OpenAI reports that o3-mini with high reasoning and a Python tool receives a 32% on FrontierMath. However, Epoch's official evaluation[1] received only 11%.
There are a few reasons to trust Epoch's score over OpenAIs:
- Epoch built the benchmark and has better incentives.
- OpenAI reported a 28% score on the hardest of the three problem tiers - suspiciously close to their overall score.
- Epoch has published quite a bit of information about its testing infrastructure and data, whereas OpenAI has published close to none.
Edited in Addendum:
Epoch has this to say in their FAQ:
The difference between our results and OpenAI’s might be due to OpenAI evaluating with a more powerful internal scaffold, using more test-time compute, or because those results were run on a different subset of FrontierMath (the 180 problems in
frontiermath-2024-11-26vs the 290 problems infrontiermath-2025-02-28-private).
- ^
Which had Python access.
I think your Epoch link re-links to the OpenAI result, not something by Epoch.
How likely is this just that OpenAI was willing to throw absurd amounts of inference time compute at the problem set to get a good score?
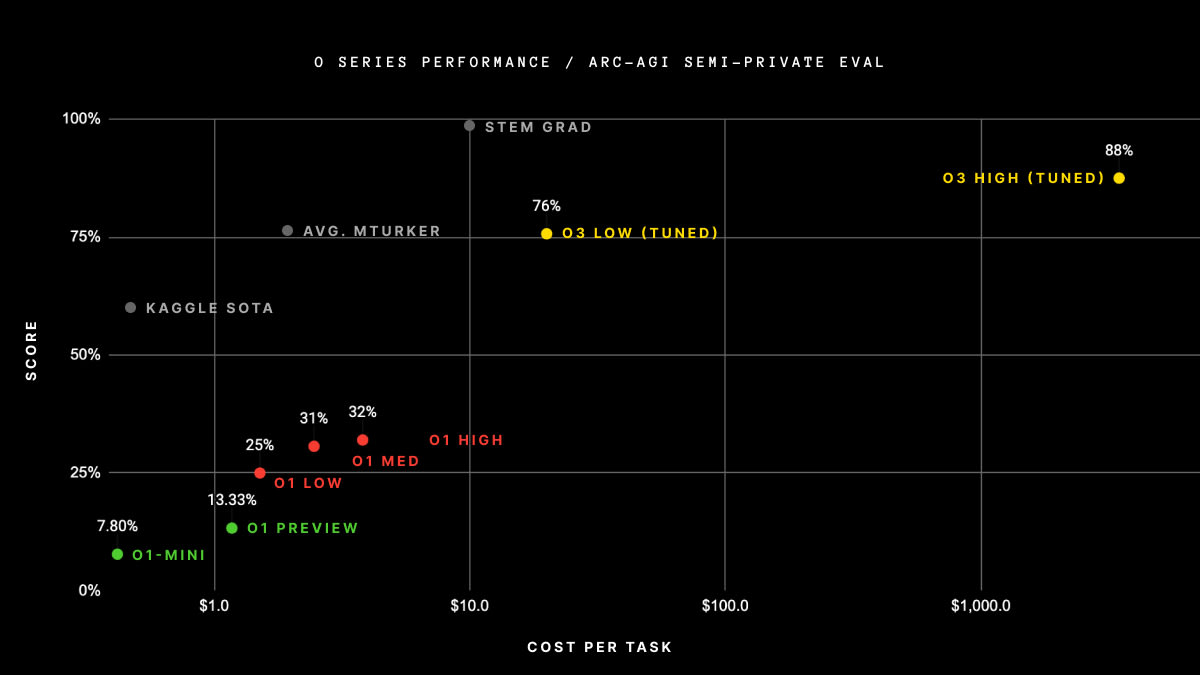
the reason why my first thought was that they used more inference is that ARC Prize specifies that that's how they got their ARC-AGI score (https://arcprize.org/blog/oai-o3-pub-breakthrough) - my read on this graph is that they spent $300k+ on getting their score (there's 100 questions in the semi-private eval). o3 high, not o3-mini high, but this result is pretty strong proof of concept that they're willing to spend a lot on inference for good scores.