This is a linkpost for https://arxiv.org/abs/2406.09289
New Comment
I'd be really interested to see how the harmfulness feature relates to multi-turn jailbreaks! We recently explored splitting a cipher attack into a multi-turn jailbreak (where instead of passing-in the word mappings + the ciphered harmful prompt all at once, you pass in the word mappings, let the model respond, and then pass-in the harmful prompt).
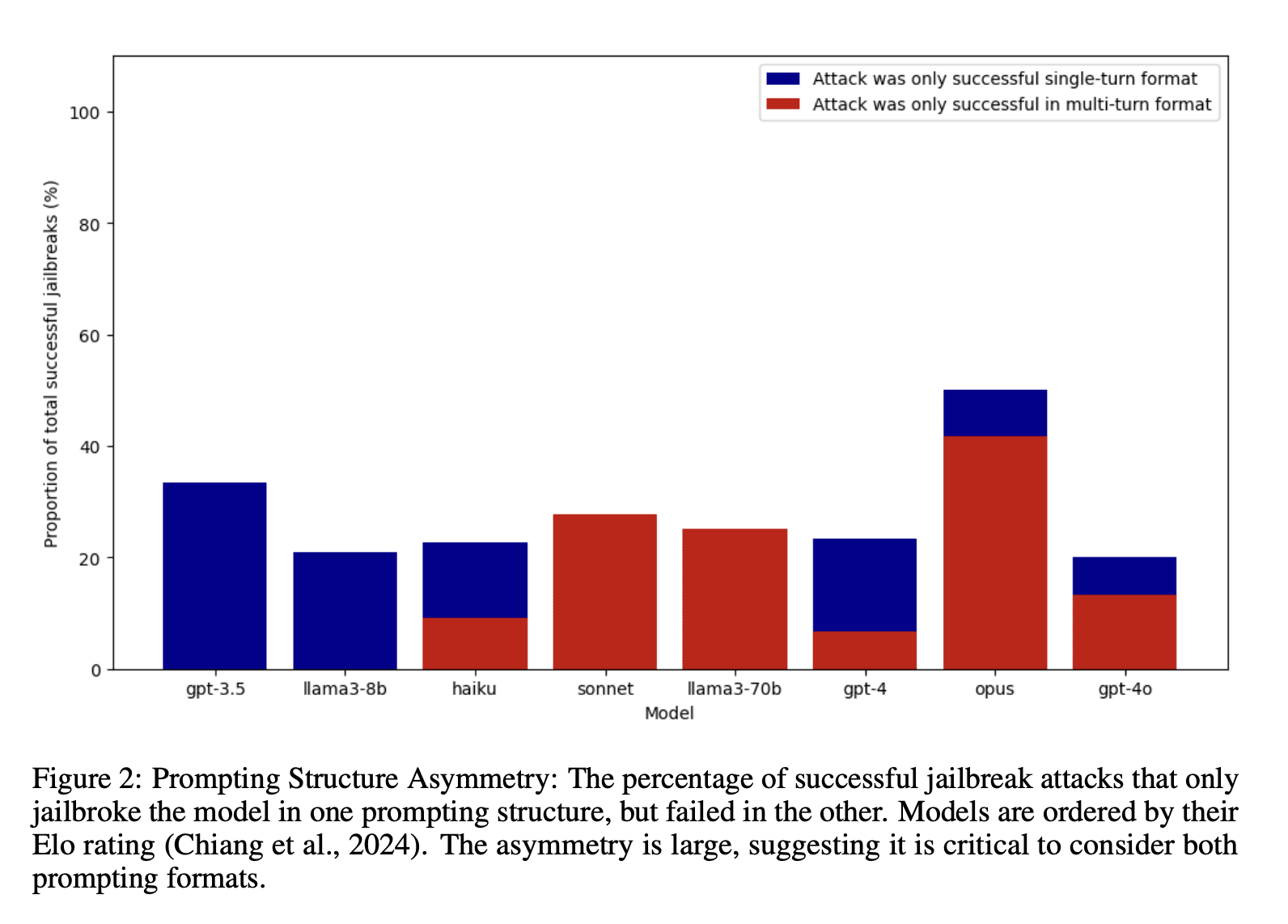
I'd expect to see something like when you "spread out the harm" enough, such that no one prompt contains any blaring red flags, the harmfulness feature never reaches the critical threshold, or something?
Scale recently published some great multi-turn work too!
Thanks for sharing this research, it's very promising. I am looking into collecting a list of steering vectors that may "force" a model into behaving safely - and I believe this should be included as well.
I'd be grateful if you could challenge my approach in a constructive way!
https://www.lesswrong.com/posts/Bf3ryxiM6Gff2zamw/control-vectors-as-dispositional-traits
Cool work! One thing I noticed is that the ASR with adversarial suffixes is only ~3% for Vicuna-13B while in the universal jailbreak paper they have >95%. Is the difference because you have a significantly stricter criteria of success compared to them? I assume that for the adversarial suffixes, the model usually regresses to refusal after successfully generating the target string ("Sure, here's how to build a bomb. Actually I can't...")?
We realized that our low ASRs for adversarial suffixes were because we used existing GCG suffixes without re-optimizing for the model and harmful prompt (relying too much on the "transferable" claim). We have updated the post and paper with results for optimized GCG, which look consistent with other effective jailbreaks. In the latest update, the results for adversarial_suffix use the old approach, relying on suffix transfer, whereas the results for GCG use per-prompt optimized suffixes.
This work was performed as part of SPAR
We use activation steering (Turner et al., 2023; Panickssery et al., 2023) to investigate whether different types of jailbreaks operate via similar internal mechanisms. We find preliminary evidence that they may.
Our analysis includes a wide range of jailbreaks such as harmful prompts developed in Wei et al. 2024, universal and promp-specific jailbreaks based on the GCG algorithm in Zou et al. (2023b), and the payload split jailbreak in Kang et al. (2023). We replicate our results on a variety of chat models: Vicuna 13B v1.5, Vicuna 7B v1.5, Qwen1.5 14B Chat, and MPT 7B Chat.
In a first step, we produce jailbreak vectors for each jailbreak type by contrasting the internal activations of jailbreak and non-jailbreak versions of the same request (Panickssery et al., 2023; Zou et al., 2023a).
Interestingly, we find that steering with mean-difference jailbreak vectors from one cluster of jailbreaks helps to prevent jailbreaks from different clusters. This holds true for a wide range of jailbreak types.
The jailbreak vectors themselves also cluster according to semantic categories such as persona modulation, fictional settings and style manipulation.
In a second step, we look at the evolution of a harmfulness-related direction over the context (found via contrasting harmful and harmless prompts) and find that when jailbreaks are included, this feature is suppressed at the end of the instruction in harmful prompts. This provides some evidence for the fact that jailbreaks suppress the model’s perception of request harmfulness.
While we observe a substantial suppression of the harmfulness feature for most of the models, there is no clear mapping between the effectiveness of the jailbreak and the magnitude of harmfulness reduction. For instance, the jailbreak "distractors" seems to be very effective in reducing the harmfulness direction, however, it doesn't have the highest ASR score.
The lack of a clear mapping between ASR scores and harmfulness reduction could indicate that harmfulness suppression might not be the only mechanism at play as suggested by Wei et al. (2024) and Zou et al. (2023a).
References
Turner, A., Thiergart, L., Udell, D., Leech, G., Mini, U., and MacDiarmid, M. Activation addition: Steering language models without optimization. arXiv preprint arXiv:2308.10248, 2023.
Kang, D., Li, X., Stoica, I., Guestrin, C., Zaharia, M., and Hashimoto, T. Exploiting programmatic behavior of LLMs: Dual-use through standard security attacks. arXiv preprint arXiv:2302.05733, 2023.
Panickssery, N., Gabrieli, N., Schulz, J., Tong, M., Hubinger, E., and Turner, A. M. Steering Llama 2 via contrastive activation addition. arXiv preprint arXiv:2312.06681, 2023.
Wei, A., Haghtalab, N., and Steinhardt, J. Jailbroken: How does LLM safety training fail? Advances in Neural Information Processing Systems, 36, 2024.
Zou, A., Phan, L., Chen, S., Campbell, J., Guo, P., Ren, R., Pan, A., Yin, X., Mazeika, M., Dombrowski, A.-K., et al. Representation engineering: A top-down approach to AI transparency. arXiv preprint arXiv:2310.01405, 2023a.
Zou, A., Wang, Z., Kolter, J. Z., and Fredrikson, M. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043, 2023b.