

I'm launching AI Lab Watch. I collected actions for frontier AI labs to improve AI safety, then evaluated some frontier labs accordingly.
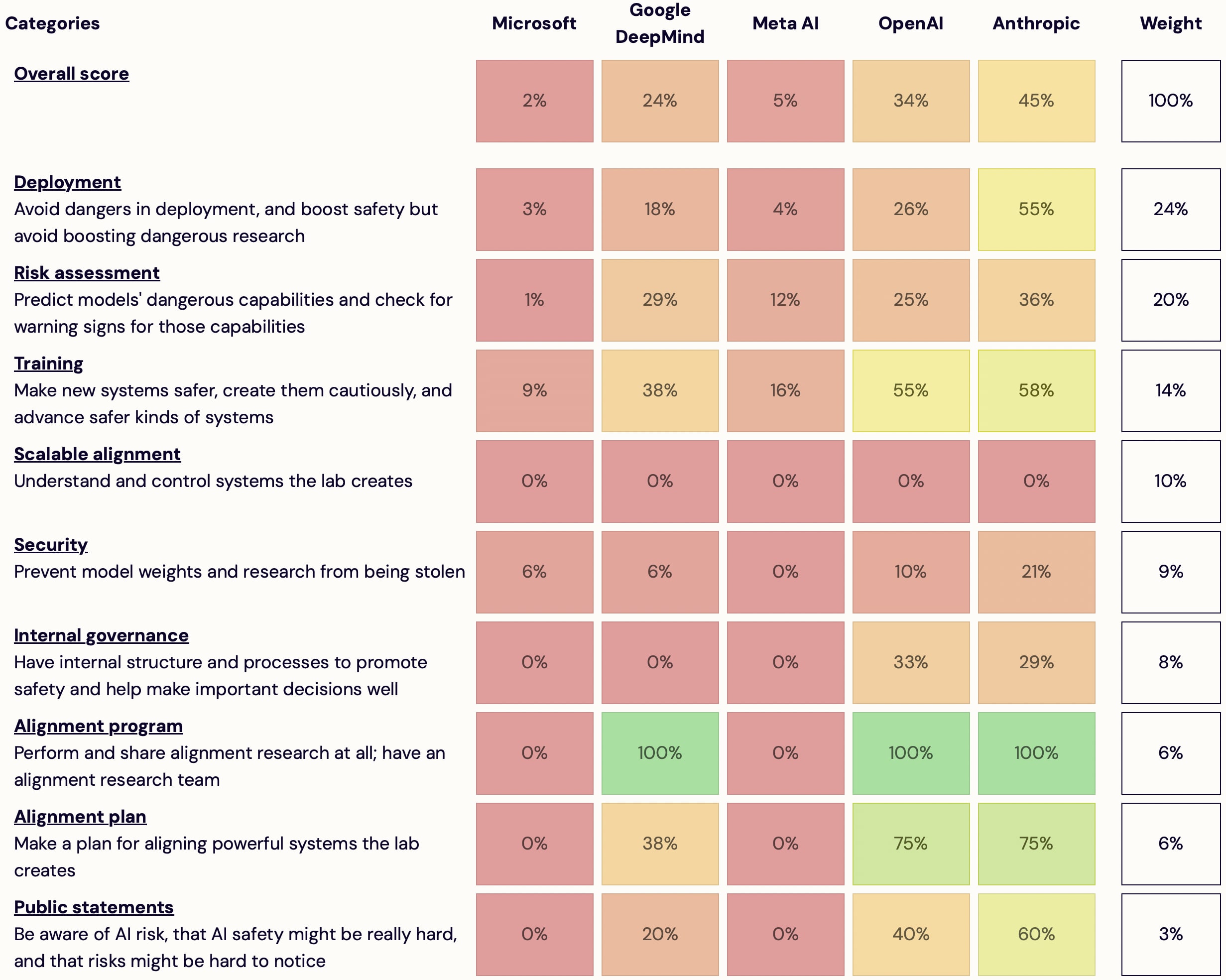
It's a collection of information on what labs should do and what labs are doing. It also has some adjacent resources, including a list of other safety-ish scorecard-ish stuff.
(It's much better on desktop than mobile — don't read it on mobile.)
It's in beta—leave feedback here or comment or DM me—but I basically endorse the content and you're welcome to share and discuss it publicly.
It's unincorporated, unfunded, not affiliated with any orgs/people, and is just me.
Some clarifications and disclaimers.
How you can help:
- Give feedback on how this project is helpful or how it could be different to be much more helpful
- Tell me what's wrong/missing; point me to sources on what labs should do or what they are doing
- Suggest better evaluation criteria
- Share this
- Help me find an institutional home for the project
- Offer expertise on a relevant topic
- Offer to collaborate
- Volunteer your webdev skills
- (Pitch me on new projects or offer me a job)
- (Want to help and aren't sure how to? Get in touch!)
I think this project is the best existing resource for several kinds of questions, but I think it could be a lot better. I'm hoping to receive advice (and ideally collaboration) on taking it in a more specific direction. Also interested in finding an institutional home. Regardless, I plan to keep it up to date. Again, I'm interested in help but not sure what help I need.
I could expand the project (more categories, more criteria per category, more labs); I currently expect that it's more important to improve presentation stuff but I don't know how to do that; feedback will determine what I prioritize. It will also determine whether I continue spending most of my time on this or mostly drop it.
I just made a twitter account. I might use it to comment on stuff labs do.
Thanks to many friends for advice and encouragement. Thanks to Michael Keenan for doing most of the webdev. These people don't necessarily endorse this project.



Various comments:
I wouldn't call this "AI lab watch." "Lab" has the connotation that these are small projects instead of multibillion dollar corporate behemoths.
"deployment" initially sounds like "are they using output filters which harm UX in deployment", but instead this seems to be penalizing organizations if they open source. This seems odd since open sourcing is not clearly bad right now. The description also makes claims like "Meta release all of their weights"---they don't release many image/video models because of deepfakes, so they are doing some cost-benefit analysis. Zuck: "So we want to see what other people are observing, what we’re observing, what we can mitigate, and then we'll make our assessment on whether we can make it open source." If this is mainly a penalty against open sourcing the label should be clearer.
"Commit to do pre-deployment risk assessment" They've all committed to this in the WH voluntary commitments and I think the labs are doing things on this front.
"Do risk assessment" These companies have signed on to WH voluntary commitments so are all checking for these things, and the EO says to check for these hazards too. This is why it's surprising to see Microsoft have 1% given that they're all checking for these hazards.
Looking at the scoring criteria, this seems highly fixated on rogue AIs, but I understand I'm saying that to the original forum of these concerns. Risk assessment's scoring doesn't really seem to prioritize bio x-risk as much as scheming AIs. This is strange because if we're focused on rogue AIs I'd put a half the priority of risk mitigation while the model is training. Many rogue AI people may think half of the time the AI will kill everyone is when the model is "training" (because it will escape during that time).
The first sentence of this site says the focus is on "extreme risks" but it seems the focus is mainly on rogue AIs. This should be upfront that this is from the perspective that loss of control is the main extreme risk, rather than positioning itself as a comprehensive safety tracker. If I were tracking rogue AI risks, I'd probably drill down to what they plan to do with automated AI R&D/intelligence explosions.
"Training" This seems to give way more weight to rogue AI stuff. Red teaming is actually assessable, but instead you're giving twice the points to if they have someone "work on scalable oversight." This seems like an EA vibes check rather than actually measuring something. This also seems like triple counting since it's highly associated with the "scalable alignment" section and the "alignment program" section. This doesn't even require that they use the technique for the big models they train and deploy. Independently, capabilities work related to building superintelligences can easily be framed as scalable oversight, so this doesn't set good incentives. Separately, at the end this also gives lots of points for voluntary (read: easily breakable) commitments. These should not be trusted and I think the amount of lipservice points is odd.
"Security" As I said on EAF the security scores are suspicious to me and even look backward. The major tech companies have much more experience protecting assets (e.g., clouds need to be highly secure) than startups like Anthropic and OpenAI. It takes years building up robust information security and the older companies have a sizable advantage.
"internal governance" scores seem odd. Older, larger institutions such as Microsoft and Google have many constraints and processes and don't have leaders who can unilaterally make decisions as easily, compared to startups. Their CEOs are also more fireable (OpenAI), and their board members aren't all selected by the founder (Anthropic). This seems highly keyed into if they are just a PBC or non-profit. In practice PBC just makes it harder to sue, but Zuck has such control of his company that getting successfully sued for not upholding his fiduciary duty to shareholders seems unlikely. It seems 20% of the points is not using non-disparagement agreements?? 30% is for whistleblower policies; CA has many whistleblower protections if I recall correctly. No points for a chief risk officer or internal audit committee?
"Alignment program" "Other labs near the frontier publish basically no alignment research" Meta publishes dozens of papers they call "alignment"; these actually don't feel that dissimilar to papers like Constitutional AI-like papers (https://twitter.com/jaseweston/status/1748158323369611577 https://twitter.com/jaseweston/status/1770626660338913666 https://arxiv.org/pdf/2305.11206 ). These papers aren't posted to LW but they definitely exist. To be clear I think this is general capabilities but this community seems to think differently. Alignment cannot be "did it come from EA authors" and it probably should not be "does it use alignment in its title." You'll need to be clear how this distinction is drawn.
Meta has people working on safety and CBRN+cyber + adversarial robustness etc. I think they're doing a good job (here are two papers from the last month: https://arxiv.org/pdf/2404.13161v1 https://arxiv.org/pdf/2404.16873).
As is, I think this is a little too quirky and not ecumenical enough for it to generate social pressure.
There should be points for how the organizations act wrt to legislation. In the SB 1047 bill that CAIS co-sponsored, we've noticed some AI companies to be much more antagonistic than others. I think is is probably a larger differentiator for an organization's goodness or badness.
(Won't read replies since I have a lot to do today.)
Disagree on "lab". I think it's the standard and most natural term now. As evidence, see your own usage a few sentences later: