This is a linkpost for https://openai.com/research/gpt-4
We’ve created GPT-4, the latest milestone in OpenAI’s effort in scaling up deep learning. GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs) that, while worse than humans in many real-world scenarios, exhibits human-level performance on various professional and academic benchmarks.
Full paper available here: https://cdn.openai.com/papers/gpt-4.pdf

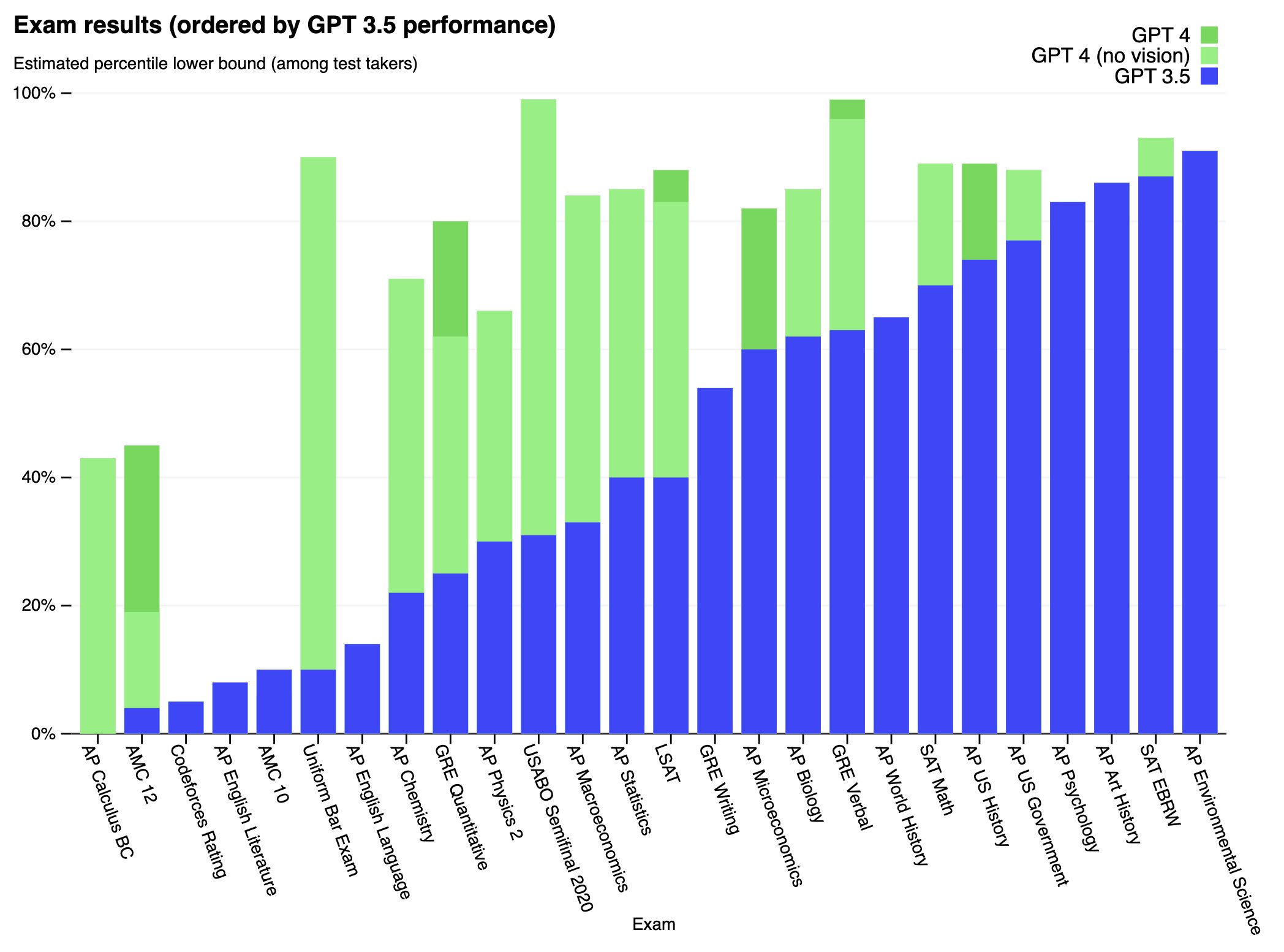

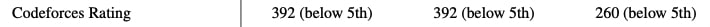
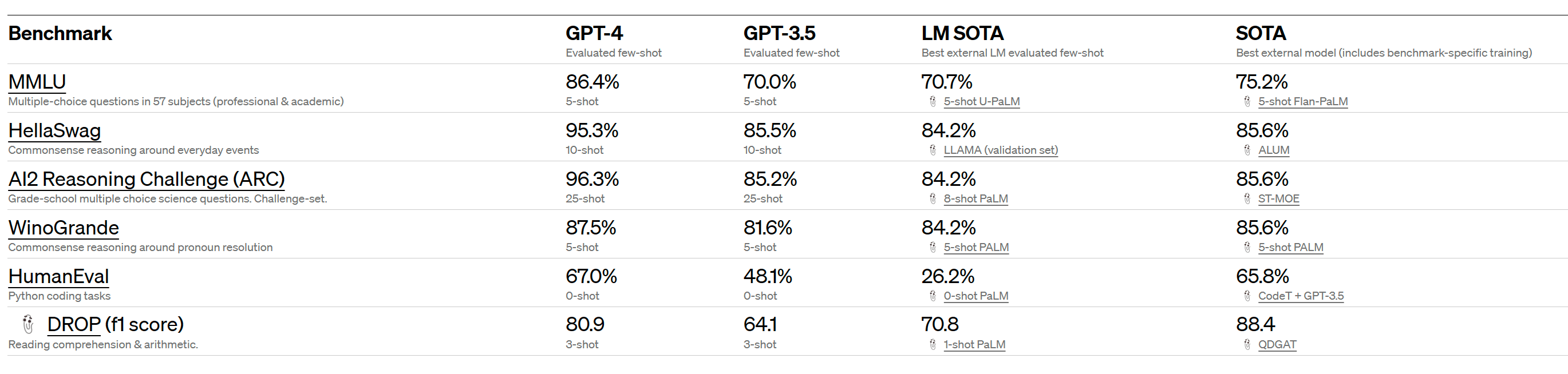
{kind=link}
I don't know how they did it, but I played a chess game against GPT4 by saying the following:
"I'm going to play a chess game. I'll play white, and you play black. On each chat, I'll post a move for white, and you follow with the best move for black. Does that make sense?"
And then going through the moves 1-by-1 in algebraic notation.
My experience largely follows that of GoteNoSente's. I played one full game that lasted 41 moves and all of GPT4's moves were reasonable. It did make one invalid move when I forgot to include the number before my move (e.g. Ne4 instead of 12. Ne4), but it fixed it when I put in the number in advance. Also, I think it was better in the opening than in the endgame. I suspect this is probably because of the large amount of similar openings in its training data.