
chinchilla's wild implications
96Ivan Vendrov
42Thirkle
8Yitz
5hackpert
9ChristianKl
5[anonymous]
63Scott Alexander
47nostalgebraist
34Buck
34paulfchristiano
16nostalgebraist
11Buck
4jacob_cannell
4Owain_Evans
3Mateusz Bagiński
22Beth Barnes
12iceman
3Owain_Evans
1Jose Miguel Cruz y Celis
11wickemu
4Jose Miguel Cruz y Celis
4Lukas Finnveden
2ChristianKl
2Lukas Finnveden
63IL
21nostalgebraist
17Sam Bowman
54MSRayne
72nostalgebraist
7MSRayne
6clone of saturn
4Vladimir_Nesov
4Evan R. Murphy
12MathiasKB
5Yitz
24Roman Leventov
23Jay Bailey
15nostalgebraist
1Yitz
2Lone Pine
15Yitz
7Buck
3Yitz
4JBlack
6Buck
2Yitz
22Julian Schrittwieser
30nostalgebraist
16p.b.
8ErickBall
16nostalgebraist
17ErickBall
7Tao Lin
1Simon Lermen
2nostalgebraist
10gwern
11gwern
17harsimony
2Peter Hroššo
1harsimony
12Alex_Altair
9nostalgebraist
3Alex_Altair
12ESRogs
12Legionnaire
9Dirichlet-to-Neumann
8Raemon
19Kaj_Sotala
10nostalgebraist
3Lech Mazur
3Raemon
2Chris_Leong
8RyanCarey
8Rodrigo Heck
48Tom Lieberum
74nostalgebraist
63gwern
15Tomás B.
12Lone Pine
12Hyperion
11Leon Lang
6Rob Bensinger
6Leon Lang
4cata
4Tom Lieberum
28Marius Hobbhahn
7deepthoughtlife
4Houshalter
2deepthoughtlife
3Houshalter
2deepthoughtlife
1Noosphere89
2deepthoughtlife
6mgalle
5Lech Mazur
5LGS
4Lech Mazur
5Zvi
6nostalgebraist
8Vanessa Kosoy
5aog
5traviswfisher@gmail.com
5maxnadeau
10nostalgebraist
3Buck
5__nmca__
4anon135711
4cubefox
3metachirality
3[anonymous]
-1The Hype Doesn't Help
1[anonymous]
3tickybob
3p.b.
7nostalgebraist
3p.b.
6gwern
4CRG
5gwern
4Not Relevant
2Aiyen
1Sushrut Karnik
1Joey Yudelson
2nostalgebraist
1awlego
-1Houshalter
3nostalgebraist
2Houshalter
(Colab notebook here.)
This post is about language model scaling laws, specifically the laws derived in the DeepMind paper that introduced Chinchilla.[1]
The paper came out a few months ago, and has been discussed a lot, but some of its implications deserve more explicit notice in my opinion. In particular:
Some things to note at the outset:
1. the scaling law
The paper fits a scaling law for LM loss L, as a function of model size N and data size D.
Its functional form is very simple, and easier to reason about than the L(N,D) law from the earlier Kaplan et al papers. It is a sum of three terms:
L(N,D)=ANα+BDβ+EThe first term only depends on the model size. The second term only depends on the data size. And the third term is a constant.
You can think about this as follows.
An "infinitely big" model, trained on "infinite data," would achieve loss E. To get the loss for a real model, you add on two "corrections":
- one for the fact that the model's only has N parameters, not infinitely many
- one for the fact that the model only sees D training examples, not infinitely many
L(N,D)=ANαfinite model+BDβfinite data+EirreducibleHere's the same thing, with the constants fitted to DeepMind's experiments on the MassiveText dataset[3].
L(N,D)=406.4N0.34finite model+410.7D0.28finite data+1.69irreducibleplugging in real models
Gopher is a model with 280B parameters, trained on 300B tokens of data. What happens if we plug in those numbers?
L(280⋅109, 300⋅109)=0.052finite model+0.251finite data+1.69irreducible=1.993What jumps out here is that the "finite model" term is tiny.
In terms of the impact on LM loss, Gopher's parameter count might as well be infinity. There's a little more to gain on that front, but not much.
Scale the model up to 500B params, or 1T params, or 100T params, or 3↑↑↑3 params . . . and the most this can ever do for you is an 0.052 reduction in loss[4].
Meanwhile, the "finite data" term is not tiny. Gopher's training data size is very much not infinity, and we can go a long way by making it bigger.
Chinchilla is a model with the same training compute cost as Gopher, allocated more evenly between the two terms in the equation.
It's 70B params, trained on 1.4T tokens of data. Let's plug that in:
L(70⋅109, 1400⋅109)=0.083finite model+0.163finite data+1.69irreducible=1.936Much better![5]
Without using any more compute, we've improved the loss by 0.057. That's bigger than Gopher's entire "finite model" term!
The paper demonstrates that Chinchilla roundly defeats Gopher on downstream tasks, as we'd expect.
Even that understates the accomplishment, though. At least in terms of loss, Chinchilla doesn't just beat Gopher. It beats any model trained on Gopher's data, no matter how big.
To put this in context: until this paper, it was conventional to train all large LMs on roughly 300B tokens of data. (GPT-3 did it, and everyone else followed.)
Insofar as we trust our equation, this entire line of research -- which includes GPT-3, LaMDA, Gopher, Jurassic, and MT-NLG -- could never have beaten Chinchilla, no matter how big the models got[6].
People put immense effort into training models that big, and were working on even bigger ones, and yet none of this, in principle, could ever get as far Chinchilla did.
Here's where the various models lie on a contour plot of LM loss (per the equation), with N on the x-axis and D on the y-axis.
Only PaLM is remotely close to Chinchilla here. (Indeed, PaLM does slightly better.)
PaLM is a huge model. It's the largest one considered here, though MT-NLG is a close second. Everyone writing about PaLM mentions that it has 540B parameters, and the PaLM paper does a lot of experiments on the differences between the 540B PaLM and smaller variants of it.
According to this scaling law, though, PaLM's parameter count is a mere footnote relative to PaLM's training data size.
PaLM isn't competitive with Chinchilla because it's big. MT-NLG is almost the same size, and yet it's trapped in the pinkish-purple zone on the bottom-left, with Gopher and the rest.
No, PaLM is competitive with Chinchilla only because it was trained on more tokens (780B) than the other non-Chinchilla models. For example, this change in data size constitutes 85% of the loss improvement from Gopher to PaLM.
Here's the precise breakdown for PaLM:
L(540⋅109, 780⋅109)=0.042finite model+0.192finite data+1.69irreducible=1.924PaLM's gains came with a great cost, though. It used way more training compute than any previous model, and its size means it also takes a lot of inference compute to run.
Here's a visualization of loss vs. training compute (loss on the y-axis and in color as well):
Man, we spent all that compute on PaLM, and all we got was the slightest edge over Chinchilla!
Could we have done better? In the equation just above, PaLM's terms look pretty unbalanced. Given that compute, we probably should have used more data and trained a smaller model.
The paper tells us how to pick optimal values for params and data, given a compute budget. Indeed, that's its main focus.
If we use its recommendations for PaLM's compute, we get the point "palm_opt" on this plot:
Ah, now we're talking!
"palm_opt" sure looks good. But how would we train it, concretely?
Let's go back to the N-vs.-D contour plot world.
I've changed the axis limits here, to accommodate the massive data set you'd need to spent PaLM's compute optimally.
How much data would that require? Around 6.7T tokens, or ~4.8 times as much as Chinchilla used.
Meanwhile, the resulting model would not be nearly as big as PaLM. The optimal compute law actually puts it at 63B params[7].
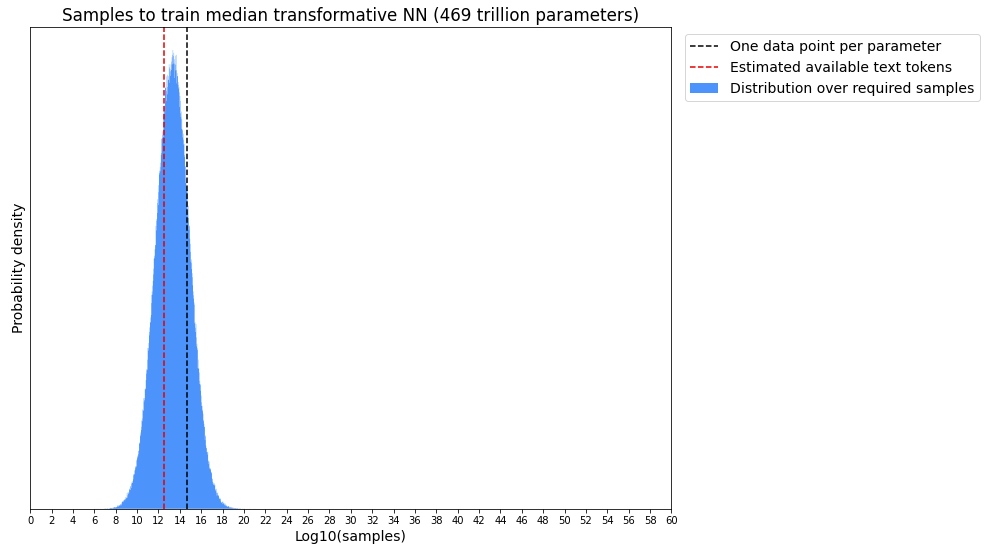
Okay, so we just need to get 6.7T tokens and . . . wait, how exactly are we going to get 6.7T tokens? How much text data is there, exactly?
2. are we running out of data?
It is frustratingly hard to find an answer to this question.
The main moral I want to get across in this post is that the large LM community has not taken data scaling seriously enough.
LM papers are meticulous about N -- doing all kinds of scaling analyses on models of various sizes, etc. There has been tons of smart discussion about the hardware and software demands of training high-N models. The question "what would it take to get to 1T params? (or 10T?)" is on everyone's radar.
Yet, meanwhile:
As a particularly egregious example, here is what the LaMDA paper says about the composition of their training data:
"Dialogs data from public forums"? Which forums? Did you use all the forum data you could find, or only 0.01% of it, or something in between? And why measure words instead of tokens -- unless they meant tokens?
If people were as casual about scaling N as this quotation is about scaling D, the methods sections of large LM papers would all be a few sentences long. Instead, they tend to look like this (excerpted from ~3 pages of similar material):
...anyway. How much more data could we get?
This question is complicated by the fact that not all data is equally good.
(This messy Google sheet contains the calculations behind some of what I say below.)
web scrapes
If you just want a lot of text, the easiest way to get it is from web scrapes like Common Crawl.
But these are infamously full of garbage, and if you want to train a good LM, you probably want to aggressively filter them for quality. And the papers don't tell us how much total web data they have, only how much filtered data.
MassiveWeb
The training dataset used for Gopher and Chinchilla is called MassiveText, and the web scrape portion of it is called MassiveWeb. This data originates in a mysterious, unspecified web scrape[8], which is funneled through a series of filters, including quality heuristics and an attempt to only keep English text.
MassiveWeb is 506B. Could it be made bigger, by scaling up the original web scrape? That depends on how complete the original web scrape was -- but we know nothing about it.
The GLaM/PaLM web corpus
PaLM used a different web scrape corpus. It was first used in this paper about "GLaM," which again did not say anything about the original scraping process, only describing the quality filtering they did (and not in much detail).
The GLaM paper says its filtered web corpus is 143B tokens. That's a lot smaller than MassiveWeb. Is that because of the filtering? Because the original scrape was smaller? Dunno.
To further complicate matters, the PaLM authors used a variant of the GLaM dataset which made multilingual versions of (some of?) the English-only components.
How many tokens did this add? They don't say[9].
We are told that 27% (211B) of PaLM's training tokens came from this web corpus, and we are separately told that they tried to avoid repeating data. So the PaLM version of the GLaM web corpus is probably at least 211B, versus the original 143B. (Though I am not very confident of that.)
Still, that's much smaller than MassiveWeb. Is this because they had a higher quality bar (which would be bad news for further data scaling)? They do attribute some of PaLM's success to quality filtering, citing the ablation on this in the GLaM paper[10].
It's hard to tell, but there is this ominous comment, in the section where they talk about PaLM vs. Chinchilla:
The subcorpora that start to repeat are probably the web and dialogue ones.
Read literally, this passage seems to suggest that even the vast web data resources available to Google Research (!) are starting to strain against the data demands of large LMs. Is that plausible? I don't know.
domain-specific corpora
We can speak with more confidence about text in specialized domains that's less common on the open web, since there's less of it out there, and people are more explicit about where they're getting it.
Code
If you want code, it's on Github. There's some in other places too, but if you've exhausted Github, you probably aren't going to find orders of magnitude of additional code data. (I think?)
We've more-or-less exhausted Github. It's been scraped a few times with different kinds of filtering, which yielded broadly similar data sizes:
(The text to token ratios vary due to differences in how whitespace was tokenized.)
All of these scrapes contained a large fraction of the total code available on Github (in the Codex paper's case, just the python code).
Generously, there might be ~1T tokens of code out there, but not vastly more than that.
Arxiv
If you want to train a model on advanced academic research in physics or mathematics, you go to Arxiv.
For example, Arxiv was about half the training data for the math-problem-solving LM Minerva.
We've exhausted Arxiv. Both the Minerva paper and the Pile use basically all of Arxiv, and it amounts to a measly 21B tokens.
Books
Books? What exactly are "books"?
In the Pile, "books" means the Books3 corpus, which means "all of Bibliotik." It contains 196,640 full-text books, amounting to only 27B tokens.
In MassiveText, a mysterious subset called "books" has 560B tokens. That's a lot more than the Pile has! Are these all the books? In . . . the world? In . . . Google books? Who even knows?
In the GLaM/PaLM dataset, an equally mysterious subset called "books" has 390B tokens.
Why is the GLaM/PaLM number so much smaller than the MassiveText number? Is it a tokenization thing? Both of these datasets were made by Google, so it's not like the Gopher authors have special access to some secret trove of forbidden books (I assume??).
If we want LMs to learn the kind of stuff you learn from books, and not just from the internet, this is what we have.
As with the web, it's hard to know what to make of it, because we don't know whether this is "basically all the books in the world" or just some subset that an engineer pulled at one point in time[13].
"all the data we have"
In my spreadsheet, I tried to make a rough, erring-on-generous estimate of what you'd get if you pooled together all the sub-corpora mentioned in the papers I've discussed here.
I tried to make it an overestimate, and did some extreme things like adding up both MassiveWeb and the GLaM/PaLM web corpus as though they were disjoint.
The result was ~3.2T tokens, or
Recall that this already contains "basically all" of the open-source code in the world, and "basically all" of the theoretical physics papers written in the internet era -- within an order of magnitude, anyway. In these domains, the "low-hanging fruit" of data scaling are not low-hanging at all.
what is compute? (on a further barrier to data scaling)
Here's another important comment from the PaLM paper's Chinchilla discussion. This is about barriers to doing a head-to-head comparison experiment:
In LM scaling research, all "compute" is treated as fungible. There's one resource, and you spend it on params and steps, where compute = params * steps.
But params can be parallelized, while steps cannot.
You can take a big model and spread it (and its activations, gradients, Adam buffers, etc.) across a cluster of machines in various ways. This is how people scale up N in practice.
But to scale up D, you have to either:
Thus, it is unclear whether the "compute" you spend in high-D models is as readily available (and as bound to grow over time) as we typically imagine "compute" to be.
If LM researchers start getting serious about scaling up data, no doubt people will think hard about this question, but that work has not yet been done.
appendix: to infinity
Earlier, I observation that Chinchilla beats any Gopher of arbitrary size.
The graph below expands on that observation, by including two variants of each model:
(There are two x-axes, one for data and one for params. I included the latter so I have a place to put the infinite-data models without making an infinitely big plot.
The dotted line is Chinchilla, to emphasize that it beats infinite-params Gopher.)
The main takeaway IMO is the size of the gap between ∞ data models and all the others. Just another way of emphasizing how skewed these models are toward N, and away from D.
Training Compute-Optimal Large Language Models
See their footnote 2
See their equation (10)
Is 0.052 a "small" amount in some absolute sense? Not exactly, but (A) it's small compared to the loss improvements we're used to seeing from new models, and (B) small compared to the improvements possible by scaling data.
In other words, (A) we have spent a few years plucking low-hanging fruit much bigger than this, and (B) there are more such fruit available.
The two terms are still a bit imbalanced, but that's largely due to the "Approach 3 vs 1/2" nuances mentioned above.
Caveat: Gopher and Chinchilla were trained on the same data distribution, but these other models were not. Plugging them into the equation won't give us accurate loss values for the datasets they used. Still, the datasets are close enough that the broad trend ought to be accurate.
Wait, isn't that smaller than Chinchilla?
This is another Approach 3 vs. 1/2 difference.
Chinchilla was designed with Approaches 1/2. Using Approach 3, like we're doing here, give you a Chinchilla of only 33B params, which is lower than our palm_opt's 63B.
Seriously, I can't find anything about it in the Gopher paper. Except that it was "collected in November 2020."
It is not even clear that this multilingual-ization affected the web corpus at all.
Their datasheet says they "used multilingual versions of Wikipedia and conversations data." Read literally, this would suggest they didn't change the web corpus, only those other two.
I also can't tell if the original GLaM web corpus was English-only to begin with, since that paper doesn't say.
This ablation only compared filtered web data to completely unfiltered web data, which is not a very fine-grained signal. (If you're interested, EleutherAI has done more extensive experiments on the impact of filtering at smaller scales.)
They are being a little coy here. The current received wisdom by now is that repeating data is really bad for LMs and you should never do it. See this paper and this one.
EDIT 11/15/22: but see also the Galactica paper, which casts significant doubt on this claim.
The Pile authors only included a subset of this in the Pile.
The MassiveText datasheet says only that "the books dataset contains books from 1500 to 2008," which is not especially helpful.