Hospitalization: A Review
I woke up Friday morning w/ a very sore left shoulder. I tried stretching it, but my left chest hurt too. Isn't pain on one side a sign of a heart attack? Chest pain, arm/shoulder pain, and my breathing is pretty shallow now that I think about it, but I don't think I'm having a heart attack because that'd be terribly inconvenient. But it'd also be very dumb if I died cause I didn't go to the ER. So I get my phone to call an Uber, when I suddenly feel very dizzy and nauseous. My wife is on a video call w/ a client, and I tell her: "Baby?" "Baby?" "Baby?" She's probably annoyed at me interrupting; I need to escalate "I think I'm having a heart attack" "I think my husband is having a heart attack"[1] I call 911[2] "911. This call is being recorded. What’s your emergency?" "I think I'm having a heart attack" They ask for my address, my symptoms, say the ambulance is on the way. After a few minutes, I heard an ambulance, which is weird to realize Oh, that ambulance is for me. I've broken out into a cold sweat and my wife informs me my face is pale. Huh, I might actually die here and that's that. After 10 long minutes, they arrive at our apartment. They ask me my symptoms, ask to describe the pain, ask if moving my arm hurts. They load me up on the gurney, we bump the frame of my front door a lot getting out, and we're on our way. The paramedics didn't seem too worried, the hospital staff didn't seem too worried. They just left me in a room when I arrived. Don't some people die from a heart attacks pretty quickly? Well at least I'm at a hospital. The resident surgeon doesn't think it's a heart attack. "But I felt dizzy and nauseous and broke out in a sweat" "And his face was very pale" "Sounds like a vasovagal syncope", the doctor assured us. They take an ECG to detect irregular heart rhythms and it's all fine! They take some blood & take a CAT scan of my chest just to make extra sure though.[3] And then we wait. So I google "What's a vasova

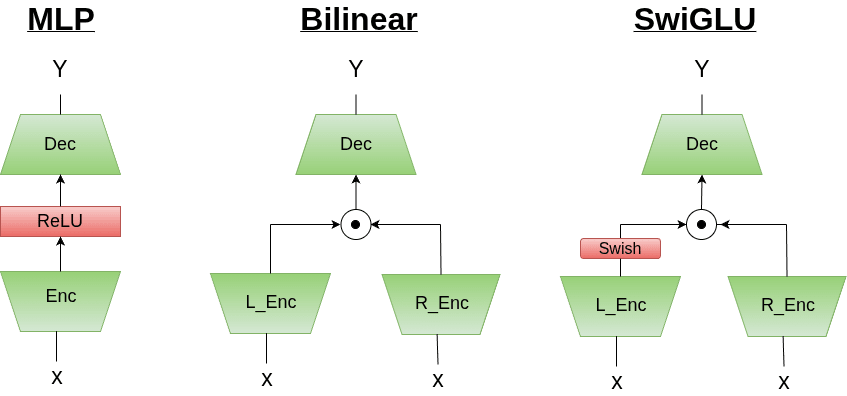


I'm confused on what you're referring to. Bilinear layers are scale invariant by linearity
Bilinear(ax)=a2Bilinear(x)So x could be the input-token, a vector d (from the previous bilinear layer), or a steering vector added in, but it will still produce the same output vector (and affect the same hidden dims of the bilinear layer in the same proportions).
Another way to say this is that for:
y=Bilinear(ax)The percentage of attribution of each weight in bilinear w/ respect to y is the same regardless of a, since to compute the percentage, you'd divide by the total so that cancels out scaling by a.
This also means that, solely from the weights, you can trace the computation done by injecting this... (read more)