If one believes that unaligned AGI is a significant problem (>10% chance of leading to catastrophe), speeding up public progress towards AGI is obviously bad.
Though it is obviously bad, there may be circumstances which require it. However, accelerating AGI should require a much higher bar of evidence and much more extreme circumstances than is commonly assumed.
There are a few categories of arguments that claim intentionally advancing AI capabilities can be helpful for alignment, which do not meet this bar[1].
Two cases of this argument are as follows
- It doesn't matter much to do work that pushes capabilities if others are likely to do the same or similar work shortly after.
- We should avoid capability overhangs, so that people are not surprised. To do so, we should extract as many capabilities as possible from existing AI systems.
We address these two arguments directly, arguing that the downsides are much higher than they may appear, and touch on why we believe that merely plausible arguments for advancing AI capabilities aren’t enough.
Dangerous argument 1: It doesn't matter much to do work that pushes capabilities if others are likely to do the same or similar work shortly after.
For a specific instance of this, see Paul Christiano’s “Thoughts on the impact of RLHF research”:
RLHF is just not that important to the bottom line right now. Imitation learning works nearly as well, other hacky techniques can do quite a lot to fix obvious problems […] RLHF is increasingly important as time goes on, but it also becomes increasingly overdetermined that people would have done it. In general I think your expectation should be that incidental capabilities progress from safety research is a small part of total progress […]
Markets aren’t efficient, they only approach efficiency under heavy competition when people with relevant information put effort into making them efficient. This is true for machine learning, as there aren’t that many machine learning researchers at the cutting edge, and before ChatGPT there wasn’t a ton of market pressure on them. Perhaps something as low hanging as RLHF or something similar would have happened eventually, but this isn’t generally true. Don’t assume that something seemingly obvious to you is obvious to everyone.
But even if something like RLHF or imitation learning would have happened eventually, getting small steps of progress slightly earlier can have large downstream effects. Progress often follows an s-curve, which appears exponential until the current research direction is exploited and tapers off. Moving an exponential up, even a little, early on can have large downstream consequences:
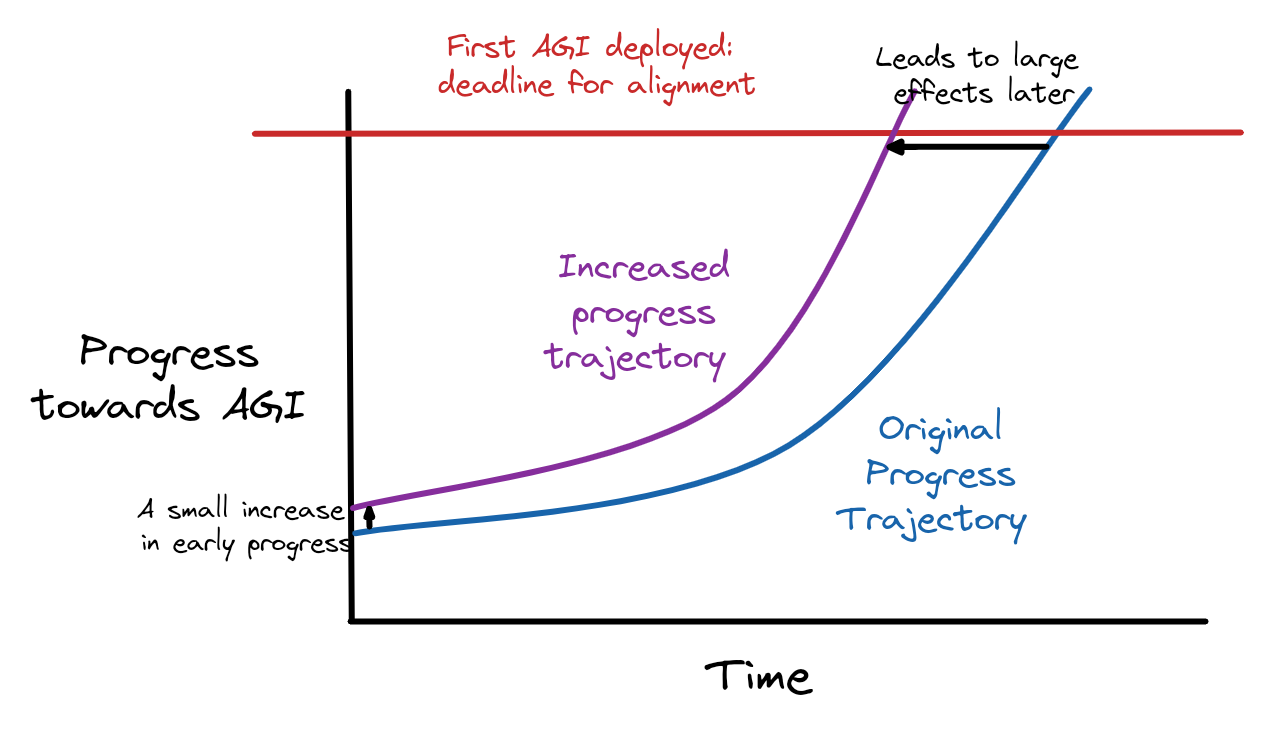
The red line indicates when the first “lethal” AGI is deployed, and thus a hard deadline for us to solve alignment. A slight increase in progress now can lead to catastrophe significantly earlier! Pushing us up the early progress exponential has really bad downstream effects!
And this is dangerous decision theory too: if every alignment researcher took a similar stance, their marginal accelerations would quickly add up.
Dangerous Argument 2: We should avoid capability overhangs, so that people are not surprised. To do so, we should extract as many capabilities as possible from existing AI systems.
Again, from Paul:
Avoiding RLHF at best introduces an important overhang: people will implicitly underestimate the capabilities of AI systems for longer, slowing progress now but leading to faster and more abrupt change later as people realize they’ve been wrong.
But there is no clear distinction between eliminating capability overhangs and discovering new capabilities. Eliminating capability overhangs is discovering AI capabilities faster, so also pushes us up the exponential! For example, it took a few years for chain-of-thought prompting to become more widely known than among a small circle of people around AI Dungeon. Once chain-of-thought became publicly known, labs started fine-tuning models to explicitly do chain-of-thought, increasing their capabilities significantly. This gap between niche discovery and public knowledge drastically slowed down progress along the growth curve!
More worryingly, we also don’t know what capabilities are safe and with what model. There exists no good theory to tell us, and a key alignment challenge is to develop such theories. Each time we advance capabilities without having solved alignment, we roll a die to see if we get catastrophic results, and each time capabilities improve, the die gets more heavily weighted against us. Perhaps GPT-5 won’t be enough to cause a catastrophe, but GPT-5 plus a bunch of other stuff might be. There is simply no way to know with our current understanding of the technology. Things that are safe on GPT-3 may not be safe on GPT-4, and if those capabilities are known earlier, future models will be built to incorporate them much earlier. Extracting all the capabilities juice from the current techniques, as soon as possible, is simply reckless.
Meta: Why arguments for advancing AI capabilities should be subject to much greater scrutiny
Advancing AI capabilities towards AGI, without a theory of alignment, is obviously bad. While all but the most extreme deontologists tend to believe that obviously bad things, such as stealing or murdering, are necessary at times, when listening to arguments for them we generally demand a much higher standard of evidence that they are necessary.
Similarly to justifying taking power or accumulating personal wealth by stealing money for yourself, finding plausible arguments for advancing AI capabilities is heavily incentivized. From VC money, to papers, prestige, hype over language model releases, beating benchmarks or solving challenges, AI capabilities are much more heavily incentivized than alignment. The weight of this money and time means that evidence for the necessity of capabilities will be found faster, and more easily.
Pushing AI capabilities for alignment is also unilateral: one group on their own can advance AI capabilities without input from other alignment groups. That makes it more likely that groups will advance AI capabilities for alignment than is ideal.
As pushing AI capabilities is both incentivized for and unilateralist, we should hold arguments for it to a much higher standard. Being merely convincing (or even worse, just plausible) isn’t enough. The case should be overwhelming.
Moreover, a lot more optimization pressure is being put into optimizing the arguments in favor of advancing capabilities than in the arguments for caution and advancing alignment, and so we should expect the epistemological terrain to be fraught in this case.
We are still engaging with the arguments as if there were not much more resources dedicated to coming up with new arguments for why pushing capabilities is good. But this is mostly for practical reasons: we expect the current community would not react well if we did not do that.
Conclusion
Advancing AI capabilities is heavily incentivized, especially when compared to alignment. As such, arguments that justify advancing capabilities as necessary for alignment should be held to a higher standard. On the other hand, there are very few alignment researchers, and they have limited resources to find and spread counter-arguments against the ones justifying capabilities. Presenting a given piece of capabilities work, as something that will happen soon enough anyways, or pushing for the elimination of “overhangs” to avoid surprise both fall under that umbrella. It is very easy to miss the downstream impacts of pushing us along the progress curve (as they are in the future), and very hard to clarify vague claims about what is an overhang versus a capability.
Instead of vague promises of helping alignment research and plausible deniability of harm, justifying advancing AI capabilities for alignment requires overwhelmingly convincing arguments that these actions will obviously advance alignment enough to be worth the downsides.
- ^
Here are a few example of arguments along these lines.
I have two major reasons to be skeptical of actively slowing down AI (setting aside feasibility):
1. It makes it easier for a future misaligned AI to take over by increasing overhangs, both via compute progress and algorithmic efficiency progress. (This is basically the same sort of argument as "Every 18 months, the minimum IQ necessary to destroy the world drops by one point.")
- RLHF is just not that important to the bottom line right now. Imitation learning works nearly as well, other hacky techniques can do quite a lot to fix obvious problems, and the whole issue is mostly second order for the current bottom line. RLHF is increasingly important as time goes on, but it also becomes increasingly overdetermined that people would have done it. In general I think your expectation should be that incidental capabilities progress from safety research is a small part of total progress, given that it’s a small fraction of people, very much not focused on accelerating things effectively, in a domain with diminishing returns to simultaneous human effort. This can be overturned by looking at details in particular cases, but I think safety people making this argument mostly aren’t engaging with details in a realistic way
- [...]
- Avoiding RLHF at best introduces an important overhang: people will implicitly underestimate the capabilities of AI systems for longer, slowing progress now but leading to faster and more abrupt change later as people realize they’ve been wrong...
Paul and Rohin outlining these positions publicly is extremely laudable. We engage with Paul's post here as he makes concrete, public arguments, not to single him out.
1. Fully agree and we appreciate you stating that.
2. While we are concerned about capability externalities from safety work (that’s why we have an infohazard policy), what we are most concerned about, and that we cover in this post, is deliberate capabilities acceleration justified as being helpful to alignment. Or, to put this in reverse, using the notion that working on systems that are closer to being dangerous might be more fruitful for safety work, to justify actively pushing the capabilities frontier and thus accelerating the arrival of the dangers themselves.
3. We fully agree that engaging with arguments is good, this is why we’re writing this and other work, and we would love all relevant players to do so more. For example, we would love to hear a more detailed, more concrete story from OpenAI of why they believe accelerating AI development has an altruistic justification. We do appreciate that OpenAI and Jan Leike have published their own approach to AI alignment, even though we disagree with some of its contents, and we would strongly support all other players in the field doing the same.
4.
We share your significant unease with such plans. But given what you say here, why at the same time you wouldn’t pursue this plan yourself, yet you say that it seems to you like the expected impact is good?
From our point of view, an unease-generating, AI arrival-accelerating plan seems pretty bad unless proven otherwise. It would be great for the field to hear the reasons why, despite these red flags, this is nevertheless a good plan.
And of course, it would be best to hear the reasoning about the plan directly from those who are pursuing it.