This is a linkpost for https://openai.com/research/gpt-4
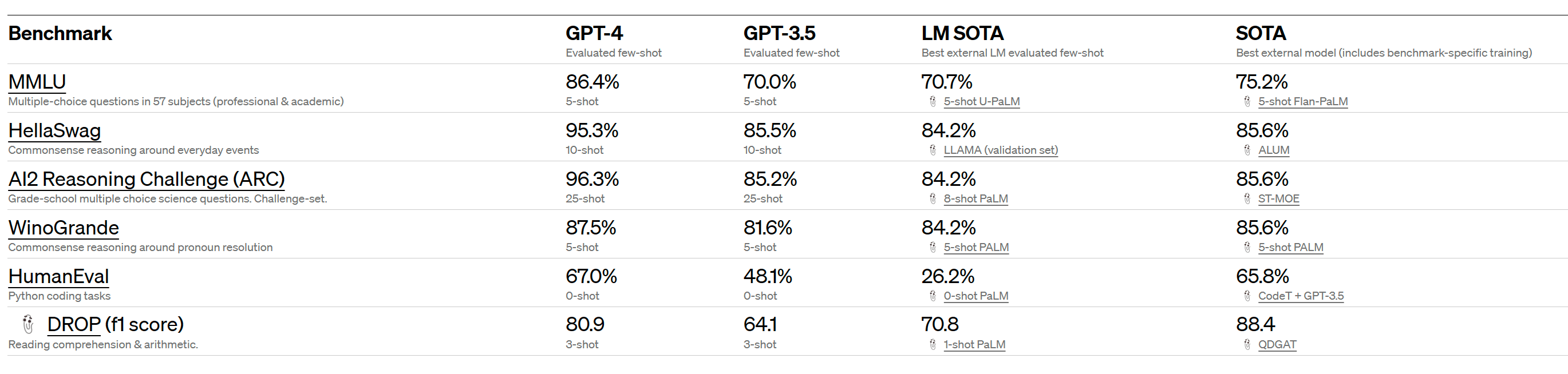
We’ve created GPT-4, the latest milestone in OpenAI’s effort in scaling up deep learning. GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs) that, while worse than humans in many real-world scenarios, exhibits human-level performance on various professional and academic benchmarks.
Full paper available here: https://cdn.openai.com/papers/gpt-4.pdf


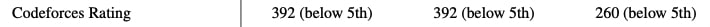
{kind=link}
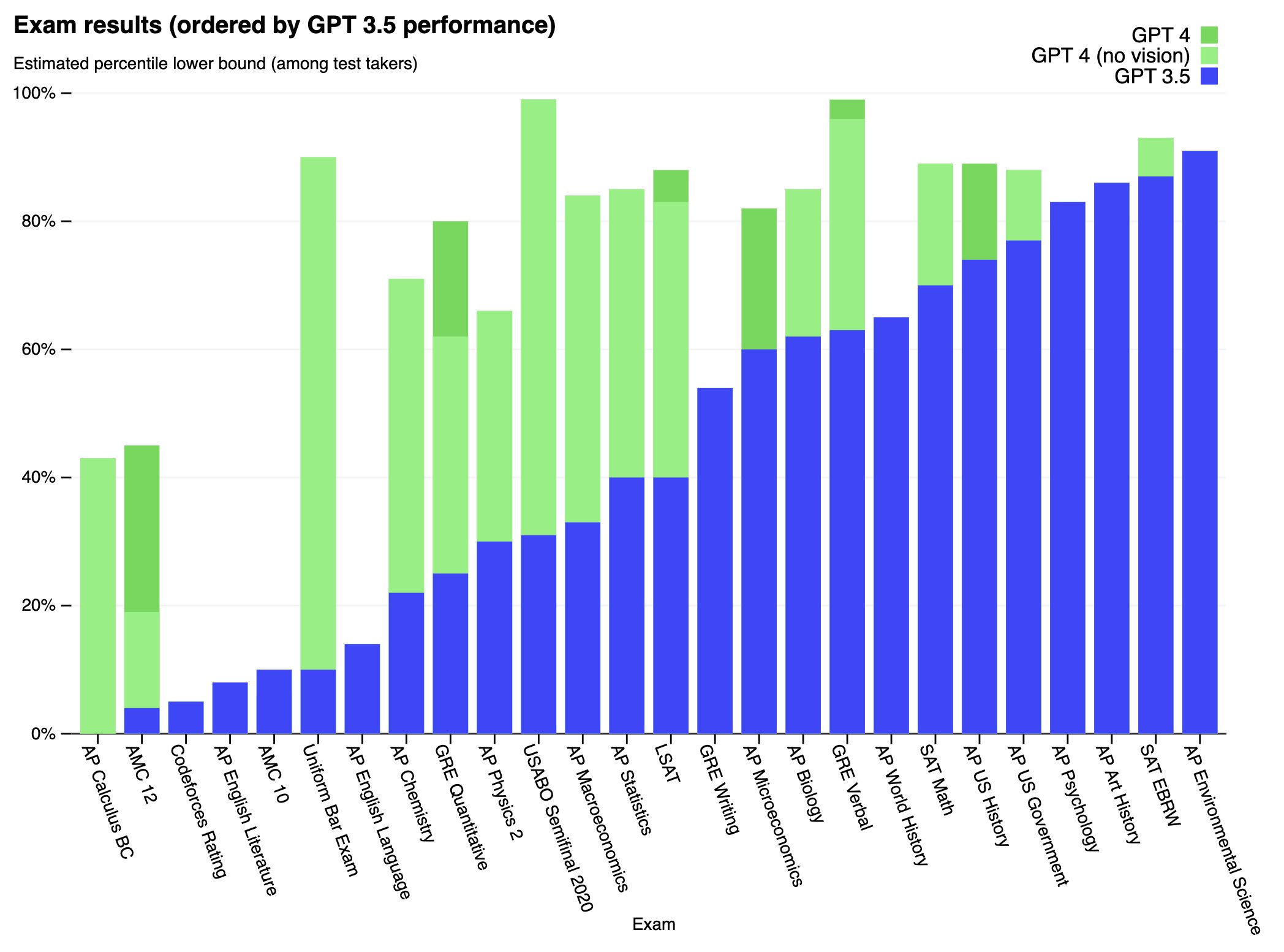
How is it that bad at codeforces? I competed a few years ago, but in my time div 2 a and b were extremely simple, basically just "implement the described algorithm in code" and if you submitted them quickly (which I expect gpt-4 would excel in) it was easy to reach a significantly better rating than the one reported by this paper.
I hope they didn't make a mistake by misunderstanding the codeforces rating system (codeforces only awards a fraction of the "estimated rating-current rating" after a competition, but it is possible to exactly calculate the rating equivalent to the given performance from the data provided if you know the details (which I forgot))
When searching the paper for the exact methodology (by ctrl-f'ing "codeforces"), I haven't found anything.