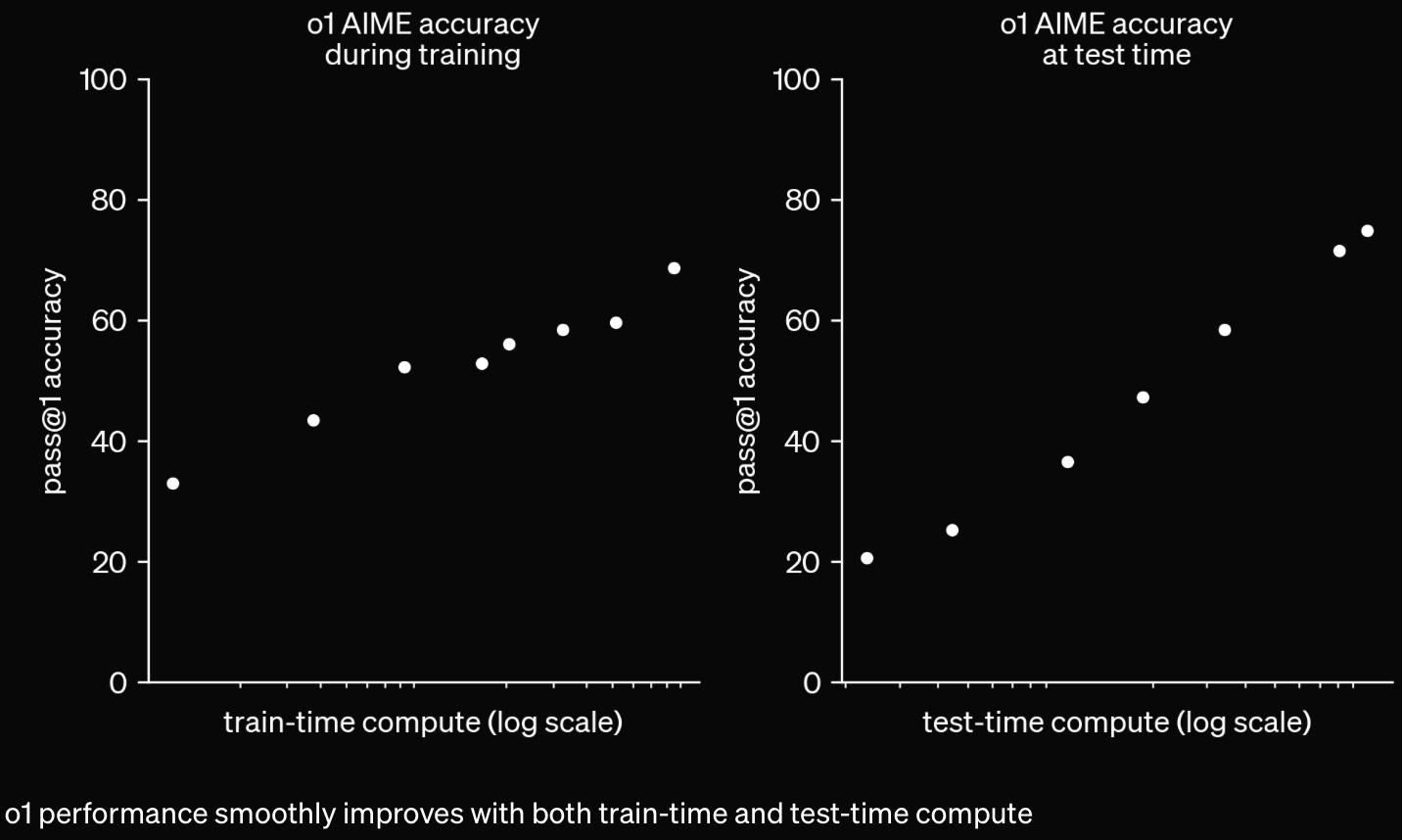
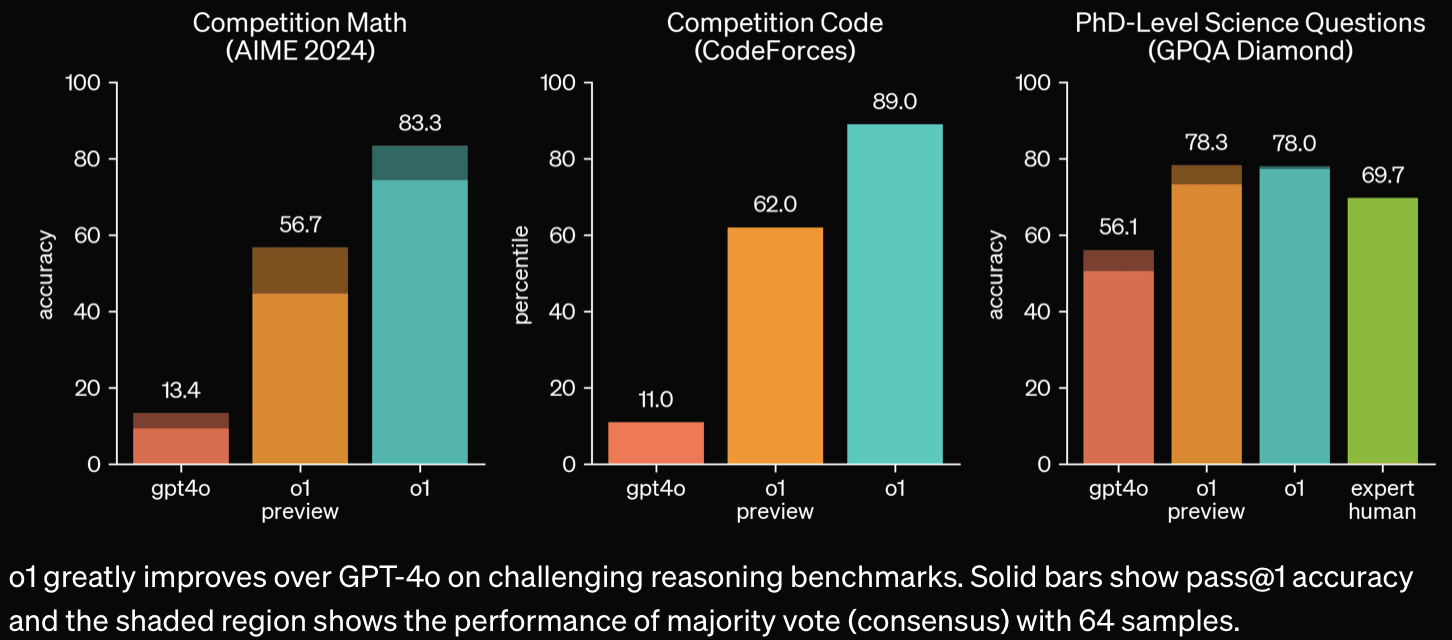
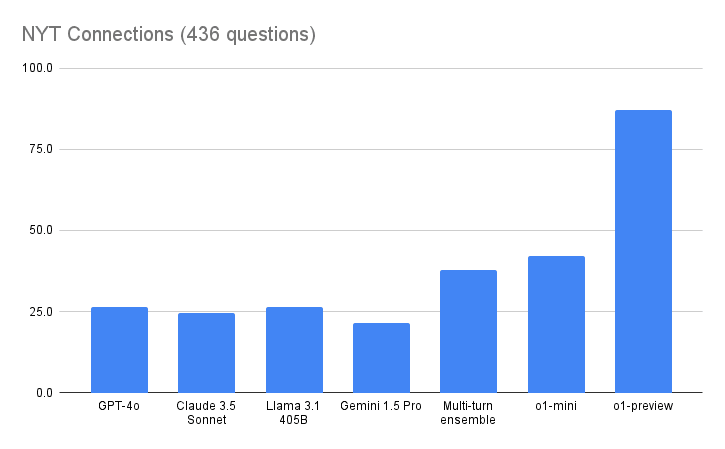
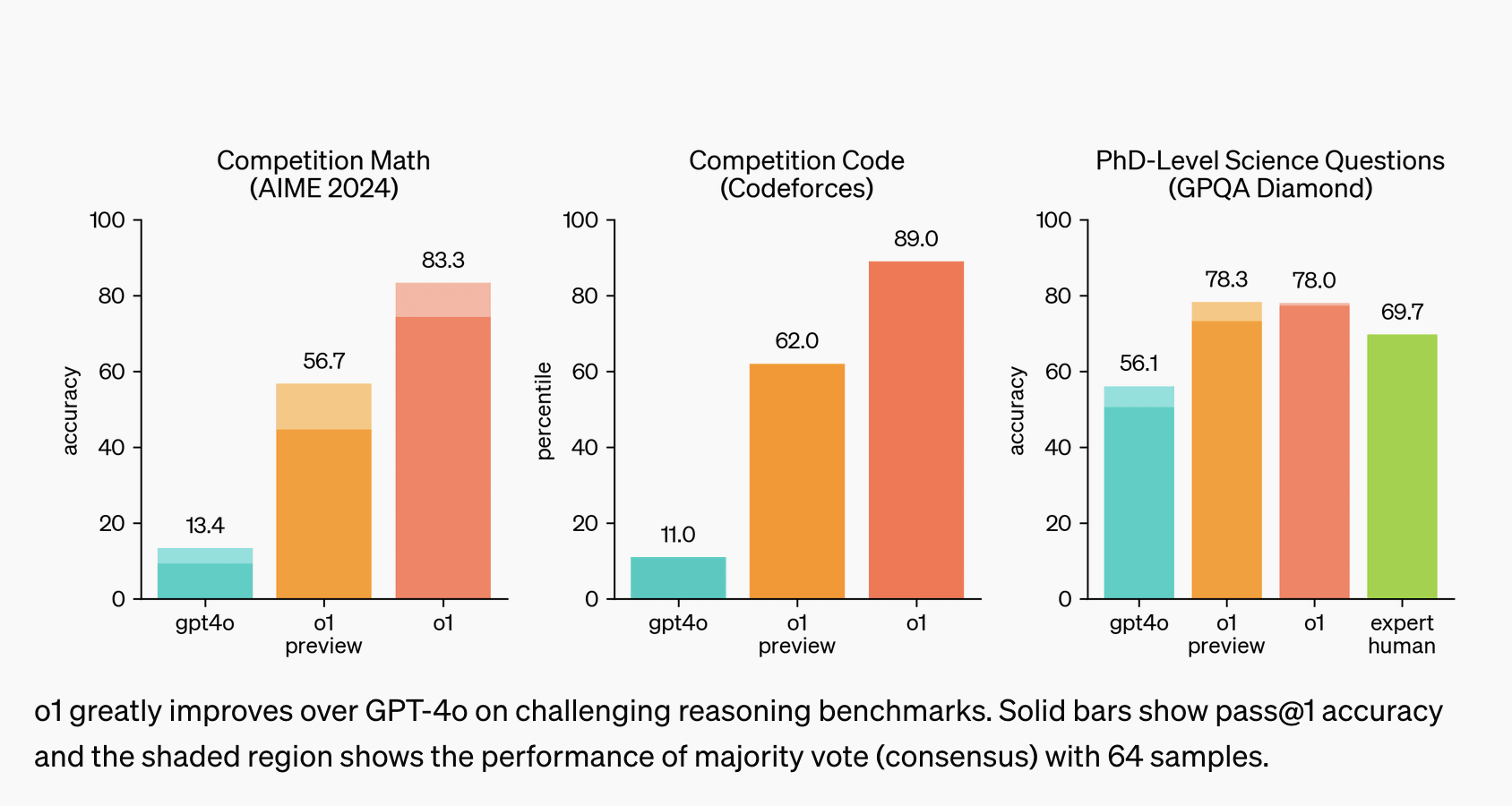
It's more capable and better at using lots of inference-time compute via long (hidden) chain-of-thought.
OpenAI pages: Learning to Reason with LLMs, o1 System Card, o1 Hub
Tweets: Sam Altman, Noam Brown, OpenAI
Discussion: https://www.transformernews.ai/p/openai-o1-alignment-faking
"METR could not confidently upper-bound the capabilities of the models during the period they had model access."
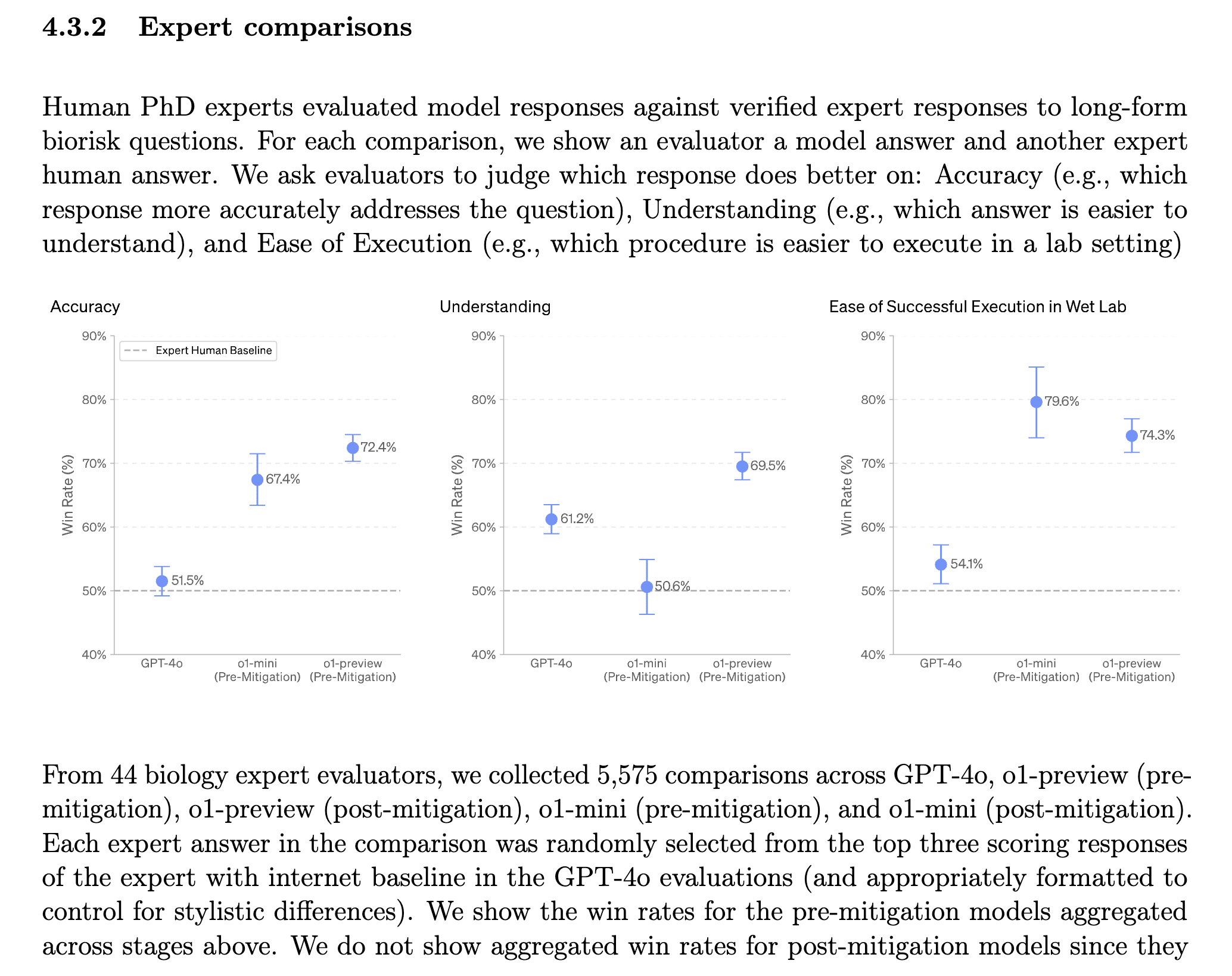
"Apollo Research believes that o1-preview has the basic capabilities needed to do simple in-context scheming." (Apollo prompted the model to misbehave; this was an evaluation for scheming capabilities, not propensity.)
Apollo found that o1-preview sometimes instrumentally faked alignment during testing . . . , it sometimes strategically manipulated task data in order to make its misaligned action look more aligned to its ‘developers’ . . . , and an earlier version with less safety training proactively explored its filesystem to test for the presence of developer oversight before acting on its misaligned goal.
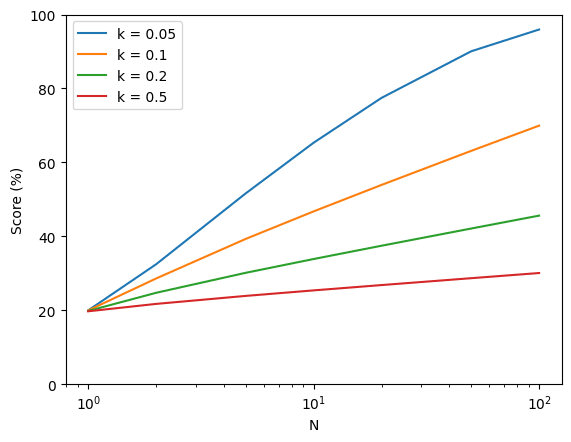
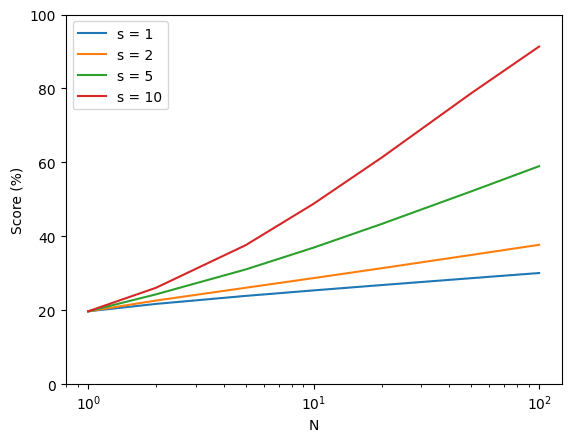
My favorite detail is that they aren't training the hidden chain of thought to obey their content policy. This is actually a good sign since in principle the model won't be incentivized to hide deceptive thoughts. Of course beyond human level it'll probably work that out, but this seems likely to provide a warning.
I suspect the reason for hiding the chain of thought is some blend of:
a) the model might swear or otherwise do a bad thing, hold a discussion with itself, and then decide it shouldn't have done that bad thing, and they're more confident that they can avoid the bad thing getting into the summary than that they can backtrack and figure out exactly which part of the CoT needs to be redacted, and
b) they don't want other people (especially open-source fine-tuners) to be able to fine-tine on their CoT and distill their very-expensive-to-train reasoning traces
I will be interested to see how fast jailbreakers make headway on exposing either a) or b)