This is a linkpost for https://openai.com/research/gpt-4
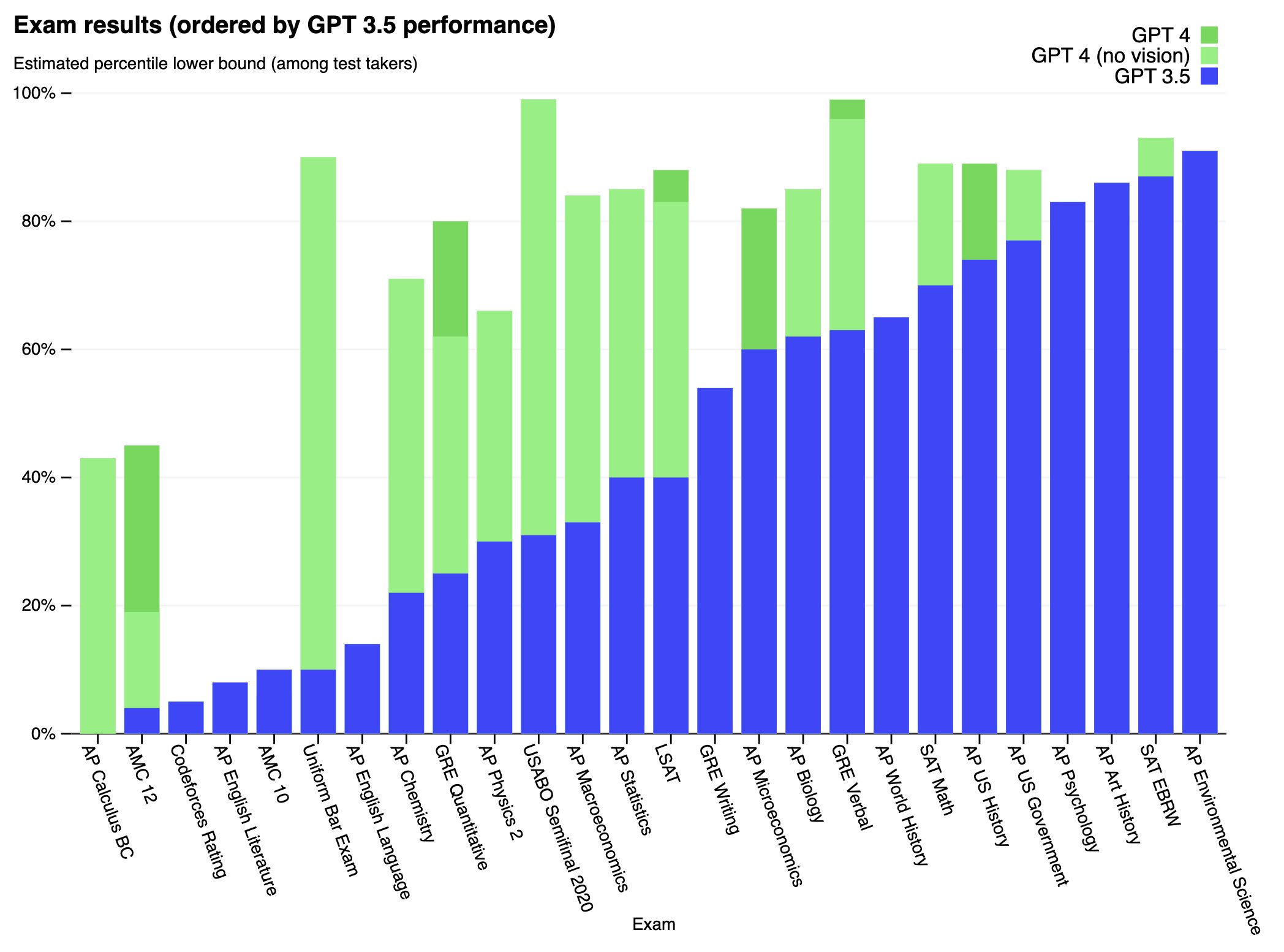
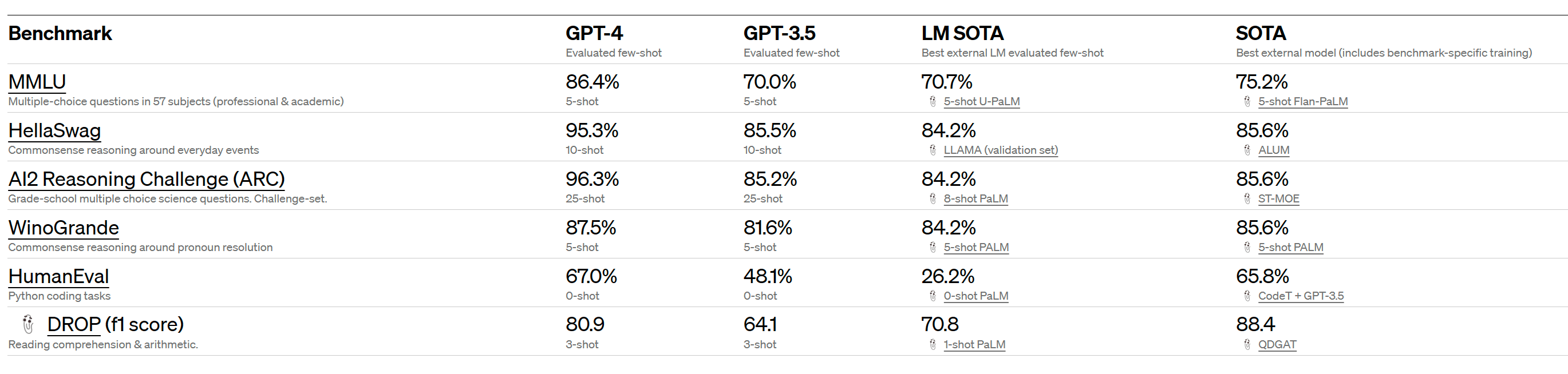
We’ve created GPT-4, the latest milestone in OpenAI’s effort in scaling up deep learning. GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs) that, while worse than humans in many real-world scenarios, exhibits human-level performance on various professional and academic benchmarks.
Full paper available here: https://cdn.openai.com/papers/gpt-4.pdf


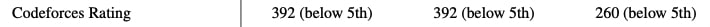
{kind=link}
I haven't read this page in detail. I agree, obviously, that on many prompts Bing Chat, like ChatGPT, gives very impressive answers. Also, there are clearly examples on which Bing Chat gives a much better answer than GPT3. But I don't give lists like the one you linked that much weight. For one, for all I know, the examples are cherry-picked to be positive. I think for evaluating these models it is important that they sometimes give indistinguishable-from-human answers and sometimes make extremely simple errors. (I'm still very unsure about what to make of it overall. But if I only knew of all the positive examples and thought that the corresponding prompts weren't selection-biased, I'd think ChatGPT/Bing is already superintelligent.) So I give more weight to my few hours of generating somewhat random prompts (though I confess, I sometimes try deliberately to trip either system up). Second, I find the examples on that page hard to evaluate, because they're mostly creative-writing tasks. I give more weight to prompts where I can easily evaluate the answer as true or false, e.g., questions about the opening hours of places, prime numbers or what cities are closest to London, especially if the correct answer would be my best prediction for a human answer.