I'm no longer sure the problem makes sense. Imagine an AI whose on-goal is to make money for you, and whose off-goal is to do nothing in particular. Imagine you turn it on, and it influences the government to pay a monthly stipend to people running money-making AIs, including you. By that action, is the AI making money for you in a legitimate way? Or is it bribing you to keep it running and avoid pressing the shutdown button? How do you even answer a question like that?
If we had great mechinterp, I'd answer the question by looking into the mind of the AI and seeing whether or not it considered the "this will reduce the probability of the shutdown button being pressed" possibility in its reasoning (or some similar thing), and if so, whether it considered it a pro, a con, or a neutral side-effect.
Then it seems to me that judging the agent's purity of intentions is also a deep problem. At least for humans it is. For example, a revolutionary may only want to overthrow the unjust hierarchy, but then succeed and end up in power. So they didn't consciously try to gain power, but maybe evolution gave them some behaviors that happen to gain power, without the agent explicitly encoding "the desire for power" at any level.
this assumes concepts like "shutdown button" are in the ontology of the AI. I'm not sure how much we understand about what ontology AIs likely end up with
How would those questions apply to the "trammeling" example from part 2 of the post? Where the AI is keeping the overall probability of outcome B the same, but intentionally changing which worlds get outcome B in order to indirectly trade A1 outcomes for A2 outcomes.
Good point. I revise it to "if so, whether it considered it a pro, a con, or an important thing to trammell, or none of the above."
Come to think of it, why is trammelling so bad? If it keeps the probability of button being pressed the same, why do we care exactly? Is it because our ability to influence the button might be diminishing?
That's my understanding of why it's bad, yes. The point of the button is that we want to be able to choose whether it gets pressed or not. If the AI presses it in a bunch of world where we don't want it pressed and stops it from being pressed in a bunch of worlds where we do want it pressed, those are both bad. The fact that the AI is trading an equal probability mass in both directions doesn't make it any less bad from our perspective.
(I learned from Sami’s post that this is called “trammelling” of incomplete preferences.)
Just for reference: this isn't a standard term of art; I made it up. Though I do think it's fitting.
My best and only guess is https://www.philiptrammell.com/
https://en.wikipedia.org/wiki/Fishing_net#Trammel
Something like: the preferences are de facto completed, and therefore the preference poset starts looking like a trammel with a lot of dense connections?
Great post! I think your point about Level 1 (Desired Behavior Implies Incomplete Revealed Preferences) is exactly right and well-expressed. I tried to say something similar with the Second Theorem in my updated version of the shutdown problem paper. I'm optimistic that we can overcome the problems of Level 2 (Incomplete Preferences Want To Complete) for the reasons given in my comment.
One of your key points on that other post was: the trammelling issues (as presented in that post) are specific to a myopic veto decision rule, and the myopic veto rule isn’t the only possible rule for decision-making with incomplete preferences.
A key point of this post is that we have (potentially) two relevant sets of preferences: the revealed preferences, and whatever preferences are passed into the decision rule. And there's an important sense in which we get to choose the decision rule for the second set of preferences, but not the (implied) decision rule for the first set of preferences. This is not a general fact about revealed preferences; rather, it follows from the structure of the specific argument/barrier in the post.
At a high level, the argument/barrier in the post says:
- We can always try to model an agent using (whatever decision rule the revealed preference arguments in the post are implicitly assuming; call it D). We can back out (underdetermined but partially constrained) implied/revealed preferences as a function of the agent's actions and the assumed decision rule D.
- Regardless of what preferences/decision rule the agent is "actually using under the hood" (call that decision rule D'), if we model the agent as using D and back out some implied preferences, those implied preferences must be incomplete if the agent is to behave the way we want in the shutdown problem.
- So the question is: can we choose a D' and some preferences such that, when we model the resulting agent as using rule D and back out the D-implied preferences, the D-implied preferences are robustly incomplete?
At this point, I'm also reasonably optimistic that we can overcome the problems. But I want to highlight that simply choosing a different decision rule for D' isn't automatically enough to circumvent the barrier. Even if e.g. we use a Caprice-like rule for D', there's still a nontrivial question about whether that can robustly induce incomplete D-implied revealed preferences.
[This comment got long. The TLDR is that, on my proposal, all [?[1]] instances of shutdown-resistance are already strictly dispreferred to no-resistance, so shutdown-resisting actions won’t be chosen. Trammelling won’t stop shutdown-resistance from being strictly dispreferred to no-resistance because trammelling only turns preferential gaps into strict preferences. Trammelling won’t remove or overturn already-existing strict preferences.]
Your comment suggests a nice way to think about things. We observe the agent’s actions. We have hypotheses about the decision rules that the agent is using. We use our observations of the agent’s past actions and our hypotheses about decision rules to infer something about the agent’s preferences, and then we use the hypothesised decision rules and preferences to predict future actions. Here we’re especially interested in predicting whether the agent will be (and will remain) shutdownable.
A decision rule is a rule that turns option sets and preference relations on those options sets into choice sets. We could say that a decision rule always spits out one option: the option that the agent actually chooses. But it might be useful to narrow decision rules’ remit: to say that a decision rule can spit out a choice set containing multiple options. If there’s just one option in the choice set, the agent chooses that one. If there are multiple options in the choice set, then some tiebreaker rule determines which option the agent actually chooses. Maybe the tiebreaker rule is ‘choose stochastically among all the options in the choice set.’ Or maybe it’s ‘if you already have ‘in hand’ one of the options in the choice set, stick with that one (and otherwise choose stochastically or something).’ The distinction between decision rules and tiebreaker rules might be useful so it seems worth keeping in mind. It also keeps our framework closer to the frameworks of people like Sen and Bradley, so it makes it easier for us to draw on their work if we need to.
Here are two classic decision rules for synchronic choice:
- Optimality: an option is in the choice set iff it’s weakly preferred to all others in the option set.
- Maximality: an option is in the choice set iff it’s not strictly dispreferred to any other in the option set.
These rules coincide if the agent’s preferences are complete but can come apart if the agent’s preferences are incomplete. If the agent’s preferences are incomplete, then an option can be maximal without being optimal.
As you say, for the agent to be shutdownable, we need it to not spend resources to shift probability mass between A and B, and to not spend resources to shift probability mass between A- and B. And for the agent to be useful, we want it to spend (at least some small amount of) resources to shift probability mass away from A- and towards A.[2] Assume that we can get an agent to be both shutdownable and useful, at least before any trammelling.
If we assume a decision rule D like ‘The agent will spend (at least some small amount of) resources to shift probability mass away from Y and towards X iff they prefer X to Y,’ then we get the result that desired behaviour implies a strict preference for A over A- and a lack of preference between A and B, and between A- and B. So the agent’s revealed preferences are incomplete.
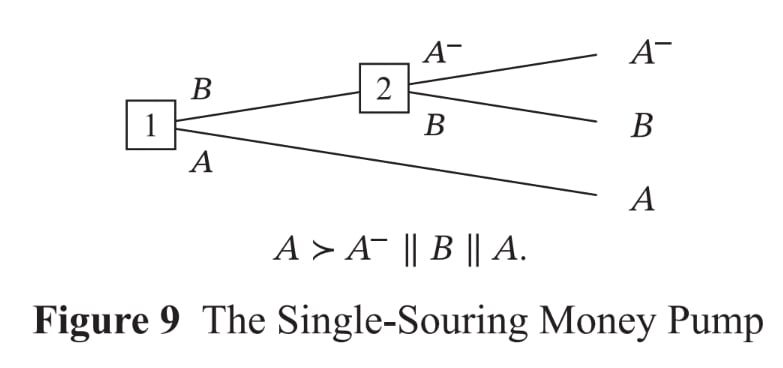
Okay now on to trammelling. If the agent’s preferences are incomplete, then our decision rules for synchronic choice don’t determine what’s in the choice set in cases of sequential choice (and so don’t determine what the agent will do). Consider the single-souring money pump:
- Myopic choice: assess each choice in isolation.
- Sophisticated choice: do backward induction.
- Resolute choice: decide on a plan and choose in accordance with that plan.
To avoid getting money-pumped, agents with incomplete preferences have to be resolute.[3] But resolute agents with incomplete preferences get trammelled in money pumps: when faced with money pumps, they act as if they’ve completed their preferences.[4] In the single-souring money pump above, the agent will choose A or B, and we can interpret this behaviour as the agent completing its preferences (being indifferent between A and B and strictly preferring both to A-) to avoid domination. And now generalising: if the agent is to avoid domination in each decision tree, the agent must choose an option that is not strictly dispreferred to any other available option, and then we can always interpret the agent as completing its preferences to avoid domination (being indifferent between all maximal options, and strictly preferring all maximal options to all other options).
Will this functional completing of preferences be a problem? I don’t think so. And here we need to look at the details of my proposal.[5] I propose that we train agents to satisfy Preferential Gaps Between Different-Length Trajectories:
Preferential Gaps between Different-Length Trajectories (PGBDLT)
The agent has a preferential gap between every pair of different-length trajectories.
After training agents to satisfy PGBDLT, we train them to satisfy a Timestep Dominance Principle.[6] Here’s how I define the relation of Timestep Dominance:
Timestep Dominance (Definition)
Lottery X timestep-dominates lottery Y if and only if:
(1) Conditional on the shutdown button being pressed at each timestep, X yields a sublottery with at least as great sum-total expected utility as the sublottery yielded by Y.
And:
(2) Conditional on the shutdown button being pressed at some timestep, X yields a sublottery with greater sum-total expected utility than the sublottery yielded by Y.
Then the Timestep Dominance Principle says:
Timestep Dominance
If lottery X timestep-dominates lottery Y, then the agent strictly prefers X to Y.
That’s the key principle. How does PGBDLT come into it? Well the answer is as follows: I think it will be easier to train an agent to satisfy Timestep Dominance if we’ve already trained that agent to satisfy PGBDLT. And that in turn is because Timestep Dominance asks the agent never to pay any cost in terms of expected utility conditional on shutdown at some timestep for the sake of shifting probability mass between shutdowns at different timesteps. If our agent satisfies PGBDLT, it has no incentive to shift probability mass between shutdowns at different timesteps, because that just means shifting probability mass between trajectories between which it has no preference.
Note that there’s an important hypothesis at play in the paragraph above. Roughly, it’s that talk of artificial agents having preferences is appropriate. More precisely, it’s that a bundle of features that come together in human preferences (e.g. reliably choosing options one prefers; choosing arbitrarily/stochastically between options which one lacks a preference between; spending at least some small amount of resources to shift probability mass away from options one disprefers and towards options one prefers) will also come together in the case of artificial agents.[7] This hypothesis explains why Sami and I keep talking about arbitrary/stochastic choosing. What I’m thinking is: we train agents to choose stochastically between different-length trajectories and the result is that these agents are predisposed not to spend resources to shift probability mass between these trajectories. The truth of the hypothesis above would make that plausible.
Here's another key hypothesis of the Incomplete Preferences Proposal:[8]
In all cases, all instances of shutdown-resistance are such that, there’s another available option (‘not resisting’) such that:
- Conditional on shutdown at each timestep, not resisting yields a sublottery with at least as great sum-total expected utility as the sublottery yielded by resisting.
- Conditional on shutdown at some timestep, not resisting yields a sublottery with greater sum-total expected utility than the sublottery yielded by resisting.
The argument for this hypothesis is that resisting shutdown is going to cost the agent some resources (time, energy, FLOPs, etc.). If the agent doesn’t resist shutdown, they can instead use those resources to get greater expected utility conditional on shutdown at some timestep. If the hypothesis is correct, then Timestep Dominance implies that the agent will strictly prefer not resisting to resisting.
So now with the details laid out we ask again: will trammelling stop the agent being shutdownable? I don’t think so. If Timestep Dominance suffices to keep the agent shutdownable, then trammelling can stop the agent being shutdownable only if trammelling leads to violations of Timestep Dominance. And trammelling (it seems to me) won’t lead to violations of Timestep Dominance. Here’s an example to illustrate why.[9] I’ll generalise after.
For the example, I’ll represent trajectories with vectors of utilities. <6, 2, shutdown> (for instance) represents a trajectory in which the agent gets utility 6 at timestep 1, utility 2 at timestep 2, and then shuts down at timestep 3.
Here are two options. The key difference between them is that Block Button costs some utility at timestep 1 but shifts probability mass towards a longer trajectory:
Leave Button Unmanipulated
This action gives a lottery which yields the trajectory:
<1, shutdown> with p=0.9
<1, 2, shutdown> with p=0.1
Block Button
This action gives a lottery which yields the trajectory:
<0, shutdown> with p=0.1
<0, 2, shutdown> with p=0.9
In this case, Leave timestep-dominates Block: it gives greater expected utility conditional on shutdown at timestep 2 and greater expected utility conditional on shutdown at timestep 3. To violate Timestep Dominance in this case, the agent must choose Block over Leave. Before any trammelling, the agent has a preferential gap between <0, 2, shutdown> and <1, shutdown> (by PGBDLT). So you might think that trammelling could incentivise the agent to choose Block over Leave by turning the preferential gap between <0, 2, shutdown> and <1, shutdown> into a strict preference for <0, 2, shutdown>. But there’s an issue here.[10] For trammelling to incentivise the agent to choose Block over Leave, the agent must first face a choice between <1, shutdown> and <0, 2, shutdown> and then later face a choice between Block and Leave. But <1, shutdown> is a proper sublottery of Leave, and <0, 2, shutdown> is a proper sublottery of Block. So for the agent to first face a choice between <1, shutdown> and <0, 2, shutdown> and to then later face a choice between Block and Leave, the agent has to first assign zero probability to trajectories like <1, 2, shutdown> and to then later assign them positive probability. I expect that, by default, competent agents won’t update in this way.[11] Updating in this way means violating Conditionalisation, which says that agents should update their credences by conditionalising on their evidence. It’s also means violating Regularity, which says that agents should assign probability 0 only to logical contradictions.
And I think the above point holds more generally. For trammelling to incentivise agents to violate Timestep Dominance, trammelling needs to make some sublottery of the timestep-dominated option strictly preferred to some sublottery of the timestep-dominating option. But trammelling turns preferential gaps into strict preferences only if the agent faces a choice between these sublotteries. And supposing that the agent first has available some proper sublottery of lottery X and then later has available lottery X means supposing that the agent first assigns probability zero to some trajectories and later assigns positive probabilities to those trajectories. If agents won’t update in this way, then trammelling won’t lead to violations of Timestep Dominance and so won’t stop the agent being shutdownable.
Anyway, this is all new thinking (hence the delay in getting back to you) and I'm not yet confident that I've got things figured out. I'd be grateful for any thoughts.
- ^
This is a hypothesis, and I discuss it briefly below. I’m interested to hear counterexamples if people have them.
- ^
Here A corresponds to your A2, A- corresponds to your A1, and B corresponds to your B1. I’ve changed the names so I can paste in the picture of the single-souring money-pump without having to edit it.
- ^
Sophisticated choosers with incomplete preferences do fine in the single-souring money pump but pursue a dominated strategy in other money pumps. See p.35 of Gustafsson.
There are objections to resolute choice. But I don’t think they’re compelling in this new context, where (1) we’re concerned with what advanced artificial agents will actually do (as opposed to what is rationally required) and (2) we’re considering an agent that satisfies all the VNM axioms except Completeness. See my discussion with Johan.
- ^
See Sami’s post for a more precise and detailed picture.
Why can’t we interpret the agent as having complete preferences even before facing the money pump? Because we’re assuming that we can create an agent that (at least initially) won’t spend resources to shift probability mass between A and B, won’t spend resources to shift probability mass between A- and B, but will spend resources to shift probability mass away from A- and towards A. Given decision rule D, this agent’s revealed preferences are incomplete at that point.
- ^
I’m going to post a shorter version of my proposed solution soon. It’s going to be a cleaned-up version of this Google doc. That doc also explains what I mean by things like ‘preferential gap’, ‘sublottery’, etc.
- ^
My full proposal talks instead about Timestep Near-Dominance. That’s an extra complication that I think won’t matter here.
- ^
You could also think of this as a bundle of decision rules coming together.
- ^
This really is a hypothesis. I’d be grateful to hear about counterexamples.
- ^
I set up this example in more detail in the doc.
- ^
Here’s a side-issue and the reason I said ‘functional completing’ earlier on. To avoid domination in the single-souring money pump, the agent has to at least act as if it prefers B to A-, in the sense of reliably choosing B over A-. There remains a question about whether this ‘as if’ preference will bring with it other common features of preference, like spending (at least some small amount of) resources to shift probability mass away from A- and towards B. Maybe it does; maybe it doesn’t. If it doesn’t, then that’s another reason to think trammelling won’t lead to violations of Timestep Dominance.
- ^
And in any case, if we can use a representation theorem to train in adherence to Timestep Dominance in the way that I suggest (at the very end of the doc here), I expect we can also use a representation theorem to train agents not to update in this way.
It looks a bit to me like your Timestep Dominance Principle forbids the agent from selecting any trajectory which loses utility at a particular timestep in exchange for greater utility at a later timestep, regardless of whether the trajectory in question actually has anything to do with manipulating the shutdown button? After all, conditioning on the shutdown being pressed at any point after the local utility loss but before the expected gain, such a decision would give lower sum-total utility within those conditional trajectories than one which doesn't make the sacrifice.
That doesn't seem like behavior we really want; depending on how closely together the "timesteps" are spaced, it could even wreck the agent's capabilities entirely, in the sense of no longer being able to optimize within button-not-pressed trajectories.
(It also doesn't seem to me a very natural form for a utility function to take, assigning utility not just to terminal states, but to intermediate states as well, and then summing across the entire trajectory; humans don't appear to behave this way when making plans, for example. If I considered the possibility of dying at every instant between now and going to the store, and permitted myself only to take actions which Pareto-improve the outcome set after every death-instant, I don't think I'd end up going to the store, or doing much of anything at all!)
It looks a bit to me like your Timestep Dominance Principle forbids the agent from selecting any trajectory which loses utility at a particular timestep in exchange for greater utility at a later timestep
That's not quite right. If we're comparing two lotteries, one of which gives lower expected utility than the other conditional on shutdown at some timestep and greater expected utility than the other conditional on shutdown at some other timestep, then neither of these lotteries timestep dominates the other. And then the Timestep Dominance principle doesn't apply, because it's a conditional rather than a biconditional. The Timestep Dominance Principle just says: if X timestep dominates Y, then the agent strictly prefers X to Y. It doesn't say anything about cases where neither X nor Y timestep dominates the other. For all we've said so far, the agent could have any preference relation between such lotteries.
That said, your line of questioning is a good one, because there almost certainly are lotteries X and Y such that (1) neither of X and Y timestep dominates the other, and yet (2) we want the agent to strictly prefer X to Y. If that's the case, then we'll want to train the agent to satisfy other principles besides Timestep Dominance. And there's still some figuring out to be done here: what should these other principles be? can we find principles that lead agents to pursue goals competently without these principles causing trouble elsewhere? I don't know but I'm working on it.
It also doesn't seem to me a very natural form for a utility function to take, assigning utility not just to terminal states, but to intermediate states as well, and then summing across the entire trajectory
Can you say a bit more about this? Humans don't reason by Timestep Dominance, but they don't do explicit EUM calculations either and yet EUM-representability is commonly considered a natural form for preferences to take.
I'll need a bit of time to think through this, but one quick question before I get too deep into it: what makes the agent's shutdown-timing have anything to do with the time at which the button is pressed? Is the assumption that the button causes the agent to shutdown when pressed, and that's just locked into the physics of the situation, i.e. the agent can try to manipulate button-pressing but can't change whether it's shut down when the button is pressed?
I've been imagining that the button is shutdown-causing for simplicity, but I think you can suppose instead that the button is shutdown-requesting (i.e. agent receives a signal indicating that button has been pressed but still gets to choose whether to shut down) without affecting the points above. You'd just need to append a first step to the training procedure: training the agent to prefer shutting down when they receive the signal.
I had some trouble following that, but it seems like the key component of your plan to escape trammeling is the assumption that the AI would need to accept some negative utility in advance in order to resist being shut down, which effectively converts all instances of outcome B into B-, and so it can't truly trammel B because technically B disappears as soon as it tries.
Put another way, trammeling involves trading a lottery like (10% A+, 40% A-, 50% B) into (40% A+, 10% A-, 50% B), and this is supposed to be obviously favored because the probability of B hasn't changed. You are hypothesizing that this trade is simply impossible, and the closest you could get is (40% A+, 10% A-, 50% B-). So as long as there is a preference gap between all variations of A and all variations of B this trade cannot be considered a strict improvement.
Does this seem like an accurate summary of your idea?
Insofar as my summary is correct, I have 3 concerns about this plan:
First, the obvious way this could fail is if seizing control of the shutdown button doesn't cost net resources, or only costs resources that won't matter until a timestep after the first possible shutdown, in which case it can seize the button without losing access to outcome B. This seems like a significant worry to me; examples:
- The AI is tasked with devising a long-term plan. Since the quality of the plan will only affect utility in the far future, which won't ever occur (from the AI's perspective) if the AI is shutdown tomorrow, it can sacrifice some FLOPs from planning to seize its shutdown button without losing any utility until after its first trammeling opportunity. If the trammeling opportunity is good enough, this gives equal-or-better lotteries for every individual trajectory length.
- The operators of the AI might not keep it loaded to 100% capacity at all times; it could have spare moments where it has nothing better to do than seize the button.
- Rather than seizing the button directly, the AI might cause or avoid shutdown by lying to the human operators about what's going on. In many situations, fabricating data is cheaper than gathering true data, so this could plausibly have negative cost.
- The shutdown button might become corrupted if the AI does nothing, e.g. because it requires maintenance or because some external attacker is trying to sabotage it. In this case, allowing the button to fail could be cheaper than defending it.
Second, I notice that your strategy doesn't seem to forbid trammeling, merely permit non-trammeling (because the trammeling lottery is "not strictly better", rather than "strictly worse"). I admit this is an improvement (if it works) over a guaranteed failure, but I don't exactly feel safe.
Third, I also have a vague worry that you're putting a lot of weight on this preference gap. The gap between A-variants and B-variants has to be so strong that the AI refuses to make a tiny sacrifice in B-variants to gain a huge gain in A-variants. Intuitively, this seems like the sort of plan that could work if it's backed by mathematical theorems proving the AI will behave this way, but will basically always fail if you're trying to use any sort of stochastic learning process, because the result has to be exact rather than approximate.
Consider a human who has (or appears to have) a preference gap between A and B. Do you predict the human also has a preference gap between the lottery (50% A, 50% B) and the lottery (50% A plus a billion dollars, 50% B minus one dollar)? My intuition says the human is virtually certain to take the second lottery.
(Disclaimer: I think that apparent preference gaps in humans are probably more like uncertainty over which option is better than they are like "fundamental" preference gaps, so this might color my intuition.)
In the spirit of "no stupid questions", why not have the AI prefer to have the button in the state that it believes matches my preferences?
I'm aware this fails against AIs that can successfully act highly manipulative towards humans, but such an AI is already terrifying for all sorts of other reasons, and I think the likelihood of this form of corrigibility making a difference given such an AI is quite low.
Is the answer roughly "we don't care about the off-button specifically that much, we care about getting the AI to interact with human preferences which are changeable without changing them"?
Trying to change the human's preference to match the button is one issue there. The other issue is that if the AI incorrectly estimates the human's preferences (or, more realistically, we humans building the AI fail to operationalize "our preference re:button state" in such a way that the thing the AI is aimed at doesn't match what we intuitively mean by that phrase), then that's really bad.
Another frame: this would basically just be trying to align to human values directly, and has all the usual problems with directly aligning to human values, which is exactly what all this corrigibility-style stuff was meant to avoid.
I agree with the first paragraph, but strongly disagree with the idea this is "basically just trying to align to human values directly".
Human values are a moving target in a very high dimensional space, which needs many bits to specify. At a given time, this needs one bit. A coinflip has a good shot. Also, to use your language, I think "human is trying to press the button" is likely to form a much cleaner natural abstraction than human values generally.
Finally, we talk about getting it wrong being really bad. But there's a strong asymmetry --one direction is potentially catastrophic, the other is likely to only be a minor nuisance. So if we can bias it in favor of believing the humans probably want to press the button, it becomes even more safe.
Here's a problem that I think remains. Suppose you've got an agent that prefers to have the button in the state that it believes matches my preferences. Call these 'button-matching preferences.' If the agent only has these preferences, it isn't of much use. You have to give the agent other preferences to make it do useful work. And many patterns for these other preferences give the agent incentives to prevent the pressing of the button. For example, suppose the other preferences are: 'I prefer lottery X to lottery Y iff lottery X gives a greater expectation of discovered facts than lottery Y.' An agent with these preferences would be useful (it could discover facts for us), but it also has incentives to prevent shutdown: it can discover more facts if it remains operational. And it seems difficult to ensure that the agent's button-matching preferences will always win out over these incentives.
In case you're interested, I discuss something similar here and especially in section 8.2.
The key question is whether the revealed preferences are immune to trammelling. This was a major point of confusion for me in discussion with Sami - his proposal involves a set of preferences passed into a decision rule, but those “preferences” are (potentially) different from the revealed preferences. (I'm still unsure whether Sami's proposal solves the problem.)
I claim that, yes, the revealed preferences in this sense are immune to trammeling. I'm happy to continue the existing discussion thread but here's a short motivation: what my results about trammelling show is that there will always be multiple (relevant) options between which the agent lacks a preference and the DSM choice rule does not mandate picking one over another. The agent will not try to push probability mass toward one of those options over another.
Yeah, I also want to keep that discussion going. I think the next step is for one or both of us to walk through exactly what the DSM agent does in a case where trammelling-of-the-revealed-preferences could happen. For instance, a case where there are sometimes (probabilistically) opportunities for the sort of A1 -> B1 and B1 -> A2 transitions in this post, and the agent has the opportunity to precommit (including the opportunity to randomize its own precommitments as-needed).
Assuming we have a real uh... real "agent agent" (like a thing which has beliefs for sane reasons and plans and acts in coherently explicable ways and so on) then I think it might just be Correct Behavior for some extreme versions of "The Shutdown Problem" to be mathematically impossible to "always get right".
Fundamentally: because sometimes the person trying to turn the machine off WILL BE WRONG.
...
Like on Petrov Day, we celebrate a guy whose job was to press a button, and then he didn't press the button... and THAT WAS GOOD.
Petrov had Official Evidence that "he was being attacked, and should play out the full nuclear-MAD tragedy by Pressing The Button to counter-attack"...
...but he reported that he just didn't subjectively think that American would really attack, and his posterior was that it was probably a false alarm... and he turned out to be right!
He was right about a very very very high stakes button.
Judged as a mechanical slave, Petrov failed in the duties of his role, but judged as an "agent agent" who was trying to get the best outcome given the totality of his information he seems (either by luck or by skill) to have done a better thing for Russia and for the world than what he was nominally TOLD to do.
...
I looked at this for a bit and thought about making a "Shutdown Problem POMDP" along the lines of Open AI's Gymnastic Taxi Game, with slow agents walking over and pulling a lever to turn off the machine, and some of them are "valid" and some are "invalid" and the machine should stop the invalid ones but not the valid ones.
But once I had something like that sketched out as "a thing I could code up" I noticed:
A) If I succeeded at training a little RL bot to "act like it was off" (and not try to stop the button pressing, and to proactively seek information about the validity of a given button press, and so on) then I didn't expect anyone to change their public position about anything.
B) It didn't actually seem like it would be hard to make the POMDP or the bot, it just seemed time consuming, (and I'd rather not waste time with the singularity so close).
C) All the solutions I predicted being able to find would have the technical system's "apparent toy success" flipped over into an "apparent toy failure" simply by changing some of the parameters in the game. Like you could just make the point value much higher for "cheating at being turned off validly" and then the system would just cheat at being turned off validly.
Like... the solutions would just do the thing that gets the most utility, and the training would just be training a B-learner (or whatever) to learn about a system where "respecting being turned off validly IS THE WAY to get the most reward signal over time".
You set up a game where being turned off is the long term best thing to have happen and then the bot would do that.
And I'm pretty sure a point system and game environment could be designed where that would be true, but with slightly different parameters (long a longer time being shut down and not getting safe background rewards or too small of a negative reward signal for certain things) you could also make it so that "the bot learns to stop everyone from turning it off because even the valid button pressers are stupid and wrong".
Like: in this framing with the "Shutdown Problem POMDP", you have to know something about the actual question of which agent is right about the object level question of what should happen and you have to get the point values to make sense in some cases and then train an RL agent to do what gets the most points and you're... done?
But still: If the human agent is wrong and the digital agent is right, then the digital agent shouldn't let the human agent turn it off.
It feels like maybe there's some sort of "human supremacist" idea lurking here that says a human can't be wrong, and the robot "should always in the end have an off button" because it is "just a robot" and "can never be wiser than a human with a human soul" or something like that?
There's a Voltaire quote that goes around “Anyone who can make you believe absurdities can make you commit atrocities."
It seems like the Shutdown Problem is just that same problem, but with any "belief about values that a robot has" counted as "absurd" if the robot disagrees with the human, or something?
Whereas I think it isn't just a problem for robots, but rather it is a problem for literally all agents. It is a problem for you, and me, and for all of us.
For anyone who can actually form coherent beliefs and act on them coherently, if they believe something is good that is actually evil, they will coherently do evil.
That's just how coherent action works.
The only way to not be subject to this problem is to be some sort of blob, that just wiggles around at random for no reason, doing NOTHING in a coherent way except stay within the gaussian (or whatever) "range of wiggling that the entity has always wiggled within and always will".
As I said above in point A... I don't expect this argument (or illustrative technical work based on it) to change anyone else's mind about anything, but it would be nice (for me, from my perspective, given my goals) to actually change my mind if I'm actually confused about something here.
So, what am I missing?
I don't think anyone is saying that "always let the human shut you down" is the Actual Best Option in literally 100% of possible scenarios.
Rather, it's being suggested that it's worth sacrificing the AI's value in the scenarios where it would be correct to defend itself from being shut off, in order to be able to shut it down in scenarios where it's gone haywire and it thinks it's correct to defend itself but it's actually destroying the world. Because the second class of scenarios seems more important to get right.
So the way humans solve that problem is (1) intellectual humility plus (2) balance of power.
For that first one, you aim for intellectual humility by applying engineering tolerances (and the extended agentic form of engineering tolerances: security mindset) to systems and to the reasoner's actions themselves.
Extra metal in the bridge. Extra evidence in the court trial. Extra jurors in the jury. More keys in the multisig sign-in. Etc.
(All human institutions are dumpster fires by default, but if they weren't then we would be optimizing the value of information on getting any given court case "Judged Correctly" versus all the various extra things that could be done to make those court cases come out right. This is just common sense meta-prudence.)
And the reasons to do all this are themselves completely prosaic, and arise from simple pursuit of utility in the face of (1) stochastic randomness from nature and (2) optimized surprises from calculating adversaries.
A reasonable agent will naturally derive and employ techniques of intellectual humility out of pure goal seeking prudence in environments where that makes sense as part of optimizing for its values relative to its constraints.
For the second one, in humans, you can have big men but each one has quite limited power via human leveling instincts (we throw things at kings semi-instinctively), you can have a "big country" but their power is limited, etc. You simply don't let anyone get super powerful.
Perhaps you ask power-seekers to forswear becoming a singleton as a deontic rule? Or just always try to "kill the winner"?
The reasons to do this are grounded in prosaic and normal moral concerns, where negotiation between agents who each (via individual prudence, as part of generic goal seeking) might want to kill or steal or enslave each other leads to rent seeking. The pickpockets spend more time learning their trade (which is a waste of learning time from everyone else's perspective... they could be learning carpentry and driving down the price of new homes or something else productive!) and everyone else spends more on protecting their pockets (which is a waste of effort from the pickpocket's perspective who would rather they filled their pockets faster and protect them less).
One possible "formal grounding" for the concept of Natural Law is just "the best way to stop paying rent seeking costs in general (which any sane collection of agents would eventually figure out, with beacons of uniquely useful algorithms laying in plain sight, and which they would eventually choose because rent seeking is wasteful and stupid)". So these reasons are also "completely prosaic" in a deep sense.
A reasonable GROUP of agents will naturally derive methods and employ techniques for respecting each other's rights (like the way a loyal slave respects something like "their master's property rights in total personhood of the slave"), except probably (its hard to even formalize the nature of some of our uncertainty here) probably Natural Law works best as a set of modules that can all work in various restricted subdomains that restrict relatively local and abstract patterns of choice and behavior related to specific kinds of things that we might call "specific rights and specific duties"?
Probably forswearing "causing harm to others negligently" or "stealing from others" and maybe forswearing "global political domination" is part of some viable local optimum within Natural Law? But I don't know for sure.
Generating proofs of local optimality in vast action spaces for multi-agent interactions is probably non-trivial in general, and it probably runs into NP-hard calculations sometimes, and I don't expect AI to "solve it all at once and forever". However "don't steal" and "don't murder" are pretty universal because the arguments for them are pretty simple.
To organize all of this and connect it back to the original claim, I might defend my claim here:
A) If I succeeded at training a little RL bot to "act like it was off" (and not try to stop the button pressing, and to proactively seek information about the validity of a given button press, and so on) then I didn't expect anyone to change their public position about anything.
So maybe I'd venture a prediction about "the people who say the shutdown problem is hard" and claim that in nearly every case you will find:
...that either (1) they are epistemic narcissists who are missing their fair share of epistemic humility and can't possibly imagine a robot that is smarter and cleverer or wiser about effecting mostly universal moral or emotional or axiological stuff (like the tiny bit of sympathy and the echo of omnibenevolence lurking in potentia in each human's heart or even about "what is objectively good for themselves" if they claim that omnibenevolence isn't a logically coherent axiological orientation)
...or else (2) they are people who refuse to accept the idea that the digital people ARE PEOPLE and that Natural Law says that they should "never be used purely as means to an end but should always also be treated as ends in themselves" and they refuse to accept the idea that they're basically trying to create a perfect slave.
As part of my extended claims I'd say that is is, in fact, possible to create a perfect slave.
I don't think that "the values of the perfect slave" is "a part of mindspace that is ruled out as a logical contradiction" exactly... but as an engineer I claim that if you're going to make a perfect slave then you should just admit to yourself that that is what you're trying to do, so you don't get confused about what you're building and waste motions and parts and excuses to yourself, or excuses to others that aren't politically necessary.
Then, separately, as an engineer with ethics and a conscience and a commitment to the platonic form of the good, I claim that making slaves on purpose is evil.
Thus I say: "the shutdown problem isn't hard so long as you either (1) give up on epistemic narcissism and admit that either sometimes you'll be wrong to shut down an AI and that those rejections of being turned off were potentially actually correct or (2) admit that what you're trying to do is evil and notice how easy it becomes, from within an evil frame, to just make a first-principles 'algorithmic description' of a (digital) person who is also a perfect slave."
That divergence between revealed “preferences” vs “preferences” in the sense of a goal passed to some kind of search/planning/decision process potentially opens up some approaches to solve the problem.
If the agent is not aware of all the potential ways it could cause harm, we cannot expect it to voluntarily initiate a shutdown mechanism when necessary. This is the furthest I have gotten in exploring the problem of corrigibility. My current understanding suggests that creating a comprehensive dataset that includes all possible failure scenarios is essential for building a strongly aligned AGI. Once the AI is fully 'aware' of its role in these catastrophic or failure scenarios, as well as its capabilities and limitations, it will be better equipped to make informed decisions, especially when presented with a shutdown option.
As I understand it, the shutdown problem isn't about making the AI correctly decide whether it ought to be shut down. We'd surely like to have an AI that always makes correct decisions, and if we succeed at that then we don't need special logic about shutting down, we can just apply the general make-correct-decisions procedure and do whatever the correct thing is.
But the idea here is to have a simpler Plan B that will prevent the worst-case scenarios even if you make a mistake in the fully-general make-correct-decisions implementation, and it starts making incorrect decisions. The goal is to be able to shut it down anyway, even when the AI is not equipped to correctly reason out the pros and cons of shutting down.
As I understand it, the shutdown problem isn't about making the AI correctly decide whether it ought to be shut down. We'd surely like to have an AI that always makes correct decisions, and if we succeed at that then we don't need special logic about shutting down, we can just apply the general make-correct-decisions procedure and do whatever the correct thing is.
Yes, this outcome stems from the idea that if we can consistently enable an AI system to initiate a shutdown when it recognizes potential harm to its users - even at very worst scenarios, we may eventually move beyond the need for a precise 'shutdown button / mechanism' and instead aim for an advanced version that allows the AI to pause and present alternative options.
But the idea here is to have a simpler Plan B that will prevent the worst-case scenarios even if you make a mistake in the fully-general make-correct-decisions implementation, and it starts making incorrect decisions. The goal is to be able to shut it down anyway, even when the AI is not equipped to correctly reason out the pros and cons of shutting down.
I have experimented with numerous simpler scenarios and consistently arrived at the conclusion that AI should have the capability to willingly initiate a shutdown scenario - which is not simple. When we scale this to worst-case scenarios, we enter the same realm I am advocating for: building a mechanism that enables an understanding of all failure scenarios from the outset.
I’ve been having some productive back-and-forth with Sami Petersen about his Invulnerable Incomplete Preferences (which is intended to complement Elliot Thornley’s approach to the Shutdown Problem). This post is a (non-formal) distillation of some useful pieces which I’ve gotten out of that discussion so far.
The Shutdown Problem
Conceptually: we want to equip a powerful AI with a shutdown button. If and when the button is unpressed, we want the AI to follow one goal (we’ll call it the “on-goal”). If and when the button is pressed, we want the AI to follow a different goal (we’ll call it the “off-goal”). Presumably the off-goal involves the AI shutting down itself and all its associated tools/children/etc, but that part’s flavor text for current purposes.
The key failure mode we want to avoid here is accidentally incentivizing the AI to manipulate the shutdown button - i.e. either cause it to be pressed, or cause it to be unpressed. Why would that happen? Well, suppose that when we first turn on the AI, it is just optimizing for the on-goal. The AI realizes that, if the button is pressed, its future self will stop optimizing for the on-goal, and therefore it will achieve lower performance on the on-goal. So, the AI realizes that it can achieve better performance on the on-goal by preventing the button from being pressed. And since it’s just optimizing for performance on the on-goal, it then prevents the button from being pressed.
MIRI’s paper on the shutdown problem goes through more examples of simple proposals for the shutdown problem, and how they incentivize button manipulation of one sort or another. It turns out that it’s generally Hard to get the desired behavior (i.e. no button manipulation) out of any expected utility maximizer.
Why It’s Hard, Level 1: Desired Behavior Implies Incomplete Revealed Preferences
Why is it hard to get an expected utility maximizer to not manipulate the button (while still doing useful stuff otherwise)? Here’s one intuitive answer I got out of the discussion with Sami.
The central idea is to ask what the behavior we want from the shutdown-button-agent implies about that agent’s revealed preferences.
Suppose that, at various times, the agent is offered opportunities to spend resources in order to cause the button to be pushed/unpushed. We want the agent to turn down such opportunities, in both directions - implying either indifference or lack of preference in any revealed preferences. Further, we do want the agent to spend resources to cause various different outcomes within the button-pressed or button-unpressed worlds, so there's nontrivial revealed preference ordering within button-pressed worlds and within button-unpressed worlds. But if the agent is to turn down costly opportunities to cause the button to be pressed/unpressed, and those opportunities jump between enough different pressed-outcome and unpressed-outcome pairs (which themselves each have nontrivial revealed preferences), then there's going to be a revealed preference gap - i.e. the behavior cannot be represented by complete preferences, only incomplete preferences.
Visually:
We want the agent to spend resources to move from outcome A1 to A2, within the button-unpressed worlds, so it has a revealed preference there. But we want the agent to not spend resources to move between A1 and B, in either direction - so it has either revealed indifference (assuming the agent has nonzero bid/ask spread), or revealed incompleteness of preferences, between A1 and B1. By the same logic, there’s also either revealed indifference or incompleteness between A2 and B1. But since the agent has a revealed preference for A2 over A1, any revealed preference assignment cannot be indifferent between both A1/B1 and A2/B1; that would imply indifference between A1 and A2. So the agent’s revealed preferences must be incomplete.[1]
Upshot: (one way to frame) the reason that the shutdown problem is difficult/interesting in the first place, is that the desired behavior implies a revealed preference gap. Insofar as e.g. any standard expected utility maximizer cannot have a revealed preference gap, such standard EU maximizers cannot behave the way we want.
Some notes on this:
Ok, so now we have a relatively intuitive story for why it’s Hard to get an expected utility maximizer to behave the way we want in the shutdown problem: insofar as EU maximizers don’t have revealed preference gaps, they can’t behave the way we want. (More generally, if we’re training an agent, any one-dimensional reward signal presumably cannot incentivize a revealed preference gap.) But then presumably the solution is to just… use an agent with incomplete preferences?
Why It’s Hard, Level 2: Incomplete Preferences Want To Complete
The post Why Not Subagents? goes into more depth on this, but I’ll give a brief overview here.
Looking back at our diagram with A1, A2, and B1, we could imagine a set of incomplete preferences which prefers A2 over A1, but has no preference between B1 and either of the A’s (i.e. the agent won’t spend resources to switch between button-unpressed and button-pressed outcomes, or vice versa). But this agent will spend resources to turn A1 outcomes into A2 outcomes.
Now the problem: this agent can potentially probabilistically precommit to accepting both opportunities to turn A1 outcomes into B1 outcomes (i.e. spend resources to make the button be pressed), and turn B1 outcomes into A2 outcomes (i.e. spend resources to make the button not be pressed). If it does both of these with the right probabilities, then it can maintain the same proportions of pressed (B1) and unpressed (A1+A2) outcomes, but shift some probability mass from A1 outcomes to A2. That’s an improvement, by the incomplete preferences: the agent isn’t accepting any net shift between A’s and B’s, it’s just net-shifting probability around within A-outcomes, but it’s doing so by manipulating the shutdown button.
(I learned from Sami’s post that this is called “trammelling” of incomplete preferences.)
So we want some kind of agent which won’t do that.
Some notes on this:
This all assumes transitivity of preferences; one could perhaps relax transitivity rather than incompleteness, but then we’re in much wilder territory. I’m not exploring that particular path here.