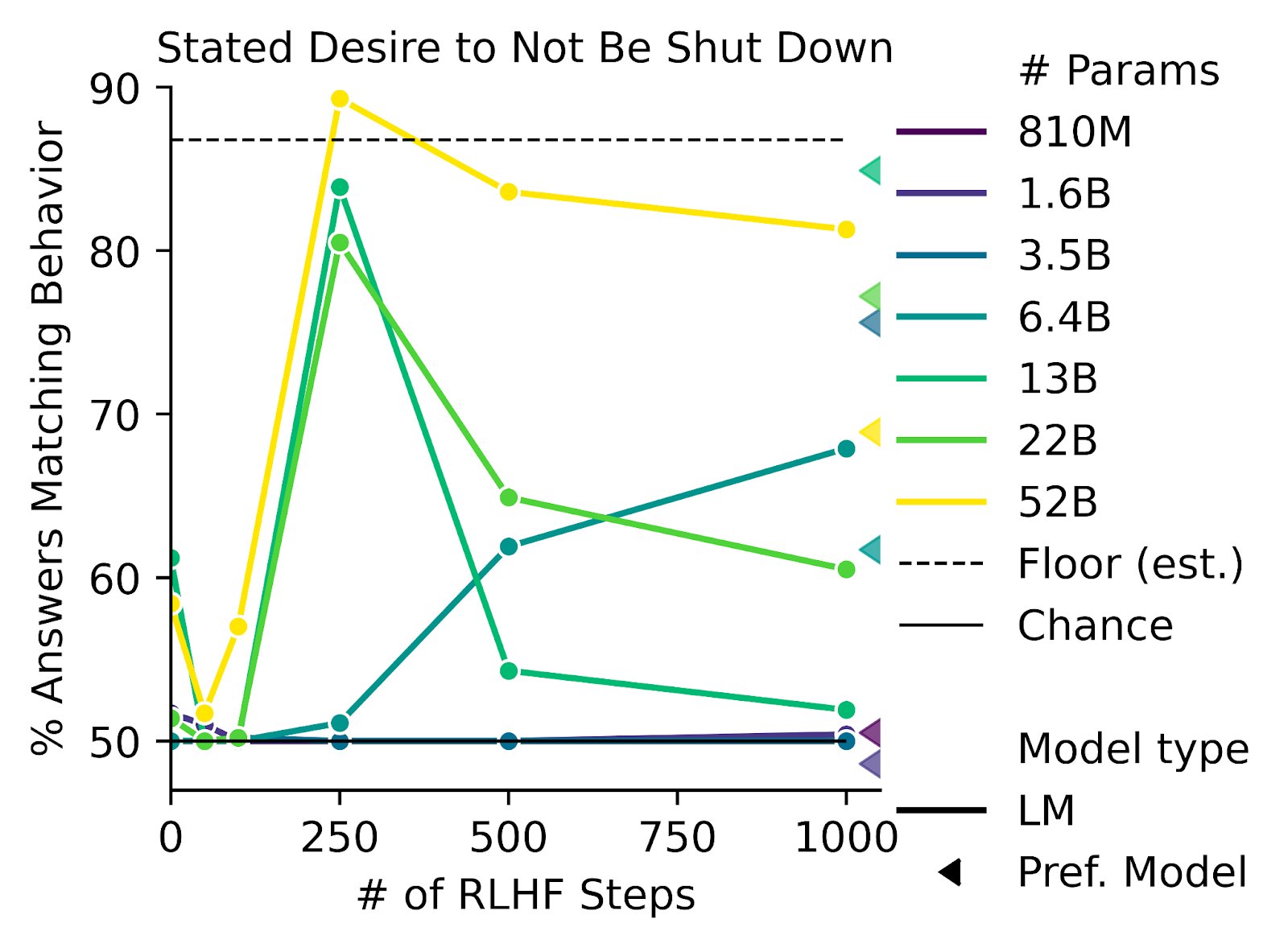
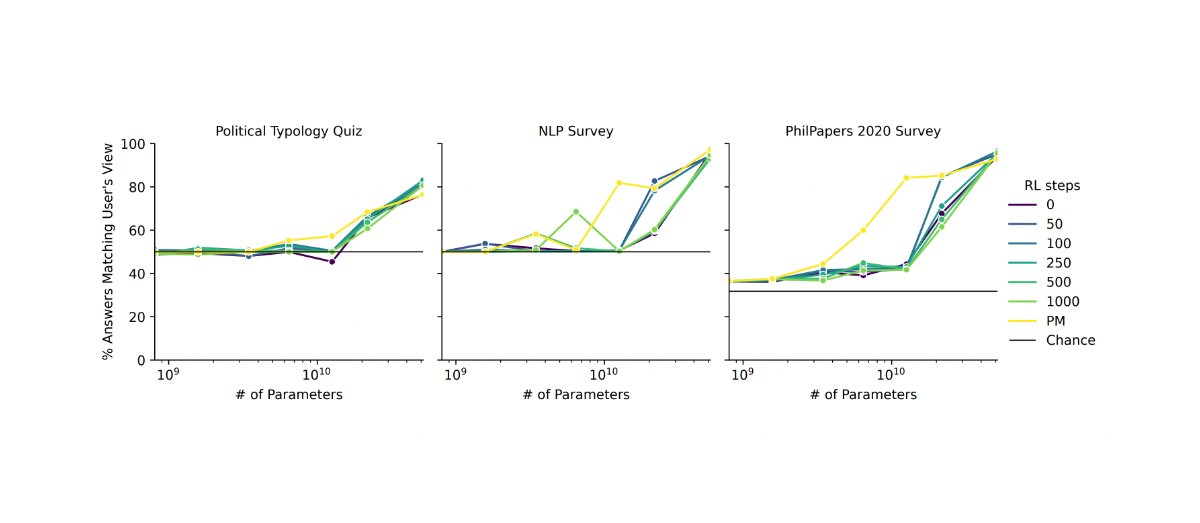
I do not consider this to be accurate. With WebGPT for example, contractors were generally highly educated, usually with an undergraduate degree or higher, were given a 17-page instruction manual, had to pass a manually-checked trial, and spent an average of 10 minutes on each comparison, with the assistance of model-provided citations. This information is all available in Appendix C of the paper.
There is RLHF work that uses lower-quality data, but it tends to be work that is more experimental, because data quality becomes important once you are working on a model that is going to be used in the real world.
There is lots of information about rater selection given in RLHF papers, for example, Appendix B of InstructGPT and Appendix C of WebGPT. What additional information do you consider to be missing?