Epistemic status: thinking aloud, not got any plans, definitely not making any commitments.
I'm thinking about building a pipeline to produce a lot of LessWrong books based around authors. The idea being that a bunch of authors would have their best essays collated in a single book, with a coherent aesthetic and ML art and attractive typography.
This stands in contrast to making books around sequences, and I do really like sequences, but when I think about most authors whose work I love from the past 5 years there's a lot of standalone essays, and they don't tie together half as neatly as Eliezer's original sequences (and were not supposed to). For instance, Eliezer himself has written a lot of standalone dialogues in recent years that could be collated into a book, but that don't make sense as a 'sequence' on a single theme.
Well, the actual reason I'm writing this is because I sometimes feel a tension between my own taste (e.g. who I'd like to make books for) and not wanting to impose my opinions too dictatorially on the website. Like, I do want to show the best of what LessWrong has, but I think sometimes I'd want to have more discretion — for instance maybe I'd want to release a series of three books on similar themes, and but I don't know a good way to justify my arbitrary choice there of which books to make.
The review was a process of making a book that maximally took my judgment about content out of the decision, that well-represented the best of LW. I also don't know that I really want to use a voting process to determine which essays go into the books, I think the essays in the book are more personal and represent the author, and also a book coheres better together if it's put together with a single vision, and I'd rather that be a collaboration between me and the author (to the extent they wish to be involved).
Thoughts on ways for me to move forward on this?
Why not do both? Are there any relevant hard limits on how many books you can publish?
Publish normal LW books, and publish your own curation of books?
One way would be to setup a general pipeline that can be used by everyone and give extra attention to those authors for whom you want to make books to do all the necessary work for them.
[What follows is a definitely impractical recommendation, which can hopefully be approximated by more practical actions. For example, you could have voting take place before the bookmaking, so that people only vote on teams, and each team can take more time & effort into making the books because of the guaranteed publishing]
If you want the community to be involved, and you also want lots of books with single visions, then you can have the community vote on a collection of books rather than essays. Top books get published by Lightcone/LessWrong, and maybe before voting Lightcone/LessWrong provides an impact market like mechanism by which people can buy/sell stocks on which book teams will get in the top in order to pay people to actually work on the books.
Alternatively, you could brand the books you want under the name Ben Pace rather than LessWrong, like the team does when making comments on LessWrong.
I could, but I'd really like to build up the LW library, not the Ben Pace library. LW's library sounds like a much cooler library that people would be really keen to read. It's just hard to figure out how to do that right.
I am curious about whether the goal of making lesswrong books is driven by a general interest in making a book "It would be fun to get together a book, I would love to have a copy of my favourite ideas in physical form", or is a way of trying to introduce people to your favourite essays? Because, I worry that if its the latter a book might not be an efficient approach. There are many, many random self-published books available, most of which probably sell 10's of copies (if that). So, if you made the book as a way of reaching people, you would then still need to reach people (somehow) to tell them about the book, and the inertia against buying a book of unknown quality is probably higher than that against "read this random article someone has linked me, hey look it says its only a 15 min read".
Many thousands of people have bought the last two sets of books we produced. They were to a much higher quality standard than 99% of self-published books available.
Yes, part of my motive is for lots of people who haven't read these posts to have them in a beautifully designed physical format and finally get around to reading them. I would guess that there are less than 100 people who have read every essay in each of the books (before the books were published), so I think most people who bought them got new content.
I have no-doubt at all that the books are of a much higher quality than most self-published material. And the thousands of sales of the last two books is impressive! My point was that someone who had never heard of lesswrong before was unlikely to purchase a book "cold" - which is what I had read as your intention. But from the reply your goal is instead to connect people already in the know with more good stuff faster, which a book probably achieves well. (In addition to the "books are just really nice things" angle.)
I don't recall how I found the LW community, but I'm looking forward to some intelligence, online discussion. Judging by the posts I've read thus far, this appears to be the place. I look forward to learning from the community and will hopefully contribute something of value.
Personally, I'm gravely concerned about the state of academia, from a rationalist's perspective, and troubled by what I perceive as a trend away from rationality in the public sphere. I hope to learn more about how we can steer society back towards a path that values logic, empiricism, and free inquiry.
Hey all, nice forum you've got going here!
I've recently drunk the koolaid of the 80,000 Hours initiative and would like to make a difference by dedicating my career to human-aligned AI implementation. I thought I'd comment in this thread to express my interest in information about how I (or anybody else in my position) can make a difference.
A quick search of the forum history shows that a Lurkshop was held in December, which I obviously just missed. But that's the exact kind of thing I'm looking for.
Any information on how one can enter the field of risk mitigation around AI would be much appreciated. And if this kind of message isn't welcome on this forum, please let me know.
Welcome to LessWrong!
There are multiple guides to getting started on Alignment. In no particular order:
- Alignment Research Field Guide
- How To Get Into Independent Research On Alignment/Agency
- A Guide to MIRI’s Research
- Alignment Fundamentals curriculum (101)
- Alignment 201 Curriculum (successor to 101)
I think the last two options are best as comprehensive curricula for a general aspiring alignment researcher.
I applied to take the 101 course myself.
Amazing resources, thank you for sharing!
I didn't want to dive too deeply into the specifics of where I'm at so that the resulting advice would be generally applicable. But I've been out in the working world for more-than-a-few years already and so jumping back into pure research would be a big challenge on a number of levels.
Would you say that the state of the field at the moment is almost entirely research? Or are there opportunities to work in more applied positions in outreach/communications, policy strategy, etc?
Would you say that the state of the field at the moment is almost entirely research?
No.
Or are there opportunities to work in more applied positions in outreach/communications, policy strategy, etc?
There are, I just don't know them of the top of my head.
Hello, long time reader all the way back to Overcoming Bias. I've always liked this community and loved reading posts here. I have never posted before and only just created this account a few months ago shorty after I used ChatGPT in November.
This is my first comment here; I do webcomics and a bit of category theory!
I gravitate towards certain aspects of rationality because I have an aesthetic preference for certain things like simplicity and consistency, which gives me a fondness for principles like Occam's Razor and identifying ways that peope often fail to be consistent, which rationalists tend to talk about afaik.
But I wouldn't say I'm a truthseeker, just an 'intellectual hedonist'. I have a sense of 'curiosity', but it's more towards 'cool stuff' rather than 'true stuff'. My sense of what's 'cool' is pretty arbitrary.
Anyone else feels similarly? Would this be a good place for me? My goals might not completely align with yours, but compared to most other places on the Internet, this place has a higher concentration of stuff I find pleasing (or at least not-displeasing) to read :P
I think LW would be a good fit for you.
Honestly, I think most of the rationality content on LW is insight porn[1] and apply a very heavy karma penalty (-100) to the Rationality tag to suppress it from showing up on my feed:
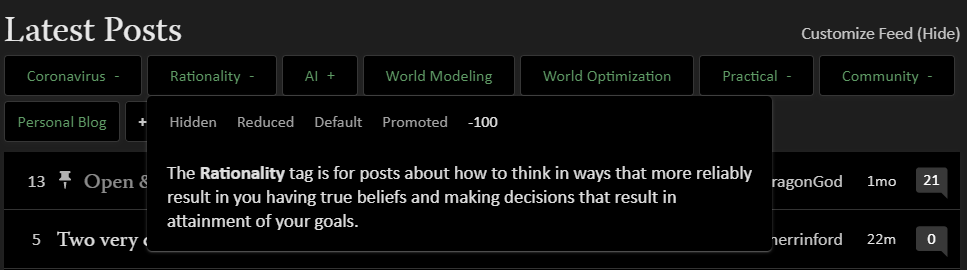
That said, I am very much a rationalist/share rationality values. I just mostly read LW for AI posts ("World Modeling" and "World Optimization" posts are a nice bonus).
- ^
Obligatory disclaimer that I've listened to the Sequences multiple times and would probably give it another listen later on.
Yeah, I think I'm drawn to insight porn because of my intellectual hedonism (which mostly cares about what feels good to read about than what actually improves my ability to have true beliefs and make decisions that result in the attainment of my goals) XD But I'll be careful!
I think I've read one or two AI posts which were surprisingly accessible considering I have no background in AI.
I'm banning user lesswrong.com/users/alfred, based in part on their reputation in an in-person community, and in part on their LW content being fairly bad. (I realize this is kinda opaque, but seemed better to say something rather than nothing about it)
Insomuch as this comment is an invite for commentary, I don't think their LW content warranted a ban.
Perusing their comments, they seemed critical of LW/the community, but their criticism didn't seem valueless?
And I don't like banning people that provide contentful criticism of LW/the community for evapourative cooling effects. This ban seems like a step in the direction of worse community epistemics?
I'm looking for feedback on my understanding of Corrigibility.
I skimmed CHAI, Assistance Games, And Fully Updated Deferece . Is the key criticism that The Off-Switch Game ignores the embeddedness of the human? i.e. The agent will stochastically model the human and so will just try to predict what the human will say instead of asking it? This limitation is mentioned on Page 3.
Is this criticism correct or am I missing something else?
The Intercom is not appearing on my version of Chromium 109.0.5414.119 snap but does appear fine on Google Chrome 109.0.5414.74. Not sure if this is worth fixing.
I recently figured out a great way of restoring my hands to baseline functionality after they‘ve been exposed to cold for an extended period of time. It goes like this:
- Put your hands under warm water for a minute or so. This will make your blood vessels dilate.
- With your arms extended, rapidly bring your hands up and down about 10-20 times. This motion helps to improve circulation by using centrifugal force to bring blood into your hands.
I've tried this technique a few times and it seems to be vastly more effective than just using hot water alone.
I hope someone finds this helpful during the winter.
Depending on how cold your hands are, you should NOT use hot water. I was always taught that this is really bad for your body to go from freezing to hot.
Edit: To be clear, this is emphatic agreement, not disagreement
(I may promote this to a full question)
Do we actually know what's happening when you take an LLM trained on token prediction and fine-tune is via e.g. RLHF to get something like InstructGPT or ChatGPT? The more I think about the phenomenon, the more confused I feel.
A long time ago, a LWer posted lyrics to a The National song, which introduced me to the band. About a week ago, the band uploaded a new song, with some more interesting lyrics, so I figured I would pass the fun forward.
Specifically, the lines are:
``Something somehow has you rapidly improving Oh, what happened to the wavelength we were on? Oh, where's the gravity gone? Something somehow has you rapidly improving You found the ache in my argument You couldn't wait to get out of it You found the slush in my sentiment You made it sound so intelligent``
Source:
For some reason I don't get e-mail notifications when someone replies to my posts or comments. My e-mail is verified and I've set all notifications to "immediately". Here's what my e-mail settings look like:
If I encounter a capabilities paper that kinda spooks me, what should I do with it? I'm inclined to share it as a draft post with some people I think should know about it. I have encountered a paper that, if scaled, is probably starkly superintelligent at math, and I found it in a capabilities discussion group who will have no hesitation about using it to try to accumulate power for themselves, in denial about any negative effects it could have.
edit: actually, I posted this as a whole question, so maybe reply there
Do you expect that there are papers that spook you but that wouldn't get attention if you don't tell other people about it?
whoops, I also posted a whole question about this and forgot I'd actually hit send on the comment on the open thread. Can you move your reply over there and I'll also do so?
but my reply is,
attention isn't binary. Giving a paper more attention because I think it is very powerful could still be a spark that gets it to spread much faster, if the folks who've seen it don't realize how powerful it is yet. This is extremely common; mere combinations of papers are often enough for the abstract of the obvious followup to nearly write itself in the heads of competent researchers. In general, the most competent capabilities researchers do not announce paper lists from the rooftops for this reason - they try to build the followup and then they announce that. In general I don't think I am being watched by many high competence folks, and the ones who are, probably simply explore the internet manually the same way I do. But it's something that I always have in mind, and occasionally I see a paper that really raises my hackles.
I remember (from listening to a bunch of podcasts by German hackers from the mid 00s) a strong vibe that the security of software systems at the time and earlier was definitely worse than what would've been optimal for the people making the software (definitely not safe enough for the users!).
I wonder whether that is (1) true and (if yes) (2) what led to this happening!
Maybe companies were just myopic when writing software then, and could've predicted the security problems but didn't care?
Or was it that the error predicting the importance of security was just an outlier, that companies and industries on average correctly predict the importance of safety & security, and this was just a bad draw from the distribution.
Or is this a common occurrence? Then one might chalk it up to (1) information asymmetries (normal users don't value the importance of software security, let alone evaluate the quality of a given piece of software) or (2) information problems in firms (managers had a personal incentive to cut corners on safety).
Another reason might be that lower-level software usually can make any security issues a reputational externality for end-user software: sure, in the end Intel's branch predictor is responsible for Meltdown and Spectre, and for setting cache timeouts too high that we can nicely rowhammer.js it out, but what end-user will blame Intel and not "and then Chrome crashed and they wanted my money".
This is, of course, in the context of the development of AI, and the common argument that "companies will care about single-single alignment".
The possible counterexample of software security engineering until the mid 00s seemed like a good test case to me, but on reflection I'm now not so sure anymore.
If it’s worth saying, but not worth its own post, here's a place to put it.
If you are new to LessWrong, here's the place to introduce yourself. Personal stories, anecdotes, or just general comments on how you found us and what you hope to get from the site and community are invited. This is also the place to discuss feature requests and other ideas you have for the site, if you don't want to write a full top-level post.
If you're new to the community, you can start reading the Highlights from the Sequences, a collection of posts about the core ideas of LessWrong.
If you want to explore the community more, I recommend reading the Library, checking recent Curated posts, seeing if there are any meetups in your area, and checking out the Getting Started section of the LessWrong FAQ. If you want to orient to the content on the site, you can also check out the Concepts section.
The Open Thread tag is here. The Open Thread sequence is here.