Summary
Four months after my post 'LLM Generality is a Timeline Crux', new research on o1-preview should update us significantly toward LLMs being capable of general reasoning, and hence of scaling straight to AGI, and shorten our timeline estimates.
Summary of previous post
In June of 2024, I wrote a post, 'LLM Generality is a Timeline Crux', in which I argue that
- LLMs seem on their face to be improving rapidly at reasoning.
- But there are some interesting exceptions where they still fail much more badly than one would expect given the rest of their capabilities, having to do with general reasoning. Some argue based on these exceptions that much of their apparent reasoning capability is much shallower than it appears, and that we're being fooled by having trouble internalizing just how vast their training data is.
- If in fact this is the case, we should be much more skeptical of the sort of scale-straight-to-AGI argument made by authors like Leopold Aschenbrenner and the short timeline that implies, because substantial additional breakthroughs will be needed first.
Reasons to update
In the original post, I gave the three main pieces of evidence against LLMs doing general reasoning that I found most compelling: blocksworld, planning/scheduling, and ARC-AGI (see original for details). All three of those seem importantly weakened in light of recent research.
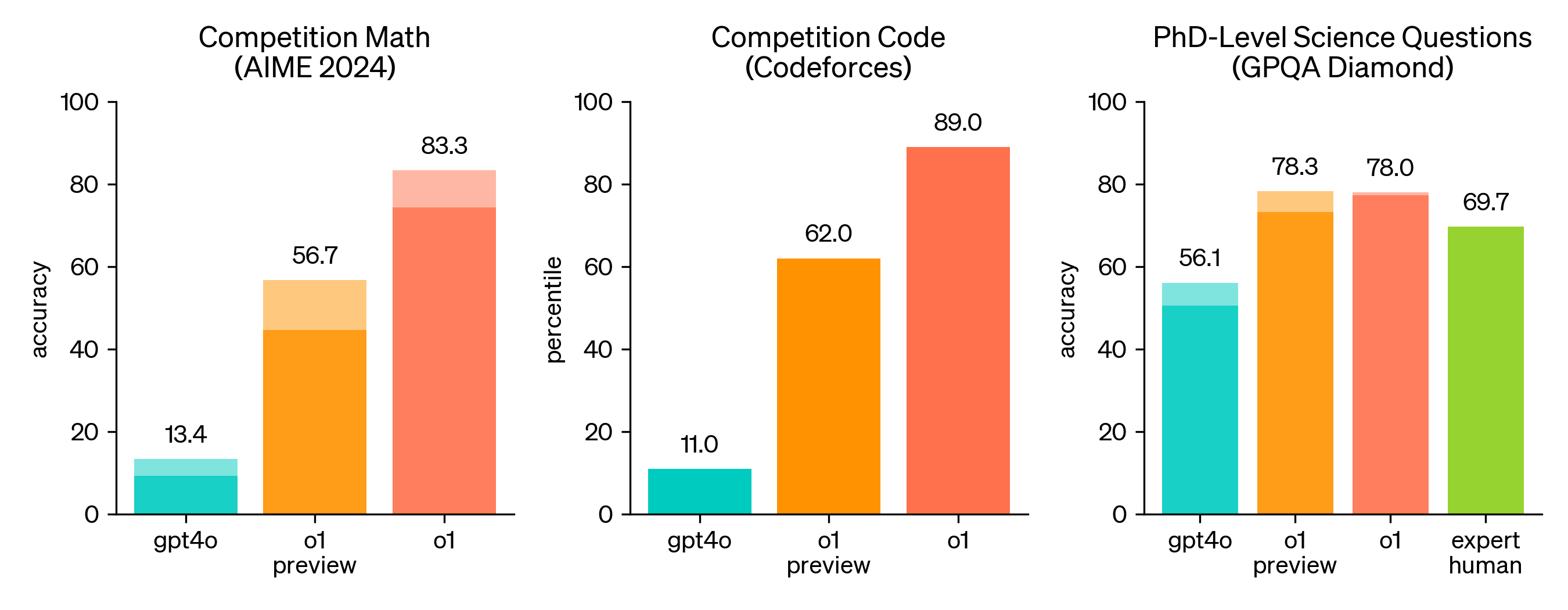
Most dramatically, a new paper on blocksworld has recently been published by some of the same highly LLM-skeptical researchers (Valmeekam et al, led by Subbarao Kambhampati[1]: 'LLMs Still Can’t Plan; Can LRMs? A Preliminary Evaluation of OpenAI’s o1 on Planbench'. Where the best previous success rate on non-obfuscated blocksworld was 57.6%, o1-preview essentially saturates the benchmark with 97.8%. On obfuscated blocksworld, where previous LLMs had proved almost entirely incapable (0.8% zero-shot, 4.3% one-shot), o1-preview jumps all the way to a 52.8% success rate. In my view, this jump in particular should update us significantly toward the LLM architecture being capable of general reasoning[2].
o1-preview also does much better on ARC-AGI than gpt-4o, jumping from 9% to 21.2% on the public eval ('OpenAI o1 Results on ARC-AGI-Pub'). Note that since my original post, Claude-3.5-Sonnet also reached 21% on the public eval.
The planning/scheduling evidence, on the other hand, seemed weaker almost immediately after the post; a commenter quickly pointed out that the paper was full of errors. Nonetheless, note that another recent paper looks at a broader range of planning problems and also finds substantial improvements from o1-preview, although arguably not the same level of 0-to-1 improvement that Valmeekam et al find with obfuscated blocksworld ('On The Planning Abilities of OpenAI’s o1 Models: Feasibility, Optimality, and Generalizability').
I would be grateful to hear about other recent research that helps answer these questions (and thanks to @Archimedes for calling my attention to these papers).
Discussion
My overall conclusion, and the reason I think it's worth posting this follow-up, is that I believe the new evidence should update all of us toward LLMs scaling straight to AGI, and therefore toward timelines being relatively short. Time will continue to tell, of course, and I have a research project planned for early spring that aims to more rigorously investigate whether LLMs are capable of the particular sorts of general reasoning that will allow them to perform novel scientific research end-to-end.
My own numeric updates follow.
Updated probability estimates
(text copied from my previous post is italicized for clarity on what changed)
- LLMs continue to do better at block world and ARC as they scale: 75% -> 100%, this is now a thing that has happened.
- LLMs entirely on their own reach the grand prize mark on the ARC prize (solving 85% of problems on the open leaderboard) before hybrid approaches like Ryan's: 10% -> 20%, this still seems quite unlikely to me (especially since hybrid approaches have showed continuing improvement on ARC). Most of my additional credence is on something like 'the full o1 turns out to already be close to the grand prize mark' and the rest on 'researchers, perhaps working with o1, manage to find an improvement to current LLM technique (eg a better prompting approach) that can be easily fixed'.
- Scaffolding & tools help a lot, so that the next gen (GPT-5, Claude 4) + Python + a for loop can reach the grand prize mark: 60% -> 75% -- I'm tempted to put it higher, but it wouldn't be that surprising if o2 didn't quite get there even with scaffolding/tools, especially since we don't have clear insight into how much harder the private test set is.
- Same but for the gen after that (GPT-6, Claude 5): 75% -> 90%? I feel less sure about this one than the others; it seems awfully likely that o3 plus scaffolding will be able to do it.
- The current architecture, including scaffolding & tools, continues to improve to the point of being able to do original AI research: 65% -> 80%. That sure does seem like the world we're living in. It seems plausible to me that o1 could already do some original AI research with the right scaffolding. Sakana claims to have already gotten there with GPT-4o / Sonnet, but their claims seem overblown to me. Regardless, I have trouble seeing a very plausible block to this.
Citations
'LLMs Still Can’t Plan; Can LRMs? A Preliminary Evaluation of Openai’S O1 on Planbench', Valmeekam et al (includes Kambhampati) 09/24
'OpenAI o1 Results on ARC-AGI-Pub', Mike Knoop 09/24
'On The Planning Abilities of OpenAI’s o1 Models: Feasibility, Optimality, and Generalizability', Wang et al 09/24.
- ^
I am restraining myself with some difficulty from jumping up and down and yelling about the level of goalpost-moving in this new paper.
- ^
There's a sense in which comparing results from previous LLMs with o1-preview isn't entirely an apples-to-apples comparison, since o1-preview is throwing a lot more inference-time compute at the problem. In that way it's similar to Ryan's hybrid approach to ARC-AGI, as discussed in the original post. But since the key question here is whether LLMs are capable of general reasoning at all, that doesn't really change my thinking here; certainly there are many problems (like capabilities research) where companies will be perfectly happy to spend a lot on compute to get a better answer.
Hey, thanks for taking the time to answer!
First, I want to make clear that I don’t believe LLMs to be just stochastic parrots, nor do I doubt that they are capable of world modeling. And you are right to request some more specifically stated beliefs and predictions. In this comment, I attempted to improve on this, with limited success.
There are two main pillars in my world model that make me, even in light of the massive gains in capabilities we have seen in the last seven year, still skeptical of transformer architecture scaling straight to AGI.
On the first point:
My model of the world circa 2017 looks like this. There's a massive data overhang, which in a certain sense took humanity all of history to create. A special kind of data, refined over many human generations of "thinking work", crystalized intelligence. But also with distinct blind spots. Some things are hard to capture with the available media, others we just didn't much care to document.
Then transformer architecture comes around, is uniquely suited to extract the insights embedded in this data. Maybe better than the brains that created it in the first place. At the very least it scales in a way that brains can't. More compute makes more of this data overhang accessible, leading to massive capability gains from model to model.
But in 2024 the overhang has been all but consumed. Humans continue to produce more data, at an unprecedented rate, but still nowhere near enough to keep up with the demand.
On the second point:
Taking the globe representation as an example, it is unclear to me how much of the resulting globe (or atlas) is actually the result of choices the authors made. The decision to map distance vectors in two or three dimensions seems to change the resulting representation. So, to what extent are these representations embedded in the model itself versus originating from the author’s mind? I'm reminded of similar problems in the research of animal intelligence.
Again, it is clear there’s some kind of world model in the LLM, but less so how much this kind of research predicts about its potential (lack of) shortcomings.
However, this is still all rather vague; let me try to formulate some predictions which could plausibly be checked in the next year or so.
Predictions:
Now, your comment prompted me to look more deeply into the current state of machine learning in robotics and the success of decision transformers and even more so behaviour transformers disagree with my predictions.
Examples:
https://arxiv.org/abs/2206.11251
https://sjlee.cc/vq-bet/
https://youtu.be/5_G6o_H3HeE?si=JOsTGvQ17ZfdIdAJ
Compound systems, yes. But clearly transformers have an outsized impact on the results, and they handled data which I would have filed under “not well-suited” just fine. For now, I’ll stick with my predictions, if only for the sake of accountability. But evidently it’s time for some more reading.