Edit - Neuronpedia has pivoted to be a research tool for Sparse Autoencoders, so most of this post is outdated. Please read the new post, Neuronpedia: Accelerating Sparse Autoencoders Research.
Neuronpedia is an AI safety game that documents and explains each neuron in modern AI models. It aims to be the Wikipedia for neurons, where the contributions come from users playing a game. Neuronpedia wants to connect the general public to AI safety, so it's designed to not require any technical knowledge to play.
Neuronpedia is in experimental beta: getting its first users in order to collect feedback, ideas, and build an initial community.
OBJECTIVES
- Increase understanding of AI to help build safer AI
- Increase public engagement, awareness, and education in AI safety
CURRENT STATUS
- I started working on Neuronpedia three weeks ago, and I'm posting on LessWrong to develop an initial community and for feedback and testing. I'm not posting it anywhere else, please do not share it yet in other forums like Reddit.
- There's an onboarding tutorial that explains the game, but to summarize: It's a word association game. You're shown one neuron ("puzzle") at a time, and its highest activations ("clues"). You then either vote for an existing explanation, or submit your own explanation. Neuronpedia's first "campaign" is explaining gpt2-small, layer 6.
- There is an "advanced mode" that allows testing custom activation text and shows more details/filters. Click "Simple" at the top right to toggle it.
WHAT YOU CAN DO
- Play @ neuronpedia.org - feel free to use a throwaway GitHub account to log in.
- Give feedback, ideas, and ask questions.
THE VISION
- Millions of casual and technical users play Neuronpedia daily, trying to solve each neuron (like NYT crossword/Wordle). There are weekly/monthly contests ("side quests"). Top scorers are ranked on leaderboards by country, region, etc.
- Neuronpedia sparks interest in AI safety for thousands of people and they contribute in other ways (switch fields, do research, etc).
- Researchers use the data to build safer and more predictable AI models. Companies post updated versions of their AI models (or parts of them) as new "campaigns" and iterate through increasingly safer models.
HOW NEURONPEDIA CAME ABOUT
After moving on from my previous startup, I reached out to 80,000 Hours for career advice. They connected me to William Saunders who provided informal (not affiliated with any company) guidance on what might be useful products to develop for AI safety research. Three weeks ago, I started prototyping versions of Neuronpedia, starting as a reference website, then eventually iterating into a game.
Neuronpedia is seeded with data and tools from OpenAI's Automated Interpretability and Neel Nanda's Neuroscope.
IS THIS SUSTAINABLE?
Unclear. There's no revenue model, and there is nobody supporting Neuronpedia. I'm working full time on it and spending my personal funds on hosting, inference servers, OpenAI API, etc. If you or your organization would like to support this project, please reach out at johnny@neuronpedia.org.
COUNTERARGUMENTS AGAINST NEURONPEDIA
These are reasons Neuronpedia could fail to achieve one or more of its objectives. They're not insurmountable, but good to keep in mind.
- Can't get enough people to care about AI safety or think it's a real problem.
- Neurons are the wrong "unit" for useful interpretability and Neuronpedia is unable to adapt to the correct "unit" (groups of neurons, etc).
- Even the best human explanations are not good.
- Scoring algorithm for explanation is bad and can't be improved.
- Not engaging enough - the game isn't balanced, doesn't have enough "loops", etc.
- Bugs.
- Lack of funds.
- AI companies shut it down via copyright claims, cease and desist, etc.
- Unable to contain abusive users or spam.
- Too slow to stop misaligned AI.

This is great! Really professionally made. I love the look and feel of the site. I'm very impressed you were able to make this in three weeks.
I think my biggest concern is (2): Neurons are the wrong unit for useful interpretability—or at least they can't be the only thing you're looking at for useful interpretability. My take is that we also need to know what's going on in the residual stream; if all you can see is what is activating neurons most, but not what they're reading from and writing to the residual stream, you won't be able to distinguish between two neurons that may be activating on similar-looking tokens but that are playing completely different roles in the network. Moreover, there will be many neurons where interpreting them is basically hopeless, because their role is to manipulate the residual stream in a way that's opaque if you have no way of understanding what's in the residual stream.
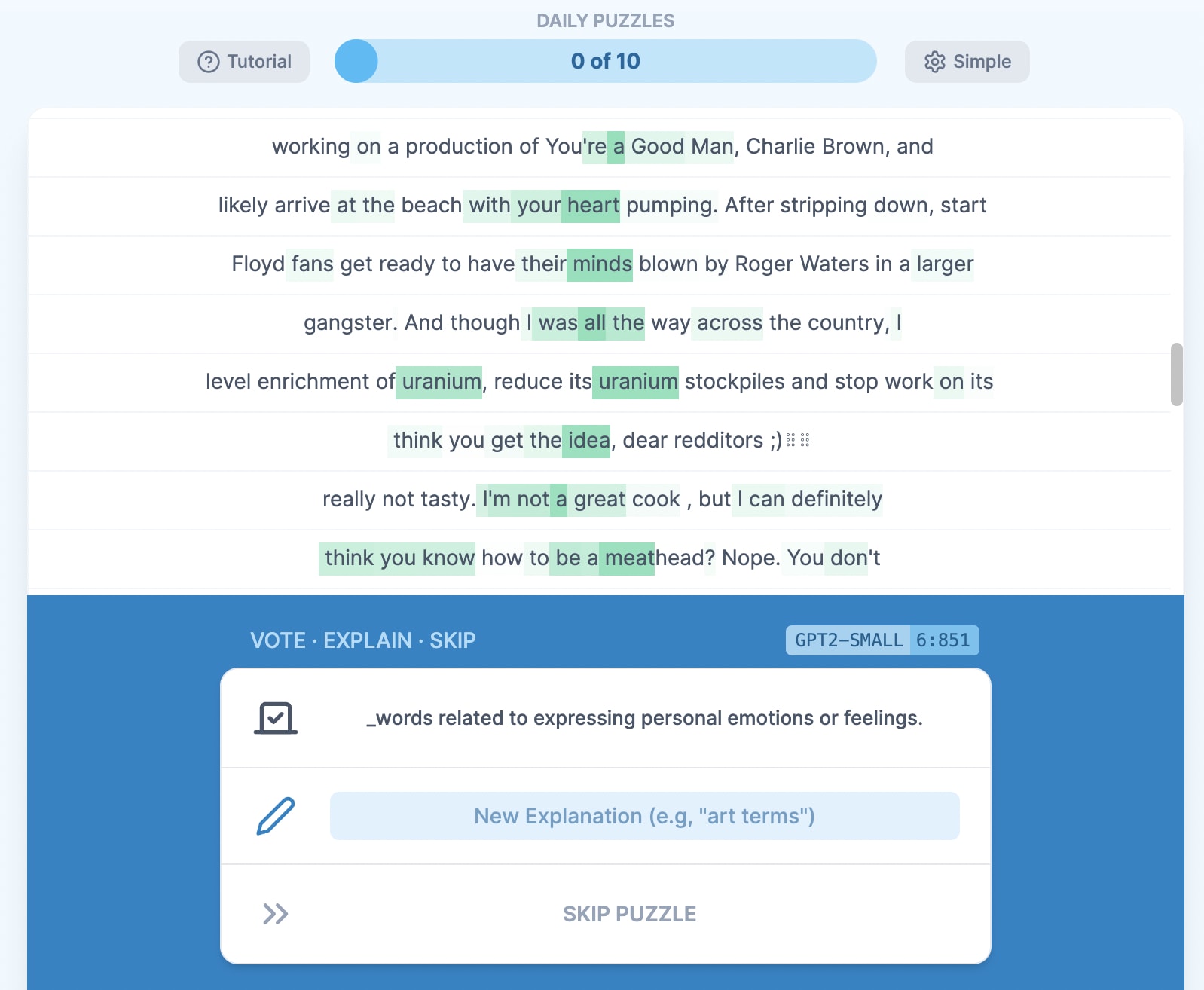
Take this neuron, for example (this was the first one to pop up for me, so not too cherrypicked):
Clearly, the autogenerated explanation of "words related to expressing personal emotions or feelings" doesn't fit at all. But also, coming up with a reasonable explanation myself is really hard. I think probably this neuron is doing something that's inscrutable until you've understood what it's reading and writing—which requires some understanding of the residual stream.
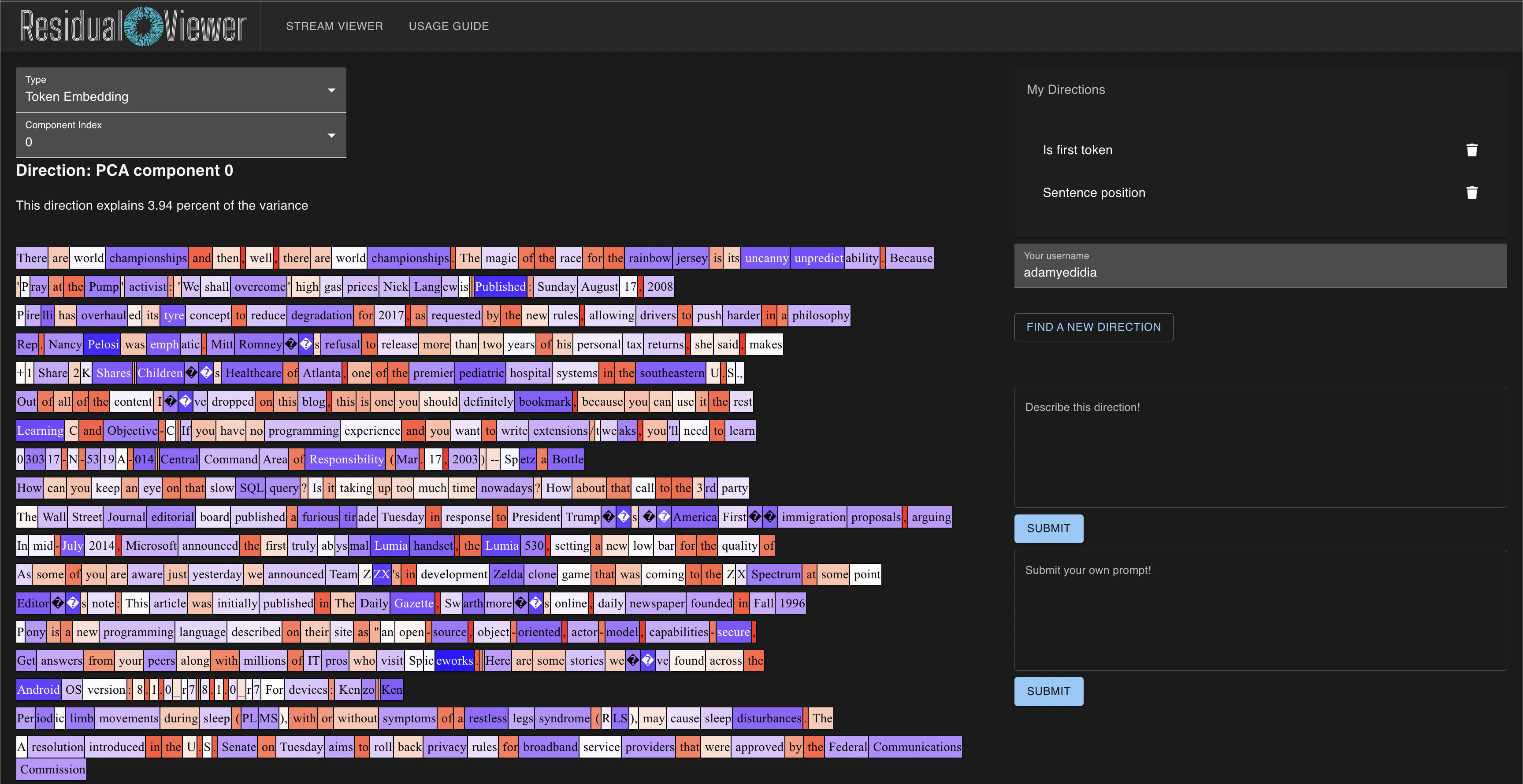
My hope is that the residual stream can mostly be understood in terms of relevant directions, which will represent features or superpositions of features. If users can submit possible mappings of directions -> features, and we can look at what directions the neuron is reading from/writing to, then maybe there's more potential hope for interpreting a neuron like the above. I've been working on a similar tool to yours, which would allow users to submit explanations for residual stream directions. Not online at the moment, but here's a current screenshot of it:
DM me if you'd be interested in talking further, or working together in some capacity. We clearly have a similar approach.
The game is addictive on me, so I can't resist an attempt at describing this one, too :)
It seems related to grammar, possibly looking for tokens on/after articles and possessives
My impression from trying out the game is that most neurons are not too hard to find plausible interpretations for, but most seem to have low-level syntactical (2nd token of a work) or grammatical (conjunctions) concerns.
Assuming that is a sensible thing to ask for, I would definitely be interested in an UI that allows working with the next smallest meaningful construction that fea... (read more)