This is a linkpost for https://openai.com/research/gpt-4
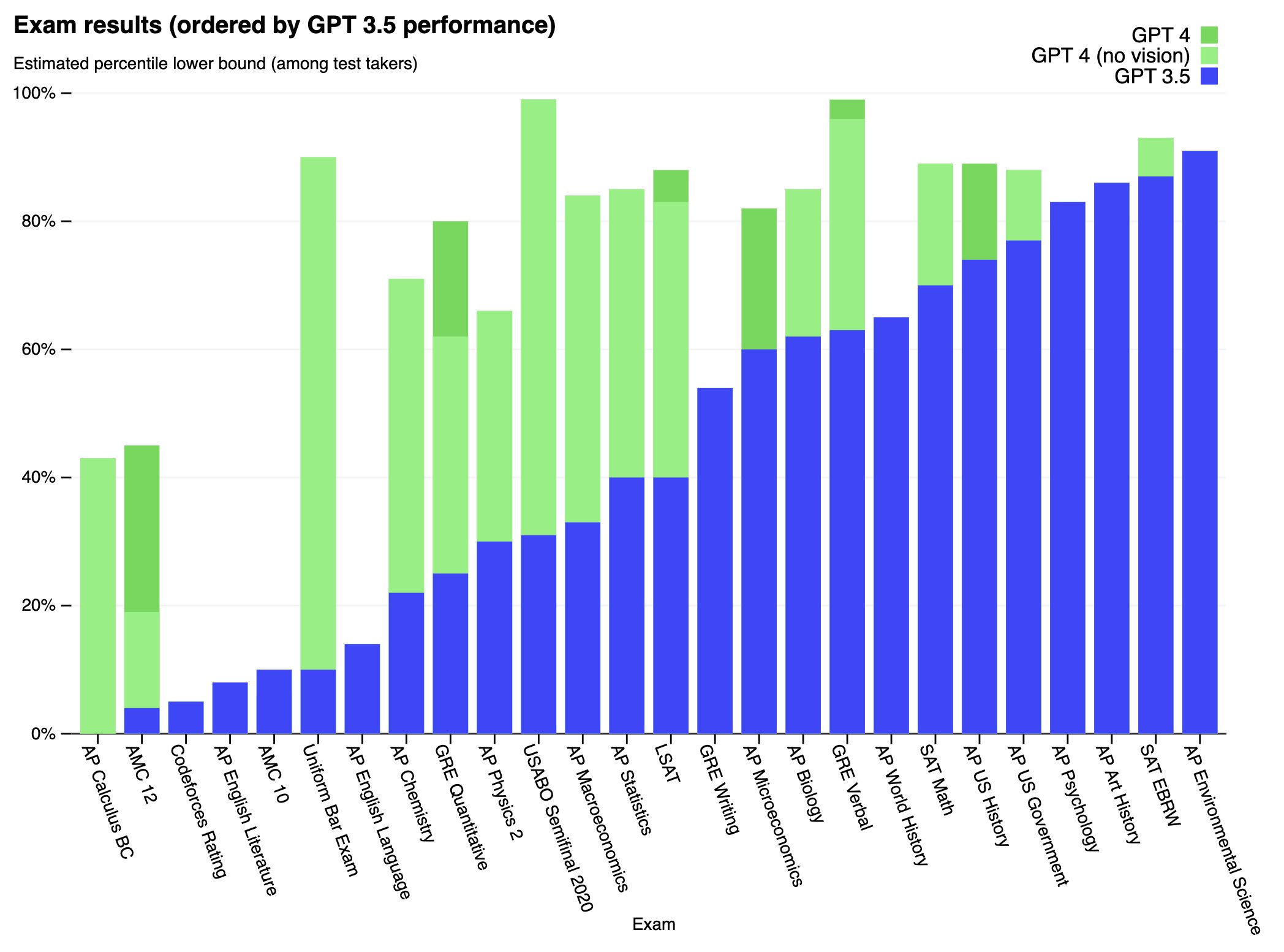
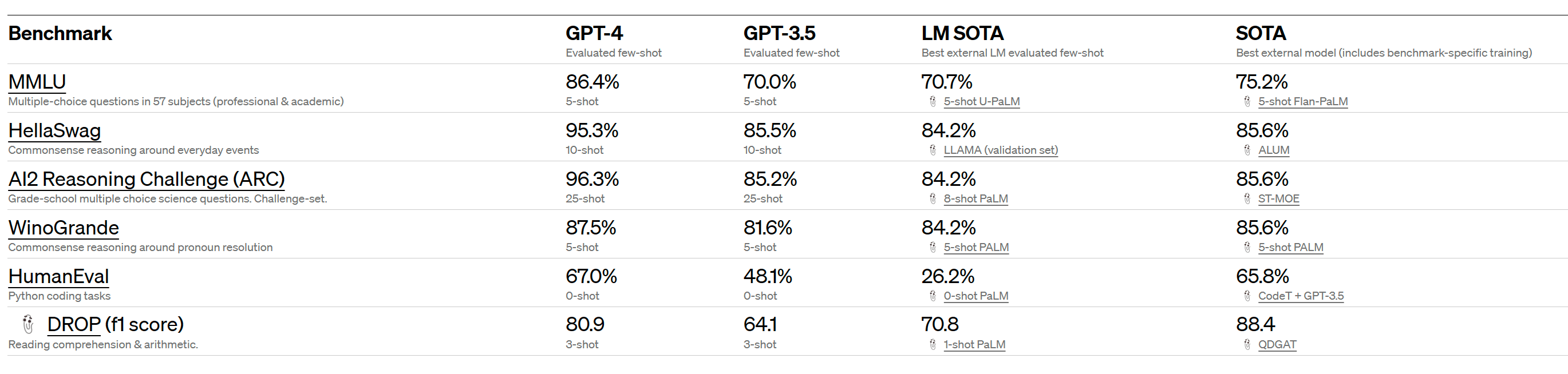
We’ve created GPT-4, the latest milestone in OpenAI’s effort in scaling up deep learning. GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs) that, while worse than humans in many real-world scenarios, exhibits human-level performance on various professional and academic benchmarks.
Full paper available here: https://cdn.openai.com/papers/gpt-4.pdf


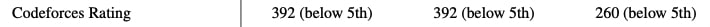
{kind=link}
I think that if RLHF reduced to a proper loss on factual questions, these probabilities would coincide (given enough varied training data). I agree it’s not entirely obvious that having these probabilities come apart is problematic, because you might recover more calibrated probabilities by asking for them. Still, knowing the logits are directly incentivised to be well calibrated seems like a nice property to have.
An agent says yes if it thinks yes is the best thing to say. This comes apart from “yes is the correct answer” only if there are additional considerations determining “best” apart from factuality. If you’re restricted to “yes/no”, then for most normal questions I think an ideal RLHF objective should not introduce considerations beyond factuality in assessing the quality of the answer - and I suspect this is also true in practical RLHF objectives. If I’m giving verbal confidences, then there are non-factual considerations at play - namely, I want my answer to communicate my epistemic state. For pretrained models, the question is not whether it is factual but whether someone would say it (though somehow it seems to come close). But for yes/no questions under RLHF, if the probabilities come apart it is due to not properly eliciting the probability (or some failure of the RLHF objective to incentivise factual answers).