We founded Anthropic because we believe the impact of AI might be comparable to that of the industrial and scientific revolutions, but we aren’t confident it will go well. And we also believe this level of impact could start to arrive soon – perhaps in the coming decade.
This view may sound implausible or grandiose, and there are good reasons to be skeptical of it. For one thing, almost everyone who has said “the thing we’re working on might be one of the biggest developments in history” has been wrong, often laughably so. Nevertheless, we believe there is enough evidence to seriously prepare for a world where rapid AI progress leads to transformative AI systems.
At Anthropic our motto has been “show, don’t tell”, and we’ve focused on releasing a steady stream of safety-oriented research that we believe has broad value for the AI community. We’re writing this now because as more people have become aware of AI progress, it feels timely to express our own views on this topic and to explain our strategy and goals. In short, we believe that AI safety research is urgently important and should be supported by a wide range of public and private actors.
So in this post we will summarize why we believe all this: why we anticipate very rapid AI progress and very large impacts from AI, and how that led us to be concerned about AI safety. We’ll then briefly summarize our own approach to AI safety research and some of the reasoning behind it. We hope by writing this we can contribute to broader discussions about AI safety and AI progress.
As a high level summary of the main points in this post:
- AI will have a very large impact, possibly in the coming decade
Rapid and continuing AI progress is a predictable consequence of the exponential increase in computation used to train AI systems, because research on “scaling laws” demonstrates that more computation leads to general improvements in capabilities. Simple extrapolations suggest AI systems will become far more capable in the next decade, possibly equaling or exceeding human level performance at most intellectual tasks. AI progress might slow or halt, but the evidence suggests it will probably continue.- We do not know how to train systems to robustly behave well
So far, no one knows how to train very powerful AI systems to be robustly helpful, honest, and harmless. Furthermore, rapid AI progress will be disruptive to society and may trigger competitive races that could lead corporations or nations to deploy untrustworthy AI systems. The results of this could be catastrophic, either because AI systems strategically pursue dangerous goals, or because these systems make more innocent mistakes in high-stakes situations.- We are most optimistic about a multi-faceted, empirically-driven approach to AI safety
We’re pursuing a variety of research directions with the goal of building reliably safe systems, and are currently most excited about scaling supervision, mechanistic interpretability, process-oriented learning, and understanding and evaluating how AI systems learn and generalize. A key goal of ours is to differentially accelerate this safety work, and to develop a profile of safety research that attempts to cover a wide range of scenarios, from those in which safety challenges turn out to be easy to address to those in which creating safe systems is extremely difficult.
The full post goes into considerably more detail, and I'm really excited that we're sharing more of our thinking publicly.
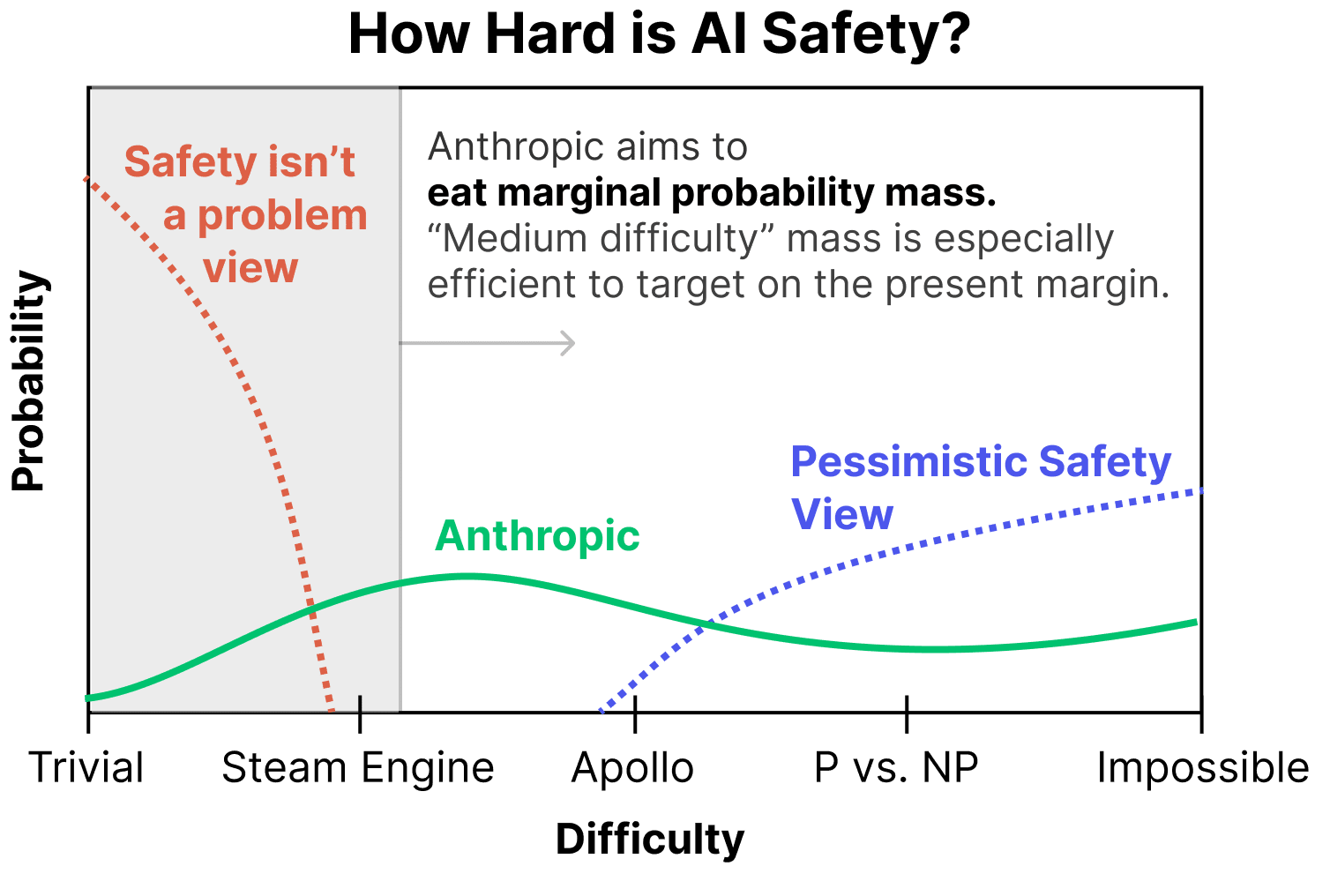
I think the worldview here seems cogent. It's very good for Anthropic folk to be writing up their organizational-beliefs publicly. I'm pretty sympathetic to "man, we have no idea how to make real progress without empirical iteration, so we just need to figure out how to make empirical iteration work somehow."
I have a few disagreements. I think the most important ones route through "how likely is this to accelerate race dynamics and how bad is that?".
It sounds like this means Claude is still a bit ahead of the public-state-of-the-art (but not much). But I'm not sure I'm interpreting it correctly.
I want to flag that an Anthropic employee recently told me something like "Anthropic wants to stay near the front of the pack at AI capabilities so that their empirical research is relevant, but not at the actual front of the pack to avoid accelerating race-dynamics." That would be a plausibly reasonable strategy IMO (although I'd still be skeptical about how likely it was to exacerbate race dynamics in a net-negative way). But it sounds like Claude was released while it was an advance over the public sota.
I guess I could square this via "Claude was ahead of the public SOTA, but not an advance over privately available networks?".
But, it generally looks to me like OpenAI and Anthropic, the two ostensibly safety-minded orgs, are nontrivially accelerating AI hype and progress due to local races between the two of them, and I feel quite scared about that.
I realize they're part of some dynamics that extend beyond them, and I realize there are a lot of difficult realities like "we really do believe we need to work on LLMs, those really are very expensive to train, we really need to raise money, the money really needs to come from somewhere, and doing some releases and deals with Google/Microsoft etc seem necessary." But, it sure looks like the end result of all of this is an accelerated race, and even if you're only on 33%ish likelihood of "a really pessimistic scenario", that's a pretty high likelihood scenario to be accelerating towards.
My guess is that from the inside of Anthropic-decisionmaking, the race feels sort of out-of-their-control, and it's better to ride the wave that to sit doing nothing. But it seems to me like "figure out how to slow down the race dynamics here" should be a top organizational priority, even within the set of assumptions outlined in this post.
That's the hard part.
My guess is that training cutting edge models, and not releasing them is a pretty good play, or would have been, if there wasn't huge AGI hype.
As it is, information about your models is going to leak, and in most cases the fact that something is possible is most of the secret to reverse engineering it (note: this might be true in the regime of transformer models, but it might not be true for other tasks or sub-problems).
But on the other hand, given the hype, people are going to try to do the things that you're doing anyway,... (read more)