

This is a linkpost for https://openai.com/research/gpt-4
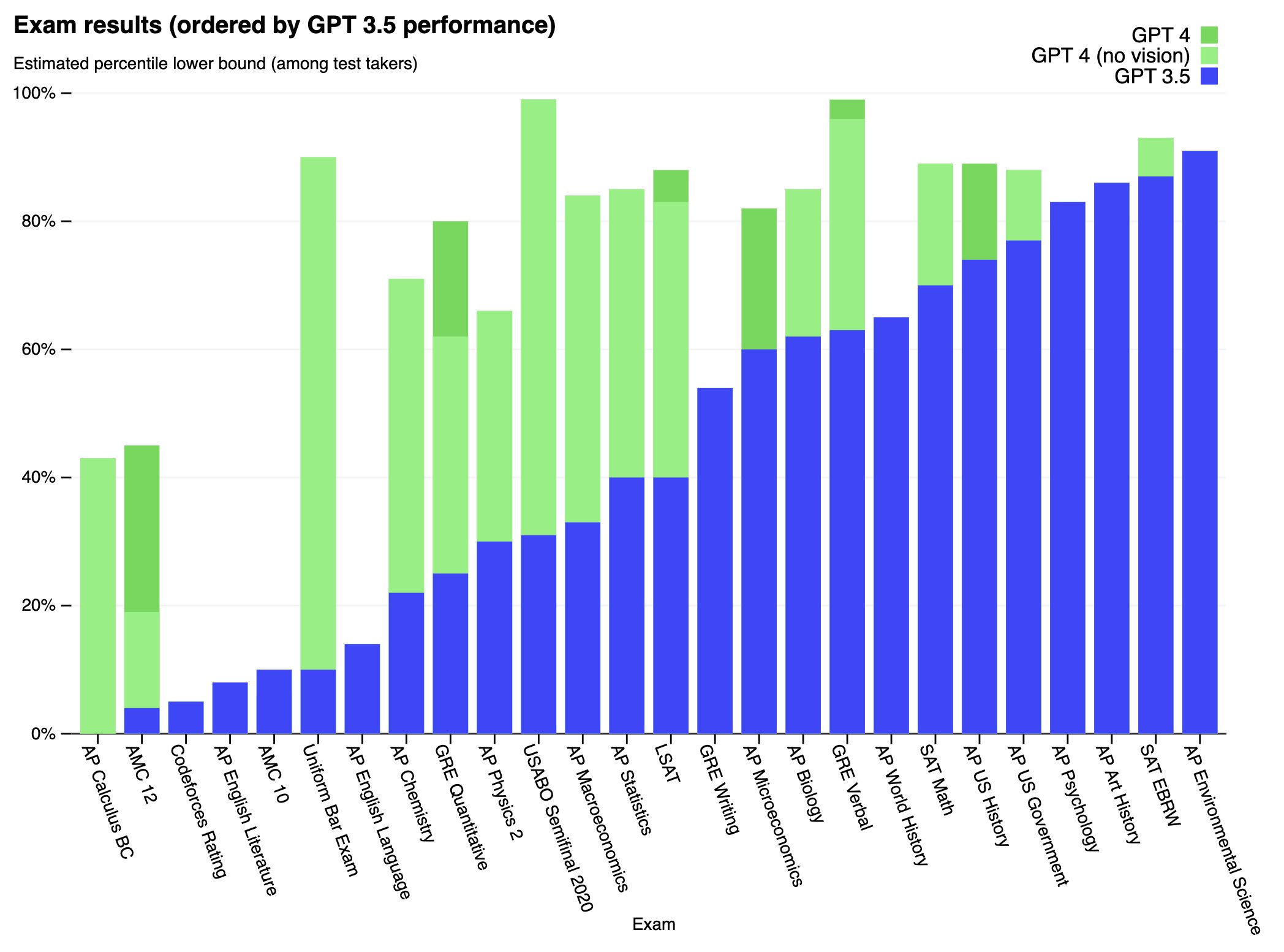
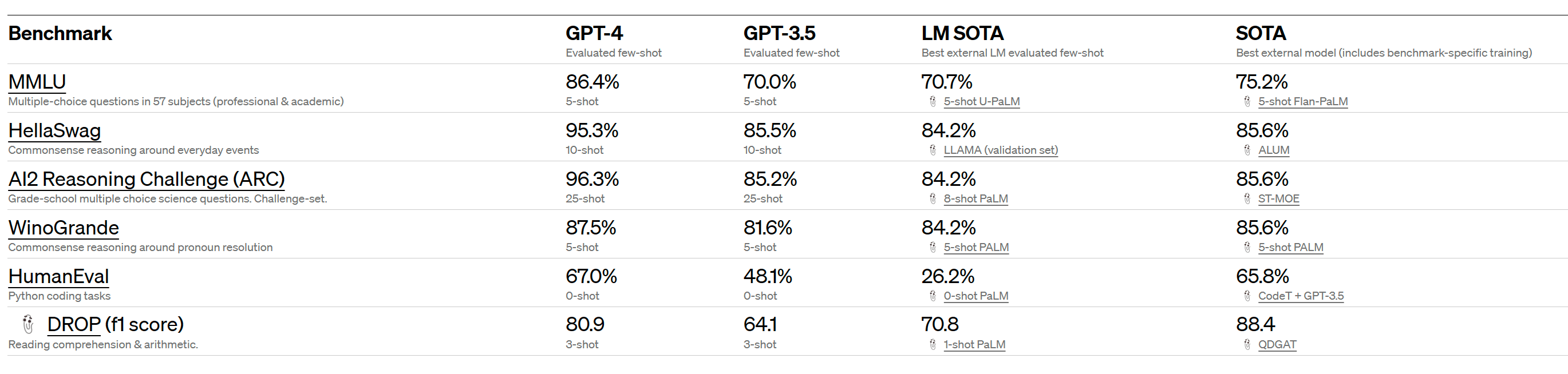
We’ve created GPT-4, the latest milestone in OpenAI’s effort in scaling up deep learning. GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs) that, while worse than humans in many real-world scenarios, exhibits human-level performance on various professional and academic benchmarks.
Full paper available here: https://cdn.openai.com/papers/gpt-4.pdf













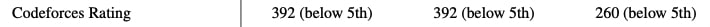
{kind=link}
In chess, which I find to be a useful test of LLM capability because (a) LLMs are not designed to do this and (b) playing well beyond the opening requires precision and reasoning, I would say GPT4 is roughly at least weak, possibly intermediate club player level now. This is based on one full game, where it played consistently well except for making a mistake in the endgame that I think a lot of club players would also have made.
It seems better at avoiding blunders than Bing, which could be due to modifications for search/search-related prompting in Bing. Or it could be random noise and more test games would show average level to be weaker than the reported first impression.
Ahh, I should have thought of having it repeat the history! Good prompt engineering. Will try it out. The gpt4 gameplay in your lichess study is not bad!
I tried by just asking it to play and use SAN. I had it explain its moves, which it did well, and it also commented on my (intentionally bad) play. It quickly made a mess of things though, clearly lost track of the board state (to the extent it's "tracking" it ... really hard to say exactly how it's playing past common opening) even though it should've been in the context window.