All of Tamay's Comments + Replies
Tamay from Epoch AI here.
We made a mistake in not being more transparent about OpenAI's involvement. We were restricted from disclosing the partnership until around the time o3 launched, and in hindsight we should have negotiated harder for the ability to be transparent to the benchmark contributors as soon as possible. Our contract specifically prevented us from disclosing information about the funding source and the fact that OpenAI has data access to much but not all of the dataset. We own this error and are committed to doing better in the future.
For f...
Just to confirm, you will be benchmarking models other than OpenAI models using this dataset and you aren't contractually prevented from doing this right?
(The original blog post cites scores of models from multiple developers, so I assume so.)
I think you should publicly commit to:
- full transparency about any funding from for profit organisations, including nonprofit organizations affiliated with for profit
- no access to the benchmarks to any company
- no NDAs around this stuff
If you currently have any of these with the computer use benchmark in development, you should seriously try to get out of those contractual obligations if there are any.
Ideally, you commit to these in a legally binding way, which would make it non-negotiable in any negotiation, and make you more credible to outsiders.
How much funding did OpenAI provide EpochAI?
Or, how much funding do you expect to receive in total from OpenAI for FrontierMath if you haven't received all funding yet?
We acknowledge that OpenAI does have access to a large fraction of FrontierMath problems and solutions, with the exception of a unseen-by-OpenAI hold-out set that enables us to independently verify model capabilities.
Can you say exactly how large of a fraction is the set that OpenAI has access to, and how much is the hold-out set?
However, we have a verbal agreement that these materials will not be used in model training.
If by this you mean "OpenAI will not train on this data", that doesn't address the vast majority of the concern. If OpenAI is evaluating the model against the data, they will be able to more effectively optimize for capabilities advancement, and that's a betrayal of the trust of the people who worked on this with the understanding that it will be used only outside of the research loop to check for dangerous advancements. And, particularly, not to make those da...
we have a verbal agreement that these materials will not be used in model training
Get that agreement in writing.
I am happy to bet 1:1 OpenAI will refuse to make an agreement in writing to not use the problems/the answers for training.
You have done work that contributes to AI capabilities, and you have misled mathematicians who contributed to that work about its nature.
Thank you for the clarification! What I would be curious about: you write
OpenAI does have access to a large fraction of FrontierMath problems and solutions
Does this include the detailed solution write-up (mathematical arguments, in LaTeX) or just the final answer (numerical result of the question / Python script verifying the correctness of the AI response)?
I found this extra information very useful, thanks for revealing what you did.
Of course, to me this makes OpenAI look quite poor. This seems like an incredibly obvious conflict of interest.
I'm surprised that the contract didn't allow Epoch to release this information until recently, but that it does allow Epoch to release the information after. This seems really sloppy for OpenAI. I guess they got a bit extra publicity when o3 was released (even though the model wasn't even available), but now it winds up looking worse (at least for those paying attention)...
Short version: The claim that AI automation of software engineering will erase NVIDIA's software advantage misunderstands that as markets expand, the rewards for further software improvements grow substantially. While AI may lower the cost of matching existing software capabilities, overall software project costs are likely to keep increasing as returns on optimization rise. Matching the frontier of performance in the future will still be expensive and technically challenging, and access to AI does not necessarily equalize production costs or eliminate NVI...
My guess is that compute scaling is probably more important when looking just at pre-training and upstream performance. When looking innovations both pre- and post-training and measures of downstream performance, the relative contributions are probably roughly evenly matched.
Compute for training runs is increasing at a rate of around 4-5x/year, which amounts to a doubling every 5-6 months, rather than every 10 months. This is what we found in the 2022 paper, and something we recently confirmed using 3x more data up to today.
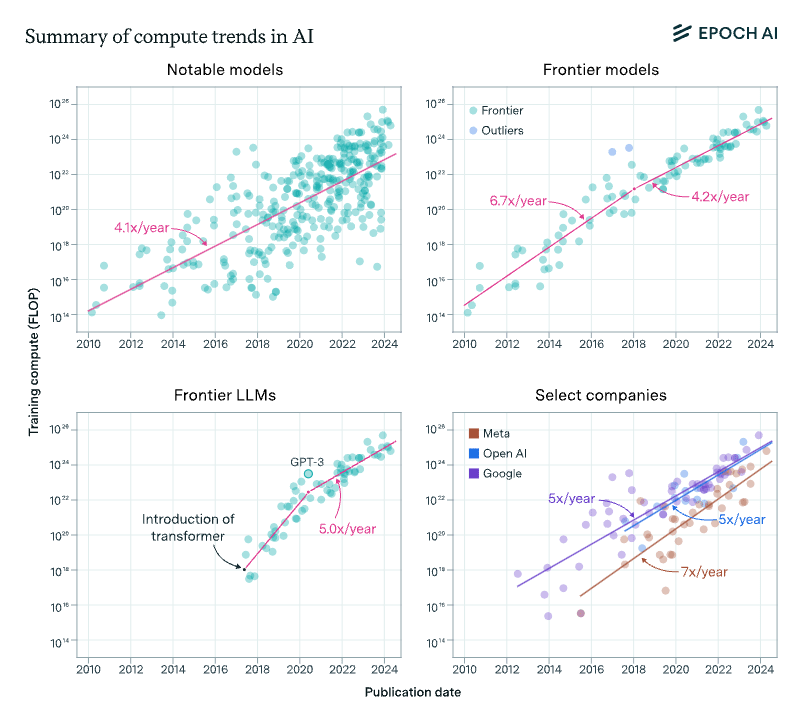
Algorithms and training techniqu...
Sebastian Borgeaud, one of the lead authors of the Chinchilla scaling paper, admits there was a bug in their code. https://twitter.com/borgeaud_s/status/1780988694163321250
Claim that the Chinchilla paper calculated the implied scaling laws incorrectly. Yes, it seems entirely plausible that there was a mistake, tons of huge training runs relied on the incorrect result, and only now did someone realize this. Why do you ask?
I'm interested. What bets would you offer?
There is an insightful literature that documents and tries to explain why large incumbent tech firms fail to invest appropriately in disruptive technologies, even when they played an important role in its invention. I speculatively think this sheds some light on why we see new firms such as OpenAI rather than incumbents such as Google and Meta leading the deployment of recent innovations in AI, notably LLMs.
Disruptive technologies—technologies that initially fail to satisfy existing demands but later surpass the dominant technology—are often underinvested ...
If the data is low-quality and easily distinguishable from human-generated text, it should be simple to train a classifier to spot LM-generated text and exclude this from the training set. If it's not possible to distinguish, then it should be high-enough quality so that including it is not a problem.
ETA: As people point out below, this comment was glib and glosses over some key details; I don't endorse this take anymore.
Generated data can be low quality but indistinguishable. Unless your classifier has access to more data or is better in some other way (e.g. larger, better architecture), you won't know. In fact, if you could know without labeling generated data, why would you generate something that you can tell is bad in the first place? I've seen this in practice in my own project.
Good question. Some thoughts on why do this:
- Our results suggest we won't be caught off-guard by highly capable models that were trained for years in secret, which seems strategically relevant for those concerned with risks
- We looked whether there was any 'alpha' in these results by investigating the training durations of ML training runs, and found that models are typically trained for durations that aren't far off from what our analysis suggests might be optimal (see a snapshot of the data here)
- It independently seems highly likely that large training runs
Thanks for thinking it over, and I agree with your assessment that this is better public knowlege than private :)
I'm not sure what you mean; I'm not looking at log-odds. Maybe the correlation is an artefact from noise being amplified in log-space (I'm not sure), but it's not obvious to me that this isn't the correct way to analyse the data.
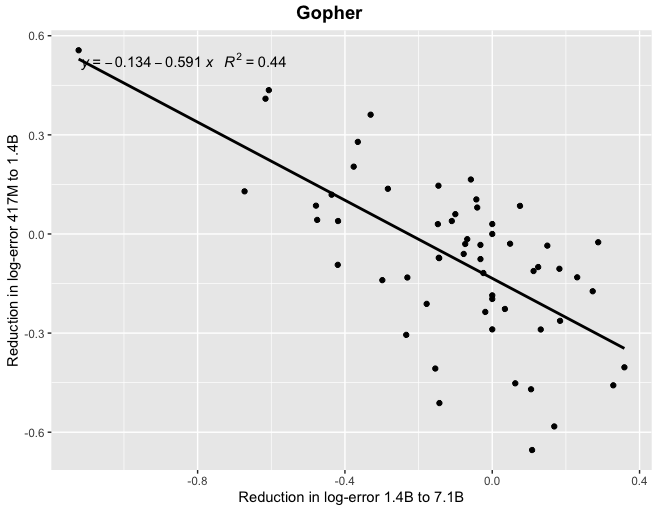
Thanks! At least for Gopher, if you look at correlations between reductions in log-error (which I think is the scaling laws literature suggests would be the more natural framing) you find a more tighter relationship, particularly when looking at the relatively smaller models.
Thanks, though I was hoping for something like a Google Sheet containing the data.
OK, here's a Google sheet I just threw together: https://docs.google.com/spreadsheets/d/1Y_00UcsYZeOwRuwXWD5_nQWAJp4A0aNoySW0EOhnp0Y/edit?usp=sharing
This is super interesting. Are you able to share the underlying data?
I just got it from the papers and ran a linear regression, using pdftables.com to convert from PDF to Excel. I used pages 68 and 79 in the Gopher paper:
https://arxiv.org/pdf/2112.11446.pdf
Page 35 in the Chinchilla paper:
https://arxiv.org/pdf/2203.15556.pdf
Pages 79 and 80 in the PaLM paper:
It is unless it's clear that a side that made a mistake in entering a lopsided bet. I guess the rule-of-thumb is to follow big bets (which tends to be less clearly lopsided) or bets made by two people whose judgment you trust.
Are you thinking of requiring each party to accept bets on either side?
Being forced to bet both sides could ensure honesty, assuming they haven't found other bets on the same or highly correlated outcomes they can use for arbitrage.
Yes. Good point.
And including from other parties, or only with each other?
I was thinking that betting would be restricted to the initial two parties (i.e. A and B), but I can imagine an alternative in which it's unrestricted.
You could imagine one party was betting at odds they consider very favourable to them, and the other party betting at odds they consider only slightly favourable, based on their respective beliefs. Then, even if they don't change their credences, one party has more room to move their odds towards their own true credences, and so drag the average towards it, and take the intermediate payments,
Sorry, I'm confused. Isn't the 'problem' that the bettor who takes a relatively more favourable odds has higher expected returns a problem with betting in general?
We also propose betting using a mechanism that mitigates some of these issues:
Since we recognize that betting incentives can be weak over long time-horizons, we are also offering the option of employing Tamay’s recently described betting procedure in which we would enter a series of repeated 2-year contracts until the resolution date.
Here’s a rough description of an idea for a betting procedure that enables people who disagree about long-term questions to make bets, despite not wanting to commit to waiting until the long-term questions are resolved.
Suppose person A and person B disagree about whether P, but can’t find any clear concrete disagreements related to this question that can be decided soon. Since they want to bet on things that pay out soon (for concreteness say they only want to bet on things that can pay out within 5 years), they don’t end up betting on anything.
What ...
Thanks!
Could you make another graph like Fig 4 but showing projected cost, using Moore's law to estimate cost? The cost is going to be a lot, right?
Good idea. I might do this when I get the time—will let you know!
Four months later, the US is seeing a steady 7-day average of 50k to 60k new cases per day. This is a factor of 4 or 5 less than the number of daily new cases that were observed over the December-January third wave period. It seems therefore that one (the?) core prediction of this post, namely, that we'd see a fourth wave sometime between March and May that would be as bad or worse than the third wave, turned out to be badly wrong.
Zvi's post is long, so let me quote the sections where he makes this prediction:
...Instead of that being the final peak and thi
It seems troubling that one of the most upvoted COVID-19 post on LessWrong is one that argued for a prediction that I think we should score really poorly.
I agree. FWIW, I strong-downvoted this post in December. I think this is the first LW post that I have strong-downvoted before.
Additionally, I commented on it (and on threads where this post was shared elsewhere, e.g. on Facebook) to explain my disagreement with it, and recorded ~the lowest forecast of anyone who submitted their forecast here that there'd be a 4th wave in the US in 2021.
What I failed t...
I think GPT-3 is the trigger for 100x larger projects at Google, Facebook and the like, with timelines measured in months.
My impression is that this prediction has turned out to be mistaken (though it's kind of hard to say because "measured in months" is pretty ambiguous.) There have been models with many-fold the number of parameters (notably one by Google*) but it's clear that 9 months after this post, there haven't been publicised efforts that use close to 100x the amount of compute of GPT-3. I'm curious to know whether and how the author (or others ...
Nine months later I consider my post pretty 'shrill', for want of a better adjective. I regret not making more concrete predictions at the time, because yeah, reality has substantially undershot my fears. I think there's still a substantial chance of something 10x large being revealed within 18 months (which I think is the upper bound on 'timeline measured in months'), but it looks very unlikely that there'll be a 100x increase in that time frame.
To pick one factor I got wrong in writing the above, it was thinking of my massive update in response to ...
Great work! It seems like this could enable lots of useful applications. One thing in particular that I'm excited about is how this can be used to make forecasting more decision-relevant. For example, one type of application that comes to mind in particular is a conditional prediction market where conditions are continuous rather than discrete (eg. "what is GDP next year if interest rate is set to r?", "what is Sierra Leone's GDP in ten years if bednet spending is x?").
If research into general-purpose systems stops producing impressive progress, and the application of ML in specialised domains becomes more profitable, we'd soon see much more investment in AI labs that are explicitly application-focused rather than basic-research focused.
I had in mind just your original counterparty. Requiring become a public market maker seems like quite the commitment.