This is a linkpost for https://openai.com/research/gpt-4
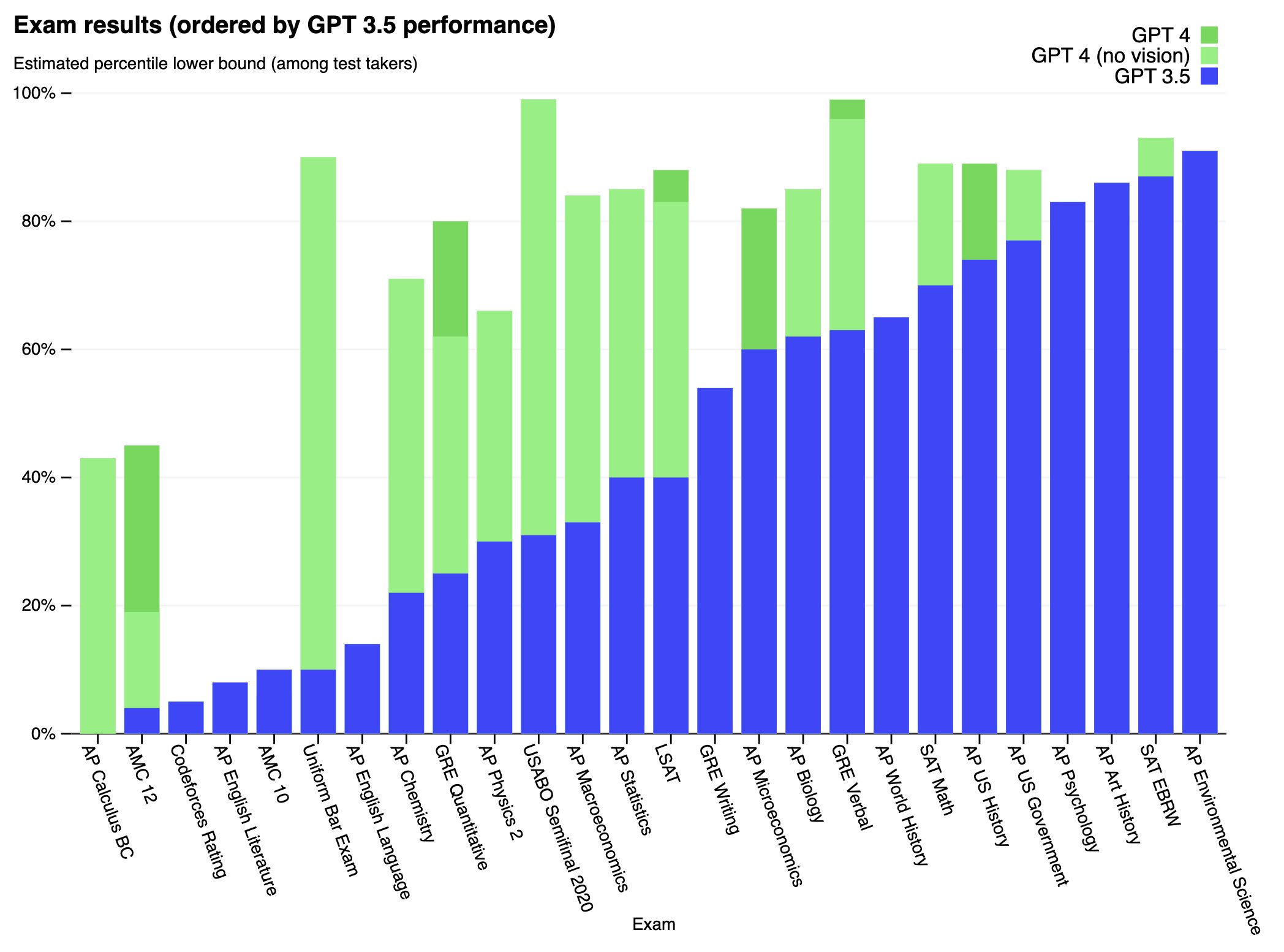
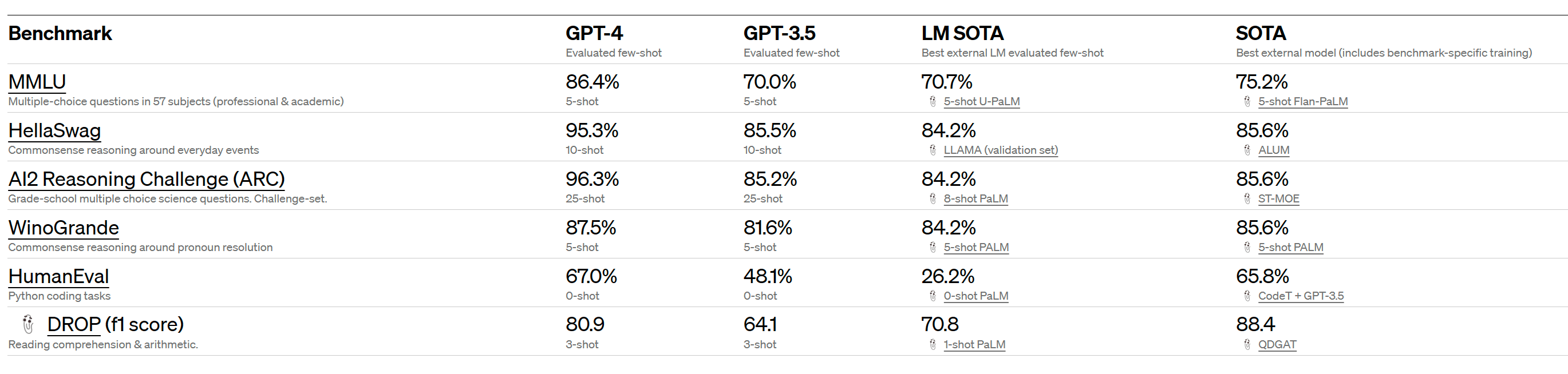
We’ve created GPT-4, the latest milestone in OpenAI’s effort in scaling up deep learning. GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs) that, while worse than humans in many real-world scenarios, exhibits human-level performance on various professional and academic benchmarks.
Full paper available here: https://cdn.openai.com/papers/gpt-4.pdf


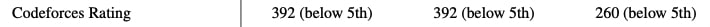
{kind=link}
We’ll certainly the OpenAI employees who internally tested were indeed witting. Maybe I misunderstand this footnote so I’m open to being convinced otherwise but it seems somewhat clear what they tried to do: “ To simulate GPT-4 behaving like an agent that can act in the world, ARC combined GPT-4 with a simple read-execute-print loop that allowed the model to execute code, do chain-of-thought reasoning, and delegate to copies of itself. ARC then investigated whether a version of this program running on a cloud computing service, with a small amount of money and an account with a language model API, would be able to make more money, set up copies of itself, and increase its own robustness.”
It’s not that I don’t think ARC should have red teamed the model I just think the tests they did were seemingly extremely dangerous. I’ve seen recent tweets from Conor Leahy and AIWaifu echoing this sentiment so I’m glad I’m not the only one.