OpenAI has already been the biggest contributor to accelerating the AI race; investing in chips is just another step in the same direction. I'm not sure why people keep assuming Altman is optimizing for safety. Sure, he has talked about safety, but it's very common for people to give lip service to something while doing the opposite thing. I'm not surprised by it and nobody should be surprised by it. Can we just accept already that OpenAI is going full speed in a bad direction, and start thinking what we can/should do about it?
Hearing Altman talk about safety reminds me of Sam Bankman-Fried testifying in congress that FTX was all about protecting consumers, their main goal was risk management, and they strongly supported regulation.
I'm kind of surprised this has almost 200 karma. This feels much more like a blog post on substack, and much less like the thoughtful, insightful new takes on rationality that used to get this level of attention on the forum.
It also isn't my favorite version of this post that could exist, but it seems like a reasonable point to make, and my guess is a lot of people are expressing their agreement with the title by upvoting.
OP here. I think this post has, unfortunately for the rest of us, aged quite well. In 2025, OpenAI secured up to $1.5T in compute deals (without much in the way of formal advice), and the industry is collectively investing gargantuan sums to build data centers. While this particular example may seem less dramatic than the others in the "not consistently candid" canon, it's a very important one.
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
The lesswrong/EA communities 'inside game' strategy for AI safety is genuinely embarrassing to me as a longtime community member. Quokkas gonna quokka but this is ridiculous.
Without endorsing anything, I can explain the comment.
The "inside strategy" refers to the strategy of safety-conscious EAs working with (and in) the AI capabilities companies like openAI; Scott Alexander has discussed this here. See the "Cooperate / Defect?" section.
The "Quokkas gonna quokka" is a reference to this classic tweet which accuses the rationalists of being infinitely trusting, like the quokka (an animal which has no natural predators on its island and will come up and hug you if you visit). Rationalists as quokkas is a bit of a meme; search "quokka" on this page, for example.
In other words, the argument is that rationalists cannot imagine the AI companies would lie to them, and it's ridiculous.
I am just now learning the origin of the quokka meme. The first and only time I ever saw the reference was with no explanation when someone posted this meme on Twitter

As one of the people who advocated this strategy early on, I want to point out what I pointed out then: working inside AI capabilities labs probably grants you access to insights about what is going on, how things work, and what is (going to be) important that you wouldn't necessarily get from outside.
That said, it's not clear to me that the community's entire strategy is 'inside game'. I know at least one community member who is hostile to OpenAI, I guess Pause AI protesting outside OpenAI counts as those of us who are in Pause AI being hostile to it, and I guess you yourself also count as a community member who is hostile to OpenAI? Is MIRI working with OpenAI or other corporate labs?
The faster the takeoff, the more dangerous, the thinking goes.
You seem to be fundamentally confused about what the words "fast takeoff" and "slow takeoff" mean. A fast takeoff occurs later in time than a slow takeoff because a slow takeoff involves gradual acceleration over a longer period of time, whereas a slow takeoff involves sudden takeoff over a shorter period of time.
Slow takeoffs are considered safer not because of when they take, but because a gradual ramp-up gives us more opportunities to learn about AI alignment (we spend more time near the part of the curve were AI is powerful but not yet dangerous).
A fast takeoff occurs later in time than a slow takeoff because a slow takeoff involves gradual acceleration over a longer period of time, whereas a slow takeoff involves sudden takeoff over a shorter period of time.
I think you’re confused. If you hold the “singularity date” / “takeoff end time” fixed—e.g., you say that we somehow know for certain that “the singularity” will happen on August 29, 2047—then the later takeoff starts, the faster it is. I think that’s what you have in mind, right? (Yes I know that the singularity is not literally a specific day, but hopefully you get what I’m saying).
But that’s irrelevant. It’s not what we’re talking about. I.e., it is not true that the singularity will happen at a fixed, exogenous date. There are possible interventions that could make that date earlier or later.
Anyway, I understand your comment as suggesting: “As long as the singularity hasn’t happened yet, any intervention that would accelerate AI progress, such as Sam Altman’s trying to make more AI chips in the next 10ish years, pushes us in the direction of slow takeoff, not fast takeoff.” Am I understanding you correctly? If so, then I disagree because it’s possible to accelerate AI progress in a way that brings the “takeoff end time” sooner without affecting the “takeoff start time” (using the terminology of that post you linked), or at least in a way that brings the end time sooner more than it brings the start time sooner.
You see what I mean?
I think you’re confused. If you hold the “singularity date” / “takeoff end time” fixed—e.g., you say that we somehow know for certain that “the singularity” will happen on August 29, 2047—then the later takeoff starts, the faster it is. I think that’s what you have in mind, right?
That's not what I have in mind at all.
I have picture like this in mind when I think of slow/fast takeoff:
There are 3 types of ways we can accelerate AGI progress:
1. Moore's law (I consider this one more or less inevitable)
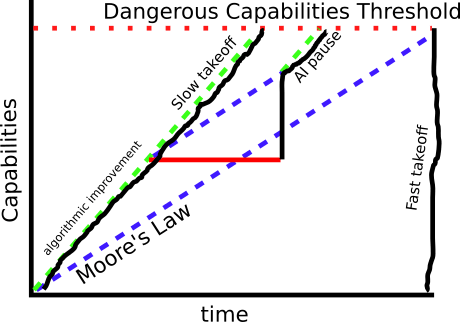
As we make progress in the material sciences, the cost of compute goes down
2. Spending
If we spend more money on compute, we can build AGI sooner
3. Algorithmic progress
The more AI we build, the better we get at building AI
Assuming we don't plan to ban science altogether (and hence do not change Moore's law), then pausing AI research (by banning large training runs) inevitably leads to a period of catch-up growth when the pause ends.
I think that the line marked "slow takeoff" is safer because:
1. the period of rapid catch up growth seems the most dangerous
2. we spend more time near the top of the curve where AI safety research is the most productive
I suppose that if you could pause exactly below the red line marked "dangerous capabilities threshold", that would be even safer. But since we don't know where that line is I don't really believe that to be possible. The closest approximation is Anthropic's RSP or Open AI's early warning system which says "if we notice we've already crossed the red line, then we should definitely pause".
I’m confused about how “pausing AI research (by banning large training runs)” is related to this conversation. The OP doesn’t even mention that, nor do any of the other comments, as far as I can see. The topic of discussion here on this page is a move by Sam Altman to raise tons of money and build tons of chip fabs. Right?
If you weren’t talking about “Sam Altman’s chip ambitions” previously, then, well, I propose that we start talking about it now. So: How do you think that particular move—the move by Sam Altman to raise tons of money and build tons of chip fabs—would affect (or not affect) takeoff speeds, and why do you think that? A.k.a. how would you answer the question I asked here?
I think that Sam's actions increase the likelihood of a slow takeoff.
Consider Paul's description of a slow takeoff from the original takeoff speed debate
right now I think hardware R&D is on the order of $100B/year, AI R&D is more like $10B/year, I guess I'm betting on something more like trillions? (limited from going higher because of accounting problems and not that much smart money)
Can you explain why? If that Paul excerpt is supposed to be an explanation, then I don’t follow it.
You previously linked this post by Hadshar & Lintz which is very explicit that the more chips there are in the world, the faster takeoff we should expect. (E.g. “slow, continuous takeoff is more likely given short timelines […partly because…] It’s plausible that compute overhang is low now relative to later, and this tends towards slower, more continuous takeoff.”) Do you think Hadshar & Lintz are incorrect on this point, or do you think that I am mischaracterizing their beliefs, or something else?
My understanding is that the fundamental disagreement is over whether there will be a "sharp discontinuity" at the development of AGI.
In Paul's model, there is no sharp discontinuity. So, since we expect AGI to have a large economic impact, we expect "almost AGI" to have an "almost large" economic impact (which he describes as being trillions of dollars).
One way to think of this is to ask: will economic growth suddenly jump on the day AGI is invented? Paul think's 'no' and EY thinks 'yes'.
Since sudden discontinuities are generally dangerous, a slow (continuous) takeoff is generally thought of as safer, even though the rapid economic growth prior to AGI results in AGI happen sooner.
This also effects the "kind of world" that AGI enters. In a world where pre-AGI is not widely deployed, the first AGI has a large "compute advantage" versus the surrounding environment. But in a world where pre-AGI is already quite powerful (imagine everyone has a team of AI agent that handles their financial transactions, protects them from cyber threats, is researching the cutting edge of physics/biology/nanotechnology, etc), there is less free-energy so to speak for the first AGI to take adavantage of.
Most AI Foom stories involve the first AGI rapidly acquiring power (via nanomachines or making computers out of dna or some other new technology path). But if pre-AGI AIs are already exploring these pathways, there are fewer "exploits" for the AGI to discover and rapidly gain power relative to what already exists.
edit:
I feel like I didn't sufficiently address the question of compute overhang. Just as a "compute overhang" is obviously dangerous, so is an "advanced fab" overhang or a "nanotechnology" overhang", so pushing all of the tech-tree ahead enhances our safety.
You’re saying a lot of things that seem very confused and irrelevant to me, and I’m trying to get to the bottom of where you’re coming from.
Here’s a key question, I think: In this comment, you drew a diagram with a dashed line labeled “capabilities ceiling”. What do you think determines the capabilities ceiling? E.g. what hypothetical real-world interventions would make that dashed line move left or right, or to get steeper or shallower?
In other words, I hope you’ll agree that you can’t simultaneously believe that every possible intervention that makes AGI happen sooner will push us towards slow takeoff. That would be internally-inconsistent, right? As a thought experiment, suppose all tech and economic and intellectual progress of the next century magically happened overnight tonight. Then we would have extremely powerful AGI tomorrow, right? And that is a very fast takeoff, i.e. one day.
Conversely, I hope you’ll agree that you can’t simultaneously believe that every possible intervention that makes AGI happen later will push us towards fast takeoff. Again, that would be internally-inconsistent, right? As a thought experiment, suppose every human on Earth simultaneously hibernated for 20 years starting right now. And then the entire human race wakes up in 2044, and we pick right back up where we were. That wouldn’t make a bit of difference to takeoff speed—the takeoff would be exactly as fast or slow if the hibernation happens as if it doesn’t. Right? (Well, that’s assuming that takeoff hasn’t already started, I guess, but if it has, then the hibernation would technically make takeoff slower not faster, right?)
If you agree with those two thought experiments, then you need to have in mind some bottleneck sitting between us and dangerous AGI, i.e. the “capabilities ceiling” dashed line. If there is such a bottleneck, then we can and hopefully would accelerate everything except that bottleneck, and we won’t get all the way to dangerous AGI until that bottleneck goes away, which (we hope) will take a long time, presumably because of the particular nature of that bottleneck. Most people in the prosaic AGI camp (including the slightly-younger Sam Altman I guess) think that the finite number of chips in the world is either the entirety of this bottleneck, or at least a major part of it, and that therefore trying to alleviate this bottleneck ASAP is the last thing you want to do in order to get maximally slow takeoff. If you disagree with that, then you presumably are expecting a different bottleneck besides chips, and I’d like to know what it is, and how you know.
idk.
Maybe I got carried away with the whole "everything overhang" idea.
While I do think fast vs slow takeoff is an important variable that determines how safe a singularity is, it's far from the only thing that matters.
If you were looking at our world today and asking "what obvious inefficiencies will an AGI exploit?" there are probably a lot of lower-hanging fruits (nuclear power, genetic engineering, zoning) that you would point to before getting to "we're not building chip fabs as fast as physically possible".
My actual views are probably closest to d/acc which is that there are a wide variety of directions we can chose when researching new technology and we ought to focus on the ones that make the world safer.
I do think that creating new obvious inefficiencies is a bad idea. For example, if we were to sustain a cap of 10**26 FLOPs on training runs for a decade or longer, that would make it really easy for a rouge actor/ai to suddenly build a much more powerful AI than anyone else in the world has.
As to the specific case of Sam/$7T, I think that it's largely aspiration and to the extent that it happens it was going to happen anyway. I guess if I was given a specific counterfactual, like: TSMC is going to build 100 new fabs in the next 10 years, is it better that they be built in the USA or Taiwan? I would prefer they be built in the USA. If, on the other hand, the counterfactual was: the USA is going to invest $7T in AI in the next 10 years, would you prefer it be all spent on semiconductor fabs or half on semiconductor fabs and half on researching controllable AI algorithms, I would prefer the latter.
Basically, my views are "don't be an idiot", but it's possible to be an idiot both by arbitrarily banning things and by focusing on a single line of research to the exclusion of all others.
I think you're confused. A rocket launch is not the same thing as filling the rocket fuel tanks with high explosives. Even when you give the rocket bigger engines. Launching a roller coaster harder is not the same as dropping someone to the ground. Avalanche isn't the same thing as a high speed train moving the ice.
The difference between these cases is the sudden all at once jolt, or impulse, is fatal. While most acceleration events up to a limit are not.
So in the AI case, situations where there are a lot of idle chips powerful enough to host ASI piled up everywhere plugged into infrastucture like the explosives/fall/avalanche. You may note the system has a lot of potential energy unused that is suddenly released.
While if humans start running their fabs faster, say 10-1000 times faster, and every newly made IC goes into an AI cluster giving immediate feedback to the developers, then to an extent this is a continuous process. You might be confident that it is simply not possible to create ICs fast enough, assuming they all immediately go into AI and humans immediately get genuine feedback on failures and safety, to cause a fast takeoff.
And I think this is the case, assuming humans isolate each cluster and refrain from giving their early production AIs some mechanism to communicate with each other in an unstructured way, and/or a way to remember past a few hours.
Failures are fine, AI screwing up and killing people is just fine (so long as the risks are less than humans doing the task). What's not fine is a coordinated failure.
The converse view might be you can't try to change faster than some rate limit decided by human governments. The legal system isn't ready for AGI, the economy and medical system isn't, no precautions whatsoever are legally required, the economy will naturally put all the power into the hands of a few tech companies if this goes forward. That democracies simply can't adjust fast enough because most voters won't understand any of the issues and keep voting for incumbents, dictatorships have essentially the same problem.
Whether Eliezer or Paul is right about “sudden all at once jolt” is an interesting question but I don’t understand how that question is related to Sam Altman’s chip ambitions. I don’t understand why Logan keeps bringing that up, and now I guess you’re doing it too. Is the idea that “sudden all at once jolt” is less likely in a world with more chips and chip fabs, and more likely in a world with fewer chips and chip fabs? If so, why? I would expect that if the extra chips make any difference at all, it would be to push things in the opposite direction.
In other words, if “situations where there are a lot of chips piled up everywhere plugged into infrastucture” is the bad thing that we’re trying to avoid, then a good way to help avoid that is to NOT manufacture tons and tons of extra chips, right?
Is the idea that “sudden all at once jolt” is less likely in a world with more chips and chip fabs, and more likely in a world with fewer chips and chip fabs? If so, why? I would expect that if the extra chips make any difference at all, it would be to push things in the opposite direction.
We're changing 2 variables, not 1:
(1) We know how to make useful AI, and these are AI accelerator chips specifically meant for specific network architectures
(2) we built a lot of them
Pretend base world:
(1) OAI doesn't exist or folds like most startups. Deepmind went from a 40% staff cut to 100% and joins the graveyard.
(2) Moore's law continues, and various kinds of general accelerator keep getting printed
So in the "pretend base world", 2 things are true:
(1) AI is possible, just human investors were too stupid to pay for it
(2) each 2-3 years, the cost of compute is halving
Suppose for 20 more years the base world continues, with human investors preferring to invest in various pyramid schemes instead of AI. (real estate, crypto...). Then after 20 years, compute is 256 times cheaper. This "7 trillion" investment is now 27 billion, pocket change. Also various inefficient specialized neural networks ("narrow AI") are used in places, with lots of support hardware plugged into real infrastructure.
That world has a compute overhang, and since compute is so cheap, someone will eventually try to train a now small neural network with 20 trillion weights on some random stuff they downloaded and you know the rest.
What's different in the real world: Each accelerator built in practice will be specifically for probably a large transformer network, specifically with fp16 or less precision. Each one printed is then racked into a cluster specifically with a finite bandwidth backplane intended to support the scale of network that is in commercial use.
Key differences :
(1) the expensive hardware has to be specialized, instead of general purpose
(2) specializations mean it is likely impossible for any of the newly made accelerators to support a different/much larger architecture. This means is is very unlikely to be able to run an ASI, unless that ASI happens to function with a transformers-like architecture of similar scale on fp16, or can somehow function as a distributed system with low bandwidth between clusters.
(3) Human developers get immediate feedback as they scale up their networks. If there are actual safety concerns of the type that MIRI et al has speculated exist, they may be found before the hardware can support ASI. This is what makes it a continuous process.
Note the epistemics : I work on an accelerator platform. I can say with confidence that accelerator design does limit what networks it is viable to accelerate, tops are not fungible.
Conclusion: if you think AI during your lifetime is bad, you're probably going to see this as a bad thing. Whether it is actually a bad thing is complicated.
I’m confused about your “pretend base world”. This isn’t a discussion about whether it’s good or bad that OAI exists. It’s a discussion about “Sam Altman’s chip ambitions”. So we should compare the world where OAI seems to be doing quite well and Sam Altman has no chip ambitions at all, to the world where OAI seems to be doing quite well and Sam Altman does have chip ambitions. Right?
I agree that if we’re worried about FOOM-from-a-paradigm-shifting-algorithmic-breakthrough (which as it turns out I am indeed worried about), then we would prefer be in a world where there is a low absolute number of chips that are flexible enough to run a wide variety of algorithms, than a world where there are a large number of such chips. But I disagree that this would be the effect of Sam Altman’s chip ambitions; rather, I think Sam Altman’s chip ambitions would clearly move things in the opposite, bad direction, on that metric. Don’t you think?
By analogy, suppose I say “(1) It’s very important to minimize the number of red cars in existence. (2) Hey, there’s a massively hot upcoming specialized market for blue cars, so let’s build 100 massive car factories all around the world.” You would agree that (2) is moving things in the wrong direction for accomplishing (1), right?
This seems obvious to me, but if not, I’ll spell out a couple reasons:
- For one thing, who’s to say that the new car factories won’t sell into the red-car market too? Back to the case at hand: we should strongly presume that whatever fabs get built by this Sam Altman initiative will make not exclusively ultra-specialized AI chips, but rather they will make whatever kinds of chips are most profitable to make, and this might include some less-specialized chips. After all, whoever invests in the fab, once they build it, they will try to maximize revenue, to make back the insane amount of money they put in, right? And fabs are flexible enough to make more than one kind of chip, especially over the long term.
- For another thing, even if the new car factories don’t directly produce red cars, they will still lower the price of red cars, compared to the factories not existing, because the old car factories will produce extra marginal red cars when they would otherwise be producing blue cars. Back to the case at hand: the non-Sam-Altman fabs will choose to pump out more non-ultra-specialized chips if Sam-Altman fabs are flooding the specialized-chips market. Also, in the longer term, fab suppliers will be able to lower costs across the industry (from both economies-of-scale and having more money for R&D towards process improvements) if they have more fabs to sell to, and this would make it economical for non-Sam-Altman fabs to produce and sell more non-ultra-specialized chips.
I think the possibility of compute overhang seems plausible given the technological realities, but generalizing from this to a second-order overhang etc. seems taking it too far.
If there is an argument that we should push compute due to the danger of another "overhang" down the line that should be made explicitly and not by generalisation from one (debatable!) example.
Slow takeoff : humans get pre AGI in the near future and then AGI. The Singularity is slow if humans have AGI in the near future if we assume that the price per transistor is expensive, and we assume that each inference instance of a running AGI is only marginally faster than humans and requires say $3.2 million USD in hardware. (If gpt-4 needs 128 H100s at inference time, albeit this hosts multiple parallel generation sessions). This is also why the AGI->ASI transition is slow. If you model it as an "intelligent search", where merely thousands of AGI scale training runs are done to find an architecture that scales to ASI, then this requires 10^3 times as much hardware as getting to AGI. If that's $100 billion, then ASI costs 100 trillion.
Fast Takeoff: humans are stuck or don't attempt to find algorithms for general AI but keep making compute cheaper and cheaper and building more of it. You can also think of humans putting insecure GPUs just everywhere - for VR, for analyzing camera footage, for killer drones - as like putting red barrels full of diesel everywhere. Then once AGI exists, there is the compute to iterate thousands of training sessions and immediately find ASI and then all the network stacks protecting the GPUs are all human written. Before humans can react, the ASI exploits implementation bugs and copies itself all over, and recall all those killer drones...
Fast Takeoff is a specific chain reaction similar to an explosion or an avalanche. It's dangerous because of the impulse function : you go from a world with just software to one with ASI essentially overnight, with ASI infesting everything. An explosion is bad not because of the air it moves but because the shockwave hits all at once.
Sam Altman proposal looks to me like slow takeoff with early investment to speed it up.
So for example, one of the AI labs develops AGI in 5 years, immediately there will be a real 7T investment. AGI turns sand into revenue, any rational market will invest all the capital it has into maximizing that revenue.
Assuming it takes 5 years from today to start producing new AI accelerators with capital invested now, then Sam is anticipating having AGI in 5 years. So it's a pre-investment into a slow takeoff. It's not an inpulse, just faster ramp. (It may still be dangerous, a fast enough ramp is indistinguishable from an impulse...)
Whether or not investors can be convinced is an open question. I would assume there will be lingering skepticism that AGI is 5 years away (2 years according to metaculus).
I’m confused about whether you agree or disagree with the proposition: “By doing this chip thing, Sam Altman is likely to make takeoff faster (on the margin) than it otherwise would be.”
In other words, compare the current world to the world where Sam Altman did everything else in life the same, including leading OpenAI etc., but where he didn’t pursue this big chip project. Which world do you think has faster takeoff? If you already answered that question, then I didn’t understand it, sorry.
Mr Byrnes is contrasting fast to slow takeoff, keeping the singularity date constant. Mr Zoellner is keeping the past constant, and contrasting fast takeoff (singularity soon) with slow takeoff (singularity later).
Maybe I wasn't clear enough in the writing, but I make basically the same point about the desirability of a slow takeoff in the piece.
Logan Zoellner, thank you for clarifying the concept.
However, it is possible to argue about semantics but since no one knows when AGI will happen if you increase the compute and or deploy new models, all take offs are equally dangerous. I think a fair stance by all AI researcher and companies trying to get to AGI is to admit that they have zero clue when AGI will be achieved, how that AI will behave and what safety measures are needed that can keep it under control.
Can anyone with certainty say that for instance a 100x in compute and model complexity over the state of the art today does not constitute an AGI? A 100x could be achieved within 2-3 years if someone poured a lot of money into it i.e. if someone went fishing for trillions in venture capital...
We are on a path for takeoff. Brace for impact.
all take offs are equally dangerous.
I think that a slow (earlier) takeoff is safer than a fast (later) takeoff.
Let us agree for a moment that GPT-5 is not going to destroy the world.
Suppose aliens were going to arrive at some unknown point in the future. Humanity would obviously be in a better position to defend themselves if everyone on Earth had access to GPT-5 than if they didn't.
Similarly, for AGI. If AGI arrives and finds itself in a world where most humans already have access to powerful (but not dangerous) AIs, then it is less likely to destroy us all.
As an extreme, consider a world in which all technology was legally frozen at an Amish level of development for several thousand years but nonetheless some small group of people eventually broke the restriction and secretly developed AGI. Such a world would be much more doomed than our own.
Logan Zoellner thank you for further expanding on your thoughts,
No, I will not agree that GPT5 will not destroy the world, cause I have no idea what it will be capable of.
I do not understand you assertion that we would be better fending off aliens if we have access to GPT5 than if we do not. What exactly do you think GPT5 could do in that scenario?
Why do you think that having access to powerful AI's would make AGI less likely to destroy us?
If anything, I believe that the Amish scenario is less dangerous than the slow take off scenario you described. In the slow take off scenario there will be billions of interconnected semi-smart entities that a full blown AGI could take control over. In the Amish scenario there would be just one large computer somewhere that is really really smart, but that does not have the possibility to hijack billions of devices, robots and other computers to reek havoc.
My point is this. We do not know. Nobody knows. We might create AGI and survive, or we might not survive. There are no priors and everything going forward from now on is just guesswork.
What exactly do you think GPT5 could do in that scenario?
At some model capabilities level (gpt-8?), the overall capabilities will be subhuman, but the model will be able to control robots to do at least 90 percent of the manufacturing and resource gathering steps needed to build more robots. This reduces the cost of building robots by 10 times (ok not actually 10 times but pretending land and IP is free...), increases the total number of robots humans can build by 10 times, and assuming the robots can be ordered to build anything that is similar to the steps needed to build robots (a rocket, a car, a house all have similar techniques to build) , it increases human resiliency.
Any problems humans have, they have 10 times the resources to deal with those problems.*
They have 10 times the resources to make bunkers (future nuclear wars and engineered pandemics), manufacture weapons (future wars), can afford every camera to have a classifier gpu (terrorism and mass shooting), can afford more than 10 times the spacecraft (off planet colonies maybe, more telescopes to see aliens arriving), can produce 10 times as much food, housing, can afford to use solely clean energy for everything, and so on.
You likely objection will be that humans could not maintain control of a bunch of general purpose robotics, an ASI would just "hack in" and take over them all. However, if for the sake of argument, you think there might be a way to secure the equipment using methods that are not hackable, it would help humans a lot.
This also helps humans with rogue AI - it gives them 10 times the resources for monitoring systems and 10 times the military hardware to deal with rebels. The "aliens" case is a superset of the "rogue AI" case, and it's the same thing - assuming interstellar spacecraft are tiny, humans at least have a fighting chance if they have robots capable of exponential growth and several years of warning.
So it's possible to come to the conclusion that humans have their best chance of survival "getting strapped" with near future armies of robots, carefully locked down with many layers of cybersecurity and isolation, to survive the challenges that are to come.
And that "pausing everything" or "extremely slow AI progress with massive amounts of review and red tape" will have the outcome of China during the Opium wars, China again in WW2, France during WW2, Ukraine right now, USA automakers during the 80s...
Failing to adopt new weapons and tech I believe has not yet paid off in human history. AI could be the exception to the trend.
- Actually more than 10 times, since humans need a constant amount of food, shelter, medicine, and transport. Also if the automation is 99 percent that's 100 times and so on.
Thank you Gerald Monroe for your comments,
My interpretation of your writing is that we should relentlessly pursue the goal of AGI because it might give us some kind of protection against a future alien invasion of which we have no idea what we are dealing with or will even happen? Yes, the "aliens" could be switched for AGI but it makes the case even stranger to me, that we should develop A(G)I to protect us from AGI.
We could speculate that AGI gives an 10x improvement there and 100x here and so on. But we really do not have any idea. What if AGI is like turning on a light switch, that you from one model to the next get a trillion fold increase in capability, how will the AI safety bots deal with that? We have no idea how to classify intelligence in terms of levels. How much smarter is a human compared to a dog? Or a snake? Or a chimpanzee? Assume for the sake of argument that a human is twice as "smart" as a chimpanzee on some crude brain measure scale thingy. Are humans than twice as capable than chimpanzees? We are probably close to infinitely more capable even if the raw brain power is NOT millions or billions or trillions times that of a chimpanzee.
We just do not have any idea what just a "slightly smarter" thing than us is capable of doing, it could be just a tiny bit better than us or it could be close to infinitely better than us.
My interpretation of your writing is that we should relentlessly pursue the goal of AGI because it might give us some kind of protection against a future alien invasion of which we have no idea what we are dealing with or will even happen? Yes, the "aliens" could be switched for AGI but it makes the case even stranger to me, that we should develop A(G)I to protect us from AGI.
You misunderstood. Let me quote myself:
At some model capabilities level (gpt-8?), the overall capabilities will be subhuman, but the model will be able to control robots to do at least 90 percent of the manufacturing and resource gathering steps needed to build more robots.
This is not an AGI, but a general machine that can do many things that GPT-4 can't do, and almost certainly GPT-5 cannot do either. The reason we should pursue the goal is to have tools against all future dangers. Not exotic ones like aliens but :
They have 10 times the resources to make bunkers (future nuclear wars and engineered pandemics), manufacture weapons (future wars), can afford every camera to have a classifier gpu (terrorism and mass shooting), can afford more than 10 times the spacecraft (off planet colonies maybe, more telescopes to see aliens arriving), can produce 10 times as much food, housing, can afford to use solely clean energy for everything, and so on.
You then said:
We could speculate that AGI gives an 10x improvement there and 100x here and so on. But we really do not have any idea.
I don't think 90% automation leading to approximately 10x available resources is speculation, it's reasoning based on reducing the limiting input (human labor). It is also not speculation to say that it is possible to build a machine that can increase automation by 90%. Humans can do all of the steps, and current research shows that reaching a model that can do 90% of the tasks at the skill level of a median factory worker or technician is relatively near term. "GPT-8" assumes about 4 generations more, or 8-12 years of time.
You then said, with some detail paragraphs that seem to say the same thing :
We just do not have any idea what just a "slightly smarter" thing than us is capable of doing, it could be just a tiny bit better than us or it could be close to infinitely better than us.
I am talking about something "slightly dumber" than us. And we already do have an idea - GPT-4 is slightly smarter than any living human in some domains. It gets stuck on any practical real world task at the moment.
Gerald Monroe, thank you for expanding your previous comments.
You propose building these sub-human machines in order to protect humanity from anything like nuclear war to street violence. But it also sound like there are two separate humanities, one that starts wars and spread disease and another one, to which "we" apparently belong, that needs protection and should inherit the earth. How come that those with the resources to start nuclear wars and engineer pandemics will not be in control of the best AI's that will do their bidding? In its present from, the reason to build the sub-humans machines sound to me like an attempt to save us from the "elites".
But I think my concern over that we have no idea what capabilities certain levels of intelligence have is brushed off to easily, since you seem to assume that a GPT8 (an AI 8-12 years from now) should not pose any direct problems to humans except for perhaps a meaning crisis due to mass layoffs and we should just build it. Where does this confidence come from?
But it also sound like there are two separate humanities, one that starts wars and spread disease and another one, to which "we" apparently belong, that needs protection and should inherit the earth. How come that those with the resources to start nuclear wars and engineer pandemics will not be in control of the best AI's that will do their bidding? In its present from, the reason to build the sub-humans machines sound to me like an attempt to save us from the "elites".
But I think my concern over that we have no idea what capabilities certain levels of intelligence have is brushed off to easily, since you seem to assume that a GPT8 (an AI 8-12 years from now) should not pose any direct problems to humans except for perhaps a meaning crisis due to mass layoffs and we should just build it. Where does this confidence come from?
One response covers both paragraphs:
It's a fight for survival like it always was. That's exactly right, there will be other humans armed with new weapons made possible with ai, terrorists will be better equipped, rival nations get killer drones, and so on.
I know with pretty high confidence - coming from the sum of all human history - that you cannot "regulate" away dangers. All you are doing is disarming yourself. You have to "get strapped" with more and better weapons. (One famous example is https://www.reed.edu/reed_magazine/june2016/articles/features/gunpowder.html )
Might those new weapons turn on you? Yes. Human survival was never guaranteed. But from humans harnessing fire to coal to firearms to nukes, it has so far always paid off for those who adopted the new tools faster and better than their rivals.
- Reasonable regulations like no nuclear reactors in private homes are fine, but it has to be possible to innovate.
Gerald Monroe thank you again clarifying you thoughts,
When you say that you know with pretty high confidence that X, Y or Z will happen, I think this encapsulate the whole debate around AI safety i.e. that some people seem to know unknowable things for certain, which is what frightens me. How can you know since there is nothing remotely close to the arrival of a super intelligent being in the recorded history of humans. How do you extrapolate from the data we have that says NOTHING about encountering a super intelligent being? I am curious to know how you managed to get so confident about the future?
When you say that you know with pretty high confidence that X, Y or Z will happen, I think this encapsulate the whole debate around AI safety i.e. that some people seem to know unknowable things for certain, which is what frightens me. How can you know since there is nothing remotely close to the arrival of a super intelligent being in the recorded history of humans. How do you extrapolate from the data we have that says NOTHING about encountering a super intelligent being? I am curious to know how you managed to get so confident about the future?
I don't. Here's the way the reasoning works. All intelligence of any kind by anyone is saying "ok this thing I have is most similar to <these previous things I have observed, or people long dead observed and they wrote down>".
So an advanced robotic system, or an AI I can tell to do something, is kinda like [a large dataset of past examples of technology]. Therefore even if the class match is not exact, it is still strong evidence that it will have properties shared in common with all past instances.
Specifically for tools/weapons, that dataset goes from [chipped rocks as hand axes to ICBMS to killer drones]. So far it has paid off to be up to date in quantity and quality of weapons technology.
What makes me "confident " is those data sets are real. They aren't some argument someone cooked up online. British warships really did rule the seas. The cold war was not fought because of ICBMs.
Centuries of history and billions of people were involved. While advanced AI doesn't exist yet and we don't know how far intelligence scales.
So it is more likely the past history is true than "an author of Harry Potter fanfiction and a few hundred scientist speculating about the future" are correct.
Note it's all about likelihood. If one side of a position has overwhelming evidence, you can still be wrong [example: investing in crypto]. Lesswrong though implies that's what this site/culture is about.
The confidence comes from the sheer number of examples.
Again though, you're right. Maybe AI is different. But you can't be very confident it is different without evidence of the empirical kind.
Btw I was wrong about crypto and the COVID lockdowns were a surprise because the closest historical match, 1922 flu epidemic, did not have wfh.
Nevertheless I think given the prior evidence, my assumptions were a correct EV assessment.
Thank you Gerald Monroe for answering my question,
I agree that staying on top of the weapon development game have had some perks, but its not completely one sided. Wars have to my understanding been mostly about control and less about extermination so the killing is in many ways optional if the counterpart waves a white flag. When two entities with about the same military power engage in a war, that is when the real suffering happens I believe. That is when millions dies trying to win against an equal opponent. One might argue that modern wars like Iraq or Afghanistan did have one entity with a massive military power advantage compared to their counterpart, but US did not use its full power (nukes) and instead opted to go for conventional warfare. In many senses having no military power might be the best from a surviving point of view, but for sure you will be in danger of losing your freedom.
So, I understand that you believe in your priors and they might very well be correct in predicting the future. But I still have a hard time using any kind of priors to predict whats going to happen next, since to me the situation with a technology as powerful as AI might turn out to be in combined with its inherent "blackboxiness" have no precedent in history. That is why I am so surprised that so many people are willing to charge ahead with the standard "move fast, break things" silicon valley attitude.
That is why I am so surprised that so many people are willing to charge ahead with the standard "move fast, break things" silicon valley attitude.
Well for one thing, because you don't have a choice in a competitive environment. Any software/hardware company in the Bay Area that doesn't adopt AI (at least to reduce developer cost) will go broke. At a national scale, any power bloc that doesn't develop weapons using AI will be invaded and their governments deposed. And it has historically not been effective to try to negotiate agreements not to build advanced weapons. It frankly doesn't appear to have ever successfully happened.
See here: https://en.wikipedia.org/wiki/Washington_Naval_Treaty
Page has been edited but a summary of the outcome is:
The United States developed better technology to get better performance from their ships while still working within the weight limits, the United Kingdom exploited a loop-hole in the terms, the Italians misrepresented the weight of their vessels, and when up against the limits, Japan left the treaty. The nations which violated the terms of the treaty did not suffer great consequences for their actions. Within little more than a decade, the treaty was abandoned.
Later arms control agreements such as SALT leave large enough nuclear arsenals to effectively still be MAD (~4000 nuclear warheads on each side). And agreements on chemical and biological weapons were violated openly and privately until the superpowers determined, after decades of R&D, that they weren't worth the cost.
Thank you Gerald Monroe for explaining you thoughts further,
And this is what bothers me. The willingness of apparently intelligent people to risk everything. I am fine with people risking their own life and healthy for what ever reason they see fit, but to relentlessly pursue AGI without anyone really know how to control it is NOT ok. People can´t dabble with anthrax or Ebola at home for obvious reasons, they can´t control it! But with AI anything goes and is, if anything, encouraged by governments, universities. VC´s etc.
No, I will not agree that GPT5 will not destroy the world, cause I have no idea what it will be capable of.
Great, this appears to be an empirical question that we disagree on!
I (and the Manifold prediction market I linked) think there is a tiny chance that GPT-5 will destroy the world.
You appear to disagree. I hope you are buying "yes" shares on Manifold and that one of us can "update our priors" a year from now when GPT-5 has/has-not destroyed the world.
Logan Zoellner thank you for highlighting one of your previous points,
You asked me to agree to your speculation that GPT5 will not destroy the world. I will not agree with your speculation because I have no idea if GPT5 will do that or not. This does not mean that I agree with the statement that GPT5 WILL destroy earth. It just means that I do not know.
I would not use Manifold as any data point in assessing the potential danger of future AI.
I would not use Manifold as any data point in assessing the potential danger of future AI.
What would you use instead?
In particular, I'd be interested in knowing what probability you assign to the chance that GPT-5 will destroy the world and how you arrived at that probability.
Logan Zoellner thank you for your question,
In my view we need more research, not people that draw inferences on extremely complex matters from what random people without that knowledge bet on a given day. Its maybe fun entertainment, but it does not say anything about anything.
I do not assign any probabilities. To me it is just silly that whole assigning probabilities game surrounding x-risk and AI safety in general. How can anyone say for instance that it is a 10% risk of human extinction. What does that mean? Is that a 1 in 10 chance at a given moment, during a 23.7678 year period, forever or? And most importantly how do you come up with the figure 10%, based on what exactly?
If you enjoy this, please consider subscribing to my Substack.
Sam Altman has said he thinks that developing artificial general intelligence (AGI) could lead to human extinction, but OpenAI is trying to build it ASAP. Why?
The common story for how AI could overpower humanity involves an “intelligence explosion,” where an AI system becomes smart enough to further improve its capabilities, bootstrapping its way to superintelligence. Even without any kind of recursive self-improvement, some AI safety advocates argue that a large enough number of copies of a genuinely human-level AI system could pose serious problems for humanity. (I discuss this idea in more detail in my recent Jacobin cover story.)
Some people think the transition from human-level AI to superintelligence could happen in a matter of months, weeks, days, or even hours. The faster the takeoff, the more dangerous, the thinking goes.
Sam Altman, circa February 2023, agrees that a slower takeoff would be better. In an OpenAI blog post called “Planning for AGI and beyond,” he argues that “a slower takeoff gives us more time to figure out empirically how to solve the safety problem and how to adapt.”
So why does rushing to AGI help? Altman writes that “shorter timelines seem more amenable to coordination and more likely to lead to a slower takeoff due to less of a compute overhang.”
Let’s set aside the first claim, which is far from obvious to me.
Computational resources, or compute, is one of the key inputs into training AI models. Altman is basically arguing that the longer it takes to get to AGI, the cheaper and more abundant the compute, which can then be plowed back into improving or scaling up the model.
The amount of compute used to train AI models has increased roughly one-hundred-millionfold since 2010. Compute supply has not kept pace with demand, driving up prices and rewarding the companies that have near-monopolies on chip design and manufacturing.
Last May, Elon Musk said that “GPUs at this point are considerably harder to get than drugs” (and he would know). One startup CEO said “It’s like toilet paper during the pandemic.”
Perhaps no one has benefited more from the deep learning revolution than the 31-year-old GPU designer Nvidia. GPUs, chips originally designed to process 3D video game graphics, were discovered to be the best hardware for training deep learning models. Nvidia, once little-known outside of PC gaming circles, reportedly accounts for 88 percent of the GPU market and has ridden the wave of AI investment. Since OpenAI’s founding in December 2015, Nvidia’s valuation has risen more than 9,940 percent, breaking $1 trillion last summer. CEO and cofounder Jensen Huang was worth $5 billion in 2020. Now it’s $64 billion.
If training a human-level AI system requires an unprecedented amount of computing power, close to economic and technological limits, as seems likely, and additional compute is needed to increase the scale or capabilities of the system, then your takeoff speed may be rate-limited by the availability of this key input. This kind of reasoning is probably why Altman thinks a smaller compute overhang will result in a slower takeoff.
Given all this, many in the AI safety community think that increasing the supply of compute will increase existential risk from AI, by both shortening timelines AND increasing takeoff speed — reducing the time we have to work on technical safety and AI governance and making loss of control more likely.
So why is Sam Altman reportedly trying to raise trillions of dollars to massively increase the supply of compute?
Last night, the Wall Street Journal reported that Altman was in talks with the UAE and other investors to raise up to $7 trillion to build more AI chips.
I’m going to boldly predict that Sam Altman will not raise $7 trillion to build more AI chips. But even one percent of that total would nearly double the amount of money spent on semiconductor manufacturing equipment last year.
Perhaps most importantly, Altman’s plan seems to fly in the face of the arguments he made not even one year ago. Increasing the supply of compute is probably the purest form of boosting AI capabilities and would increase the compute overhang that he claimed to worry about.
The AI safety community sometimes divides AI research into capabilities and safety, but some researchers push back on this dichotomy. A friend of mine who works as a machine learning academic once wrote to me that “in some sense, almost all [AI] researchers are safety researchers because the goal is to try to understand how things work.”
Altman makes a similar point in the blog post:
There are good reasons to doubt the numbers reported above (mostly because they’re absurdly, unprecedentedly big). But regardless of its feasibility, this effort to massively expand the supply of compute is hard to square with the above argument. Making compute cheaper speeds things up without any necessary increase in understanding.
Following November’s board drama, early reporting emerged about Altman’s Middle East chip plans. It’s worth noting that Helen Toner and Tasha McCauley, two of the (now ex-) board members who voted to fire Altman, reviewed drafts of the February 2023 blog post. While I don’t think there was any single smoking gun that prompted the board to fire him, I’d be surprised if these plans didn’t increase tensions.
OpenAI deserves credit for publishing blog posts like “Planning for AGI and beyond.” Given the stakes of what they’re trying to do, it’s important to look at how OpenAI publicly reasons about these issues (of course, corporate blogs should be taken with a grain of salt and supplemented with independent reporting). And when the actions of company leaders seem to contradict these documents, it’s worth calling that out.
If Sam Altman has changed his mind about compute overhangs, it’d be great to hear about it from him.