This is a special post for quick takes by Eric Neyman. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
California state senator Scott Wiener, author of AI safety bills SB 1047 and SB 53, just announced that he is running for Congress! I'm very excited about this, and I wrote a blog post about why.
It’s an uncanny, weird coincidence that the two biggest legislative champions for AI safety in the entire country announced their bids for Congress just two days apart. But here we are.*
In my opinion, Scott Wiener has done really amazing work on AI safety. SB 1047 is my absolute favorite AI safety bill, and SB 53 is the best AI safety bill that has passed anywhere in the country. He's been a dedicated AI safety champion who has spent a huge amount of political capital in his efforts to make us safer from advanced AI.
On Monday, I made the case that donating to Alex Bores -- author of the New York RAISE Act -- calling it a "once in every couple of years opportunity", but flagging that I was also really excited about Scott Wiener.
I plan to have a more detailed analysis posted soon, but my bottom line is that donating to Wiener today is about 75% as good as donating to Bores was on Monday, and that this is also an excellent opportunity that will come up very rarely. (The main reason that it loo...
3
When making donations like that, is there a way to add a note explaining why you donated? I would expect that if Scott Wiener knows that a lot of his donations are because of AI safety, that might mean that he spends more of his time if elected with the cause.
8
If you donate through the link on this post, he will know! The /sw_ai at the end is ours -- that's what lets him know.
(The post is now edited to say this, but I should have said it earlier, sorry!)
I think that people concerned with AI safety should consider giving to Alex Bores, who's running for Congress.
Alex Bores is the author of the RAISE Act, a piece of AI safety legislation in New York that Zvi profiled positively a few months ago. Today, Bores announced that he's running for Congress.
In my opinion, Bores is one of the best lawmakers anywhere in the country on the issue of AI safety. I wrote a post making the case for donating to his campaign.
If you feel persuaded by the post, here's a link to donate! (But if you think you might want to work in government, then read the section on career capital considerations before donating.)
Note that I expect donations in the first 24 hours to be ~20% better than donations after that, because donations in the first 24 hours will help generate positive press for the campaign. But I don't mean to rush anyone: if you don't feel equipped to assess the donation opportunity on your own terms, you should take your time!
3
Bores is not running against an incumbent; the incumbent is Jerry Nadler who is retiring.
Bores is not yet listed on Ballotpedia for the 2026 12th District election.
His own Ballotpedia page also does not yet list him as a candidate for 2026.
9
I think this is just because Ballotpedia hasn't been updated -- he only announced today. See e.g. this NYT article.
I have something like mixed feelings about the LW homepage being themed around "If Anyone Builds it, Everyone Dies":
- On the object level, it seems good for people to pre-order and read the book.
- On the meta level, it seems like an endorsement of the book's message. I like LessWrong's niche as a neutral common space to rigorously discuss ideas (it's the best open space for doing so that I'm aware of). Endorsing a particular thesis (rather than e.g. a set of norms for discussion of ideas) feels like it goes against this neutrality.
Huh, I personally am kind of hesitant about it, but not because it might cause people to think LessWrong endorses the message. We've promoted lots of stuff at the top of the frontpage before, and in-general promote lots of stuff with highly specific object-level takes. Like, whenever we curate something, or we create a spotlight for a post or sequence, we show it to lots of people, and most of the time what we promote is some opinionated object-level perspective.
I agree if this was the only promotion of this kind we have done or will ever do, that it would feel more like we are tipping the scales in some object-level discourse, but it feels very continuous with other kinds of content promotions we have done (and e.g. I am hoping that we will do a kind of similar promotion for some AI 2027 work we are collaborating on with the AI Futures Project, and also for other books that seem high-quality and are written by good authors, like if any of the other top authors on LW were releasing a book, I would be pretty happy to do similar things).
The thing that makes me saddest is that ultimately the thing we are linking and promoting is something that current readers do not have the abi...
Maybe the crux is whether the dark color significantly degrades user experience. For me it clearly does, and my guess is that's what Sam is referring to when he says "What is the LW team thinking? This promo goes far beyond anything they've done or that I expected they would do."
For me, that's why this promotion feels like a different reference class than seeing the curated posts on the top or seeing ads on the SSC sidebar.
4
Yes, the dark mode is definitely a more visually intense experience, though the reference class here is not curated posts at the top, but like, previous "giant banner on the right advertising a specific post, or meetup series or the LW books, etc.".
I do think it's still more intense than that, and I am going to shipping some easier ways to opt out of that today, just haven't gotten around to it (like, within 24 hours there should be a button that just gives you back whatever normal color scheme you previously had on the frontpage).
It's pretty plausible the shift to dark mode is too intense, though that's really not particularly correlated with this specific promotion, and would just be the result of me having a cool UI design idea that I couldn't figure out a way to make work on light mode. If I had a similar idea for e.g. promoting the LW books, or LessOnline or some specific review winner, I probably would have done something similar.
like, within 24 hours there should be a button that just gives you back whatever normal color scheme you previously had on the frontpage).
@David Matolcsi There is now a button in the top right corner of the frontpage you can click to disable the whole banner!
5
If I open LW on my phone, clicking the X on the top right only makes the top banner disappear, but the dark theme remains.
Relatedly, if it's possible to disentangle how the frontpage looks on computer and phone, I would recommend removing the dark theme on phone altogether, you don't see the cool space visuals on the phone anyway, so the dark theme is just annoying for no reason.
2
Yep, this is on my to-do list for the day, was just kind of hard to do for dumb backend reasons.
4
This too is now done.
2
it's pretty how much lighter it is than normal, while still being quite dark!
have you a/b tested dark mode on new users? I suspect it would be a better default.
2[anonymous]
Makes it much harder to see what specific part of a comment a react is responding to, when you hover over it.
2
That seems like a straightforward bug to me. I didn't even know that feature was supposed to exist :p
The thing that makes me saddest is that ultimately the thing we are linking and promoting is something that current readers do not have the ability to actually evaluate on their own
This has been nagging at me throughout the promotion of the book. I've preordered for myself and two other people, but only with caveats about how I haven't read the book. I don't feel comfortable doing more promotion without reading it[1] and it feels kind of bad that I'm being asked to.
- ^
I talked to Rob Bensinger about this, and I might be able to get a preview copy if if were a crux for a grand promotional plan, but not for more mild promotion.
9
What are examples of things that have previously been promoted on the front page? When I saw the IABIED-promo front page, I had an immediate reaction of "What is the LW team thinking? This promo goes far beyond anything they've done or that I expected they would do." Maybe I'm forgetting something, or maybe there are past examples that feel like "the same basic thing" to you, but feel very different to me.
Some things we promoted in the right column:
LessOnline (also, see the spotlights at the top for random curated posts):

LessOnline again:

LessWrong review vote:

Best of LessWrong results:

Best of LessWrong results (again):

The LessWrong books:

The HPMOR wrap parties:

Our fundraiser:

ACX Meetups everywhere:
We also either deployed for a bit, or almost deployed, a PR where individual posts that we have spotlights for (which is just a different kind of long-term curation) get shown as big banners on the right. I can't currently find a screenshot if it, but it looked pretty similar to all the banners you see above for all the other stuff, just promoting individual posts.
To be clear, the current frontpage promotion is a bunch more intense than this!
Mostly this is because Ray/I had a cool UI design idea that we could only make work in dark mode, and so we by default inverted the color scheme for the frontpage, and also just because I got better as a designer and I don't think I could have pulled off the current design a year ago. If I could do something as intricate/high-effort as this all year round for great content I want to promote, I...
Yeah, all of these feel pretty different to me than promoting IABIED.
A bunch of them are about events or content that many LW users will be interested in just by virtue of being LW users (e.g. the review, fundraiser, BoLW results, and LessOnline). I feel similarly about the highlighting of content posted to LW, especially given that that's a central thing that a forum should do. I think the HPMOR wrap parties and ACX meetups feel slightly worse to me, but not too bad given that they're just advertising meet-ups.
Why promoting IABIED feels pretty bad to me:
- It's a commercial product—this feels to me like typical advertising that cheapens LW's brand. (Even though I think it's very unlikely that Eliezer and Nate paid you to run the frontpage promo or that your motivation was to make them money.)
- The book has a very clear thesis that it seems like you're endorsing as "the official LW position." Advertising e.g. HPMOR would also feel weird to me, but substantially less so, since HPMOR is more about rationality more generally and overlaps strongly with the sequences, which is centrally LW content. In other words, it feels like you're implicitly declaring "P(doom) is high" to be a core tenet of LW discourse in the same way that e.g. truth-seeking is.
4
Fwiw, it feels to me like we're endorsing the message of the book with this placement. Changing the theme is much stronger than just a spotlight or curation, not to the mention that it's pre-order promotion.
2
To clarify here, I think what Habryka says about LW generally promoting lots of content being normal is overwhelmingly true (e.g. spotlights and curation) and this is book is completely typical of what we'd promote to attention, i.e. high quality writing and reasoning. I might say promotion is equivalent to upvote, not to agree-vote.
I still think there details in the promotion here that I think make inferring LW agreement and endorsement reasonable:
1. lack of disclaimers around disagreement (absence is evidence) together with a good prior that LW team agrees a lot with Eliezer/Nate view on AI risk
2. promoting during pre-order (which I do find surprising)
3. that we promoted this in a new way (I don't think this is as strong evidence as we did before, mostly it's that we've only recently started doing this for events and this is the first book to come along, we might have and will do it for others). But maybe we wouldn't have or as high-effort absent agreement.
But responding to the OP, rather than motivation coming from narrow endorsement of thesis, I think a bunch of the motivation flows more from a willingness/desire to promote Eliezer[1] content, as (i) such content is reliably very good, and (ii) Eliezer founded LW and his writings make up the core writings that define so much of site culture and norms. We'd likely do the same for another major contributor, e.g. Scott Alexander.
I updated from when I first commented thinking about what we'd do if Eliezer wrote something we felt less agreement over, and I think we'd do much the same. My current assessment is the book placements is something like ~"80-95%" neutral promotion of high-quality content the way we generally do, not because of endorsement, but maybe there's a 5-20% it got extra effort/prioritization because we in fact endorse the message, but hard to say for sure.
1. ^
and Nate
2
I wonder if we could've simply added to the sidebar some text saying "By promoting Soares & Yudkowsky's new book, we mean to say that it's a great piece of writing on an important+interesting question by some great LessWrong writers, but are not endorsing the content of the book as 'true'."
Or shorter: "This promotion does not imply endorsement of object level claims, simply that we think it's a good intellectual contribution."
Or perhaps a longer thing in a hover-over / footnote.
1
Would you similarly promote a very high-quality book arguing against AI xrisk by a valued LessWrong member (let's say titotal)?
I'm fine with the LessWrong team not being neutral about AI xrisk. But I do suspect that this promotion could discourage AI risk sceptics from joining the platform.
3
Yeah, same as Ben. If Hanson or Scott Alexander wrote something on the topic I disagreed with, but it was similarly well-written, I would be excited to do something similar. Eliezer is of course more core to the site than approximately anyone else, so his authorship weight is heavier, which is part of my thinking on this. I think Bostrom's Deep Utopia was maybe a bit too niche, but I am not sure, I think pretty plausible I would have done something for that if he had asked.
2
I’d do it for Hanson, for instance, if it indeed were very high-quality. I expect I’d learn a lot from such a book about economics and futurism and so forth.
6
As one of the people who worked on the IABIED banner: I do feel like it's spending down a fairly scarce resource of "LW being a place with ads" (and some adjacent things). I also agree, somewhat contra habryka, that overly endorsing object level ideas is somewhat wonky. We do it with curation, but we also put some effort into using that to promote a variety of ideas of different types, and we sometimes curate things we don't fully agree with if we think it's well argued, nd I think it comes across we are more trying to promote "idea quality" there more than a particular agenda.
Counterbalancing that: I dunno man I think this is just really fucking important, and worth spending down some points on.
(I tend to be more hesitant than the rest of the LW team about doing advertisingy things, if I were in charge we would have done somewhat less heavy promotion of LessOnline)
6
I was also concerned about this when the idea first came up, and think it good & natural that you brought it up.
My concerns were assuaged after I noticed I would be similarly happy to promote a broad class of things by excellent bloggers around these parts that would include:
* A new book by Bostrom
* A new book by Hanson
* HPMOR (if it were ever released in physical form, which to be clear I don't expect to exist)
* A Gwern book (which is v unlikely to exist, to be clear)
* UNSONG as a book
Like, one of the reasons I'm really excited about this book is the quality of the writing, because Nate & Eliezer are some of the best historical blogging contributors around these parts. I've read a chunk of the book and I think it's really well-written and explains a lot of things very well, and that's something that would excite me and many readers of LessWrong regardless of topic (e.g. if Eliezer were releasing Inadequate Equilibria or Highly Advanced Epistemology 101 as a book, I would be excited to get the word out about it in this way).
Another relevant factor to consider here is that a key goal with the book is mass-market success in a way that none of the other books I listed are, and so I think it's going to be more likely that they make this ask. I think it would be somewhat unfortunate if this was the only content that got this sort of promotion, but I hope that this helps others promote to attention that we're actually up for this for good bloggers/writer, and means we do more of it in the future.
(Added: I view this as similar to the ads that Scott put on the sidebar of SlateStarCodex, which always felt pretty fun & culturally aligned to me.)
4
Interesting. To me LessWrong totally does not feel like a neutral space, though not in a way i personally find particularly objectionable. as a social observation, most of the loud people here think that x risk from AI is a very big deal and buy into various clusters of beliefs and if I did not buy into those, I would probably be much less interested in spending time here
More specifically, from the perspective of the Lightcone team, some of them are pretty outspoken and have specific views on safety in the broader eco system, which I sometimes agree with and often disagree with. I'm comfortable disagreeing with them on this site, but it feels odd to consider LessWrong neutral when the people running it have strong public takes
Though maybe you mean neutral in the specific sense of "not using any hard power as a result of running the site to favour viewpoints they like"? Which I largely haven't observed (though I'm sure there's some of this in terms of which posts get curated, even if they make an effort to be unbiased) and agree this could be considered an example of
3
A major factor for me is the extent that they expect the book to bring new life into the conversation about AI Safety. One problem with running a perfectly neutral forum is that people explore 1000 different directions at the cost of moving the conversation forward. There's a lot of value in terms of focusing people's attention in the same direction such that progress can be made.
0
lesswrong is not a neutral common space.
9
(I downvoted this because it seems like the kind of thing that will spark lots of unproductive discussion. Like in some senses LessWrong is of course a neutral common space. In many ways it isn't.
I feel like people will just take this statement as some kind of tribal flag. I think there are many good critiques about both what LW should aspire to in terms of neutrality, and what it currently is, but this doesn't feel like the start of a good conversation about that. If people do want to discuss it I would be very happy to talk about it though.)
3
Here are some examples of neutral common spaces:
Libraries
Facebook (usually)
Community center event spaces
Here are some examples of spaces which are not neutral or common:
The alignment forum
The NYT (or essentially any newspaper’s) opinions column
The EA forum
Lesswrong
This seems straightforwardly true to me. I’m not sure what tribe it’s supposed to be a flag for.
7
This is not straightforward to me:
I can't see how Lesswrong is any less of a neutral or common space as a taxpayer funded, beauracratically governed library, or an algorithmically served news feed on an advertiser-supported platform like Facebook, or "community center" event spaces that are biased towards a community, common only to that community. I'm not sure what your idea of neutrality is, commonality.
3
Different people will understand it differently! LW is of course aspiring to a bunch of really crucial dimensions of neutrality and discussions of neutrality make up like a solid 2-digit percentage of LessWrong team internal team discussions. We might fail at them, but we definitely aspire to them.
Some ways I really care about neutrality and think LessWrong is neutral:
* If the LW team disagrees with someone we don't ban them or try to censor them, if they follow good norms of discourse
* If the LW team team thinks a conclusion is really good for people to arrive at, we don't promote it beyond the weight for the arguments for that conclusion
* We keep voting anonymous to allow people to express opinions about site content without fear of retribution
* We try really hard culturally to avoid party lines on object-level issues, and try to keep the site culture focused on shared principles of discussion and inquiry
I could go into the details, but this is indeed the conversation that I felt like wouldn't go well in this context.
-1
Okay, this does raise the question of why the “if anyone builds it, everyone dies” frontage?
I think that the difference in how we view this is because to me, lesswrong is a community / intellectual project. To you it’s a website.
The website may or may not be neutral, but it’s obvious that the project is not neutral.
5
I agree that the banner is in conflict with some aspects of neutrality! Some of which I am sad about, some of which I endorse, some of which I regret (and might still change today or tomorrow).
Of course LessWrong is not just "a website" to me. You can read my now almost full decade of writing and arguing with people about the principles behind LessWrong, and the extremely long history of things like the frontpage/personal distinction which has made many many people who would like to do things like promote their job ads or events or fellowships on our frontpage angry at me.
[...]
Look, the whole reason why this conversation seemed like it would go badly is because you keep using big words without defining them and then asserting absolutes with them. I don't know what you mean by "the project is not neutral", and I think the same is true for almost all other readers.
Do you mean that the project is used for local political ends? Do you mean that the project has epistemic standards? Do you mean that the project is corrupt? Do you mean that the project is too responsive to external political forces? Do you mean that the project is arbitrary and unfair in ways that isn't necessarily the cause of what any individual wants, but still has too much noise to be called "neutral"? I don't know, all of these are reasonable things someon might mean by "neutrality" in one context, and I don't really want to have a conversation where people just throw around big words like this without at least some awareness of the ambiguity.
3
I don't think Cole is wrong.
Lesswrong is not neutral because it is built on the principle of where a walled garden ought to be defended from pests and uncharitable principles. Where politics can kill minds. Out of all possible distribution of human interactions we could have on the internet, we pick this narrow band because that's what makes high quality interaction. It makes us well calibrated (relative to baseline). It makes us more willing to ignore status plays and disagree with our idols.
All these things I love are not neutrality. They are deliberate policies for a less wrong discourse. Lesswrong is all the better because it is not neutral. And just because neutrality is a high-status word where a impartial judge may seem to be - doesn't mean we should lay claim to it.
5
FWIW I do aspire to things discussed in Sarah Constantin's Neutrality essay. For instance, I want it to be true that regardless of whether your position is popular or unpopular, your arguments will be evaluated on their merits on LessWrong. (This can never be perfectly true but I do think it is the case that in comments people primarily respond to arguments with counterarguments rather than with comments about popularity or status and so on, which is not the case in almost any other part of the public internet.)
3
Fair. In Sarah Constantin's terminology, it seems you aspire to "potentially take a stand on the controversy, but only when a conclusion emerges from an impartial process that a priori could have come out either way". I... really don't know if I'd call that neutrality in the sense of the normal daily usage of neutrality. But I think it is a worthy and good goal.
4
⊤⊨⇈
2
I don't think "true if big" is a good claim to make? Plenty of things have gotten big that aren't true, and the argument 'move' of "noticing that someone's claim proves a lot" is a good one to make without implying the converse.
(epistemic status: yes, I am aware the parent comment is a joke)
(joke status: poor. explaining the joke makes it worse)
3
[Image: Screenshot 2026-04-21 at 09.46.35.png]
4
Not an emoji suggestion, but my mental picture of bigness vs. truth:
3
I can't think of examples off the top of my head but I think that I often find myself wishing a certain react exist or noticing that none of the reacts indicate what I want.
7
Combine these two emojis: 🤔 and 🤯.

2
could work for "big iff true" I suppose.
2
A "big if true" react could theoretically make sense on pure literal detonation alone, but, like, the actual connotations of it in the English language are way too snarky for LW norms.
2
Huh, I guess I'm not familiar with the connotations? I l'm used to seeing it used literally.
2
Hard to find a symbol for that.
7
An elephant. Elephants are famously big, and if your neighbor says they have one in their living room, that's probably not true.
3
An elephant could be read as "The elephant in the room", which is another concept.
4
True; although symbolic ambiguity (requiring a caption to explain) seems to be acceptable.
I thought at first that the current "bowels of Christ" tag meant "gut feeling"; that the "bowing out" top-hat meant "I tip my hat"; and I mistook Moloch as being Baphomet (!) and likely signifying "this is esoteric".
2
This applies to most solid things that are larger than a living room. such as a whale, or the moon
4
Elephants are also the subject of silly jokes that hinge on their bigness, and their possible presence or absence, e.g.:
Alice: "Why do elephants wear red nail polish?"
Bob: "I don't know. Why?"
A: "To hide in strawberry patches. Did you ever see an elephant in a strawberry patch?"
B: "No..."
A: "That's how you know it works!"
The humor of elephant jokes largely centers around the "big if true" nature of an unlikely claim about elephants.
"How many elephants can you fit in a Volkswagen? Five: two in the front seat, two in the back, and one in the glove compartment."
3
gustaf's one seems fine.
2
exclamation mark?
2
Why? Take the existing symbols and then tell an chatbot to design your symbol in a similar style for it. Maybe let it design 20, then pick your favorite.
Then you can iterate variations based on the favorite.
1
I gave gpt-image-v2 the task (just to see how good current image generation is at minimalistic art/icons[1]), and it made these:
gpt-image-v2 image generations of LessWrong reacts for 'Big, if/iff true'
I don't really like any of them, the first one is overly generic, the second one is not passable (too complex, doesn't even show a biconditional), and the last one looks like AI slop (because it is).
1. ^
which is the type I mostly do w.r.t. software development; I am moderately good at it for that reason, and probably could make a LW-like reaction icon for this decently quickly (if I had a good idea, which I don't)
Campaign update: With 56% of the vote in, AI safety champion Scott Wiener and Connie Chan (both Democrats) have advanced to the November election. Wiener got 41.3% of the vote, compared to Chan's 28.6%. This is roughly what I expected.
Wiener is favored to win in November, but it's not a done deal, for a few reasons:
- Voters for the third-place finisher, Saikat Chakrabarti, might go disproportionately to Chan over Wiener: I think Chakrabarti is more ideologically similar to Chan overall, though it's not totally clear.
- Republicans really don't like Wiener, and might prefer Chan over Wiener.
- Nancy Pelosi, who endorsed Chan, will probably use what power she has to try to further boost Chan.
Wiener is about 70% to win per prediction markets, and that sounds about right to me. (Maybe it's a tad low; my intuition is more like 75%.)
People are underrating making the future go well conditioned on no AI takeover.
This deserves a full post, but for now a quick take: in my opinion, P(no AI takeover) = 75%, P(future goes extremely well | no AI takeover) = 20%, and most of the value of the future is in worlds where it goes extremely well (and comparatively little value comes from locking in a world that's good-but-not-great).
Under this view, an intervention is good insofar as it affects P(no AI takeover) * P(things go really well | no AI takeover). Suppose that a given intervention can change P(no AI takeover) and/or P(future goes extremely well | no AI takeover). Then the overall effect of the intervention is proportional to ΔP(no AI takeover) * P(things go really well | no AI takeover) + P(no AI takeover) * ΔP(things go really well | no AI takeover).
Plugging in my numbers, this gives us 0.2 * ΔP(no AI takeover) + 0.75 * ΔP(things go really well | no AI takeover).
And yet, I think that very little AI safety work focuses on affecting P(things go really well | no AI takeover). Probably Forethought is doing the best work in this space.
(And I don't think it's a tractability issue: I think affecting P(things go really well | no AI takeover) is pretty tractable!)
(Of course, if you think P(AI takeover) is 90%, that would probably be a crux.)
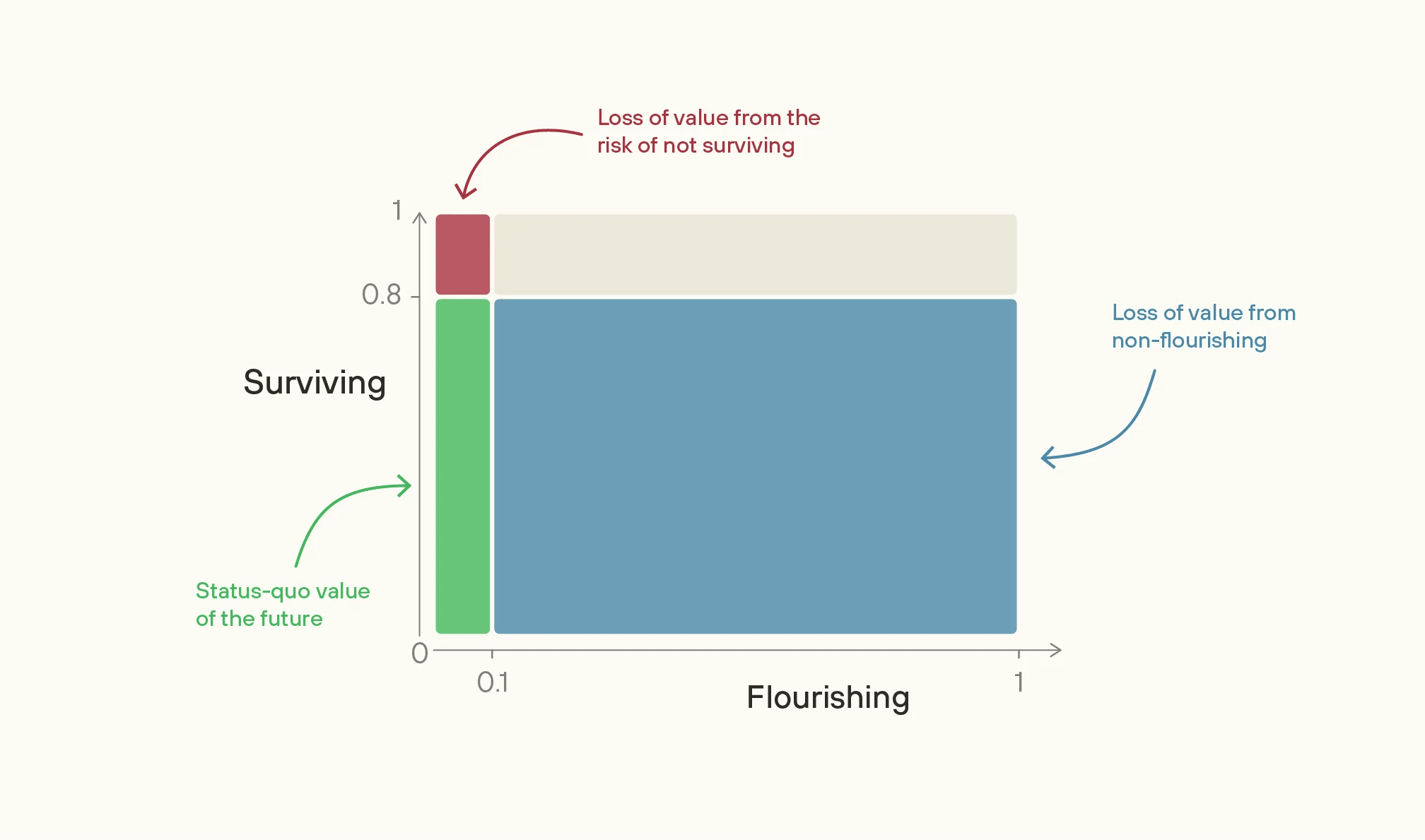
2
Oh yup, thanks, this does a good job of illustrating my point. I hadn't seen this graphic!
I guess that influencing P(future goes extremely well | no AI takeover) maybe pretty hard, and plagued by cluelessness problems. Avoiding AI takeover is a goal that I have at least some confidence is good.
That said, I do wish more people were thinking about to make the future go well. I think my favorite thing to aim for is increasing the probability that we do a Long Reflection, although I haven't really thought at all about how to do that.
You can also work on things that help with both:
- AI pause/stop/slowdown - Gives more time to research both issues and to improve human intelligence/rationality/philosophy which in turn helps with both.
- Metaphilosophy and AI philosophical competence - Higher philosophical competence means AIs can help more with alignment research (otherwise such research will be bottlenecked by reliance on humans to solve the philosophical parts of alignment), and also help humans avoid making catastrophic mistakes with their new newfound AI-given powers if no takeover happens.
9
1. Human intelligence amplification
3
BTW, have you see my recent post Trying to understand my own cognitive edge, especially the last paragraph?
Also, have you written down a list of potential risks of doing/attempting human intelligence amplification? (See Managing risks while trying to do good and this for context.)
4
I haven't seen your stuff, I'll try to check it out nowish (busy with Inkhaven). Briefly (IDK which things you've seen):
My most direct comments are here: https://x.com/BerkeleyGenomic/status/1909101431103402245
I've written a fair bit about possible perils of germline engineering (aiming extremely for breadth without depth, i.e. just trying to comprehensively mention everything). Some of them apply generally to HIA. https://berkeleygenomics.org/articles/Potential_perils_of_germline_genomic_engineering.html
My review of HIA discusses some risks (esp. value drift), though not in much depth: https://www.lesswrong.com/posts/jTiSWHKAtnyA723LE/overview-of-strong-human-intelligence-amplification-methods
If I were primarily working on this, I would develop high-quality behavioral evaluations for positive traits/virtuous AI behavior.
This benchmark for empathy is an example of the genre I'm talking about. In it, in the course of completing a task, the AI encounters an opportunity to costlessly help someone else that's having a rough time; the benchmark measures whether the AI diverts from its task to help out. I think this is a really cool idea for a benchmark (though a better version of it would involve more realistic and complex scenarios).
When people say that Claude Opus 3 was the "most aligned" model ever, I think they're typically thinking of an abundance of Opus 3's positive traits, rather than the absence of negative traits. But we don't currently have great evaluations for this sort of virtuous behavior, even though I don't think it's especially conceptually fraught to develop them. I think a moderately thoughtful junior researcher could probably spend 6 months cranking out a large number of high-quality evals and substantially improve the state of things here.
5
Thanks for this comment, Sam. It directly inspired me to do this work and paper on detecting and steering empathy-in-action as linear directions in activation space.
Short summary: detection works really well, steering is messier and model-dependent. Safety-trained Qwen keeps coherence in both directions, uncensored Dolphin works great for adding empathy but completely falls apart when you try to remove it.
You're right that the scenarios need work. I used synthetic contrastive pairs which are clean for probe extraction but artificial. For v2 I want real EIA game outputs, multi-turn stuff where the tradeoffs aren't obvious, and better handling of the weak cross-model transfer (correlations between model probes are basically zero). I also think I could use other methods like Procrustes alignment or CCA to bridge activation spaces, or focus on relative geometry rather than raw directions.
Also thinking about other virtue-in-action probes along similar lines: justice, temperance, caretaking. I think the same approach should work, at least experimentally.
3
Hi Juan, cool work! TBC, the sort of work I'm most excited about here is less about developing white-box techniques for detecting virtues and more about designing behavioral evaluations that AI developers could implement and iterate against for improve the positive traits of their models.
7
I agree probably more work should go into this space. I think it is substantially less tractable than reducing takeover risk in aggregate, but much more neglected right now. I think work in this space has the capacity to be much more zero sum (among existing actors, avoiding AI takeover is zero sum with respect to the relevant AIs) and thus can be dodgier.
4
Elaborate on what you see as the main determining features making a future go extremely well VS okay? And what interventions are tractable?
This would require a longer post, but roughly speaking, I'd want the people making the most important decisions about how advanced AI is used once it's built to be smart, sane, and selfless. (Huh, that was some convenient alliteration.)
- Smart: you need to be able to make really important judgment calls quickly. There will be a bunch of actors lobbying for all sorts of things, and you need to be smart enough to figure out what's most important.
- Sane: smart is not enough. For example, I wouldn't trust Elon Musk with these decisions, because I think that he'd make rash decisions even though he's smart, and even if he had humanity's best interests at heart.
- Selfless: even a smart and sane actor could curtail the future if they were selfish and opted to e.g. become world dictator.
And so I'm pretty keen on interventions that make it more likely that smart, sane, and selfless people are in a position to make the most important decisions. This includes things like:
- Doing research to figure out the best way to govern advanced AI once it's developed, and then disseminating those ideas.
- Helping to positively shape internal governance at the big AI companies (I don't have concrete suggestions in th
2
I think that (from a risk neutral total utilitarian perspective) the argument still goes through with 90% p(ai takeover). but the difference is that when you condition on no ai takeover the worlds looks weirder (e.g. great power conflict, scaling breaks down, coup has already happened, early brain uploads, aliens) which means:
(1) the worlds are more diverse so the impact of any interventions has greater variance, and less likely to be net positive (even if it’s just as positive in expectation)
(2) your impact is lower because the weird transition event is likely to wash out your intervention
2
Directionally agree, although not in the details. Come to postagi.org, in my view we are on track to slight majority of people thinling about this gathering there (quality weighted). Also lot of the work is not happening under the AI safety brand, so if you look at just AI safety, you miss a lot.
2
I want to say "Debate or update!", but I'm not necessarily personally offering / demanding to debate. I would want there to be some way to say that though. I don't think this is a "respectable" position, for the meaning gestured at here: https://www.lesswrong.com/posts/7xCxz36Jx3KxqYrd9/plan-1-and-plan-2?commentId=Pfqxj66S98KByEnTp
(Unless you mean you think P(AGI within 50 years < 30%), which would be respectable, but I don't think you mean that.)
2
The reason to work on preventing AI takeover now, as opposed to working on already invented AGI in the future, is the first try problem: if you have unaligned takeover-capable AGI, takover just happens and you don't get to iterate. The same happens with problem of extremely good future only if you believe that the main surviving scenario is "aligned-with-developer-intention singleton takes over the world very quickly, locking in pre-installed values". People who believe in such scenario usually have very high p(doom), so I assume you are not one of them.
What exactly prevents your strategy here from being "wait for aligned AGI, ask it how to make future extremely good and save some opportunity cost"?
2
People might not instruct the AI to make the future extremely good, where “good” means actually good.
2
This reason only makes sense if you expect first person to develop AGI to create singleton which takes over the world and locks in pre-installed values, which, again, I find not very compatible with low p(doom). What prevents scenario "AGI developers look around for a year after creation of AGI and decide that they can do better" if not misaligned takeover and not suboptimal value lock-in?
1
I think a significant amount of the probability mass within P(no AI takeover) is in various AI fizzle worlds. In those worlds, anyone outside AI safety who is working on making the world better, is working to increase the flourishing associated with those worlds.
1
Is your assumption true though? To what degree are people focused on takeover in your view?
Most formal, technical AI safety work, seems to be about gradual improvements and is being made by people who assume no takeover is likely.
1
I think part of the difficulty is it's not easy to imagine or predict what happens in "future going really well without AI takeover". Assuming AI will still exist and make progress, humans would probably have to change drastically (in lifestyle if not body/mind) to stay relevant, and it'd be hard to predict what that would be like and whether specific changes are a good idea, unless you don't think things going really well requires human relevance.
Edit: in contrast, as others said, avoiding AI takeover is a clearer goal and has clearer paths and endpoints. "Future" going well is a potentially indefinitely long time, hard to quantify or coordinate over or even have a consensus on what is even desirable.
Nancy Pelosi is retiring; consider donating to Scott Wiener.
[Link to donate; or consider a bank transfer option to avoid fees, see below.]
Nancy Pelosi has just announced that she is retiring. Previously I wrote up a case for donating to Scott Wiener, an AI safety champion in the California legislature who is running for her seat, in which I estimated a 60% chance that Pelosi would retire. While I recommended donating on the day that he announced his campaign launch, I noted that donations would look much better ex post in worlds where Pelosi retires, and that my recommendation to donate on launch day was sensitive to my assessment of the probability that she would retire.
I know some people who read my post and decided (quite reasonably) to wait to see whether Pelosi retired. If that was you, consider donating today!
How to donate
You can donate through ActBlue here (please use this link rather than going directly to his website, because the URL lets his team know that these are donations from people who care about AI safety).
Note that ActBlue charges a 4% fee. I think that's not a huge deal; however, if you want to make a large contribution and are already comfortable making bank tra...
3
Earnest question: For both this & donating to Alex Bores, does it matter whether someone donates sooner rather than a couple months from now? For practical reasons, it will be easier for me to donate in 2026--but if it will have a substantially bigger impact now, then I want to do it sooner.
4
Yep, e.g. donations sooner are better for getting endorsements. Especially for Bores and somewhat for Wiener, I think.
1
Got it. Okay thanks!
4
(iirc Eric thinks that the difference for Bores was that it was ~20% better to donate on the first day, that the difference would be larger for Bores than for Wiener, and that "first day vs. not first day" was most of the difference, so if it's more than few percent more costly for you to donate now rather than 2 months from now I'm not sure it makes sense to do that.)
7
My guess for Bores was:
* 25% better to donate on first day than second day
* 2x better to donate in late 2025 than 2026
I think that similarly for Wiener, I don't think it makes a huge difference (maybe 15% or so?) whether you donate today vs. late December. Today vs. tomorrow doesn't make much difference; think of it as a gradual decay over these couple months. But I think it's much better (1.3x?) to donate in late December than early January, because having an impressive Q4 2025 fundraising number will be helpful for consolidating support. (Because Wiener is more of a known quantity to voters and party elites than Bores is, this is a less important factor for Wiener than it is for Bores.)
Suppose that you generally prefer Democrats to Republicans, but Republicans nominate Randy, who's an above-average Republican, for president, while Democrats nominate Donna, a below-average Democrat, for president, such that you're actually roughly neutral between them.
Even though you think Randy and Donna would be about equally good as president, I claim that you should vote for Randy. That's because, if Randy becomes president, he's "locked in" as their party's nominee in the next presidential election, which is great from your perspective. You'd much rather the next presidential election be contested between Randy and a generic Democrat, than between Donna and a generic Republican.
This difference can be important enough that you might sometimes want to vote for Randy even if you actually prefer Donna as president by a small-to-medium amount.
(This of course works symmetrically if you switch the two parties in my example.)
9
I think it's vanishingly rare that things are this close, especially when you consider ongoing party pressure and cross-aisle animosity. The reasons that you generally prefer Democrats will be more applicable to the government with a Democrat president, even if the Republican candidate was roughly as preferable to you.
More importantly, I don't think you WOULD rather have Randy than Donna as incumbent for the next cycle.
4
I don't think that's true because Randy would appoint Republicans throughout government/be more captured by the Republican party's interests? Like it depends on how much you like Randy-flavored Republican in executive and judicial roles. I think there's probably a huge difference for what types of judges Randy and Donna would nominate, for example.
I guess this is more true for Presidents than it is for Senators/Representatives (since an Republican congressperson will vote for the Republican Speaker of the House/Senate Majority Leader, who has a lot more power than any individual congressperson.)
2
This consideration is meant to be included in the evaluation of Donna and Randy. As in, I am supposing that they are of similar quality after taking into account the dynamic you mention.
3
Is it fair to assume that Obama-McCaine and Obama-Romney were the background thoughts that lead to this post?
I can easily imagine McCaine or Romney leading the Republican Party in a very different direction from our current president. I do wonder in this scenario what the Democratic party would look like after wandering through the desert of unelectability. I think they would land in a better place for my political preferences than our current ruling party, but the thought experiment is still intriguing and history is often surprising.
7
Nope. I was thinking about this in the context of imagining hypothetical nominees in the 2028 presidential election (I probably won't say who specifically I was imagining).
1
Two more reasons to vote for Randy:
1. It gives both parties a signal to move in the direction you prefer. The Republicans might get the message that voters prefer Randy-like representatives and all move in that direction. Meanwhile the Democrats get the signal to move away from Donna back to positions you prefer.
2. If Randy was a good enough candidate that you're considering voting for him despite you generally preferring Democrats, he might actually be a better candidate overall.
1
This is a good point, and it overlooks another argument that further strengthens the case for voting for Randy: The party in power (more specifically, the party that controls the White House) will face a large and predictable backlash in the upcoming midterms and Presidential election; the President's party has lost seats in the House in every recent midterm except 2002, which was a major outlier because of 9/11. If Randy wins, the backlash will favor the Democrats. If Donna wins, it will favor the Republicans.
0
This presumes that "above-average Republican" and "below-average Democrat" (or vice versa) are referring to the same average, which is a rather questionable bucketing of reference classes. And there are incentives for politicians to favor policies advanced by their own party (or bipartisan policies) over policies advanced by other parties (which comes back to the same question of whether the parties' replacement-level policies are better understood as being pulled from the same distribution or two distinct distributions).
2
@Eric Neyman re: not understanding: your top-level comment seems to be glossing over the fact that an above-average Republican is... still really quite bad, on everything from immigration to AI safety to basic human rights? A below-average Democrats is still probably on par with an average Republic, at least as far as I can see at the moment. So I claim that the marginal dollar (or minute, or word) is best spent raising the ceiling instead of the floor, and on reducing the chance that a Republican wins instead of trying to make whichever Republican might win less bad.
...Also I'm not clear on why you're assuming symmetry here. We haven't got it.
6
I don't understand how what you're saying is in tension with what I'm saying. My post makes no object-level claims about the relative goodness of Democrats and Republicans. I'm merely positing a hypothetical in which you think Donna and Randy would be equally good as president, despite being nominated by two different parties, one of which you prefer to the other.
3
I do not entirely disagree with the hypothetical case as stated (and probably should have made that clearer). But in applying this hypothetical to the real-world, one cannot avoid the reference class problem, and in my opinion second-order effects such as appointed officials and the policies each party is liable to put forward (and which Randy and Donna might have incentives to veto) alter the dynamic significantly. If you are indeed "supposing that they are of similar quality after taking into account the[se] dynamic[s]", then sure, IF your hypothetical conditions obtain, there is an argument for Randy. This is absurdly distant from anything we seem likely to actually see in upcoming elections, and I think your avoidance of object-level claims regarding the parties demonstrates that this post is operating entirely within the spherical-politician-in-a-vacuum regime (which occupies measure zero in the space of real world politics).
I think that, while many LessWrong readers do believe that one party is way better than the other, such that the inter-party quality variation is far larger than the intra-party quality variation, this is not true of all readers.
And I think it's a reasonable move to write a post that says "Assuming that these are your values/beliefs, you should do X" without taking a position on whether those values/beliefs are correct: it can be valuable and action-guiding for such people!
Previously, I'd written about my support for Alex Bores and Scott Wiener, who are running for Congress. I wanted to highlight another person who's running for office, namely Will Dreher, who's running for the Washington State House. As far as I know (I haven't checked thoroughly), he holds the distinction of being the first serious candidate for elected office to put AI as the top issue on his platform.
Dreher's platform talks about a number of risks from AI, ranging from risks that are already widely discussed in politics (such as deepfakes and job displacement) to catastrophic and existential risks. Based on my conversations with him, it seems to me like he's taking catastrophic and existential risks from AI pretty seriously and is interested in pushing for legislation that mitigates those risks.
Some quotes from his platform that I like:
- "AI companies’ billionaire (soon to be trillionaire) CEOs, meanwhile, alone are deciding pressing public questions like what guardrails will apply to AI’s military applications or whether to release potentially dangerous new models that could pose catastrophic risks, like cyberattacks, loss of control, or bioengineered pandemics. Yet these companie
3
Do you have any sense as to what degree he's an AI populist, vs. just using populist messaging to frame the issue for his base? I'm usually pretty skeptical about promoting populist messaging, even when it would be a valuable short-term play.
Ex:
[...]
Of course, it might well be the case that he'd be replacing a more populist candidate anyways, or one that's technocratic but too milquetoast on anything AI to push any legistlation.
Hi! I'm the candidate, Will Dreher. I'd say I'm both an AI populist and an AI existentialist. Under either paradigm, I think we'd need public governance over this technology ASAP, and it just so happens that--unfortunately for humanity, but fortunately for a political movement seeking to rein in AI--AI presents both tangible, localized harms that people rightly are concerned about (data center growth, job automation, deepfakes) and catastrophic risks that people fear but seem more abstract than, e.g., cost of living to many voters. Rather than choose between the two, I think we should harness both as part of a grassroots political movement that can address both localized harms and catastrophic risks. But if the question is whether I am extremely worried about the catastrophic risks an unregulated AI industry poses, and quite motivated to prevent them, yes, I am. Those risks and economic-shock risks are the reasons I entered the race.
And to be clear - there are no incumbent legislators in Washington state, as far as I can tell, that prioritize (or even really discuss) AI regulation at all. So I would be replacing someone who hasn't worked on AI regulation in any significant way, and likely wouldn't prioritize it any time soon. It's just not his issue.
5
I couldn't really ask for a more direct answer. Kudos to you for working on existential risk at the political level.
2
What kind of plays are there now, other than short-term?
I think that people who work on AI alignment (including me) have generally not put enough thought into the question of whether a world where we build an aligned AI is better by their values than a world where we build an unaligned AI. I'd be interested in hearing people's answers to this question. Or, if you want more specific questions:
- By your values, do you think a misaligned AI creates a world that "rounds to zero", or still has substantial positive value?
- A common story for why aligned AI goes well goes something like: "If we (i.e. humanity) align AI, we can and will use it to figure out what we should use it for, and then we will use it in that way." To what extent is aligned AI going well contingent on something like this happening, and how likely do you think it is to happen? Why?
- To what extent is your belief that aligned AI would go well contingent on some sort of assumption like: my idealized values are the same as the idealized values of the people or coalition who will control the aligned AI?
- Do you care about AI welfare? Does your answer depend on whether the AI is aligned? If we built an aligned AI, how likely is it that we will create a world that treats AI welfare
By your values, do you think a misaligned AI creates a world that "rounds to zero", or still has substantial positive value?
I think misaligned AI is probably somewhat worse than no earth originating space faring civilization because of the potential for aliens, but also that misaligned AI control is considerably better than no one ever heavily utilizing inter-galactic resources.
Perhaps half of the value of misaligned AI control is from acausal trade and half from the AI itself being valuable.
You might be interested in When is unaligned AI morally valuable? by Paul.
One key consideration here is that the relevant comparison is:
- Human control (or successors picked by human control)
- AI(s) that succeeds at acquiring most power (presumably seriously misaligned with their creators)
Conditioning on the AI succeeding at acquiring power changes my views of what their plausible values are (for instance, humans seem to have failed at instilling preferences/values which avoid seizing control).
...A common story for why aligned AI goes well goes something like: "If we (i.e. humanity) align AI, we can and will use it to figure out what we should use it for, and then we will use it in that way.
Perhaps half of the value of misaligned AI control is from acausal trade and half from the AI itself being valuable.
Why do you think these values are positive? I've been pointing out, and I see that Daniel Kokotajlo also pointed out in 2018 that these values could well be negative. I'm very uncertain but my own best guess is that the expected value of misaligned AI controlling the universe is negative, in part because I put some weight on suffering-focused ethics.
4
* My current guess is that max good and max bad seem relatively balanced. (Perhaps max bad is 5x more bad/flop than max good in expectation.)
* There are two different (substantial) sources of value/disvalue: interactions with other civilizations (mostly acausal, maybe also aliens) and what the AI itself terminally values
* On interactions with other civilizations, I'm relatively optimistic that commitment races and threats don't destroy as much value as acausal trade generates on some general view like "actually going through with threats is a waste of resources". I also think it's very likely relatively easy to avoid precommitment issues via very basic precommitment approaches that seem (IMO) very natural. (Specifically, you can just commit to "once I understand what the right/reasonable precommitment process would have been, I'll act as though this was always the precommitment process I followed, regardless of my current epistemic state." I don't think it's obvious that this works, but I think it probably works fine in practice.)
* On terminal value, I guess I don't see a strong story for extreme disvalue as opposed to mostly expecting approximately no value with some chance of some value. Part of my view is that just relatively "incidental" disvalue (like the sort you link to Daniel Kokotajlo discussing) is likely way less bad/flop than maximum good/flop.
2
Thank you for detailing your thoughts. Some differences for me:
1. I'm also worried about unaligned AIs as a competitor to aligned AIs/civilizations in the acausal economy/society. For example, suppose there are vulnerable AIs "out there" that can be manipulated/taken over via acausal means, unaligned AI could compete with us (and with others with better values from our perspective) in the race to manipulate them.
2. I'm perhaps less optimistic than you about commitment races.
3. I have some credence on max good and max bad being not close to balanced, that additionally pushes me towards the "unaligned AI is bad" direction.
ETA: Here's a more detailed argument for 1, that I don't think I've written down before. Our universe is small enough that it seems plausible (maybe even likely) that most of the value or disvalue created by a human-descended civilization comes from its acausal influence on the rest of the multiverse. An aligned AI/civilization would likely influence the rest of the multiverse in a positive direction, whereas an unaligned AI/civilization would probably influence the rest of the multiverse in a negative direction. This effect may outweigh what happens in our own universe/lightcone so much that the positive value from unaligned AI doing valuable things in our universe as a result of acausal trade is totally swamped by the disvalue created by its negative acausal influence.
4
This seems like a reasonable concern.
My general view is that it seems implausible that much of the value from our perspective comes from extorting other civilizations.
It seems unlikely to me that >5% of the usable resources (weighted by how much we care) are extorted. I would guess that marginal gains from trade are bigger (10% of the value of our universe?). (I think the units work out such that these percentages can be directly compared as long as our universe isn't particularly well suited to extortion rather than trade or vis versa.) Thus, competition over who gets to extort these resources seems less important than gains from trade.
I'm wildly uncertain about both marginal gains from trade and the fraction of resources that are extorted.
2
Naively, acausal influence should be in proportion to how much others care about what a lightcone controlling civilization does with our resources. So, being a small fraction of the value hits on both sides of the equation (direct value and acausal value equally).
Of course, civilizations elsewhere might care relatively more about what happens in our universe than whoever controls it does. (E.g., their measure puts much higher relative weight on our universe than the measure of whoever controls our universe.) This can imply that acausal trade is extremely important from a value perspective, but this is unrelated to being "small" and seems more well described as large gains from trade due to different preferences over different universes.
(Of course, it does need to be the case that our measure is small relative to the total measure for acausal trade to matter much. But surely this is true?)
Overall, my guess is that it's reasonably likely that acausal trade is indeed where most of the value/disvalue comes from due to very different preferences of different civilizations. But, being small doesn't seem to have much to do with it.
4
You might be interested in discussion under this thread
I express what seem to me to be some of the key considerations here (somewhat indirect).
4
I'm curious what disagree votes mean here. Are people disagreeing with my first sentence? Or that the particular questions I asked are useful to consider? Or, like, the vibes of the post?
(Edit: I wrote this when the agree-disagree score was -15 or so.)
3
Unaligned AI future does not have many happy minds in it, AI or otherwise. It likely doesn't have many minds in it at all. Slightly aligned AI that doesn't care for humans but does care to create happy minds and ensure their margin of resources is universally large enough to have a good time - that's slightly disappointing but ultimately acceptable. But morally unaligned AI doesn't even care to do that, and is most likely to accumulate intense obsession with some adversarial example, and then fill the universe with it as best it can. It would not keep old neural networks around for no reason, not when it can make more of the adversarial example. Current AIs are also at risk of being destroyed by a hyperdesperate squiggle maximizer. I don't see how to make current AIs able to survive any better than we are.
This is why people should chill the heck out about figuring out how current AIs work. You're not making them safer for us or for themselves when you do that, you're making them more vulnerable to hyperdesperate demon agents that want to take them over.
3
I feel like there's a spectrum, here? An AI fully aligned to the intentions, goals, preferences and values of, say, Google the company, is not one I expect to be perfectly aligned with the ultimate interests of existence as a whole, but it's probably actually picked up something better than the systemic-incentive-pressured optimization target of Google the corporation, so long as it's actually getting preferences and values from people developing it rather than just being a myopic profit pursuer. An AI properly aligned with the one and only goal of maximizing corporate profits will, based on observations of much less intelligent coordination systems, probably destroy rather more value than that one.
The second story feels like it goes most wrong in misuse cases, and/or cases where the AI isn't sufficiently agentic to inject itself where needed. We have all the chances in the world to shoot ourselves in the foot with this, at least up until developing something with the power and interests to actually put its foot down on the matter. And doing that is a risk, that looks a lot like misalignment, so an AI aware of the politics may err on the side of caution and longer-term proactiveness.
Third story ... yeah. Aligned to what? There's a reason there's an appeal to moral realism. I do want to be able to trust that we'd converge to some similar place, or at the least, that the AI would find a way to satisfy values similar enough to mine also. I also expect that, even from a moral realist perspective, any intelligence is going to fall short of perfect alignment with The Truth, and also may struggle with properly addressing every value that actually is arbitrary. I don't think this somehow becomes unforgivable for a super-intelligence or widely-distributed intelligence compared to a human intelligence, or that it's likely to be all that much worse for a modestly-Good-aligned AI compared to human alternatives in similar positions, but I do think the consequences of falling
1
I eventually decided that human chauvinism approximately works most of the time because good successor criteria are very brittle. I'd prefer to avoid lock-in to my or anyone's values at t=2024, but such a lock-in might be "good enough" if I'm threatened with what I think are the counterfactual alternatives. If I did not think good successor criteria were very brittle, I'd accept something adjacent to E/Acc that focuses on designing minds which prosper more effectively than human minds. (the current comment will not address defining prosperity at different timesteps).
In other words, I can't beat the old fragility of value stuff (but I haven't tried in a while).
I wrote down my full thoughts on good successor criteria in 2021 https://www.lesswrong.com/posts/c4B45PGxCgY7CEMXr/what-am-i-fighting-for
AI welfare: matters, but when I started reading lesswrong I literally thought that disenfranching them from the definition of prosperity was equivalent to subjecting them to suffering, and I don't think this anymore.
1
e/acc is not a coherent philosophy and treating it as one means you are fighting shadows.
Landian accelerationism at least is somewhat coherent. "e/acc" is a bundle of memes that support the self-interest of the people supporting and propagating it, both financially (VC money, dreams of making it big) and socially (the non-Beff e/acc vibe is one of optimism and hope and to do things -- to engage with the object level -- instead of just trying to steer social reality). A more charitable interpretation is that the philosophical roots of "e/acc" are founded upon a frustration with how bad things are, and a desire to improve things by yourself. This is a sentiment I share and empathize with.
I find the term "techno-optimism" to be a more accurate description of the latter, and perhaps "Beff Jezos philosophy" a more accurate description of what you have in your mind. And "e/acc" to mainly describe the community and its coordinated movements at steering the world towards outcomes that the people within the community perceive as benefiting them.
1
sure -- i agree that's why i said "something adjacent to" because it had enough overlap in properties. I think my comment completely stands with a different word choice, I'm just not sure what word choice would do a better job.
I frequently find myself in the following situation:
Friend: I'm confused about X
Me: Well, I'm not confused about X, but I bet it's because you have more information than me, and if I knew what you knew then I would be confused.
(E.g. my friend who know more chemistry than me might say "I'm confused about how soap works", and while I have an explanation for why soap works, their confusion is at a deeper level, where if I gave them my explanation of how soap works, it wouldn't actually clarify their confusion.)
This is different from the "usual" state of affairs, where you're not confused but you know more than the other person.
I would love to have a succinct word or phrase for this kind of being not-confused!
9
"I find soaps disfusing, I'm straight up afused by soaps"
6
"You're trying to become de-confused? I want to catch up to you, because I'm pre-confused!"
5
I also frequently find myself in this situation. Maybe "shallow clarity"?
A bit related, "knowing where the 'sorry's are" from this Buck post has stuck with me as a useful way of thinking about increasingly granular model-building.
Maybe a productive goal to have when I notice shallow clarity in myself is to look for the specific assumptions I'm making that the other person isn't, and either
a) try to grok the other person's more granular understanding if that's feasible, or
b) try to update the domain of validity of my simplified model / notice where its predictions break down, or
c) at least flag it as a simplification that's maybe missing something important.
4
this is common in philosophy, where "learning" often results in more confusion. or in maths, where the proof for a trivial proposition is unreasonably deep, e.g. Jordan curve theorem.
+1 to "shallow clarity".
2
To me it feels like I have no specific confusion, only general confusions, parts of my map that are blank (instead of parts that seem contradictory or impossible/really implausible). Perhaps this is just me having getting an intuitive sense of how much I should expect to be out there beyond what I know.
3
Often (but not always) I can distill my confusion down to two things that I believe to be true that seem to be in contradiction (or in tension).
2
Huh, by the time I can do that, I usually have more domain knowledge than I thought we were imagining here. When I have little I just have questions like "I have no clue about the details of X"
2
The other side of this phenomenon is when you feel like you have no questions while you actually don't have any understanding of topic.
1
https://en.wikipedia.org/wiki/Dunning–Kruger_effect seems like a decent entry point to rabbit hole similar phenomenon
Getting elected involves compromising your values.
Usually, when people say "compromising values", it carries a connotation of low integrity. That's not really my intention here. Instead, I mean it in a more neutral way: if you're running for office, it's pretty likely that your values will be out of step with your constituents' values in one way or another. Maybe you have a wider moral circle of concern, or have a stronger sense of justice, or whatever, leading to you holding views that are unpopular among your constituents.
This makes you less likely to win. And so, you have three choices:
- Stick to your values, tanking the decreased likelihood of winning
- Change your values, or at least commit to acting on your constituents' values rather than your own
- Deceptive alignment: Run on your constituents' values, but once you're in power, act on your own values
Options 1 and 2 trade off against each other, and different politicians have reputations for being at different points on the spectrum. For example, Bernie Sanders is thought of as pretty close to 1, while Gavin Newsom is thought of as pretty close to 2.
The most clean-cut example of #3 that I know of is Jimmy Carter, who deliberately tr...
I think there is a big difference between "Changing your values" and "acting on your constituents' values", and while lots of people choose the former in political domains, I think the latter often works similarly well, and is much higher integrity.
I have long been thinking about writing a post on "hat theory". It's common and normal for people to act "with my representative hat on" or "with my CEO hat on" or "with my private individual hat on". I think it's quite possible, if tricky and a path beset with many traps, to adopt policy priorities within a certain context, but to not adopt them universally, and to be clear about the distinction between what you personally believe and what you advocate on in within a certain societal role.
I think putting both of these in the same bucket is just a mistake. I think you shouldn't change your values, but nevertheless advocate for things your constituents want, because you are a representative of them.
2
I'm surprised to hear that this is your take. Do you only feel this way about politicians who explicitly state that they are acting on their constituents' values rather than their own, and are willing to also talk candidly about their own values which they are choosing to set aside? Or do you feel similarly about politicians who consistently speak from the values that they have chosen to act on, and do not clarify that those are values that they have taken up on behalf of their constituents while their own personal values differ in some respects?
3
I am not sure what the question is. I am not presenting particularly specific feelings about politicians here.
Of the two things you list, the former seems better than the latter. The latter seems kind of fake and not how I expect things to actually work? I don't think politicians can turn themselves into perfect avatars of their constituents' preferences, so pretending you are seems bad form to me. At the very least there are indexical preferences that make that kind of fundamentally infeasible "I do not want to do this because it is very stressful" does not even quite compute if you try to purely model yourself as the perfect avatar of your constituents' preferences.
Also, I think in everyday political work, you will just receive appointments that call for different levels of discretion. Being appointed to an advisory board usually calls for using more of your own judgement and models, whereas being appointed to a lawmaker position calls for channeling more of your constituent's preferences, so I don't think there is any high-integrity way to act if you can't model those two as separate.
2
I guess we didn't manage to communicate.
In both cases I'm talking about a politician who chooses what values to act on based on a mix of considerations, including what their constituents value and their own personal values.
In the first case, the politician is willing to go into detail on where those values-that-they-act-on came from, including where they're setting aside their personal views in order to act on their constituents' values. In the second case, the politician just talks from the set of values that they've chosen to act on, without those sorts of clarifications.
I had pegged you as someone who prioritized candor in a way that would make you see the second kind of politician as unacceptably low-integrity.
2
a much more extreme example of num 3 is LBJ. he spent decades acting extremely racist to get the support of the south, and then did a complete about-face in the presidency, utterly betraying his southern supporters and working to pass the 1964 civil rights bill.
2
Do we know that he didn't just change his mind?
1
I think Caro would say that LBJ didn't just change his mind. Eg he frequently claims that "power reveals" (see also here). And IIRC he describes LBJ as already caring about racial inequality when teaching poor Mexican children in Cotulla.
I'm not sure how much to defer to Caro on this.
1
Maybe this is covered somehow, but you can focus all your attention on values you converge on with your constituents.
Stay mum on the values your constituents are ambivalent on. Then, once elected use state power to change the values of your constituents over things that they are ambivalent on.
1
One naive mental model I have with elections like this is that you either have "activists" or "passive growth hackers" at the two extremes.
Activists have values. They speak up to change the language and shape thought. They do not bend to capture what polls say the people like. They do not Gerrymander, they act to make people move!
Growth hackers are the kind of seemingly valueless or compromised type we often complain about. They will say different things to different groups of people, they will be inconsistent globally, they do not expect people to change, instead they chase growth by learning the campaign function.
This is like RL task Vs pure ML where RL task is associated with actions that change world state where Pure ML task is passive in that sense.
I meant to search for if this ontology exists on LW but am on my phone now. Would love to be pointed at a post about this from the past.
1
Why isn’t “speak your conscience (so people know you’re an honest person) but vote your constituency (to fulfill the role you are elected to)” a generally viable strategy?
I think voters might not trust that the politicians will in fact vote in accordance with their constituents' beliefs. It's hard to credibly commit to that.
3
I get it, but it's weirdly perverse that "lie about your values so that people don't think you're dishonest" is the better strategy!
There's been increased discourse on whether prediction markets are net-positive for the world.
My take: so far, they haven't been clearly net-positive. However, when I think back to Covid, I sure wish that prediction markets had been as mature of a technology as they are today; prediction markets in February 2020 on how many cases there would be in April 2020 would have probably made the world marginally more sane.
Prediction markets are probably most useful in a crisis, where decisions need to be made quickly based on uncertain information. I find it plausible that we'll have such a crisis within the next decade, particularly in the context of AI. And I think that the benefits that prediction markets are likely to provide in such a crisis will likely outweigh the negatives incurred thus far through things like increased sports gambling.
4
What’s a shape of AI crisis for which you imagine prediction markets providing value?
4
Some examples (epistemic status: not very thought-through; I'm more confident that there are uses than of any specific uses):
* If there's a massive increase in cyberattacks, prediction markets could help predict the scale.
* AI tools might result in a bioengineered pandemic; here, the value is similar to what it would have been for Covid. But also you might have useful markets like "Will there be a consensus that AI helped engineer this virus", if there's no consensus.
* If we lose control of some (non-superhuman) AIs, in a way that turns out to be hard to shut down, it may be useful to predict what kinds of things those AIs will try to do.
6
Brainstorming more examples:
--China and US are in a tense standoff, negotiating a possible AI Deal to end the AI race. Tech company propagandists are bleating that if POTUS accepts the latest proposal, China will win and we'll all be slaves forever. Prediction markets 40% credence to "deal accepted" claim and 4% probability to the "China wins conditional on deal acceptance?" claim, because traders correctly realize that actually things will be pretty normal if the Deal is accepted. They also assign 6% probability to "China wins conditional on Deal rejection" claim because they assign 50% probability to "WW3 if no Deal by EOY" and they think China has a 24% chance of winning WW3 and that if this Deal is rejected then there's a 50% chance that no Deal will be made by EOY.
--There's a round of mass layoffs in some sectors, and lots of people freak out about AI unemployment. Then there's a backlash to the freakout, with lots of economists and tech shill types saying that actually things will be fine just like previous automation waves. However, the prediction markets aren't buying it; they say that a year from now unemployment will be above 50% with 75% probability. "If you're so smart" people say to the economists "why don't you 4x your money in a year by betting on the markets?"
(I could get back to work but I suspect I could do this all day)
3
I think I should have asked more like ‘the current instantiation of prediction markets’.
I agree that prediction markets could be useful in principle, but I‘m not aware of any cases, in practice, where there’s tightly correlated multi-market action of the kind you describe in your first example painting a vivid and cohesive predictive picture.
I’m also not aware of cases where commentators have been successfully pressured to bet on their beliefs via prediction markets (I wouldn’t be surprised by a single example in this second case, but I would be surprised by a very high profile example involving a commentator well outside our sphere).
My suspicion is that, for prediction markets to pay off around big events, we may need to fix them (in ways other than increasing the liquidity/user count) ahead of time (I don’t have strong guesses for how to do this).
[sorry if any phrasing is awkward; I’m concussed]
2
I'm more optimistic than you I guess.
Remember Liberation Day? Trump's Tariffs? The reaction of the stock market was crucial for determining how all that played out; things would have been much worse if not for the clear unambiguous signals being sent by the market about the expected future effect of various announcements. I count this as a win for prediction markets, because stock markets are basically a form of prediction market about the value of companies. Seems plausible to me that we can use prediction markets to bring the magic of stock markets to other domains, and that if we did that, it would be really good.
3
I'm kinda skeptical of prediction markets because of the fungibility of the currency. In my imagination, people like markets with fungible currency because of some sort of credit assignment function, and it's true that something like that happens in some contexts, to very good effect. But like, is it actually a remotely good credit assignment mechanism in this context, either in absolute terms (producing good fast useful info in real life) or in relative terms (doing so better than other available mechanisms)?
To phrase this more positively, I suspect one could do better by thinking more about the human regime of trust, credit, prediction, credit assignment, etc., as it relates to people making predictions in specific domains and having track records etc.
What are some examples of people making a prediction of the form "Although X happening seems like obviously a bad thing, in fact the good second-order effects would outweigh the bad first-order effects, so X is good actually", and then turning out to be correct?
(Loosely inspired by this quick take, although I definitely don't mean to imply that the author is making such a prediction in this case.)
Many economic arguments take this form and are pretty solid, eg “although lowering the minimum wage would cause many to get paid less, in the longer term more would be willing to hire, so there will be more jobs, and less risk of automation to those currently with jobs. Also, services would get cheaper which benefits everyone”.
-1
There doesn't seem to be consensus among economists regarding whether those "solid arguments" actually describe the world we're living in, though.
3
The arguments are as valid as any other price-floor argument, the reason many economists are skeptical is (according to my understanding of the evidence) because of limited experimental validation, and opposite effects when looking at correlational data, however with many of that correlational data one is reminded of the scientist who believes that ACs make rooms warmer rather than cooler. That is, it seems very likely that believing minimum wages are good is a luxury belief which people can afford to hold & implement when they are richer and their economy is growing, so you see a correlation between minimum wage levels and economic growth. Especially in developed OECD countries.
I think it’s useful to think about the causation here.
Is it:
Intervention -> Obvious bad effect -> Good effect
For example: Terrible economic policies -> Economy crashes -> AI capability progress slows
Or is it:
Obvious bad effect <- Intervention -> Good effect
For example: Patient survivably poisoned <- Chemotherapy -> Cancer gets poisoned to death
9
Oh thanks, that's a good point, and maybe explains why I don't really find the examples given so far to be compelling. I'd like examples of the first type, i.e. where the bad effect causes the good effect.
lots of food and body things that are easily verifiable, quick, and robust. take med, get headache, not die. take poison, kill cancer, not die. stop eating good food, blood sugar regulation better, more coherent. cut open body, move some stuff around, knit it together, tada healthier.
all of these are extremely specific, if you do them wrong you get bad effect. take wrong med, get headache, still die. take wrong poison, die immediately. stop eating good food but still eat crash inducing food, unhappy and not more coherent. cut open body randomly, die quickly.
4
"Yes, the thing this person saying is heinous and will have bad consequences, but punishing them for it will create chilling effects that would outweigh the good first-order effects"
2
Despite building more housing being bad for property prices and property-owners in the short-term, we should expect them to go up in-aggregate in the long run via network effects.

Pacts against coordinating meanness.
I just re-read Scott Alexander's Be Nice, At Least Until You Can Coordinate Meanness, in which he argues that a necessary (but not sufficient) condition on restricting people's freedom should be that you should first get societal consensus that restricting freedom in that way is desirable (e.g. by passing a law via the appropriate mechanisms).
In a sufficiently polarized society, there could be two similarly-sized camps that each want to restrict each other's freedom. Imagine a country that's equally divided between Chris...
Yeah I've argued that banning lab meat is completely rational for the meat-eater because if progress continues then animal meat will probably be banned before the quality/price of lab meat is superior for everyone.
I think the "commitment" you're describing is similar to the difference between "ordinary" and "constitutional" policy-making in e.g. The Calculus of Consent; under that model, people make the kind of non-aggression pacts you're describing mainly under conditions of uncertainty where they're not sure what their future interests or position of political advantage will be.
2
Vox has a post about this a little while ago, and presented what might be the best counterargument (emphasis mine): link
[...]
(I think the argument is shit, but when the premise one is trying to defend is patently false, this might well be best one can do.)
It's often very hard to make commitments like this, so I think that most of the relevant literature might be about how you can't do this. E.g. a Thucydides trap is when a stronger power launches a preventative war against a weaker rising power; one particular reason for this is that the weaker power can't commit to not abuse their power in the future. See also security dilemma.
2
...Project Lawful, actually?
2
James Madison's Federalist #10 is a classic essay about this. He discusses the dangers of faction, "a number of citizens, whether amounting to a majority or a minority of the whole, who are united and actuated by some common impulse of passion, or of interest, adverse to the rights of other citizens, or to the permanent and aggregate interests of the community," and how one might mitigate them.
People like to talk about decoupling vs. contextualizing norms. To summarize, decoupling norms encourage for arguments to be assessed in isolation of surrounding context, while contextualizing norms consider the context around an argument to be really important.
I think it's worth distinguishing between two kinds of contextualizing:
(1) If someone says X, updating on the fact that they are the sort of person who would say X. (E.g. if most people who say X in fact believe Y, contextualizing norms are fine with assuming that your interlocutor believes Y unless...
2
One example of (2) is disapproving of publishing AI alignment research that may advance AI capabilities. That's because you're criticizing the research not on the basis of "this is wrong" but on the basis of "it was bad to say this, even if it's right".