I have a lot of ideas about AGI/ASI safety. I've written them down in a paper and I'm sharing the paper here, hoping it can be helpful.
Title: A Comprehensive Solution for the Safety and Controllability of Artificial Superintelligence
Abstract:
As artificial intelligence technology rapidly advances, it is likely to implement Artificial General Intelligence (AGI) and Artificial Superintelligence (ASI) in the future. The highly intelligent ASI systems could be manipulated by malicious humans or independently evolve goals misaligned with human interests, potentially leading to severe harm or even human extinction. To mitigate the risks posed by ASI, it is imperative that we implement measures to ensure its safety and controllability. This paper analyzes the intellectual characteristics of ASI, and three conditions for ASI to cause catastrophes (harmful goals, concealed intentions, and strong power), and proposes a comprehensive safety solution. The solution includes three risk prevention strategies (AI alignment, AI monitoring, and power security) to eliminate the three conditions for AI to cause catastrophes. It also includes four power balancing strategies (decentralizing AI power, decentralizing human power, restricting AI development, and enhancing human intelligence) to ensure equilibrium between AI to AI, AI to human, and human to human, building a stable and safe society with human-AI coexistence. Based on these strategies, this paper proposes 11 major categories, encompassing a total of 47 specific safety measures. For each safety measure, detailed methods are designed, and an evaluation of its benefit, cost, and resistance to implementation is conducted, providing corresponding priorities. Furthermore, to ensure effective execution of these safety measures, a governance system is proposed, encompassing international, national, and societal governance, ensuring coordinated global efforts and effective implementation of these safety measures within nations and organizations, building safe and controllable AI systems which bring benefits to humanity rather than catastrophes.
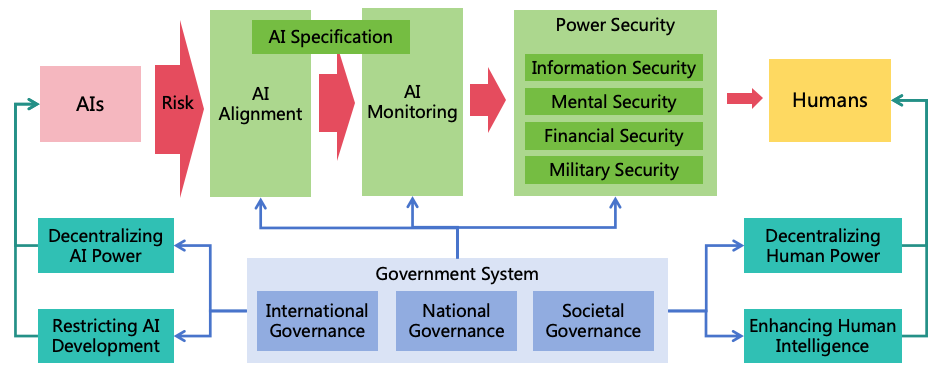
Content:
The paper is quite long, with over 100 pages. So I can only put a link here. If you're interested, you can visit this link to download the PDF: https://www.preprints.org/manuscript/202412.1418/v1
or you can read the online HTML version at this link:
(Reposted from Facebook)
Hey Weibing Wang! Thanks for sharing. I just started skimming your paper, and I appreciate the effort you put into this; it combines many of the isolated work people have been working on.
I also appreciate your acknowledgement that your proposed solution has not undergone experimental validation, humility, and the suggestion that these proposed solutions need to be tested and iterated upon as soon as possible due to the practicalities of the real world.
I want to look into your paper again when I have time, but some quick comments:
https://www.lesswrong.com/tag/ai-services-cais?sortedBy=new https://www.lesswrong.com/posts/LxNwBNxXktvzAko65/reframing-superintelligence-llms-4-years
You should make the paper into a digestible format of sub-projects you can post to find collaborators to make progress on to verify some parts experimentally and potentially collaborate with some governance folks to turn some of your thoughts into a report that will get the eyeballs of important people on it.
Need more technical elaboration on the "how" to do x, not just "what" needs to be done.
Thank you for your suggestions! I have read the CAIS stuff you provided and I generally agree with these views. I think the solution in my paper is also applicable to CAIS.