From the abstract, emphasis mine:
The agent, which we refer to as Gato, works as a multi-modal, multi-task, multi-embodiment generalist policy. The same network with the same weights can play Atari, caption images, chat, stackblocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses, or other tokens.
(Will edit to add more as I read. ETA: 1a3orn posted first.)
- It's only 1.2 billion parameters. (!!!) They say this was to avoid latency in the robot control task.
- It was trained offline, purely supervised, but could in principle be trained online, with RL, etc
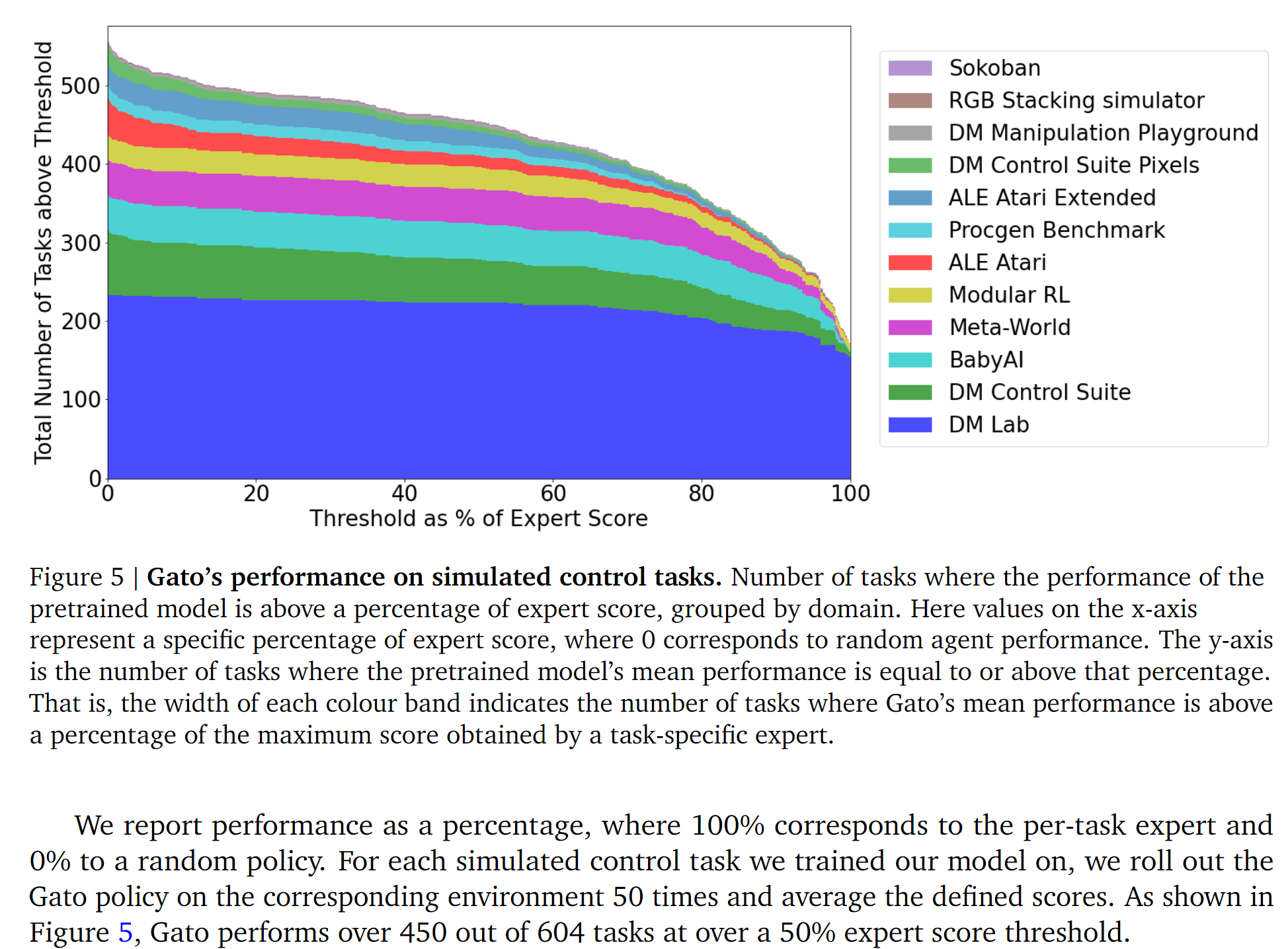
- Performance results:
The section on broader implications is interesting. Selected quote:
In addition, generalist agents can take actions in the the physical world; posing new challenges that may require novel mitigation strategies. For example, physical embodiment could lead to users anthropomorphizing the agent, leading to misplaced trust in the case of a malfunctioning system, or be exploitable by bad actors. Additionally, while cross-domain knowledge transfer is often a goal in ML research, it could create unexpected and undesired outcomes if certain behaviors (e.g. arcade game fighting) are transferred to the wrong context. The ethics and safety considerations of knowledge transfer may require substantial new research as generalist systems advance. Technical AGI safety (Bostrom, 2017) may also become more challenging when considering generalist agents that operate in many embodiments. For this reason, preference learning, uncertainty modeling and value alignment (Russell, 2019) are especially important for the design of human-compatible generalist agents. It may be possible to extend some of the value alignment approaches for language (Kenton et al., 2021; Ouyang et al., 2022) to generalist agents. However, even as technical solutions are developed for value alignment, generalist systems could still have negative societal impacts even with the intervention of well-intentioned designers, due to unforeseen circumstances or limited oversight (Amodei et al., 2016). This limitation underscores the need for a careful design and a deployment process that incorporates multiple disciplines and viewpoints.
They also do some scaling analysis and yup, you can make it smarter by making it bigger.
What do I think about all this?
Eh, I guess it was already priced in. I think me + most people in the AI safety community would have predicted this. I'm a bit surprised that it works as well as it does for only 1.2B parameters though.
Maybe I misinterpreted you and/or her sorry. I guess I was eyeballing Ajeya's final distribution and seeing how much of it is above the genome anchor / medium horizon anchor, and thinking that when someone says "we literally could scale up 2020 algorithms and get TAI" they are imagining something less expensive than that (since arguably medium/genome and above, especially evolution, represents doing a search for algorithms rather than scaling up an existing algorithm, and also takes such a ridiculously large amount of compute that it's weird to say we "could" scale up to it.) So I was thinking that probability mass in "yes we could literally scale existing algorithms" is probability mass below +12 OOMs basically. Wheras Ajeya is at 50% by +12. I see I was probably misunderstanding you; you meant scaling up existing algorithms to include stuff like genome and long-horizon anchor? But you agree it doesn't include evolution, right?)