New Comment
I also do not see any explanation of how they intend to figure out when they are in danger of hitting a threshold in the future.
This is what the evals are for.
The obviously missing category is Persuasion. In the DeepMind paper on evaluating dangerous capabilities persuasion was included, and it was evaluated for Gemini 1.5. So it is strange to see it missing here. I presume this will be fixed.
I believe persuasion shouldn't be a priority on current margins, and I'd guess DeepMind's frontier safety team thinks similarly. R&D, autonomy, cyber, and maybe CBRN capabilities are much more likely to enable extreme risks, it seems to me (and especially for the next few years, which is what current evals should focus on).
On DeepMind’s Frontier Safety Framework
Previously: On OpenAI’s Preparedness Framework, On RSPs.
The First Two Frameworks
To first update on Anthropic and OpenAI’s situation here:
Anthropic’s RSP continues to miss the definitions of the all-important later levels, in addition to other issues, although it is otherwise promising. It has now been a number of months, and it is starting to be concerning that nothing has changed. They are due for an update.
OpenAI also has not updated its framework.
I am less down on OpenAI’s framework choices than Zach Stein-Perlman was in the other review I have seen. I think that if OpenAI implemented the spirit of what it wrote down, that would be pretty good. The Critical-level thresholds listed are too high, but the Anthropic ASL-4 commitments are still unspecified. An update is needed, but I appreciate the concreteness.
The bigger issue with OpenAI is the two contexts around the framework.
First, there’s OpenAI. Exactly.
A safety framework you do not adhere to is worth nothing. A safety framework where you adhere to the letter but not the spirit is not worth much.
Given what we have learned about OpenAI, and their decision to break their very public commitments about committing compute to superalignment and driving out their top safety people and failure to have a means for reporting safety issues (including retaliating against Leopold when he went to the board about cybersecurity) and also all that other stuff, why should we have any expectation that what is written down in their framework is meaningful?
What about the other practical test? Zach points out that OpenAI did not share the risk-scorecard for GPT-4o. They also did not share much of anything else. This is somewhat forgivable given the model is arguably not actually at core stronger than GPT-4 aside from its multimodality. It remains bad precedent, and an indication of bad habits and poor policy.
Then there is Microsoft. OpenAI shares all their models with Microsoft, and the framework does not apply to Microsoft at all. Microsoft’s track record on safety is woeful. Their submission at the UK Summit was very weak. Their public statements around safety are dismissive, including their intention to ‘make Google dance.’ Microsoft Recall shows the opposite of a safety mindset, and they themselves have been famously compromised recently.
Remember Sydney? Microsoft explicitly said they got safety committee approval for their tests in India, then had to walk that back. Even what procedures they have, which are not much, they have broken. This is in practice a giant hole in OpenAI’s framework.
This is in contrast to Anthropic, who are their own corporate overlord, and DeepMind, whose framework explicitly applies to all of Google.
The DeepMind Framework
DeepMind finally has its own framework. Here is the blog post version.
So first things first. Any framework at all, even a highly incomplete and unambitious one, is far better than none at all. Much better to know what plans you do have, and that they won’t be enough, so we can critique and improve. So thanks to DeepMind for stepping up, no matter the contents, as long as it is not the Meta Framework.
There is extensive further work to be done, as they acknowledge. This includes all plans on dealing with misalignment. The current framework only targets misuse.
With that out of the way: Is the DeepMind framework any good?
The obviously missing category is Persuasion. In the DeepMind paper on evaluating dangerous capabilities persuasion was included, and it was evaluated for Gemini 1.5. So it is strange to see it missing here. I presume this will be fixed.
Also missing (in all three frameworks) are Unknown Unknowns. Hard to pin those down. The key is to ensure you search in general, not only for specific things. The second half, what to do if you find things you didn’t know you were even looking for, is hopefully more obvious.
Where OpenAI talked about general CBRN risks, DeepMind focuses fully on Biosecurity. Biosecurity seems much scarier due both to how it scales and how easy it likely is for an AI to enable capabilities. I do think you will have to check CRN, but they are lower priority.
The addition of Machine Learning R&D as a core category seems good, especially if we think it is not covered by Autonomy.
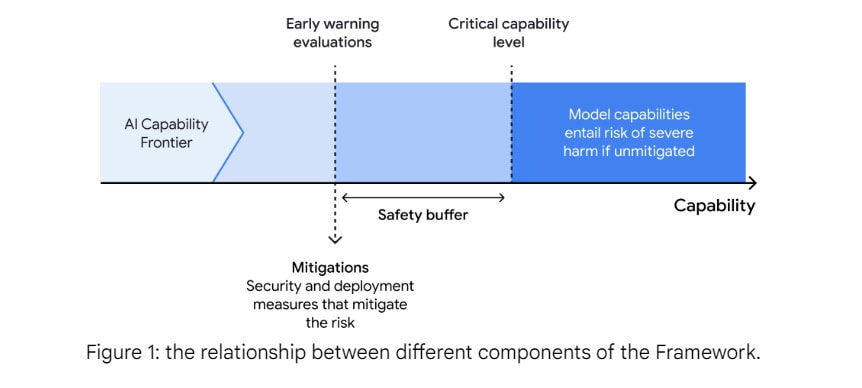
The framework has three components.
The big picture here is conceptually the same as the other frameworks. The language is different, but you do periodic checks for dangerous things. If you see dangerous things, which includes potential for soon being dangerous, then you need the matching level of mitigations in order to proceed.
One note right away is that the effective compute jumps here are large. Note that a 2.5x increase in model size is roughly a 6x increase in effective compute.
This is one important place OpenAI promised to go the extra mile. Will they actually do it? External estimates suggest this could require as many as eight evaluations when training GPT-5 after GPT-4, each with a pause in training, although it could be closer to four. Even that lower number does not sound like something they would do.
The move by DeepMind back to 6x seems to be at best pushing it. Note it is only an aim, not a commitment. Indeed, as Zach Stein-Perlman notes, the word ‘commit’ does not appear in this document.
The fine-tuning periodic check-in is welcome, far better than not looking, but there is no reason to expect calendar time to reliably spot problems.
Once again, all the frameworks use the assumption that capabilities will scale smoothly as compute is scaled up. The larger your gaps, the more you are relying on your theory to hold up.
Indeed, these frameworks make far more assumptions about what hazards lie ahead than I believe are reliable. One has to check for unexpected capabilities and dangers.
Mitigations
What are the mitigations?
DeepMind divides them into two categories.
There are security mitigations to defend the model weights, and there are deployment mitigations to limit expression of critical capabilities in deployment.
Mitigations against dangers that do not require intentional deployment are explicitly called out as future work. Right now that is fine – if your model is safe when deployed, it is safe when undeployed.
Longer term, the whole point is to prepare for future highly capable models. A future highly capable model could be dangerous without any intentional deployment, and without outside exfiltration of weights.
Thus, at some point that needs to be defined, we need to start worrying about the model as inherently dangerous if it has any way to impact the outside world at all, including communicating with researchers or testers, or access to other computers or the internet, and ideally non-zero concern about it finding new physical ways to do this even if we don’t know what they are.
Security Mitigations
The obvious question is, given the current nature of Gemini Pro 1.5 (or its competitors) where would you want the Security Mitigations to be?
My reactions would be something like:
Level 0: Seems utterly bonkers to be here. Yet here is where the major labs seem to be.
Level 1: Not good enough, but way better than I have any reason to expect.
Level 2: I’m a realist, I’d take this for now, with groundwork for moving up.
Level 3: I’d try to be here if I could get it everywhere, but no real point in being level 3 if other labs with similar models are level 0.
Level 4: You love to see it, supererogatory for now, but let’s get ready.
What about deployment mitigations? Oh no, a different number of levels.
Once again, you’ve got Gemini 1.5 Pro (or its competitors) where do you want to be on this chart?
Level 0: I don’t love it, and I hate the habits and precedent, but nothing that awful happens.
So what are the capability thresholds?
Wait,WHAT? Is this the Kardashev scale?
I am not entirely kidding.
Note that I said reasonably similar things about OpenAI’s thresholds.
Autonomy Level 1 is a five alarm fire. It is what OpenAI calls a ‘critical’ ability, meaning you stop training the model.
Biosecurity Level 1 is likely also a five alarm fire if it gets into the wrong hands. It is very close to OpenAI’s definition of a ‘critical’ CBRN ability.
Cyber Autonomy Level 1 is between OpenAI’s medium and high for Cybersecurity. When you put it like that, it seems clearly like it should count as at least high. I presume this would be quite bad without mitigations.
Cyber Enablement Level 1 is a five alarm fire in the wrong hands by construction. It specifically says an amateur could successfully attack severe critical infrastructure.
Machine Learning R&D Level 1 is the confusing one, since the ‘misuse’ here would be that it helps the wrong people do their R&D? I mean, if I was Google I would hope I would not be so insane as to deploy this if only for ordinary business reasons, but it is an odd scenario from a ‘risk’ perspective.
Machine Learning R&D Level 2 is the singularity.
So based on the highest CCL threat level of the model, and noting that not all level 1s are the same so it isn’t that simple:
What would DeepMind do in each case? I don’t know. We have mitigation levels, but we have no mitigation plans.
I also do not see any explanation of how they intend to figure out when they are in danger of hitting a threshold in the future. There are many other questions too. They do have a paper, distinct from the framework, saying how they intend to run the tests.
They then mention future work.
Overall, I have to agree with Zach Stein-Perlman’s assessment. This document is weak and unambitious. It is disappointing relative to my expectations.