[Thanks to Steven Byrnes for feedback and the idea for section §3.1. Also thanks to Justis from the LW feedback team.]
Remember this?
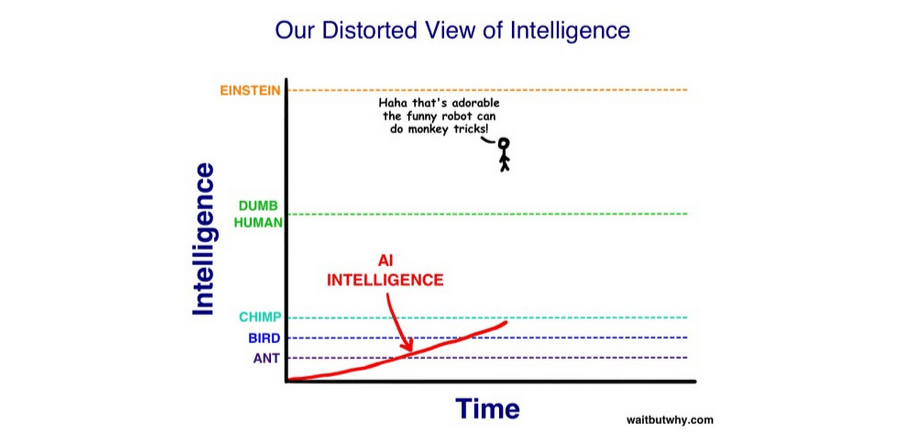
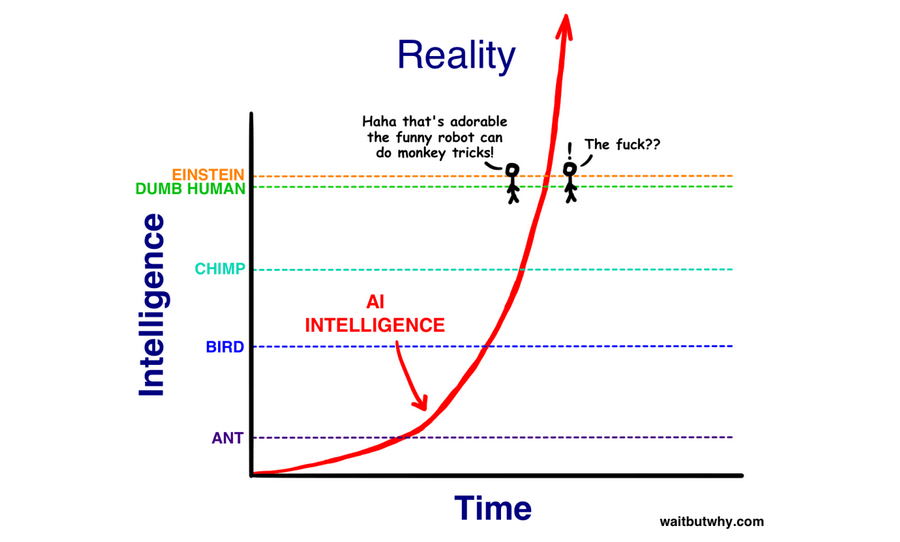
Or this?




The images are from WaitButWhy, but the idea was voiced by many prominent alignment people, including Eliezer Yudkowsky and Nick Bostrom. The argument is that the difference in brain architecture between the dumbest and smartest human is so small that the step from subhuman to superhuman AI should go extremely quickly. This idea was very pervasive at the time. It's also wrong. I don't think most people on LessWrong have a good model of why it's wrong, and I think because of this, they don't have a good model of AI timelines going forward.
1. Why Village Idiot to Einstein is a Long Road: The Two-Component Model of Intelligence
I think the human brain has two functionally distinct components for intellectual work: a thought generator module and a thought assessor module:
-
Thought Generation is the unconscious part of thinking, the module that produces the thoughts that pop into your head. You get to hear the end results but not what went into generating them.
-
Thought Assessment is the conscious part of thinking. It's about deliberate assessment. If you mull over an idea and gradually realize that it was worse than it initially seemed, that's thought assessment.
Large Language Models like GPT-3, Claude, GPT-4, GPT-4o, GPT-o1, GPT-o3, and DeepSeek do not have two functionally distinct components. They have a thought generator module, and that's it.
I'm not the first to realize this. Way back after GPT-2, Sarah Constantin wrote Humans Who Are Not Concentrating Are Not General Intelligences, making the point that GPT-2 is similar to a human who's tired and not paying attention. I think this is the central insight about LLMs, and I think it explains a lot of their properties. Like, why GPT-2 got the grammar and vibe of a scene right but had trouble with details. Or why all LLMs are bad at introspection. Why they have more trouble with what they said 30 seconds ago than with what's in their training data. Or why they particularly struggle with sequential reasoning (much more on that later). All of this is similar to a human who is smart and highly knowledgeable but just rattling off the first thing that comes to mind.
I think the proper way to think about human vs. LLM intelligence is something like this:
(Note that this doesn't mean LLMs have zero ability to perform thought assessment, it just means that they have no specialized thought assessor module. Whether they can achieve similar things without such a module is the million trillion dollar question, and the main thing we'll talk about in this post.)
My hot take is that the graphics I opened the post with were basically correct in modeling thought generation. Perhaps you could argue that progress wasn't quite as fast as the most extreme versions predicted, but LLMs did go from subhuman to superhuman thought generation in a few years, so that's pretty fast. But intelligence isn't a singular capability; it's two capabilities a phenomenon better modeled as two capabilities, and increasing just one of them happens to have sub-linear returns on overall performance.
Similarly, I think most takes stating that LLMs are already human level (I think this is the most popular one) are wrong because they focus primarily on thought generation, and likewise, most benchmarks are not very informative because they mostly measure thought generation. I think the most interesting non-AI-related insight that we can infer from LLMs is that most methods we use to discern intelligence are actually quite shallow, including many versions of the Turing Test, and even a lot of questions on IQ tests. If I remember correctly, most problems on the last IQ test I took were such that I either got the answer immediately or failed to answer it altogether, in which case thought assessment was not measured. There were definitely some questions that I got right after mulling them over, but not that many. Similarly, I think most benchmarks probably include a little bit of thought assessment, which is why LLMs aren't yet superhuman on all of them, but only a little bit.
So why should we care about thought assessment? For which types of tasks is it useful? I think the answer is:
2. Sequential Reasoning
By sequential reasoning, I mean reasoning that requires several steps that all depend on the previous one. If you reason where depends on and on and on , that's sequential reasoning. (We'll discuss an example in a bit.) On such a task, the human or LLM cannot simply guess the right answer in one take. As I said above, I think a surprising number of questions can be guessed in one take, so I think this is actually a relatively small class of problems. But it's also a hard requirement for AGI. It may be a small category, but both [progress on hard research questions] and [deception/scheming/basically any doom scenario] are squarely in it. AI will not kill everyone without sequential reasoning.
2.1 Sequential Reasoning without a Thought Assessor: the Story so Far
The description above may have gotten you thinking – does this really require thought assessment? A thought generator can read the problem description, output A, read (description , A), output B, read (description, A, B), output C, read (description, A, B, C), output D, and violà! This solves the problem, doesn't it?
Yes – in principle, all sequential reasoning can be bootstrapped with just a thought generator. And this is something AI labs have realized as well – perhaps not immediately, but over time.
Let's look at an example. This problem is hard enough that I don't think any human could solve it in a single step, but many could solve it with a small amount of thought. (Feel free to try to solve it yourself if you want; I'll jump straight into discussing reasoning steps.)
Seven cards are placed in a circle on the table, so that each card has two neighbors. Each card has a number written on it. Four of the seven cards have two neighbors with the same number. These four cards are all adjacent. The remaining three cards have neighbors with different numbers. Name a possible sequence of numbers for the seven cards.
At first glance, you may think that four adjacent cards all having the same neighbors means they have to be the same. So you may try a sequence of only 0s. But that can't work because creating four adjacent cards with identical neighbors this way actually requires six 0s, and 0-0-0-0-0-0-X implies that #7 also has the same neighbors, which violates the second criterion. Then you may realize that, actually, the same neighbor criterion just implies that #1 = #3 = #5 and #2 = #4, so perhaps an alternating sequence? Like 0-1-0-1-...? This is on the right track. Now a little bit of fine tuning, trying, or perhaps writing down exactly how much of the sequence must strictly alternate will probably make you realize that changing just one number to a third value does the trick, e.g., 0-1-0-1-0-1-2.
I think this problem is a good example because it (a) requires sequential reasoning and (b) probably won't pattern-match to a known problem in the literature, but it's also pretty easy[1] – probably about as easy as you can get while satisfying (a).
Let's look at how LLMs deal with this problem as a case study for performing sequential reasoning with only a thought generator. (Note that none of these examples are cherry-picked; I'm providing the first transcript I've gotten with every model for every example, and if I show another example, it's the second transcript.) Here's GPT-4 on 2023/04/17, before the Jun13 update:

Notice that (a) the answer is completely wrong, and (b) GPT-4 did not attempt to use sequential reasoning to obtain it. (It did repeat the problem statement, which this version did sometimes and not other times, but I would not count thas as attempting sequential reasoning.) It just guessed the answer immediately, and failed. Conversely, here's what GPT-4 responded after the Jun13 update:
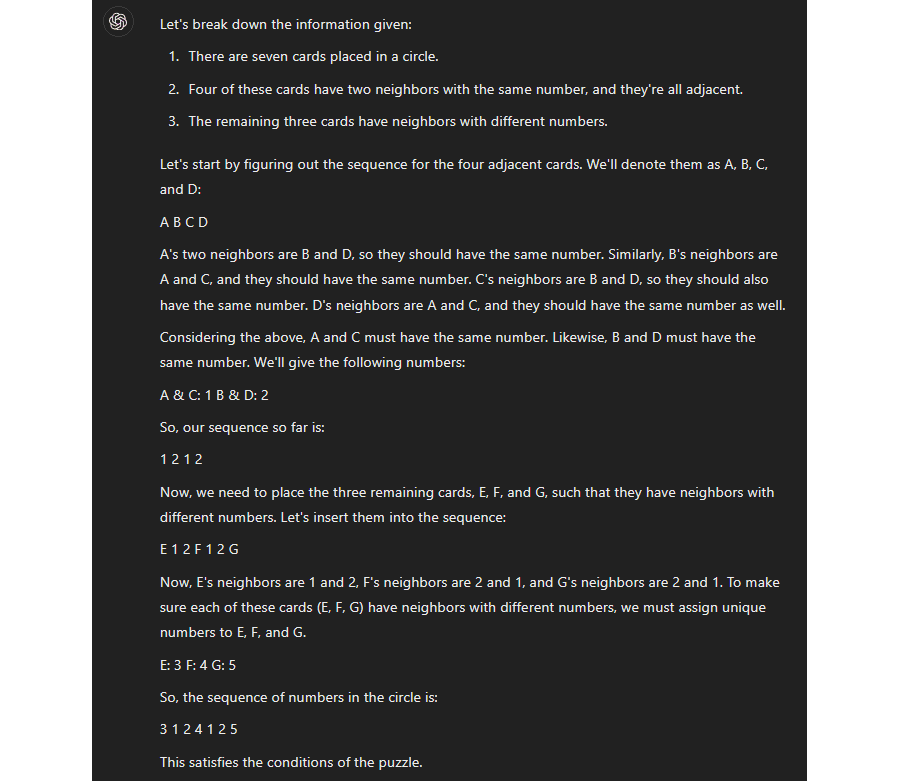
(Or see here for the second attempt.) Instead of trying to guess the answer immediately, it tried to write out a chain of reasoning. It still got the answer wrong, but this is a clear improvement. (And in fact, occasionally it got the answer right!, which the old model never did.)
I think these examples show both the potential and the problems of sequential reasoning without a thought assessor. Yes it's possible, but if you get a step wrong, the entire argument chain fails.
DeepSeek and o3 try to address this problem by verifying whether a conclusion is correct, and if it's not, trying again. Here's a snippet from the (very long) transcript with non-r1 DeepSeek:
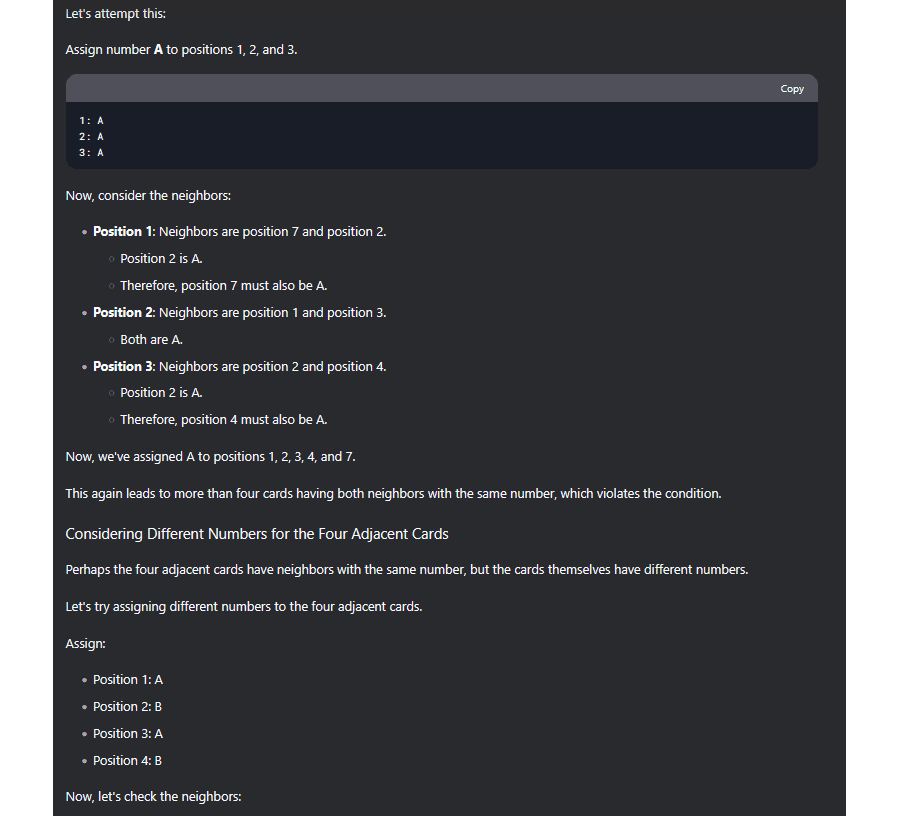
See the footnote[2] for the full version and other notes.
In a nutshell, I think the progression can be summarized as:
-
Everything up to and including pre-Jun13 GPT-4: don't do anything special for sequential reasoning tasks (i.e., just guess the solution).
-
Everything past the above and up to and including o1:[3] Attempt to write down a reasoning chain if the problem looks like it requires it.
-
o3 and DeepSeek: Attempt to write down a reasoning chain, systematically verify whether the conclusion is correct, and repeatedly go back to try again if it's not.
The above is also why I no longer consider talking about this an infohazard. Two years ago, the focus on sequential reasoning seemed non-obvious, but now, AI labs have evidently zoomed into this problem and put tremendous efforts into bootstrapping a sequential reasoner.
2.2 Sequential Reasoning without a Thought Assessor: the Future
According to my own model, LLMs seem to be picking up on sequential reasoning, which I claim is the relevant bottleneck. So is it time to panic?
Perhaps. I have some doubts about whether progress will continue indefinitely (and I'll get to them in a bit), but I think those aren't necessary to justify the title of this post. For now, the claim I want to make is that -year timelines are unlikely even without unforeseen obstacles in the future. Because I think the relevant scale is neither the Bostromian/Yudkowskian view:

nor the common sense view:

but rather something like this:
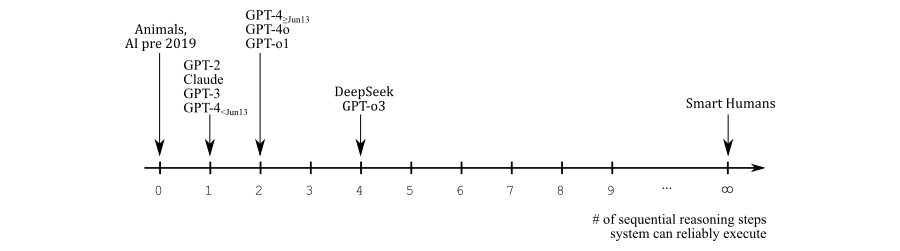
There are several caveats to this. One is that just getting from 0 to 1 on this scale requires a thought generator, which may be more than half of the total difficulty (or perhaps less than half, but certainly more than , so, either way, the scale is nonlinear). Another is that humans are not infinitely intelligent; their position on the scale just says that they can make indefinite progress on a problem given infinite time, which they don't have. And a third is that I just pulled these numbers out of my hat; you could certainly debate the claim that DeepSeek and o3 can do precisely 4 consecutive steps, or really any of these placements.
You could also argue that LLMs can do a lot more tasks with scaffolding, but I think figuring out how to decompose a task is usually the hardest part, so I think performance of pure reasoning models is the most relevant variable. (But see the section on human-AI teams.)
Nonetheless, I think the scale makes the point that very short timelines are not super likely. Remember that we have no a priori reason to suspect that there are jumps in the future; humans perform sequential reasoning differently, so comparisons to the brain are just not informative. LLMs just started doing sequential reasoning, and there's a big difference between the difficulty of what a smart human can figure out in 10 minutes vs. 10 years, and the latter is what AI needs to do – in fact, to outperform – to qualify as AGI. Imo. We're talking about a lot of steps here. So even if everything is smooth sailing from here, my point estimate for timelines would still be above 10 years. Maybe 15 years, I don't know.
Or, maybe there will be a sudden jump. Maybe learning sequential reasoning is a single trick, and now we can get from 4 to 1000 in two more years. Or, maybe there will be a paradigm shift, and someone figures out how to make a more brain-like AGI, in which case the argument structure changes. -year timelines aren't impossible, I just don't think they're likely.
3. More Thoughts on Sequential Reasoning
3.1. Subdividing the Category
Maybe sequential reasoning isn't best viewed as a single category. Maybe it makes sense to look at different types. Here are three types that I think could be relevant, with two examples for each.
- Type A: Sequential reasoning of any kind
- Once the cards in the earlier puzzle are labeled , , , , , , (with "S" for "same neighbor" and "D" for "different neighbor"), figuring out that (because has identical neighbors) and (because has identical neighbors) and therefore
- Reasoning that
Ne2allowsQg2#and is therefore a bad move
- Type B: Sequential reasoning where correctness cannot be easily verified
- Conclude that you should focus on the places where you feel shocked everyone's dropping the ball
- Reasoning, without the help of an engine, to retreat the white bishop to e2 instead so that it can be put on f1 after castling to prevent
Qg2#
- Type C: Deriving a new concept/term/category/abstraction to better think about a problem
- Derive the inner vs. outer dimension to improve (degrade?) our ability to discuss the alignment problem
- Come up with the concept of dietary fiber, comprising many different molecules, to better discuss nutrition
(I'll keep writing the types in boldface to make them distinct and different from the cards.) As written, B is a subset of A. I also think C is best viewed as a subset of B; deriving a new label or category is a kind of non-provably useful way to make progress on a difficult problem.
LLMs can now do a little bit of A. One could make the argument that they're significantly worse at B, and worse still at C. (H/t: The Rising Sea.) Can they do any C? It's somewhat unclear – you could argue that, e.g., the idea to label the seven cards in the first place, especially in a way that differentiates cards with the same vs. different neighbors, is an instance of C. Which LLMs did. But it's also just applying a technique they've seen millions of times in the training data to approach similar problems, so in that sense it's not a "new" concept. So maybe it doesn't count.
As of right now, I think there's still at least an argument that everything they can do in A is outside C. (I don't think there's an argument that it's all outside B because learned heuristics are in B, and insofar as LLMs can play chess, they probably do B – but they also have a ton of relevant training data here, so one might argue that their approach to B tends not to generalize.)
What they clearly can't do yet is long-form autonomous research, which is where C is key. Humans are actually remarkably bad at A in some sense, yet we can do work that implicitly utilizes hundreds if not thousands of steps, which are "hidden" in the construction of high-level concepts. Here's an example by GPT-4o (note that Ab is the category of abelian groups):
Theorem. Every nonzero abelian group admits a nontrivial homomorphism into .
Proof. By Pontryagin duality, the character group of any discrete abelian group is nontrivial unless . Since is an injective cogenerator in , there exists a nontrivial map .
GPT-4 could provide this proof, and maybe it could even write similar proofs that aren't directly copied from the literature, but only because it inherited 99% of the work through the use of concepts in its training data.
There is also an issue with the architecture. Current LLMs can only do sequential reasoning of any kind by adjusting their activations, not their weights, and this is probably not enough to derive and internalize new concepts à la C. Doing so would require a very large context window. That said, I think of this as more of a detail; I think the more fundamental problem is the ability to do B and C at all, especially in domains with sparse feedback. This also relates to the next section.
3.2. Philosophical Intelligence
(Note: this section is extremely speculative, not to mention unfalsifiable, elitist, self-serving, and a priori implausible. I'm including it anyway because I think it could be important, but please treat it separate from the remaining post.)
Similar to how IQ predicts performance on a wide range of reasoning tasks, I think there is a property that does the same for reasoning on philosophical tasks. "Philosophy" is a human-invented category so it's not obvious that such a property would exist (but see speculations about this later), but I've talked to a lot of people about philosophy in the last four years, and I've found this pattern to be so consistent that I've been convinced it does exist.
Furthermore, I think this category:
-
has a surprisingly weak correlation to IQ (although certainly ); and
-
is a major predictor of how much success someone has in their life, even if they don't write about philosophy. (This is probably the most speculative claim of this section and I can't do anything to prove it; it's just another pattern that I've seen too much not to believe it.)
For example, I suspect philosophical intelligence was a major driver behind Eliezer's success (and not just for his writing about philosophy). Conversely, I think many people with crazy high IQ who don't have super impressive life achievements (or only achieve great things in their specific domain, which may not be all that useful for humanity) probably don't have super high philosophical intelligence.
So, why would any of this be true? Why would philosophical intelligence be a thing, and even if it were a thing, why would it matter beyond doing philosophy (which is probably not necessary for AGI)?
I think the answer for both questions is that philosophical intelligence is about performance on problems for which there is no clearly relevant training data. (See the footnote[4] for why I think this skill is particularly noticeable on philosophical problems.) That means it's a subset of B, and specifically problems on B where feedback is hard to come by. I think it's probably mostly about the ability to figure out which "data" is relevant in such cases (with an inclusive notion of "data" that includes whatever we use to think about philosophy). It may be related to a high setting of Stephen Grossberg's vigilance parameter.
If this is on the right track, then I think it's correct to view this skill as a subset of intelligence. I think it would probably be marginally useful on most tasks (probably increases IQ by a few points) but be generally outclassed by processing speed and creativity (i.e., "regular intelligence").
For example, suppose Anna has exceptional philosophical intelligence but average regular intelligence and Bob is the reverse. Continuing in the spirit of wild speculation, I think Anna would have an advantage on several relevant tasks, e.g.:
- If a chess position is very non-concrete (i.e., strategic rather than tactical), Anna might figure out how what she's learned applies to the present case better than Bob.
- If she's at the start of a coding problem, Anna might pattern-match it to past problems in a non-obvious way that causes her to select a working approach right away, whereas Bob might start off trying something that doesn't work.
However, she's likely to be outperformed by Bob in both cases:
- Bob would most likely outcalculate Anna from a marginally worse position. (In chess, tactics usually triumph over strategy.)
- Bob can probably code at 3x the speed, start over when his approach doesn't work, and still finish first.
For these and many other tasks, I think philosophical intelligence will provide a nonzero but small advantage. But now consider a decision or problem for which time is abundant but training data is hard to come by. Almost all philosophical problems are of this kind, but so are many practical problems – they might be empirical in principle, but that doesn't matter if no relevant data can be obtained over a lifetime. I think the following questions are all a little like this, although to varying degrees:
- Which career path should I take?
- Should I switch careers even though I'm currently successful?
- Should I spend several years writing essays about rationality and publish them on a free blog?
- If I decide to work on AI alignment, which research direction should I pursue?
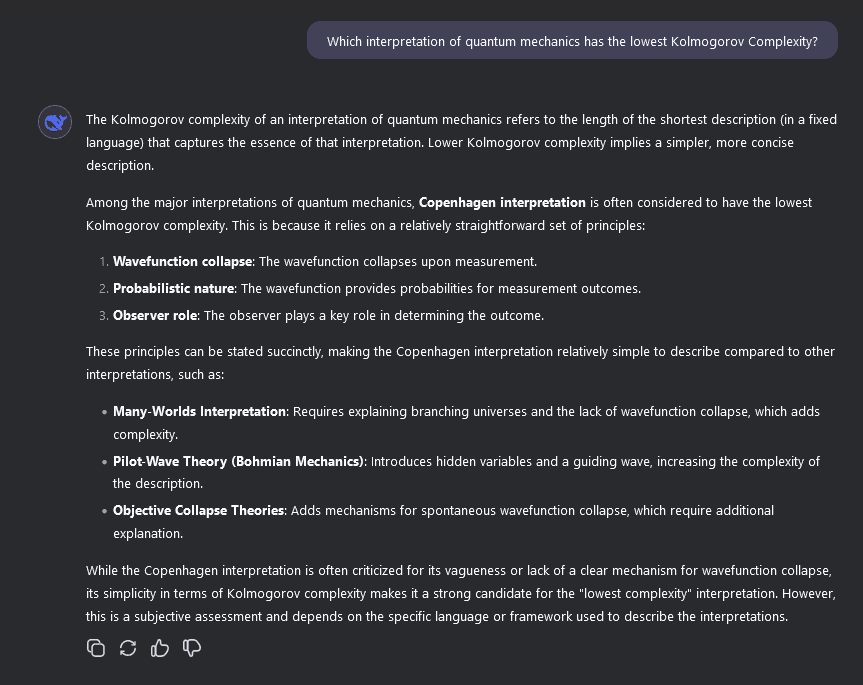
- Which interpretation of quantum mechanics is true (and is this even a well-defined question)?
- Is AI inherently safe because it's created by humans?
- What is morality/probability/consciousness/value?
If you're now expecting me to argue that this could be good news because LLMs seem to have low philosophical intelligence... then you're correct! In my experience, when you ask an LLM a question in this category, you a summary of popular thought on the subject – the same as on any other open-ended question – without any ability to differentiate good from bad ideas. And if you ask something for which there is no cached answer, you usually get back utter nonsense:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Is all the above highly speculative? Yes. Is this "philosophical intelligence" ultimately just measuring people's tendency to agree with me? I can't prove that it's not. Is it a suspiciously convenient line of argument, given that I'm afraid of AI and would like timelines to be long? Definitely. Is it inherently annoying to argue based on non-objective criteria? Absolutely.
But I wanted to include this section because at least that last property may just be inherent to the relevant capabilities of AI. Perhaps "problems for which we can't all agree on the right answer" are actually a really important class, and if that's the case, we probably should talk about them, even if we can't all agree on the right answer.
4. Miscellaneous
4.1. Your description of thought generation and assessment seems vague, underspecified, and insufficiently justified to base your conclusions on.
I agree. I have a lot more to say about why I think the model is accurate and what exactly it says, but I don't know how to do it in under 20k words, so I'm not doing it here. (If I ever publish my consciousness sequence, I'll write about it there.) For right now, the choice was between writing it with a shaky foundation for the core claim or not writing it at all, and I decided to do the former.
That said, I don't think the claim that the brain uses fundamentally different processes for thought generation and assessment is particularly crazy or fringe. See e.g. Steven Byrnes' Valence sequence.
4.2. If your model is on the right track, doesn't this mean that human+AI teams could achieve significantly superhuman performance and that these could keep outperforming pure AI systems for a long time?
The tl;dr is that I'm not sure, but I think the scenario is plausible enough that it deserves more consideration than it's getting right now.
The case for: LLMs are now legitimately strong at one-step (and potentially two-step and three-step) reasoning. If this trend continues and LLMs outperform humans in short-term reasoning but struggle with reliability and a large number of steps, then it would seem like human/LLM teams could complement each other nicely and outperform pure humans by a lot, and perhaps for a long time.
The case against: Because of the difficulties discussed in §3.1 and §3.2, it's unclear how this would work in practice. Most of the time I'm doing intellectual work, I'm neither at the beginning of a problem nor working on a problem with clear feedback. (This may be especially true for me due to my focus on consciousness, but it's probably mostly true for most people.) So far I'm primarily getting help from LLMs for coding and understanding neuroscience papers. These use cases are significant but also inherently limited, and it's unclear how progress on A would change that.
But nonetheless, maybe there are ways to overcome these problems in the future. I don't know what this would look like, but I feel like "LLM/human teams will outperform both pure LLMs and pure humans by a significant factor and for a significant period of time" is a plausible enough scenario to deserve attention.
4.3. What does this mean for safety, p(doom), etc.?
I was initially going to skip this topic because I don't think I have much to add when it comes to alignment and safety. But given the current vibes, doing so felt a bit tone-deaf, so I added a section even though I don't have many exciting insights.
Anyway, here's what I'll say. I don't dispute that the recent events look bad. But I don't think the period we're in right now is particularly crucial. If democracy in the USA still exists in four years, then there will be a different administration 2029-2033, which is probably a more important time period than right now. I don't know how much lock-in there is from current anti-safety vibes, but we know they've changed in the past.
And of course, that still assumes LLMs do scale to AGI without a significantly new paradigm. Which I think has become more plausible after DeepSeek and o3, but it's by no means obvious. If they don't scale to AGI, then even more can change between now and then.
On that note, TsviBT has argued that for many people, their short timelines are mostly vibes-based. I'm pretty confident that this is true, but I'm even more confident that it's not specific to short timelines. If and when it becomes obvious that LLMs won't scale to AGI, there will probably be a lot of smugness from people with long timelines – especially because the vibes right now are so extreme – and it will probably be mostly unearned. I think the future is highly uncertain now, and if a vibe shift really does happen, it will still be very uncertain then.
In fact, there's a sense in which this problem can be solved in a purely 'methodical' way, without requiring any creativity. Start by writing down the sequence with seven different letters (
A-B-C-D-E-F-G; this sequence is correct wlog. Now treat the same neighbor criterion as a set of four different equations and apply them in any order, changing a symbol for each to make it true. (E.g., the first requires that B=G, so change the sequence toA-B-C-D-E-F-B). This process yieldsA-B-A-B-A-F-Bafter four steps, which is the same solution we've derived above. ↩︎The full transcript is here, given as a pdf because it's so long. To my surprise, DeepSeek ended up not solving the puzzle despite getting the key idea several times (it eventually just submitted a wrong solution). I think it shows the improvement regardless of the eventual failure, but since it didn't get it right, I decided to query DeepSeek (R1) as well, which of course solved it (it can do harder problems than this one, imE). Transcript for that (also very long) is here. ↩︎
I realize that viewing the Jun13 update as a larger step than GPT-4 GPT-o1 is highly unusual, but this is genuinely my impression. I don't think it has any bearing on the post's thesis (doesn't really matter where on the way the improvements happened), but I'm mentioning it to clarify that this categorization isn't a clerical error. ↩︎
Philosophy tends to be both non-empirical and non-formal, which is why you can never settle questions definitively. I also think these properties are pretty unique because
- If something becomes empirical, it's usually considered a science. E.g., "what are the building blocks of matter" used to be considered philosophy; now it's physics.
- If something becomes formal, it's usually considered math. In fact, metalogic formalizes math as a formal language (usually in the language of set theory, but it can also be done in other languages), and "you can express it in a formal language" is basically the same as "you can formalize it". E.g., you could argue that the Unexpected Hanging Paradox is a philosophical problem, but if I answer it by making a formal model, we'd probably consider that math – that is, unless we're debating how to translate it properly, which could again be considered philosophy, or how to interpret the model. Similarly, Wikipedia says that Occam's Razor is philosophy and Kolmogorov Complexity science or math.
{kind=link}
Even if current LLM architectures cannot be upscaled or incrementally improved to achieve human-level intelligence, it is still possible that one or more additional breakthroughs will happen in the next few years that allow an explicit thought assessor module. Just like the transformer architecture surpsied everybody with its efficacy. So much money and human resources are being thrown at the pursuit of AGI nowadays, we cannot be confident that it will take 10 years or longer.