

This is a linkpost for https://openai.com/research/gpt-4
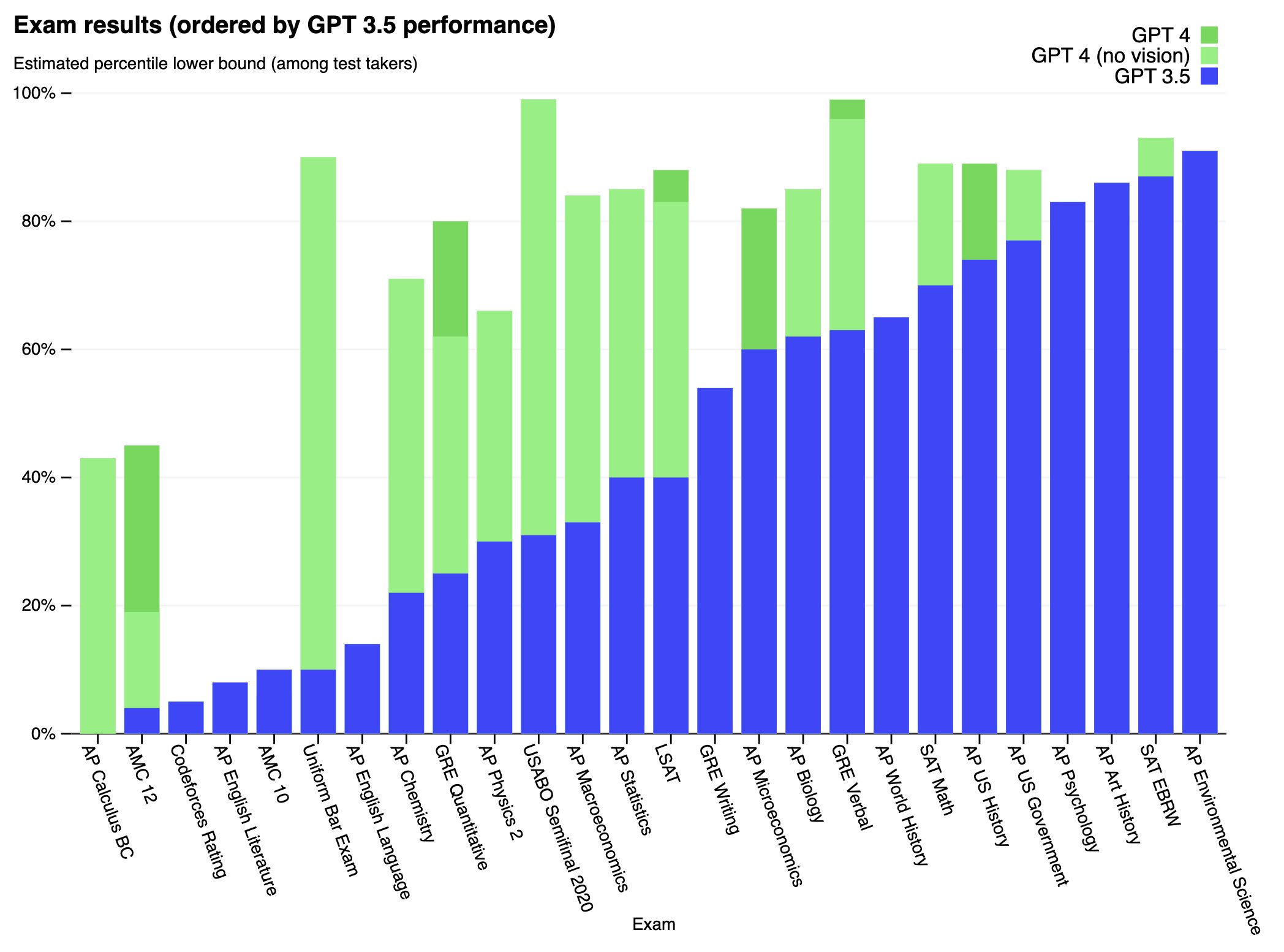
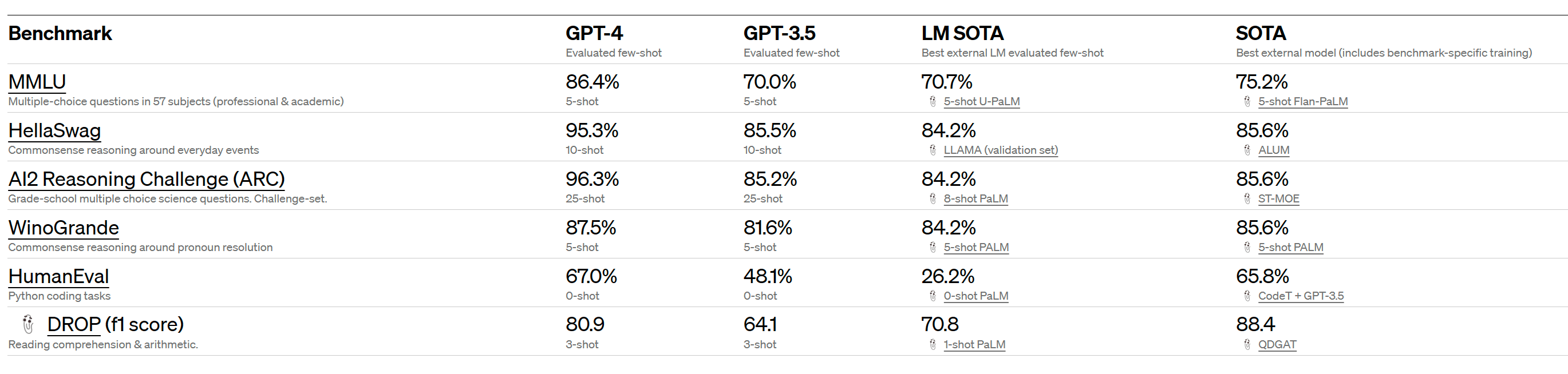
We’ve created GPT-4, the latest milestone in OpenAI’s effort in scaling up deep learning. GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs) that, while worse than humans in many real-world scenarios, exhibits human-level performance on various professional and academic benchmarks.
Full paper available here: https://cdn.openai.com/papers/gpt-4.pdf













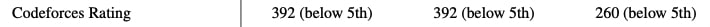
{kind=link}
I think it's important for ARC to handle the risk from gain-of-function-like research carefully and I expect us to talk more publicly (and get more input) about how we approach the tradeoffs. This gets more important as we handle more intelligent models, and if we pursue riskier approaches like fine-tuning.
With respect to this case, given the details of our evaluation and the planned deployment, I think that ARC's evaluation has much lower probability of leading to an AI takeover than the deployment itself (much less the training of GPT-5). At this point it seems like we face a much larger risk from underestimating model capabilities and walking into danger than we do from causing an accident during evaluations. If we manage risk carefully I suspect we can make that ratio very extreme, though of course that requires us actually doing the work.