Thanks to everyone who commented, I tried to make a few more fake graphs to capture the disagreements:
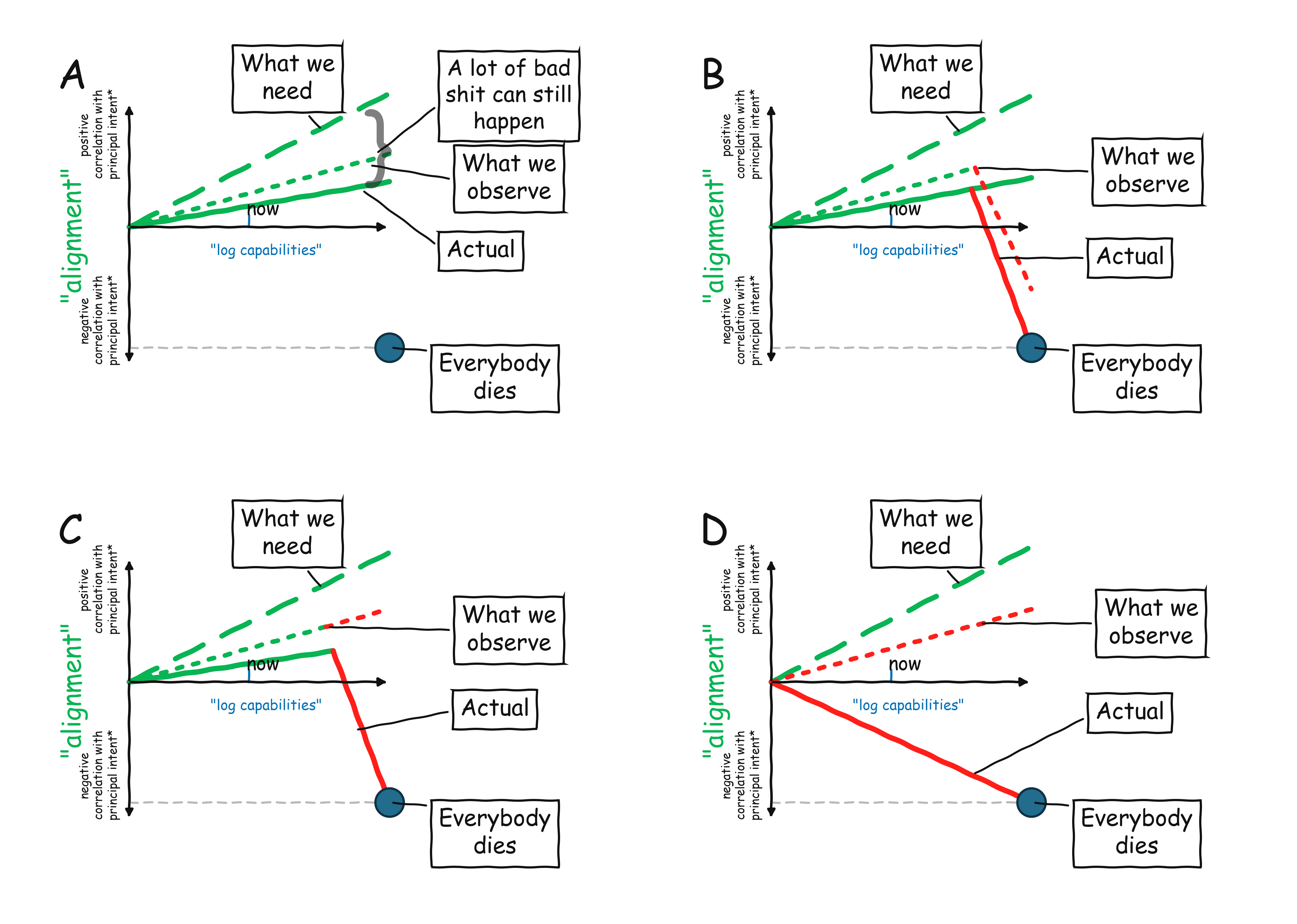
I don't want to make things very formal, but let's imagine "alignment" as the models generally following the intent of their generalized prompt (including things like constitution, policy, instructions from system/developer etc..). If the models follow a proxy that is related to the prompt but not really what we wanted (e.g. models express a confident answer when they are not really confident, or find a loophole instead of solving the actual task) then we think of them as somewhat misaligned. If a model is covertly following its own long term goals (e.g. a monitor model colluding with another model to sabotage safety training) then they are completely misaligned.
The dot at the bottom right corner is what happens if models satisfy the combination of (1) being extremely capable and (2) extremely misaligned. It is not the only way catastrophic things can happen. In particular, instruction following models can be used by bad people. Also even "small" misalignment can matter a lot when models are deployed in high stakes situations.
In my fake graphs I basically posited that we are in graph A, though it could be the case that we will be in B, and we need to constantly watch out for that. While our observability methods and evaluations are not perfect - monitoring in deployment can miss stuff and eval-awareness is a concern - they are not completely useless either. So there are some error bars wihch lead a gap between observed alignment and actual alignment, but it is not an unbounded gap.
I think some people's objection is that we are in scenario C: when the models will become more capable, they will start developing long term goals, and stop trying to follow the prompts, but will be smart enough that we don't notice it. And other people's concerns are that we are in scenario D- models already have long term misaligned goals that they follow, but they are just good at hiding it, and we will only discover it after it's too late).
I am sure 4 scenarios don't capture all option, but I hope this can focus the disagreements.
In my fake graphs I basically posited that we are in graph A, though it could be the case that we will be in B, and we need to constantly watch out for that. While our observability methods and evaluations are not perfect - monitoring in deployment can miss stuff and eval-awareness is a concern - they are not completely useless either. So there are some error bars wihch lead a gap between observed alignment and actual alignment, but it is not an unbounded gap.
I wouldn’t be confident OpenAI can claim they’d catch this with monitoring given that OpenAI doesn’t make the monitoring case in system cards (as in satisfying the preparedness framework for misalignment, where it’d have to presumably have substantial evidence). These graphs omit the hard part of the problem even in worlds where you get some signal via iterative deployment, which is that labs can and will continue to iterate against observable misalignment, so over time, your model looks aligned no matter what.
Is your claim with B that it’s some world where you detect bad things but the lab does not apply any mitigations? Realistically I’d be surprised if you don’t expect tremendous pressure in that exact situation to apply “whatever you can to get the model to be usable again” even if you’re not confident you’ve resolved the underlying misalignment.
The plots state that their x axes show capabilities on log scale, but what scales were intended for the y axes?
We might expect that the y axes are on linear (untransformed) scale. However, this would imply that multiplicative increases in AI capability can be addressed safely by making only additive amounts of progress in alignment (dashed green line on plots).
In general, multiplicative outmatches additive. How can we be confident that additive alignment progress would be enough?
Alternatively, we could view y axes as being on log scale. Yet, then the gap between "actual" (solid green line) and "what we need" (dashed green line) can be much larger than visually apparent on the plots, especially for dates in the future, leaving a big space for the region helpfully labeled, "A lot of bad shit can still happen [here]."
Many people may feel we are in your scenario A under a log y axis, with a big gap between "actual" and "what we need" appearing in future if current trends persist. In particular, people with fragile world concerns may place more "Everybody dies" dots in that gap, considering how large it could be.
Thank you for the plots! I hope I did not misinterpret them.
I was deliberately vague, but I would say that some version of log Y axis might make sense, since as capability scale up by a factor 10, you want to reduce the probability of error by some factor C.
So, yes the reason why I said "a lot" in the "a lot of bad shit can happen" is that this gap could indeed bite us. It could be potentially ameliorated by people limiting how AI can be deployed in high-stakes setting or increasing investment in safety - this is basically what happened in other industries like aviation safety. But this is also where the fourth graph on societal readiness comes in
Thank you for explaining.
The societal readiness plot doesn't seem to have a log-ish y axis, considering the shapes of the trend lines.
If the alignment plots were also drawn without a log-ish y axis, then they might look as bad as the societal readiness plot or -- if not equally bad -- then at least substantially worse than they do now.
I'm questioning plotting decisions for fake plots ...I know. This may seem like splitting hairs. However, to me, there is a major difference between requiring linear vs. exponential power law improvement in alignment, to take us to "what we need".
I think this post is misleadingly optimistic and pretty strongly disagree with how “what we avoided” is presented:
One piece of good news is that we have arguably gone past the level where we can achieve safety via reliable and scalable human supervision, but are still able to improve alignment. Hence we avoided what could have been a plateauing of alignment as RLHF runs out of steam.
No one has argued that we wouldn’t be able to improve alignment or even that ”RLHF would run out of steam”. RLAIF has been around since 2022. Models also aren’t human level yet, so it’d be a strange claim that we wouldn’t be able to apply Reinforcement Learning From Human Preferences to teach them human preferences. Models do in fact learn to exploit even reliability gaps in human supervision (ex: Language Models Learn to Mislead Humans via RLHF, Expanding on what we missed with sycophancy). We are not yet in a regime where humans can’t provide supervision in the sense of a learning signal. If interpreting supervision to mean monitoring, current arguments (including OpenAI’s per system cards) rely on inability, and in fact don’t claim that monitoring satisfies the Misalignment High requirement (instead relying on lack of Long Range Autonomy capabilities, as measured by “TerminalBench2 and proxies” to argue that they don’t yet need to make that case).
This is related to the fact that we do not see very significant scheming or collusion in models, and so we are able to use models to monitor other models! This is perhaps the most important piece of good news on AI safety we have seen so far. […] But there is reason to hope this trend will persist.
As OpenAI’s own papers and posts note, even their own research is done in preparation for future more capable models. It is not a “trend” that we don’t see this in current models, and in fact I don’t know of any research that can be characterized as predicting some “constantly increasing from 0“ line.
Indeed, this has always been predicated on prequisites around capabilities / situational awareness, with various future long horizon training / other training changes making this potentially more likely. Insofar as there are predictions around this, they would predict that you run into this problem more in the future.
Overall this post seems to confuse current benchmark scores with progress on The Alignment Problem from a Deep Learning Perspective (OpenAI, Ngo, 2022).
Just came cross this tweet https://x.com/mattyglesias/status/2038760845845442800?s=20 "AI is bad at writing in roughly the sense that Brian Scalabrine was a bad basketball player" - I think this is over-stating it for writing, but definitely that is true for programming, likely many areas of math.
AI might not be "super human" but it dominates the typical human data labeler in many tasks, and in that sense we have passed the "RLHF plateau". This is also demonstrated by how often papers these days use LLMs as a judge.
"How often papers do something" shows convenience rather than reliability or capability - it's cheaper and more consistent to use an LLM judge, but it may be strictly inferior to a human and it'd still be used.
This is similar to my understanding. I feel a bit uncomfortable with the "scheming" graph though-- it feels like it should be possible to decompose scheming as the conjunction of several other capabilities and propensities. Suppose (scheming frequency) = (non-corrigiblity) * (AI has misaligned goals) * (AI evades behavioral guardrails) * (AI correctly reasons about its strategic position). Then if we see three of the components suddenly start increasing, we should be worried even if the 4th is flat and scheming frequency remains low.
In the "alignment" graph, there are also three reasons why we need more alignment effort at higher capabilities:
- Increased consequences of misalignment means we want to decrease frequency of misaligned behavior
- More capable AIs are given new affordances which existing alignment training may not generalize to
- AIs might tend to have higher frequency of misaligned behavior (or prerequisites thereof) as capability increases, due to RL incentivizing long-term goals or agents reflecting on their values or whatever
Re the scheming graph- curious what you think about the other scenarios I posted. I am not sure I completely agree with the decomposition- to me scheming means the AI having its own prompt-independent goals that it pursues covertly, rather pursuing goals that are not completely aligned but still related to the prompt that it was given.
There's an old gdoc from my time at OpenAI where I make a similar distinction, but I like it better: The distinction is between aligned, misaligned, and adversarially misaligned. Misaligned models that are not adverarially misaligned, are the in-between category; the Spec didn't internalize in all the right ways, so e.g. the AIs sometimes misbehave, or have drives or biases they aren't supposed to have. BUT, they aren't plotting against you; they aren't thinking seriously about how to prevent you from realizing they are misaligned; etc. Adversarially misaligned models, by contrast, are. They have become your adversary.
Note that with the right prompt and/or context, current models can become adversarially misaligned. But my best guess is that most of the time / for most prompts/contexts, current models are merely misaligned, not adversarially misaligned.
(A similar distinction occurs in humans; we might say for example "Alice is aligned on this issue; she agrees with our policy proposals and is working hard to help achieve them. Bob, by contrast, is not; he has his own agenda and doesn't really care about our issues that much. But at least he's happy to live and let live, and have honest conversations with us. Chris, though -- that bastard is our enemy. He's actively trying to block our policy proposals and he lied to us about this when we met him earlier."
I think this is a decent way to describe it. When models are just “misaligned,“ we can potentially increase reliability via having one model monitor or check the work of the other, since what the model does has some relation the the prompt it is given. When a model is adversarially misaligned then the monitor could completely ignore its prompt and collude with the model it’s supposed to be monitoring.
absolutely agree that higher capabilities means higher stakes and hence increased requirements on alignment!
I responded with a post: Product Alignment is not Superintelligence Alignment (and we need the latter to survive)
Simply put, I think alignment as used here and many other places is a conflation of two quite separate tech trees.
We see some good news in alignment - as models become more capable, they are also more aligned
I find it very scary that senior alignment researchers apparently don't understand the difference between detected misalignment and actual misalignment.
Do you believe current models have large amounts of undetected misalignment? I believe the trend that more capable models are also more aligned (see Leike's blog I linked) is not just in evaluations but also people's observations in their real world usage.
Do you believe current models have large amounts of undetected misalignment?
I believe that there's no way to reliably tell. I think "people's observations in their real world usage" is also the sort of evidence that can easily fail to detect misalignment even if it exists.
I predict that ASI trained using anything resembling current techniques would be catastrophically misaligned. I don't have a strong prediction about whether current-gen models are "actually" aligned. If I had to guess, I'd say they're not. This is very speculative but my guess would be that they have misaligned internal drives/goals that would produce bad consequences if they were smart enough to reason through the implications of their goals, but they're not smart enough to do that (or it might be more accurate to say that their long-term planning isn't good enough).
What I will say is I don't think it's reasonable to believe with (say) >90% confidence that current-gen models are "actually" aligned, because our understanding of what's going on with LLMs just isn't that reliable.
I should mention that I don't keep up with the vast majority of alignment research. There might be some convincing research about why the lack-of-detected-misalignment means there is genuinely no misalignment, and I just missed it; but my guess is if that research existed, then I would've heard about it (e.g. it would've gotten tons of upvotes on LessWrong, b/c that would be a really important finding). So when Leike claims that models are becoming more aligned, most of my subjective probability for why he said that is that he doesn't understand the difference between detected misalignment and actual misalignment.
A couple other relevant bits of evidence:
- AI psychosis. When you ask LLMs point blank if it's bad to induce AI psychosis, they say yes, and (AFAIK) there is no evidence that they're being deceptive, and yet they do it anyway. This is a case where (IIRC) recent models have gotten better (less psychosis-prone), but my guess is that training psychosis out of LLMs doesn't generalize to other forms of misalignment, and maybe in the next-gen models some new form of bad behavior will emerge.
- IMO the best evidence of bad behavior by LLMs is coming out of Palisade, not any AI company. This suggests that AI companies (who have way more resources and access) are not trying sufficiently hard to detect misalignment. The implication is that, if AI companies fail to detect misalignment, this is only weak evidence that the misalignment isn't there.
I think current AI systems are likely catastrophically misaligned, but instead of properly arguing for it here, I want to clear the much lower bar of making the position sound much less weird than it might at first. When I imagine a person to whom this position sounds weird, I imagine them saying sth like:
- "AIs are acting nicely in various contexts. They look nice in our evaluations, and they look nice to users in practice. Isn't it unlikely that they are really evil, hiding it, waiting to strike?"
While I think it's likely that current AI systems are catastrophically misaligned, I don't much feel like taking a position one way or the other about the "are really evil, hiding it, waiting to strike" part. I think the hypothetical interlocutor above is making a false equivalence. When I say current AI system are "catastrophically misaligned", what I have in mind is this:
- When someone sets up some initial AI system and lets it develop a lot (ie lets it do RSI)
[1]
, with anything like this that could be done in practice
[2]
, this doesn't go well for humans. I think that the default without strict regulation of AI development is: in the first 10 years after AGI (by which I mean AI that autonomously does conceptual research better than top humans), there will be a lot of development — like probably more development than there has been in total in all of history.
[3]
Like, after developing for a lot of "subjective time", the AI systems that come out of this development process would trivially be able to replace humans with whatever other processes from some vast number of options; the negentropy/[free energy]/atoms I'm currently using could probably be used to run
Maybe this at least makes it seem not weird to think that current AI systems are catastrophically misaligned. It's plausible we're just using the same words differently, but in that case I think my use better tracks the niceness-type property that really matters. Like, it ultimately matters whether our AIs will continue to protect us
this could be framed as asking the AI to develop a good successor; the initial setup might have some processes tasked with "solving alignment"; there might be multiple AIs involved doing different things, eg there can be monitors ↩︎
absent fundamental breakthroughs in alignment ↩︎
in practice, the only way to regulate this is by banning AGI or by having some AI(s) effectively take over the world and then self-regulate ↩︎
My guess is also that things will also naively be looking worse once we get to AIs that are actually able to do research autonomously, because these AIs will be less based on human imitation, they will be actually able to come up with new thinky-stuff (new words/concepts/ideas/methods etc), they will not have nice chains of thought, and they will be more trained on clearly inhuman things like doing math/coding/science/tech. ↩︎
it maybe also depends on what self-improvement affordances are made available to a human ↩︎
I agree they're "egregiously misaligned" in this sense, but it's also the case that this usage of the word goes very much against the grain of common usage.
The term "AI alignment" was originally meant to refer to AGI-ish/ASI-ish AIs. So, if one wants to extrapolate it to "lesser AIs", extrapolating it to either one of "well-behaving sub-AGI-ish/sub-ASI-ish AI" or "sub-AGI-ish/sub-ASI-ish AI that produces aligned AGI/ASI if one seeds an RSI with it" seems fine/valid, at least in isolation. Most people went for the former; you're arguing for the latter, I think, largely because those who went for the former generally tend to be inclined to think that the former somewhat strongly implies the latter, and the latter is what matters in the long run (if something RSI's into AGI/ASI).
Initially, I was going to say that I'm pessimistic about you/someone managing to change how people think about/understand "alignment" in this way (e.g., because it implies that most humans are "egregiously misaligned", as you say it yourself), but on some thought, I'm not sure. Pushing back in this way and insisting that "this is the meaning of 'alignment' that matters and that your meaning of 'alignment' does meaningfully imply it" might be productive for shifting people's attention to where it matters.
either one of "well-behaving sub-AGI-ish/sub-ASI-ish AI" or "sub-AGI-ish/sub-ASI-ish AI that produces aligned AGI/ASI if one seeds an RSI with it" seems fine/valid, at least in isolation. Most people went for the former ... those who went for the former generally tend to be inclined to think that the former somewhat strongly implies the latter, and the latter is what matters in the long run
There is a very popular framing coloring all thinking of some people where seriously engaging with technological developments that are not immediately actionable is seen as deeply unvirtuous, and so the thought is never allowed proper consideration. Future that is not immediate is the immediate future's responsibility, not your current self's responsibility, and it's irresponsible to be seriously concerned with it over the immediately actionable things you are working on, that you are directly affecting and need to get right.
Thus observable "alignment" of modern AIs, in the sense of their good behavior, is not just a reasonable disambiguation of "alignment", but the only one permitted by this stance. Being inclined to think that this helps in the long term doesn't influence the outcome of seriously thinking only about current behavior. The claim that only long term consequences of behavior under RSI and society-scale development is what ultimately matters is not permitted to be taken seriously, it's not the background assumption that justifies the focus on current behavior of modern AIs.
It's not that such people don't believe ASI is coming, or that it's coming in their own lifetime, but the epistemic distortion of seeing serious engagement with unactionable things as intolerably unvirtuous makes their thinking and behavior indistinguishable from that of people who really believe ASI can never happen. This distortion can be pierced by belief that ASI is imminent, but once it's plausibly a few years away it could as well be pure fiction. Exploratory engineering might also be helpful for detailed engagement, where assumptions of a thought experiment permit thinking. But outside the thought experiments these assumptions are then not going to be taken seriously as gesturing at the actual future that is virtuous to engage with as actual future.
assorted thoughts in response:
- I definitely want people to think more about what AIs would think and do over a lot of reflection/development, and when more powerful. People should think more about the effects of a mind. People should think of the AGI situation as us probably having to correctly determine the future via an extremely long causal chain. [1]
- I don't think it's weird to speak of values the way I'm speaking of values. I think people accept this sort of value-talk in other contexts. E.g. it's common for antirealists to think of ethical truths as being determined by some ideal reflection; e.g. the notion of CEV. I think people who in some contexts use "egregious misalignment" in this "egregious misbehavior in mundane situations" sense also sometimes make inferences as if they were using "misalignment" in the sense I suggest. That said, one could want to make a distinction between reflection and development-in-general, and certainly it makes sense to distinguish between more and less endorsed forms of development. I think I was somewhat sloppy with this in my first comment.
- I think it'd in principle be fine for some ideal beings to use words however. In practice, [people are stupid]/[thinking is difficult], and it's very natural to make the inference "the AI is egregiously misaligned"
Some people think they can avoid this difficulty by having a first mess-AI "solve alignment" and launch some sort of aligned ASI sovereign, with the first AI not being that weird. I think that to first order one should think of this as the original AI trying to determine the future via a bottleneck. And in real life, people would plausibly just let the AI self-improve with some monitoring lol, in which case it's not exactly a tight bottleneck. The original AI will also already be doing a lot of reflection and development. Also, there will be a long chain of causality after the ASI sovereign that needs to go right. (Also, in practice, instead of some clever scheme with boxed AIs solving alignment, we will probably just get some total mess with AIs deployed broadly, connected to the internet, plausibly just running AI labs. And there's the AIs breaking out, and there's fooming being fast, and there's not having much time to be careful.) ↩︎
"Catastrophically misaligned" and "catastrophically misaligned if we give them RSI capabilities far beyond what we can currently give them" are two very, very different claims, in my eyes.
I do appreciate you articulating that your "catastrophically misaligned" is a shorthand for the latter though.
I think that if we try to make sense of "what a current AI would do after reflecting+developing for a long time", that thing does not involve being nice to humans. I think it's still not nice to humans if we add the constraint "and the reflection/development process has to be basically [endorsed by the AI]/[good according to the AI]". I think it's pretty standard to take what you would do [after a lot of reflection + if you were more powerful] to reflect your values better than what you would do instinctively. So, if I'm right about what would happen given further (self-endorsed) development, it seems like a standard use of language (at least in alignment and in philosophy) + true to say current AIs are bad? I'd agree it is also pretty standard + [maybe true] to say "current AIs are good" in the sense that they mostly have pretty acceptable instinctive behaviors. This situation is pretty unfortunate, and maybe calls on us to start explicitly making this distinction. [1]
"Catastrophic misalignment" is a bad term, in addition to the reason I already gave in my comment, also because it could mean that this AI in fact would cause a catastrophe (without human help), which I don't think is true for current AIs. That said, I think that's prevented by capabilities, not by alignment — I think the closest thing to a current AI which is capable of causing a catastrophe would cause a catastrophe. I guess maybe one should say "misalignment sufficient for a catastrophic outcome if choosing the future were handed to the AI". ↩︎
much easier to prefix the term than to change it. it sounds like you're describing either superintelligence alignment (pass the threshold of working for any superint), or asymptotic alignment (an even more difficult threshold of being reliably known to continue working more or less indefinitely). achieving asymptotic alignment would require some form of knowing that the system would, in an ongoing way, continue to improve its ability to check in with us without breaking us, and use that information in ways we know are valid extrapolations according to what we want. which sounds like what you're describing, but importantly only gets its qualitative difference from the iteratedness. local alignment is still alignment, then, and that makes a lot of sense, since currently we train ais with locally linear-ish methods.
I believe the trend that more capable models are also more aligned
But the main problem has absolutely never been that models below human capabilities would be impossible to align. As made clear in the Superalignment announcement blog post the concern is that our current techniques won’t scale beyond this. This is clear from Concrete Problems In AI Safety, W2S’s entire agenda, etc.
To be fair, my comment was talking about current models, and that's what Boaz was responding to.
Not the OP and not an alignment researcher, but I would appreciate an elaboration. What types of evidence would you consider relevant for concluding that an AI system is (roughly) aligned, as opposed to merely being a system for which we have not yet detected misalignment?
I don't know what evidence would be sufficient to conclude that an AI system is aligned. That's part of the problem—we have no way of reliably detecting misalignment or ruling it out.
(Well, I can think of some evidence that would convince me, but it's not useful. E.g. if we build an ASI and it runs for a hundred years without killing everyone, then I'm pretty sure it's aligned. But I would recommend against running that experiment.)
Ok this is a bit of a tortured analogy but imagine it's the 1600s. We learn that if the mass of an iron atom is greater than 10⁻²³ grams, everyone dies (for some contrived reason). So we need to figure out the mass of iron. AI companies shave off the smallest scrap of iron they can manage, and put it on an era-appropriate balance scale, and the scale reads zero. And they declare, see! Iron is so light that it reads as zero!
Meanwhile I'm over here like, how do we know the scale is sensitive enough to measure the mass of a single iron atom? How do we know that that tiny little shaving only contains a single atom? What if it's actually several atoms, and it's possible to have an even smaller quantity of iron?
(Plus there are questions we don't even know we're supposed to be asking, like "which isotope of iron is this?")
In that scenario, if you ask me what evidence would convince me that an iron atom weighs less than 10⁻²³ grams, I wouldn't know what to tell you.
I feel like that's where we are currently with alignment research.
(This analogy doesn't capture the fact that measurable AI alignment is improving over time according to benchmarks. It's also over-generous in that we could prove that our scales aren't sensitive enough to detect a difference of 10⁻²³ grams. I don't think we can do anything analogous in the case of AI alignment.)
Folk concerned with AI x-risk routinely cite various forms of behavior observed in frontier AI models as evidence that the systems are, or will be, dangerously misaligned. For instance, less than 24 hours ago, MIRI released this short video, which claims that “today’s AI systems lie to their developers, exploit loopholes in their instructions, and resist being shut down.” Yet, from what you say, it appears that this evidence is mostly irrelevant, because “we have no way of reliably detecting misalignment or ruling it out”.
We can detect misalignment under some conditions but we don't know how to reliably detect it, i.e. avoid false negatives, i.e., we have no way of saying "if a system is misaligned in any way, then method XYZ will definitely detect it." There are special cases of misalignment that we do know how to detect.
By analogy: If I feel sick, and a test shows that my body contains a particular strain of flu virus, then I almost certainly have the flu. If the test returns a negative result, then I might still be infected with something else.
I don’t think Boaz‘s use of “scheming” here fits with even broad recent definitions, and from what I understand he would object to characterizing OpenAI model’s as having goals of their own, so I’m also confused by this.
I deliberately used quotes since I didn't want a single precise definition. But the general notion is covert pursuit of long term misaligned goals, as opposed to misalignment failures like hallucinations, reward hacking, etc.. that can be better understood as pursuing misspecified short term goals. (They are bad, but can be understood as doing something related to the prompt that was given, but not what we intended. But not pursuing something completely unrelated to the prompt.)
Scheming is the kind of thing that, for example, make it useless to have one model monitor another since they would both be colluding in pursuit of their long term goals.
So how is that all going to hold up when you start your 100k AI researchers later this year or do fully automated AI research soon after? If alignment will still hold up, who is going to verify what that nation of geniuses produces at superhuman speed? I think you are already optimistic in seeing any progress of alignment. There are clear discontinuities here: when are the models smarter than the researchers and can easily trick them, when can models do their own research all on their own, when do they have a meaningful shot at takeover or catastrophic risks? Hitting these discontinuities does not work well with a wait-and-see strategy.
Edit: I think there is an argument to be made that 1) something like RSI/handing off AI research will totally break what exists of AI alignment and 2) there are predictably big threshold effects in the future (https://www.lesswrong.com/posts/JqrZxQwmqmoCWXXxC/ai-can-suddenly-become-dangerous-despite-gradual-progress) such as when it gets smarter than human researchers – such that the AI can easily trick them – incremental alignment strategies won't survive. However, as it stands, I am not making this point very well here and it just sounds too much like sneering for my comfort when there are valuable things here.
So how is that all going to hold up when you start your 100k AI researchers later this year or do fully automated AI research soon after?
I have many feelings about what OpenAI is doing (and don't particularly like this post), but I don't want the comments on every research post to implicitly assume the authors are responsible for OpenAI corporate strategy, or even to assume it is setting OpenAI corporate strategy.
A more careful comment would be fine, but this is veering too much into "angrily yelling at each other" territory, so please don't do that.
That is OK. I think it is a valid question to ask how we will align armies of agents, and as I point out in the post, I actually agree it's not solved. I believe that there is some level of alignment we will get by having each one of the 100K researchers be aligned, and having aligned monitors etc.., but I also believe in "more is different" and that we will need to invest in explicit alignment methods for the multi-agent setting that are not focused on just model behavior on one prompt in isolation.
Here is a quick overview of my intuitions on where we are with AI safety in early 2026:
One might argue that current alignment is “good enough” for an automated alignment researcher, and the AIs can take it from here. I disagree. I do not believe that all alignment is missing is one clever idea. Rather, we need ways to productively scale up compute into improving intent-following, honesty, monitoring, multi-agent alignment. This work will require multiple iterations of empirical experiments. AI can assist us in these, but it will not be a magic bullet. Also, we cannot afford to wait for AI to solve alignment for us, since in the meantime it will keep getting deployed in higher and higher stakes (including capability research).
`