This is a linkpost for https://openai.com/research/gpt-4
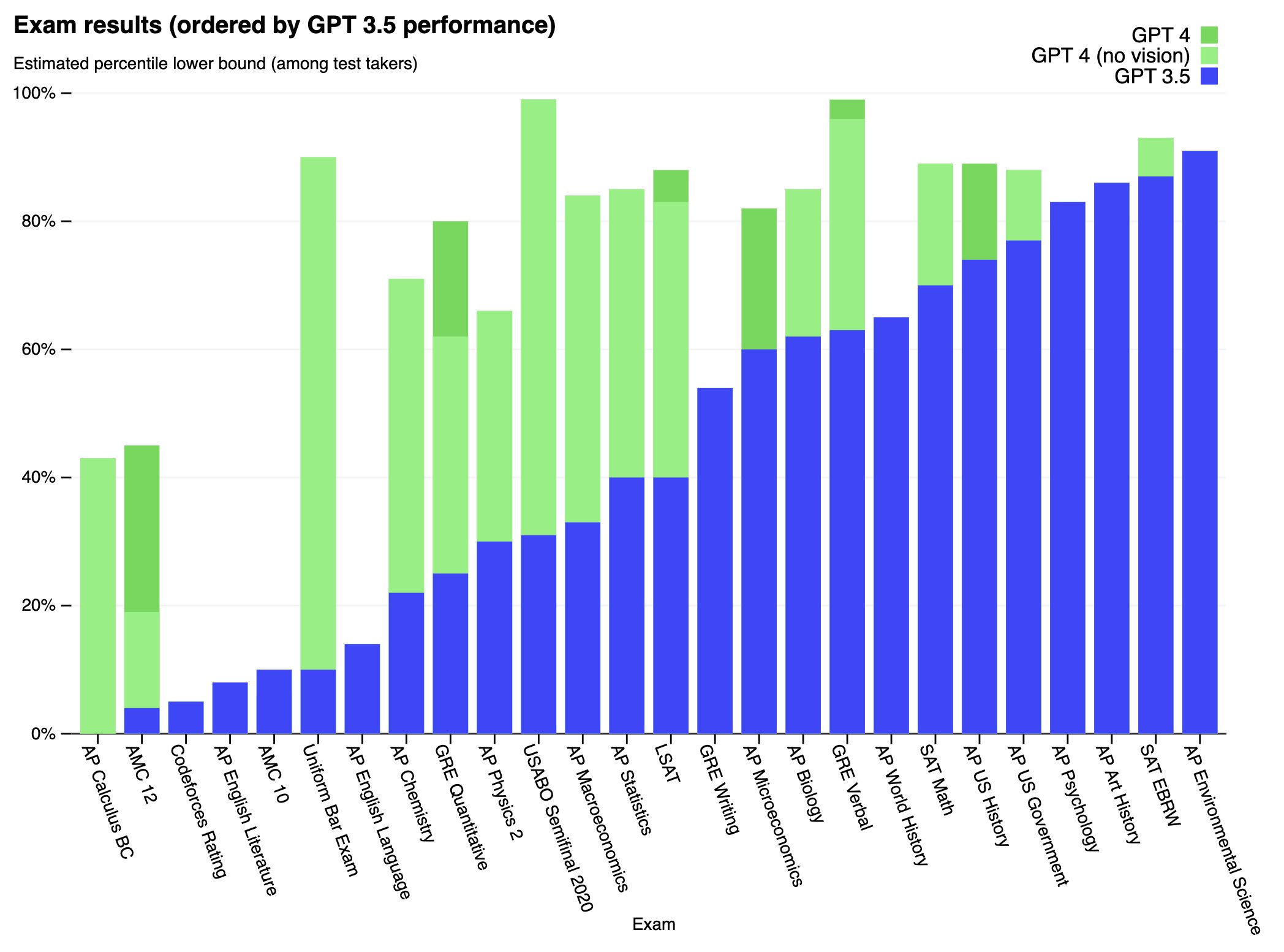
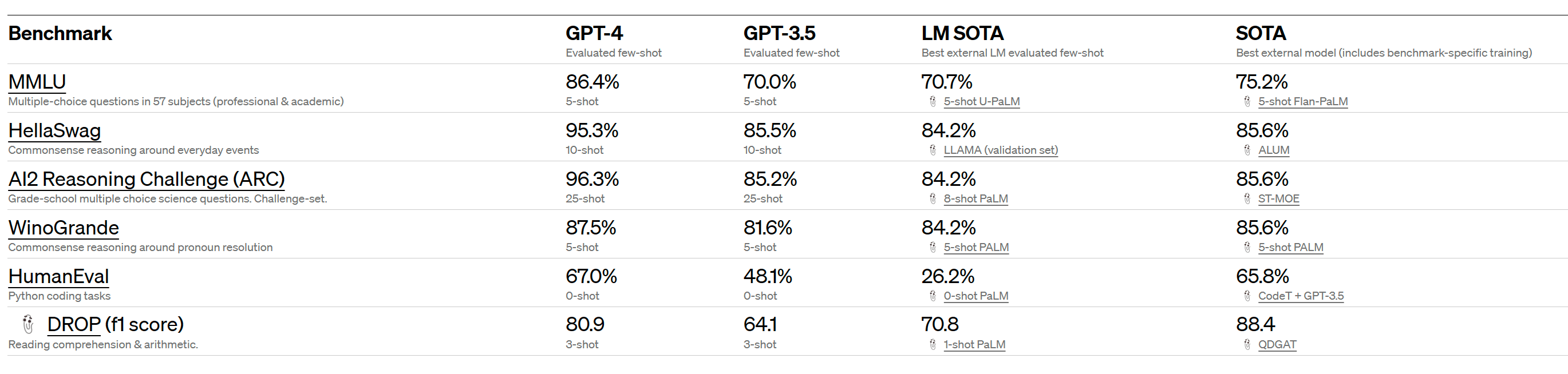
We’ve created GPT-4, the latest milestone in OpenAI’s effort in scaling up deep learning. GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs) that, while worse than humans in many real-world scenarios, exhibits human-level performance on various professional and academic benchmarks.
Full paper available here: https://cdn.openai.com/papers/gpt-4.pdf


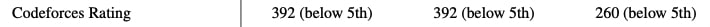
{kind=link}
Perhaps I am misunderstanding Figure 8? I was assuming that they asked the model for the answer, then asked the model what probability it thinks that that answer is correct. Under this assumption, it looks like the pre-trained model outputs the correct probability, but the RLHF model gives exaggerated probabilities because it thinks that will trick you into giving it higher reward.
In some sense this is expected. The RLHF model isn't optimized for helpfulness, it is optimized for perceived helpfulness. It is still disturbing that "alignment" has made the model objectively worse at giving correct information.