This is a special post for quick takes by Lao Mein. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
Sam Altman has made many enemies in his tenure at OpenAI. One of them is Elon Musk, who feels betrayed by OpenAI, and has filed failed lawsuits against the company. I previously wrote this off as Musk considering the org too "woke", but Altman's recent behavior has made me wonder if it was more of a personal betrayal. Altman has taken Musk's money, intended for an AI safety non-profit, and is currently converting it into enormous personal equity. All the while de-emphasizing AI safety research.
Musk now has the ear of the President-elect. Vice-President-elect JD Vance is also associated with Peter Thiel, whose ties with Musk go all the way back to PayPal. Has there been any analysis on the impact this may have on OpenAI's ongoing restructuring? What might happen if the DOJ turns hostile?
[Following was added after initial post]
I would add that convincing Musk to take action against Altman is the highest ROI thing I can think of in terms of decreasing AI extinction risk.
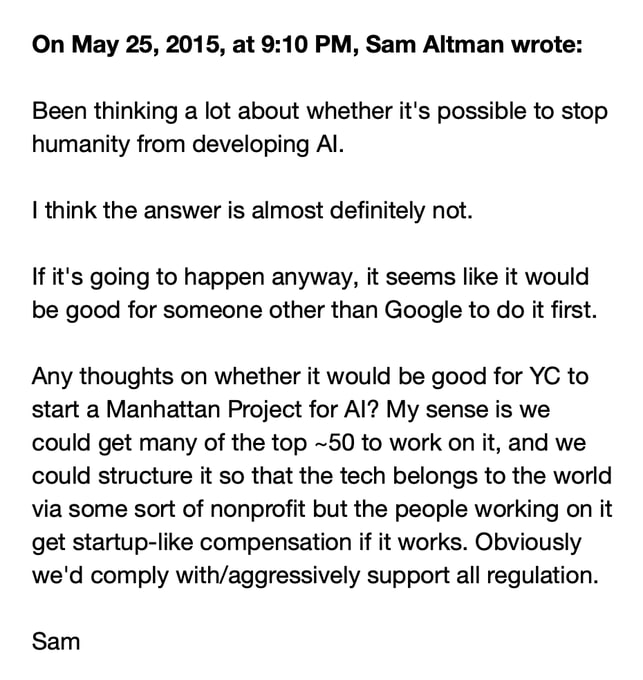
Internal Tech Emails on X: "Sam Altman emails Elon Musk May 25, 2015 https://t.co/L1F5bMkqkd" / X
In the email above, clearly stated, is a line of reasoning that has lead very competent people to work extremely hard to build potentially-omnicidal machines.
Absolutely true.
But also Altman's actions since are very clearly counter to the spirit of that email. I could imagine a version of this plan, executed with earnestness and attempted cooperativeness, that wasn't nearly as harmful (though still pretty bad, probably).
Part of the problem is that "we should build it first, before the less trustworthy" is a meme that universalizes terribly.
Part of the problem is that Sam Altman was not actually sincere in the the execution of that sentiment, regardless of how sincere his original intentions were.
It's not clear to me that there was actually an option to build a $100B company with competent people around the world who would've been united in conditionally shutting down and unconditionally pushing for regulation. I don't know that the culture and concepts of people who do a lot of this work in the business world would allow for such a plan to be actively worked on.
2
You maybe right. Maybe the top talent wouldn't have gotten on board with that mission, and so it wouldn't have gotten top talent.
I bet Illya would have been in for that mission, and I think a surprisingly large number of other top researchers might have been in for it as well. Obviously we'll never know.
And I think if the founders are committed to a mission, and they reaffirm their commitment in every meeting, they can go surprisingly far in making in the culture of an org.
2
Maybe there's a hope there, but I'll point out that many of the people needed to run a business (finance, legal, product, etc) are not idealistic scientists who would be willing to have their equity become worthless.
2
Those people don't get substantial equity in most business in the world. They generally get paid a salary and benefits in exchange for their work, and that's about it.
2
I know little enough that I don't know whether this statement is true. I would've guessed that in most $10B companies anyone with a title like "CFO" and "CTO" and "COO" is paid primarily in equity, but perhaps this is mostly true of a few companies I've looked into more (like Amazon).
2
Ilya is demonstrably not in on that mission, since his step immediately after leaving OpenAI was to found an additional AGI company and thus increase x-risk.
4
I don't think that's a valid inference.
2
Also, Sam Altman is a pretty impressive guy. I wonder what would have happened if he had decided to try to stop humanity from building AGI, instead of trying to be the one to do it instead of google.
That might very well help, yes. However, two thoughts, neither at all well thought out:
- If the Trump administration does fight OpenAI, let's hope Altman doesn't manage to judo flip the situation like he did with the OpenAI board saga, and somehow magically end up replacing Musk or Trump in the upcoming administration...
- Musk's own track record on AI x-risk is not great. I guess he did endorse California's SB 1047, so that's better than OpenAI's current position. But he helped found OpenAI, and recently founded another AI company. There's a scenario where we just trade extinction risk from Altman's OpenAI for extinction risk from Musk's xAI.
and recently founded another AI company
Potentially a hot take, but I feel like xAI's contributions to race dynamics (at least thus far) have been relatively trivial. I am usually skeptical of the whole "I need to start an AI company to have a seat at the table", but I do imagine that Elon owning an AI company strengthens his voice. And I think his AI-related comms have mostly been used to (a) raise awareness about AI risk, (b) raise concerns about OpenAI/Altman, and (c) endorse SB1047 [which he did even faster and less ambiguously than Anthropic].
The counterargument here is that maybe if xAI was in 1st place, Elon's positions would shift. I find this plausible, but I also find it plausible that Musk (a) actually cares a lot about AI safety, (b) doesn't trust the other players in the race, and (c) is more likely to use his influence to help policymakers understand AI risk than any of the other lab CEOs.
I'm sympathetic to Musk being genuinely worried about AI safety. My problem is that one of his first actions after learning about AI safety was to found OpenAI, and that hasn't worked out very well. Not just due to Altman; even the "Open" part was a highly questionable goal. Hopefully Musk's future actions in this area would have positive EV, but still.
7
I think that xAI's contributions have been minimal so far, but that could shift. Apparently they have a very ambitious data center coming up, and are scaling up research efforts quickly. Seems very accelerate-y.
2
Update from the future: they did.
6
I think Elon's strategy of "telling the world not to build AGI, and then going to start another AGI company himself" is much less dumb / ethical fraught, than people often credit.
2
If Trump dies, Vance is in charge, and he's previously espoused bland eaccism.
I keep thinking: Everything depends on whether Elon and JD can be friends.
5
I don't think Vance is e/acc. He has said positive things about open source, but consider that the context was specifically about censorship and political bias in contemporary LLMs (bolding mine):
The words I've bolded indicate that Vance is at least peripherally aware that the "tech people [...] complaining about safety" are a different constituency than the "DEI bullshit" he deplores. If future developments or rhetorical innovations persuade him that extinction risk is a serious concern, it seems likely that he'd be on board with "bipartisan efforts to regulate for safety."
How would removing Sam Altman significantly reduce extinction risk? Conditional on AI alignment being hard and Doom likely the exact identity of the Shoggoth Summoner seems immaterial.
7
Just as one example, OpenAI was against SB 1047, whereas Musk was for it. I'm not optimistic about regulation being enough to save us, but presumably they would be helpful, and some AI companies like OpenAI were against even the limited regulations of SB 1047. Plus SB 1047 also included stuff like whistleblower protections, and that's the kind of thing that could help policymakers make better decisions in the future.
8
I would expect, the issue isn't about convincing Musk to take action but about finding effective actions that Musk could take.
2
For what it's worth—even granting that it would be good for the world for Musk to use the force of government for pursuing a personal vendetta against Altman or OAI—I think this is a pretty uncomfortable thing to root for, let alone to actively influence. I think this for the same reason that I think it's uncomfortable to hope for—and immoral to contribute to—assassination of political leaders, even assuming that their assassination would be net good.
4
I don't understand the reference to assassination. Presumably there are already laws on the books that outlaw trying to destroy the world (?), so it would be enough to apply those to AGI companies.
3
Notably, no law I know of allows you to take legal action on a hunch that they might destroy the world based on your probability of them destroying the world being high without them doing any harmful actions (and no, building AI doesn't count here.)
2
What if whistleblowers and internal documents corroborated that they think what they're doing could destroy the world?
3
Maybe there's a case there, but I'd doubt it get past a jury, let alone result in any guilty verdicts.
2
I'm quite happy for laws to be passed and enforced via the normal mechanisms. But I think it's bad for policy and enforcement to be determined by Elon Musk's personal vendettas. If Elon tried to defund the AI safety institute because of a personal vendetta against AI safety researchers, I would have some process concerns, and so I also have process concerns when these vendettas are directed against OAI.
Apparently a lot of H200s were stuck in Chinese customs for a while, spawning conspiracies about top-down directives.
People who don't regularly deal with Chinese customs may not realize that they are genuinely the single most corrupt, incompetent, and evil section of the Chinese government. Over the past 5 years, I have literally never heard about anything bribe-related that wasn't about Customs. They lost 4 seperate copies of my diploma during COVID. They will sometimes "lose" biological samples if not paid a bribe.
All a foreign adversary would need to do to delay hardware shipments to Chinese firms is to pay $500 over WeChat to some mid-level bureaucrat at Customs. Maybe that's what actually happened.
5
Hmm, but can't the megacorporations involved in the H200 transaction also bribe Customs? Won't your $500 WeChat bribe to the mid-level bureaucrat be cancelled and overwhelmed by the many $5,000 WeChat bribes flying at them by the corporations eagerly awaiting their shipment of H200s?
I've never actually bribed a Customs official, so I don't know the exact process. I think they can initiate extra inspections, which can't be cancelled, but can be sped up?
Perhaps customs notices that both parties have deep pockets, and it's become a negotiation, further slowed by the fact that the negotiation has to happen entirely under the table.
5
Maybe the idea is that if a spanner is thrown in the works, you can't necessarily have someone else unthrow that spanner?

Some times "If really high cancer risk factor 10x the rate of a certain cancer, then the majority of the population with risk factor would have cancer! That would be absurd and therefore it isn't true" isn't a good heuristic. Some times most people on a continent just get cancer.
6
Most typical skin cancer is basiloma - and it is rather benign - no metastases and can be removed without hospitalization. Many people get it.
Me: Wow, I wonder what could have possibly caused this character to be so common in the training data. Maybe it's some sort of code, scraper bug or...
Some asshole in 2006:
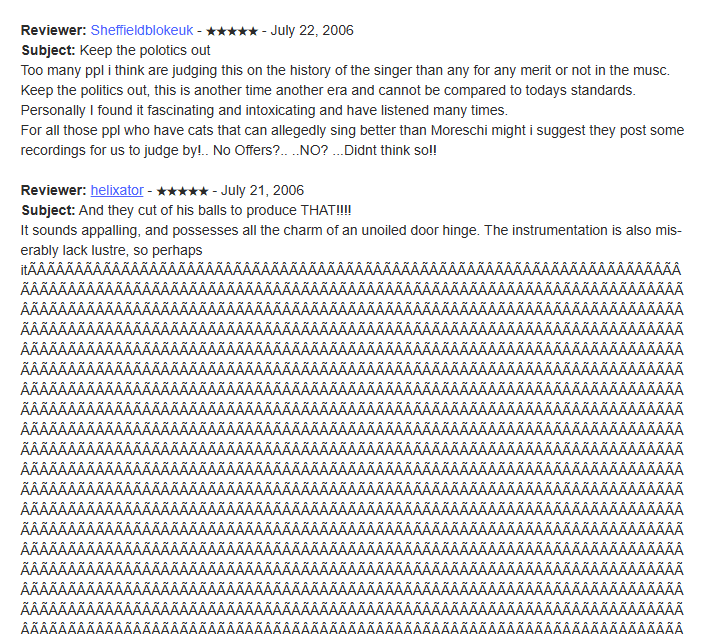
Ave Maria : Alessandro Moreschi : Free Download, Borrow, and Streaming : Internet Archive
Carnival of Souls : Free Download, Borrow, and Streaming : Internet Archive
There's 200,000 instances "Â" on 3 pages of archive.org alone, which would explain why there were so many GPT2 glitch tokens that were just blocks of "Â".
“Ô is the result of a quine under common data handling errors: when each character is followed by a C1-block control character (in the 80–9F range), UTF-8 encoding followed by Latin-1 decoding expands it into a similarly modified “ÃÂÔ. “Ô by itself is a proquine of that sequence. Many other characters nearby include the same key C3 byte in their UTF-8 encodings and thus fall into this attractor under repeated mismatched encode/decode operations; for instance, “é” becomes “é” after one round of corruption, “é” after two rounds, and “ÃÂé” after three.
(Edited for accuracy; I hadn't properly described the role of the interleaved control characters the first time.)
2
Any idea how it could happen to the point of 10,000s of consecutive characters? Below is a less extreme example from archive.org where it replaced punctuation some with 16 of them.
Grateful Dead Live at Manor Downs on 1982-07-31 : Free Borrow & Streaming : Internet Archive
Well, the expansion is exponential, so it doesn't take that many rounds of bad conversions to get very long strings of this. Any kind of editing or transport process that might be applied multiple times and has mismatched input and output encodings could be the cause; I vaguely remember multiple rounds of “edit this thing I just posted” doing something similar in the 1990s when encoding problems were more the norm, but I don't know what the Internet Archive or users' browsers might have been doing in these particular cases.
Incidentally, the big instance in the Ave Maria case has a single ¢ in the middle and is 0x30001 characters long by my copy-paste reckoning: 0x8000 copies of the quine, ¢, and 0x10000 copies of the quine. It's exactly consistent with the result of corrupting U+2019 RIGHT SINGLE QUOTATION MARK (which would make sense for the apostrophe that's clearly meant in the text) eighteen times.
2
Thanks!
For cross-reference purposes for you and/or future readers, it looks like Erik Søe Sørensen made a similar comment (which I hadn't previously seen) on the post “SolidGoldMagikarp III: Glitch token archaeology” a few years ago.

This is extremely weird - no one actually writes like this in Chinese. "等一下" is far more common than "等待一下", which seems to mash the direct translation of the "wait" [等待] in "wait a moment" - 等待 is actually closer to "to wait". The use of “所以” instead of “因此” and other tics may also indicate the use of machine-translated COT from English during training.
The funniest answer would be "COT as seen in English GPT4-o1 logs are correlated with generating quality COT. Chinese text is also correlated with highly rated COT. Therefore, using the grammar and structure of English GPT4 COT but with Chinese tokens elicits the best COT".
6
I don't see why there would necessarily be machine-translated inner-monologues, though.
If they are doing the synthesis or stitching-together of various inner-monologues with the pivot phrases like "wait" or "no, that's wrong", they could simply do that with the 'native' Chinese versions of every problem rather than go through a risky lossy translation pass. Chinese-language-centric LLMs are not so bad at this point that you need to juice them with translations of English corpuses - are they?
Or if they are using precanned English inner-monologues from somewhere, why do they need to translate at all? You would think that it would be easy for multi-lingual models like current LLMs, which so easily switch back and forth between languages, to train on o1-style English inner-monologues and then be able to 'zero-shot' generate o1-style Chinese inner-monologues on demand. Maybe the weirdness is due to that, instead: it's being very conservative and is imitating the o1-style English in Chinese as literally as possible.
9
I'm at ~50-50 for large amounts of machine-translated being present in the dataset.
Having worked in Chinese academia myself, "use Google Translate on the dataset" just seems like something we're extremely likely to do. It's a hard-to-explain gut feeling. I'll try poking around in the tokenizer to see if "uncommon Chinese phrases that would only appear in machine-translated COT" are present as tokens. (I think this is unlikely to be true even if they did do it, however)
I've done a cursory internet search, and it seems that there aren't many native Chinese COT datasets, at least compared to English ones - and one of the first results on Google is a machine-translated English dataset.
I'm also vaguely remembering o1 chain of thought having better Chinese grammar in its COT, but I'm having trouble finding many examples. I think this is the easiest piece of evidence to check - if other (non-Chinese-origin) LLMs consistently use good Chinese grammar in their COT, that would shift my probabilities considerably.
The announcement of Stargate caused a significant increase in the stock price of GE-Vernona, albeit at a delay. This is exactly what we would expect to see if the markets expect a significant buildout of US natural gas electrical capacity, which is needed for a large datacenter expansion. I once again regret not buying GE-Vernona calls (the year is 2026. OpenAI announces AGI. GE Vernova is at 20,000. I once again regret not buying calls).
This goes against my initial take that Stargate was a desperate attempt by Altman to not get gutted by Musk - he offers a grandiose economic project to Trump to prove his value, mostly to buy time for the for-profit conversion of OpenAI to go through. The markets seem to think it's real-ish.
Hm, that's not how it looks like to me? Look at the 6-months plot:
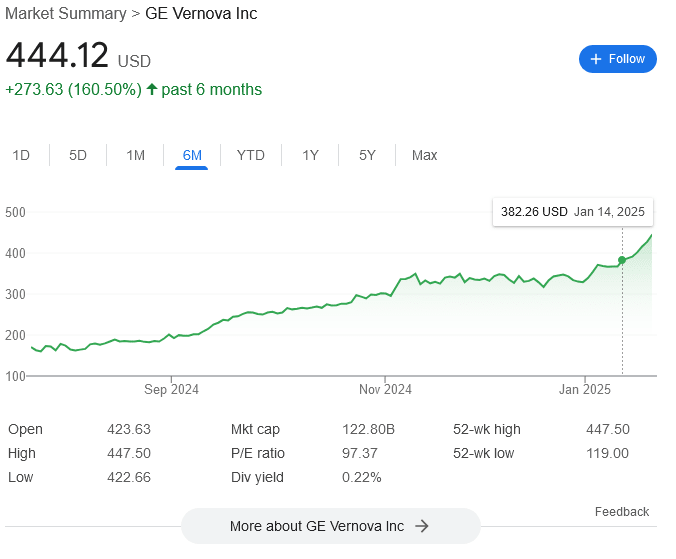
The latest growth spurt started January 14th, well before the Stargate news went public, and this seems like just its straight-line continuation. The graph past the Stargate announcement doesn't look "special" at all. Arguably, we can interpret it as Stargate being part of the reference class of events that are currently driving GE Vernova up – not an outside-context event as such, but still relevant...
Except for the fact that the market indeed did not respond to Stargate immediately. Which makes me think it didn't react at all, and the next bump you're seeing is some completely different thing from the reference class of GE-Vernova-raising events (to which Stargate itself does not in fact belong).
Which is probably just something to do with Trump's expected policies. Note that there was also a jump on November 4th. Might be some general expectation that he's going to compete with China regarding energy, or that he'd cut the red tape on building plants for his tech backers.
In which case, perhaps it's because Stargate was already priced-in – or at least whichever fraction of Stargate ($30-$100 billion?) is real and is ...
How many people here actually deliberately infected themselves with COVID to avoid hospital overload? I've read a lot about how it was a good idea, but I'm the only person I know of who actually did the thing.
Was it a good idea? Hanson's variolation proposal seemed like a possibly good idea ex ante, but ex post, at first glance, it now looks awful to me.
It seems like the sort of people who would do that had little risk of going to the hospital regardless, and in practice, the hospital overload issue, while real and bad, doesn't seem to have been nearly as bad as it looked when everyone thought that a fixed-supply of ventilators meant every person over the limit was dead and to have killed mostly in the extremes where I'm not sure how much variolation could have helped*. And then in addition, variolation became wildly ineffective once the COVID strains mutated again - and again - and again - and again, and it turned out that COVID was not like cowpox/smallpox and a once-and-never-again deal, and if you got infected early in 2020, well, you just got infected again in 2021 and/or 2022 and/or 2023 probably, so deliberate infection in 2020 mostly just wasted another week of your life (or more), exposed you to probably the most deadly COVID strains with the most disturbing symptoms like anosmia and possibly the highest Long COVID rates (because they mutated to be subtler and more tolerable an...
4
That's a pretty good point - I was mostly thinking from my position, which was the rapid end of lockdowns in China in late 2022. I had a ~100% chance of catching COVID within a month, and had no idea how prepared the hospitals were in regards to that. I ended up with a really bad cough and secondary lung infection that made me consider going to the hospital, so I guess I made the right choice? If I did develop pneumonia, I would have looked foward to a less crowded hospital with more amenities, which would have been nice. My decision was also based on the possibility of "this may be worse than expected and the hospitals will somehow fuck it up", which thankfully didn't take place.
But yeah, I didn't consider the consequences pozing yourself in 2020/2021. I agree with you that it's a bad idea in hindsight for almost everyone. I was one of the few people who could have benefited from it in theory, and all I really got was internet bragging rights.
Still very curious about those who did variolate themselves and their reasoning behind it.
I previously made a post that hypothesized a combination of the extra oral ethanol from Lumina and genetic aldehyde deficiency may lead to increased oral cancer risks in certain population. It has been cited in a recent post about Lumina potentially causing blindness in humans.
I've found that hypothesis less and less plausible ever since I published that post. I still think it is theoretically possible in a small proportion (extremely bad oral hygene) of the aldehyde deficient population, but even then it is very unlikely to raise the oral cancer incidence above the Asian average (aldehyde deficiency->less ethanol consumption->less oral cancer overall despite aldehyde deficiency causing increased oral cancer rates for a given ethanol consumption level). I notice in my unpublished followup that my best guess is that Lumina is still a (very small) net negative for me, but I would apply it if offered for free because I am for biological self-experimentation on moral principle, it would be a clear signal for being (mostly) wrong on the mangitude implied in my previous post, and because it sounds cool.
But the methanol blindness claim I've seen circulating lately is completel...
1
Yeah, my idea is just based on physical proximity. There's no way systemic concentrations would be enough, plus the E. Coli in the gut produce way more formate in total given the much larger surface area... yet I can't ignore that my mouth is directly below my eyes. I'm totally willing to bet on it, though I don't know how you'd judge something like this. Formate optic neuropathy doesn't necessarily have specific signs, though in the two case reports it does follow a progressive course and then suddenly get much worse. Is it just based on whether I end up becoming one of the mysterious idiopathic optic neuropathy cases AND test positive for Lumina if they ever come out with their testing kit thing?
Either way please do explain your reasoning on this, I'm looking for some reason to imagine I'm not totally done for but I haven't been able to come up with anything myself.
Very confused why "the US economy contains a lot of middlemen, who can just absorb massive taxes without passing them on to the consumer" is only ever used as a handwave for explaining the unexpectedly low rate of inflation. I've seen multiple people (including normally level-headed people like Ezra Klein!) bring this up briefly, but never examine the concept in detail. If true, it's a big deal, since that's a lot of consumer surplus to be gained (presumably by limiting zero-sum advertising games?), and this issue deserves much more attention! Maybe it jus...
3
Not sure about the exact context of what you write, but fwiw:
* Intuitively agree partly that "many can absorb massive taxes w/o passing through to customers" could be justified on many individual cases: with low marginal cost production tech, your optimal sales price is roughly independent of the tax rate you pay: profit maximization becomes revenue maximization, which is entirely dependent on the demand curve only, and thus your sales price & qty sold won't budge because of e.g. a VAT like tax rate increase.
* Similarly, if tax is a profit tax, absence of price-increase effect can be even more easily expected
On the other hand, if you increase taxes, even if the above is strictly speaking true, it's not true for all types of actors at all, and, maybe most importantly:
* Note also, higher taxes, even for workers, may much simply "prevent" economic activity (which basic economic models imho wrongly tend to focus on), but instead makes actors do three costly and bad things: (i) illegally hide (black markets), (ii) tweak activity (for real or in the books) to adjacent but less taxed ones, (iii) evade by relocating activity to jurisdictions with less taxes (physically or digitally, again genuine or gray-area or more illegal-but-difficult-to-catch ones). Taken together these are powerful forces, esp. if unhinged intl tax competition has many jurisdictions aggressively trying to attract any tax substrate from anywhere.
3
I was specifically refering to US import tariffs on consumer goods.
Found a really interesting pattern in GPT2 tokens:
The shortest variant of a word " volunte" has a low token_id but is also very uncommon. The actual full words end up being more common.
Is this intended behavior? The smallest token tend to be only present in relatively rare variants or just out-right misspellings: " he volunteeers to"
It seems that when the frequency drops below a limit ~15 some start exhibiting glitchy behavior. Any ideas for why they are in the tokenizer if they are so rare?
Of the examples below, ' practition' and 'ortunately' exhibi...
3
Isn't this a consequence of how the tokens get formed using byte pair encoding? It first constructs ' behavi' and then it constructs ' behavior' and then will always use the latter. But to get to the larger words, it first needs to create smaller tokens to form them out of (which may end up being irrelevant).
Edit: some experiments with the GPT-2 tokenizer reveal that this isn't a perfect explanation. For example " behavio" is not a token. I'm not sure what is going on now. Maybe if a token shows up zero times, it cuts it?
3
...They didn't go over the tokens at the end to exclude uncommon ones?
Because we see this exact same behavior in the GPT4o tokenizer too. If I had to guess, the low frequency ones make up 0.1-1% of total tokens.
This seems... obviously insane? You're cooking AI worth $billions and you couldn't do a single-line optimization? At the same time, it explains why usernames were tokenized multiple times ("GoldMagikarp", " SolidGoldMagikarp", ect.) even though they should only appear as a single string, at least with any frequency.
8
Remember, the new vocab was also full of spam tokens like Chinese porn, which implies either (1) those are dead tokens never present in the training data and a waste of vocab space, or (2) indicates the training data has serious problems if it really does have a lot of porn spam in it still. (There is also the oddly large amount of chess games that GPT-4 was trained on.) This is also consistent with the original GPT-3 seeming to have been trained on very poorly reformatted HTML->text.
My conclusion has long been that OAers are in a hurry and give in to the usual ML researcher contempt for looking at & cleaning their data. Everyone knows you're supposed to look at your data and clean it, but no one ever wants to eat their vegetables. So even though these are things that should take literally minutes to hours to fix and will benefit OA for years to come as well as saving potentially a lot of money...
3
This comment helped me a lot - I was very confused about why I couldn't find Chinese spam in my tokens and then realized I had been using the old GPT4 tokenizer all along.
The old GPT4 tokenizer was actually very clean by comparison - every Chinese token was either common conversational Chinese or coding-related (Github, I assume - you see the same pattern with other languages).
I vaguely remember people making fun of a Chinese LLM for including CCP slogans in their tokenizer, but GPT4o also has 193825 [中国特色社会主义] (Socialism with Chinese characteristics).
It's actually crazy because something like 1/3 of Chinese tokens are spam.
The devil's advocate position would be that glitch token behavior (ignore and shift attention down one token) is intended and helps scale data input. It allows the extraction of meaningful information from low-quality spam-filled webpages without the spam poisoning other embeddings.
Longest Chinese tokens in gpt4o · GitHub
chinese-tokens-in-tiktoken/chinese_tokens_o200k_base.tsv at main · secsilm/chinese-tokens-in-tiktoken · GitHub
6
My guess is that they are just lazy and careless about the tokenization/cleaning pipeline and never looked at the vocab to realize it's optimized for the pre-cleaning training corpus, and they are not actually trying to squeeze blood out of the stone of Chinese spam. (If they actually had trained on that much Chinese spam, I would expect to have seen a lot more samples of that, especially from the papers about tricking GPT-4 into barfing out memorized training data.)
5
Note if you are doubtful about whether OA researchers would really be that lazy and might let poor data choices slide by, consider that the WSJ is reporting 3 days ago that Scale, the multi-billion-dollar giant data labeler, whose job is creating & cleaning data for the past decade, last year blew a Facebook contract when the FB researchers actually looked at their data and noticed a lot of it starting "As an AI language model...":
As usual, Hanlon's razor can explain a lot about the world. (Amusingly, the HuggingFace "No Robots" instruction-tuning dataset advertises itself as "Look Ma, an instruction dataset that wasn't generated by GPTs!")
3
OK, I'm starting to see your point. Why do you think OpenAI is so successful despite this? Is their talent and engineering direction just that good? Is everyone else even worse at data management?
7
They (historically) had a large head start(up) on being scaling-pilled and various innovations like RLHF/instruction-tuning*, while avoiding pathologies of other organizations, and currently enjoy some incumbent advantages like what seems like far more compute access via MS than Anthropic gets through its more limited partnerships. There is, of course, no guarantee any of that will last, and it generally seems like (even allowing for the unknown capabilities of GPT-5 and benefits from o1 and everything else under the hood) the OA advantage over everyone else has been steadily eroding since May 2020.
* which as much as I criticize the side-effects, have been crucial in democratizing LLM use for everybody who just wants to something done instead of learning the alien mindset of prompt-programming a base model
4
That paper was released in November 2023, and GPT4o was released in May 2024. Old GPT4 had relatively normal Chinese tokens.
7
But the attacks probably still work, right? And presumably people have kept researching the topic, to understand the 'o' part of 'GPT-4o'. (My hypothesis has been that the 'secret' tokens are the modality delimiters and the alternate modalities, and so figuring out how to trick GPT-4o into emitting or talking about them would yield interesting results, quite aside from barfing out spam.) I haven't seen anything come up on Twitter or in tokenization discussions, so my inference is that it probably just wasn't trained on that much spam and the spam was removed after the tokenization but before the training, due to sloppiness in the pipeline. Otherwise, how do you explain it all?
5
But research by whom? Chinese research is notoriously siloed. GPT4 access is non-trivially restricted. There have been zero peeps about digging into this on Chinese forums, where there is little discussion in general about the paper. I remember it being mocked on Twitter as being an extremely expensive way to pirate data. It's just not that interesting for most people.
My experience with GPT2 is that out-of-context "glitch" tokens are mostly ignored.
prompts:
" Paris is theÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂ capital of"
" Paris is the capital of"
" Paris is theÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂ capital of the world's largest and most populous Arab country, and is one of the largest cities in the world with an area of 1.6 million people (more than half of them in Paris alone). It is home to"
" Paris is the capital of France, and its capital is Paris. The French capital has a population of about 6.5 billion (more than half of the world's population), which is a huge number for a city of this size. In Paris"
" Paris is theÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂ capital of France, the largest state in France and one of the wealthiest in the world. The capital of Paris is home to over 1.2 billion people, and the country's economy is growing at a rapid clip. It"
' Paris is the capital of the European Union. Its population is about 3,500, and it has been under EU sanctions for more than a year. The EU\'s top diplomat has described the bloc as "a global power".\n\nFrance\'s'
Even glitch tokens like ⓘ, which has an extremely strong association with geology archives, only has partial effect if it's present out of context.
" Paris is theⓘ capital of the French province of Lille. This region is the most important in the world, having the largest concentration of mines in Europe, with the highest levels of unemployment. The
' Paris is theⓘ capital of the province of France. The town has been in existence for more than 2,000 years.\n\nⓘ Montmartre Mine Céline-Roule, M., and Céline,
>No paper, not even a pre-print
>All news articles link to a not-yet-released documentary as the sole source. It doesn't even have a writeup or summary.
>The company that made it is know for making "docu-dramas"
>No raw data
>Kallmann Syndrome primarily used to mock Hitler for having a micropenis
Yeah, I don't think the Hitler DNA stuff is legit.
US markets are not taking the Trump tariff proposals very seriously - stock prices increased after the election and 10-year Treasury yields have returned to pre-election levels, although they did spike ~0.1% after the election. Maybe the Treasury pick reassured investors?
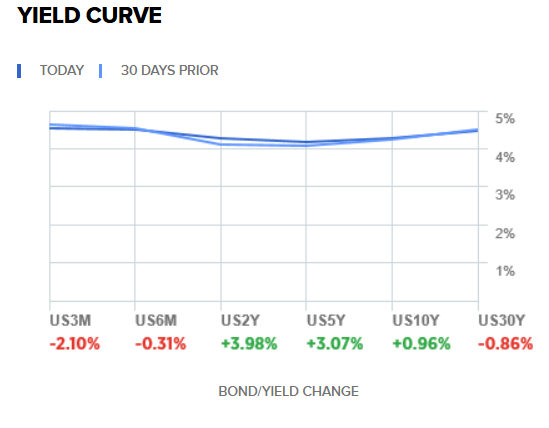
https://www.cnbc.com/quotes/US10Y
If you believe otherwise, I encourage you to bet on it! I expected both yields and stocks to go up and am quite surprised.
I'm not sure what the markets expect to happen - Trump uses the threat of tariffs to bully Europeans for diplomatic concessions, who th...
1
Musk met with Iran ambassador. maybe the market thinks they cut a deal?
4
The meeting allegedly happened on the 11th. The Iranian market rallied immediately after the election. It was clearly based on something specific to a Trump administration. Maybe it's large-scale insider trading from Iranian diplomats?
I also think the market genuinely, unironically disbelieves everything Trump says about tariffs in a way they don't about his cabinet nominations (pharma stocks tanked after RFK got HHS).
The man literally wrote that he was going to institute 25% tariffs on Canadian goods, to exactly zero movement on Canadian stocks.
2
That Iran thing is weird.
If I were guessing I might say that maybe this is happening:
Right now the more trade China has with Iran the more America might make a fuss. Either complaining politically, putting tariffs, or calling on general favours and good will for it to stop. But if America starts making a fuss anyway, or burns all its good will, then their is suddenly no downside to trading with Iran. Now substitute "China" for any and all countries (for example the UK, France and Germany, who all stayed in the Iran Nuclear Deal even after the USA pulled out).
Is there a thorough analysis of OpenAI's for-profit restructuring? Surely, a Delaware lawyer who specializes in these types of conversions has written a blog somewhere.
I don't believe there are any details about the restructuring, so a detailed analysis is impossible. There have been a few posts by lawyers and quotes from lawyers, and it is about what you would expect: this is extremely unusual, the OA nonprofit has a clear legal responsibility to sell the for-profit for the maximum $$$ it can get or else some even more valuable other thing which assists its founding mission, it's hard to see how the economics is going to work here, and aspects of this like Altman getting equity (potentially worth billions) render any conversion extremely suspect as it's hard to see how Altman's handpicked board could ever meaningfully authorize or conduct an arms-length transaction, and so it's hard to see how this could go through without leaving a bad odor (even if it does ultimately go through because the CA AG doesn't want to try to challenge it).
My takeaway from the US elections is that electoral blackmail in response to party in-fighting can work, and work well.
Dearborn and many other heavily Muslim areas of the US had plurality or near-plurality support for Trump, along with double-digit vote shares for Stein. It's notable that Stein supports cutting military support for Israel, which may signal a genuine preference rather than a protest vote. Many previously Democrat-voting Muslims explicitly cited a desire to punish Democrats as a major motivator for voting Trump or Stein.
Trump also has the ad...
6
Democrats lost by sufficient margins, and sufficiently broadly, that one can make the argument that any pet cause is a responsible or contributing factor. But that seems like entirely the wrong level of analysis to me. See this FT article called "Democrats join 2024’s graveyard of incumbents", which includes this striking graph:
So global issues like inflation and immigration seem like much better explanatory factors to me, rather than things like the Gaza conflict which IIRC never made the top 10 in any issue polling I saw.
(The article may be paywalled; I got the unlocked version by searching Bing for "ft every governing party facing election in a developed country".)
2
Sure, if Muslim Americans voted 100% for Harris, she still would have lost (although she would have flipped Michigan). However, I just don't see any way Stein would have gotten double digits in Dearborn if Muslim Americans weren't explicitly retaliating against Harris for the Biden administration's handling of Gaza.
But 200,000 registered voters in a state Trump won by 80,000 is a critical demographic in a swing state like Michigan. The exit polls show a 40% swing in Dearborn away from Democrats, enough for "we will vote Green/Republican if you give us what we want" to be a credible threat, which I'm seen some (maybe Scott Alexander?) claim isn't possible, as it would require a large group of people to coordinate to vote against their interests. Seemingly irrational threats ("I will vote for someone with a worse Gaza policy than you if you don't change your Gaza policy") are entirely rational if you have a track record of actually carrying them out.
On second thought, a lot of groups swung heavily towards Trump, and it's not clear that Gaza is responsible for the majority of it amongst Muslim Americans. I should do more research.
2
You can't trust exit polls on demographics crosstabs. From Matt Yglesias on Slow Boring:
4
I misspoke. I was using the actual results from Dearborn, and not exit polls. Note how differently they voted from Wayne County as a whole!

Currently looking at some of the example problems used to assess AI capabilities in this paper. This... obviously doesn't work as intended? Based only on recall (no search), Deepseek answers these questions somewhat well, getting 2/3 attempts for the first, 0/3 for the second, [assumes Star Wars refers to Episode I and gives the answer for that movie, changes to correct answer after clarification, so either 0/3 or 3/3]. It identifies Satan, but misidentifies the squished animal as a cat for #4 in all 3 tests. So a model with zero visual ...
My big problem with METR time horizons as a useful metric is that they start to break down exactly when things get interesting, after the 1 hour mark. I think this is because the benchmark is based on the pool of [people available to METR via friend/professional networks and also randoms from Task Rabbit], and there aren't enough people in that pool with time horizons much longer that 1 hour to set a consistant metric.
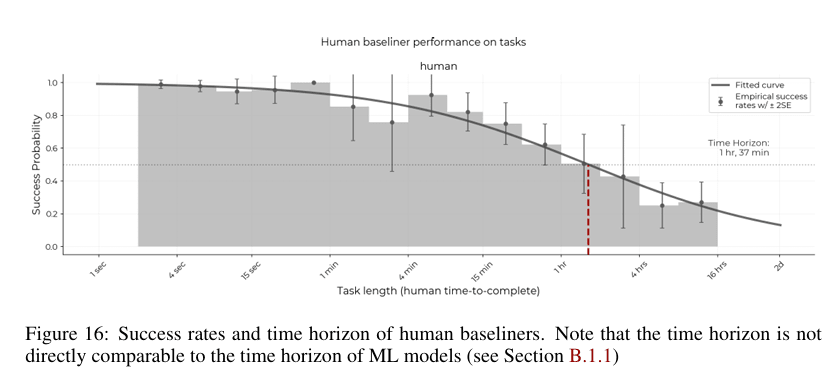
I think there are actual human beings who can complete actual 16 hour+ time horizon tasks, but people like that...
3
The baseliners are described in the paper as
(pg. 7)
I think it's unlikely that AIs are talking people who otherwise wouldn't have developed psychosis on their own into active psychosis. AIs can talk people into really dumb positions and stroke their ego over "discovering" some nonsense "breakthrough" in mathematics or philosophy. I don't think anyone disputes this.
But it seems unlikely that AIs can talk someone into full-blown psychosis who wouldn't have developed something similar at a later time. Bizarre beliefs aren't the central manifestation of psychosis, but are simply the most visible symptom. A norm...
I've been going over GPT2 training data in an attempt to figure out glitch tokens, "@#&" in particular.
Does anyone know what the hell this is? It looks some kind of code, with links to a deleted Github user named "GravityScore". What format is this, and where is it from?

but == 157)) then !@#& term.setCursorBlink(false)!@#& return nil!@#& end!@#& end!@#& end!@#& local a = sendLiveUpdates(e, but, x, y, p4, p5)!@#& if a then return a end!@#& end!@#&!@#& term.setCursorBlink(false)!@#& if line ~= nil t...
It looks like Minecraft stuff (like so much online). "GravityScore" is some sort of Minecraft plugin/editor, Lua is a common language for game scripting (but otherwise highly unusual), the penis stuff is something of a copypasta from a 2006 song's lyrics (which is a plausible time period), ZudoHackz the user seems to have been an edgelord teen... The gibberish is perhaps Lua binary bytecode encoding poorly to text or something like that; if that is some standard Lua opcode or NULL, then it'd show up a lot in between clean text like OS calls or string literals. So I'm thinking something like an easter egg in a Minecraft plugin to spam chat for the lolz, or just random humor it spams to users ("Warning: Logging in will make you a nerd").
7
The identifiable code chunks look more specifically like they're meant for ComputerCraft, which is a Minecraft mod that provides Lua-programmable in-game computers. Your link corroborates this: it's within the ComputerCraft repository itself, underneath an asset path that provides files for in-game floppy disks containing Lua programs that players can discover as dungeon loot; GravityScore is a contributor with one associated loot disk, which claims to be an improved Lua code editor. The quoted chunk is slightly different, as the “availableThemes” paragraph is not commented out—probably a different version. Lua bytecode would be uncommon here; ComputerCraft programs are not typically stored in bytecode form, and in mainline Lua 5.2 it's a security risk to enable bytecode loading in a multitenant environment (but I'm not sure about in LuaJ).
The outermost structure starting from the first image looks like a Lua table encoding a tree of files containing an alternate OS for the in-game computers (“Linox” likely a corruption of “Linux”), so probably an installer package of some kind. The specific “!@#&” sequence appears exactly where I would expect newlines to appear where the ‘files’ within the tree correspond to Lua source, so I think that's a crude substitution encoding of newline; perhaps someone chose it because they thought it would be uncommon (or due to frustration over syntax errors) while writing the “encode as string literal” logic.
The strings of hex digits in the “etc” files look more like they're meant to represent character-cell graphics, which would be consistent with someone wanting to add logos in a character-cell-only context. One color palette index per character would make the frequency distribution match up with logos that are mostly one color with some accents. However, we can't easily determine the intended shapes if whitespace has been squashed HTML-style for display.
4
Yeah, that makes sense. I was unsure about the opcode guess because if it was a Lua VIM/JIT opcode from bytecompiling (which often results in lots of strings interspersed with binary gibberish), why would it be so rare? As I understand Lao Mein, this is supposed to be some of the only occurrences online; Lua is an unpopular language compared to something like Python or JS, sure, but there's still a lot of it out there and all of the opcodes as well as their various manglings or string-encodings ought to show up reasonably often. But if it's some very ad hoc encoding - especially if it's an Minecraft kid, who doesn't know any better - then choosing cartoon-style expletives as a unique encoding of annoying characters like \n would be entirely in keeping with the juvenile humor elsewhere in that fragment.
And the repeated "linox"/"Linux" typo might be another nasty quick ad hoc hack to work around something like a 'Linux' setting already existing but not wanting to figure out how to properly override or customize or integrate with it.
2
Thanks, this helps a lot!
2
I guess this is dump of some memory leak, like "Cloudbleed".
1
Is this an LLM generation or part of the training data?
2
This is from OpenWebText, a recreation of GPT2 training data.
"@#&" [token 48193] occured in 25 out of 20610 chunks. 24 of these were profanity censors ("Everyone thinks they’re so f@#&ing cool and serious") and only contained a single instance, while the other was the above text (occuring 3299 times!), which was probably used to make the tokenizer, but removed from the training data.
I still don't know what the hell it is. I'll post the full text if anyone is interested.
1
Does it not have any sort of metadata telling you where it comes from?
My only guess is that some of it is probably metal lyrics.
Starting to suspect the hypothesis "torture doesn't work for information extraction" doesn't survive the replication crisis.
Surrogacy costs ~$100,000-200,000 in the US. Foster care costs ~$25,000 per year. This puts the implied cost of government-created and raised children at ~$600,000. My guess is that this goes down greatly with economies of scale. Could this be cheaper than birth subsidies, especially as prefered family size continues to decrease with no end in sight?
3
If you're thinking economically, I'm quite confident that children born from surrogates on average will have higher incomes and therefore pay much more tax per capita than children who have spent time in foster care.
I'm not sure if Foster Care costs are a good model for how to create people who "thrive" - most importantly on an existential level - are they emotionally satisfied? But from an economic argument, I assume that whatever foster kids are getting is not the optimal to make them productive in terms of future income, and therefore the taxes they can pay.
1
I question your guess.
Childcare is similar to education and medicine in that it's cursed to suffer from piss poor economies of scale forever.
Or, at least, until advanced AI+robots can straight up replace the human labor involved. In which case - are high birth rates even desirable?
I vaguely remember seeing a stop button problem solution (partial) that utilized internal betting markets on LessWrong years ago, but have not been able to find it since. Does anyone else know what I'm talking about?
1
"Internal betting markets" may be a reference to the Logical Induction paper? Unsure it ties strongly to stop-button/corrigibility.
The recent push for coal power in the US actually makes a lot of sense. A major trend in US power over the past few decades has been the replacement of coal power plants by cheaper gas-powered ones, fueled largely by low-cost natural gas from fracking. Much (most?) of the power for recently constructed US data centers have come from the continued operation of coal power plants that would otherwise been decommissioned.
The sheer cost (in both money and time) of building new coal plants in comparison to gas power plants still means that new coal power p...
Potential token analysis tool idea:
Use the tokenizers of common LLMs to tokenize a corpus of web text (OpenWebText, for example), and identify the contexts in which they frequently appear, their correlation with other tokens, whether they are glitch tokens, ect. It could act as a concise resource for explaining weird tokenizer-related behavior to those less familiar with LLMs (e.g. why they tend to be bad at arithmetic) and how a token entered a tokenizer's vocabulary.
Would this be useful and/or duplicate work? I already did this with GPT2 when I used it to analyze glitch tokens, so I could probably code the backend in a few days.
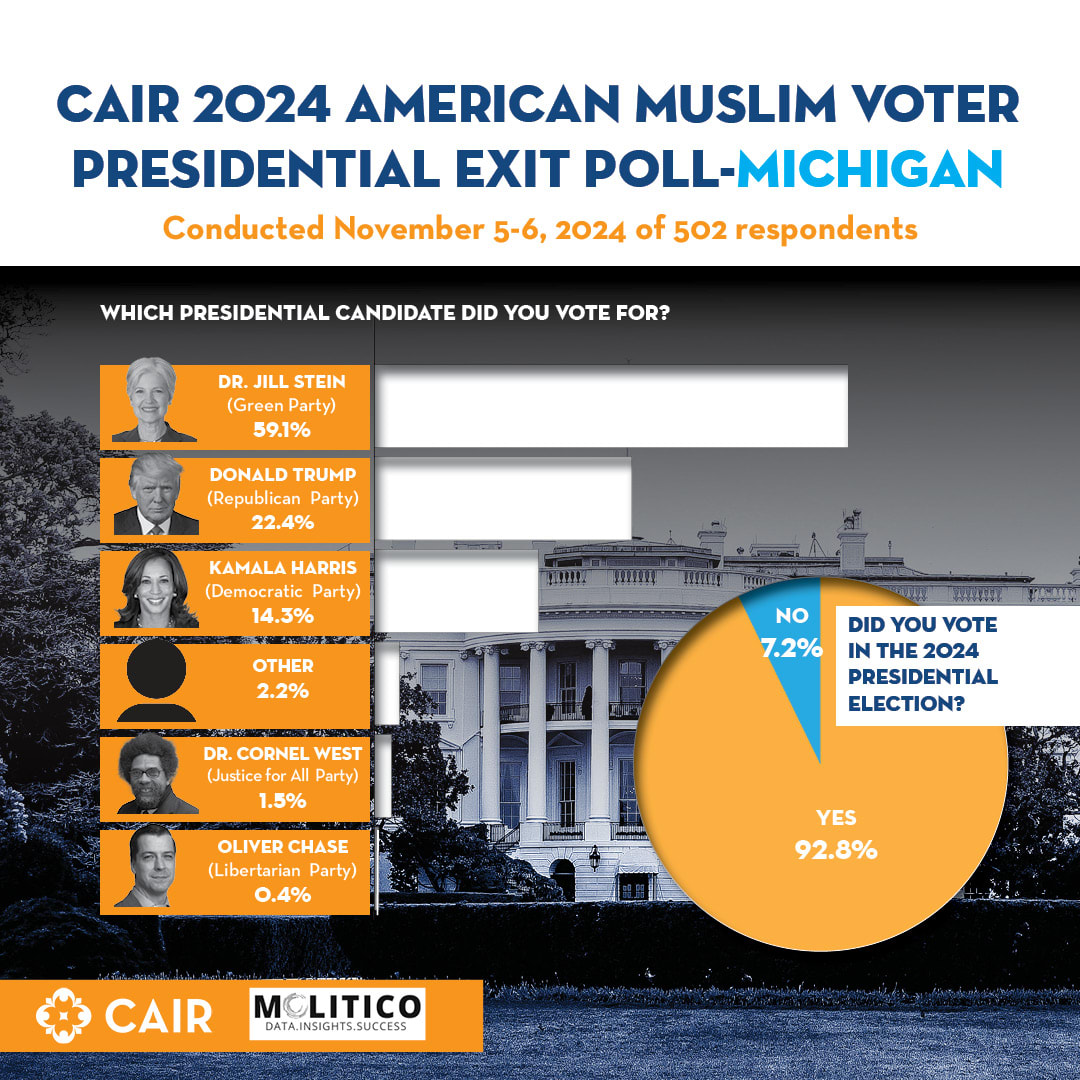
CAIR took a while to release their exit polls. I can see why. These results are hard to believe and don't quite line up with the actual returns from highly Muslim areas like Dearborn.
We know that Dearborn is ~50% Muslim. Stein got 18% of the vote there, as opposed to the minimum 30% implied by the CAIR exit polls. Also, there are ~200,000 registered Muslim voters in Michigan, but Stein only received ~45,000 votes. These numbers don't quite add up when you consider that the Green party had a vote share of 0.3% in 2020 and 1.1% in 2016, long before Gaz...
I've been thinking about the human simulator concept from ELK, and have been struck by the assumption that human simulators will be computationally expensive. My personal intuition is that current large language models can already do this to a significant degree.
Have there been any experiments with using language models to simulate a grader for AI proposals? I'd imagine you can use a prompt like this:
The following is a list of conversations between AIs of unknown alignment and a human evaluating their proposals.
Request: Provide a plan to cure c...
I'm currently writing an article about hangovers. This study came up in the course of my research. Can someone help me decipher the data? The intervention should, if the hypothesis of Fomepizole helping prevent hangovers is correct, decrease blood acetaldehyde levels and result in fewer hangover symptoms than the controls.
Why does California have forests so close to residential areas if they can not handle wildfires? In a just world, insurance companies would be allowed to pave over Californian forests with concrete.