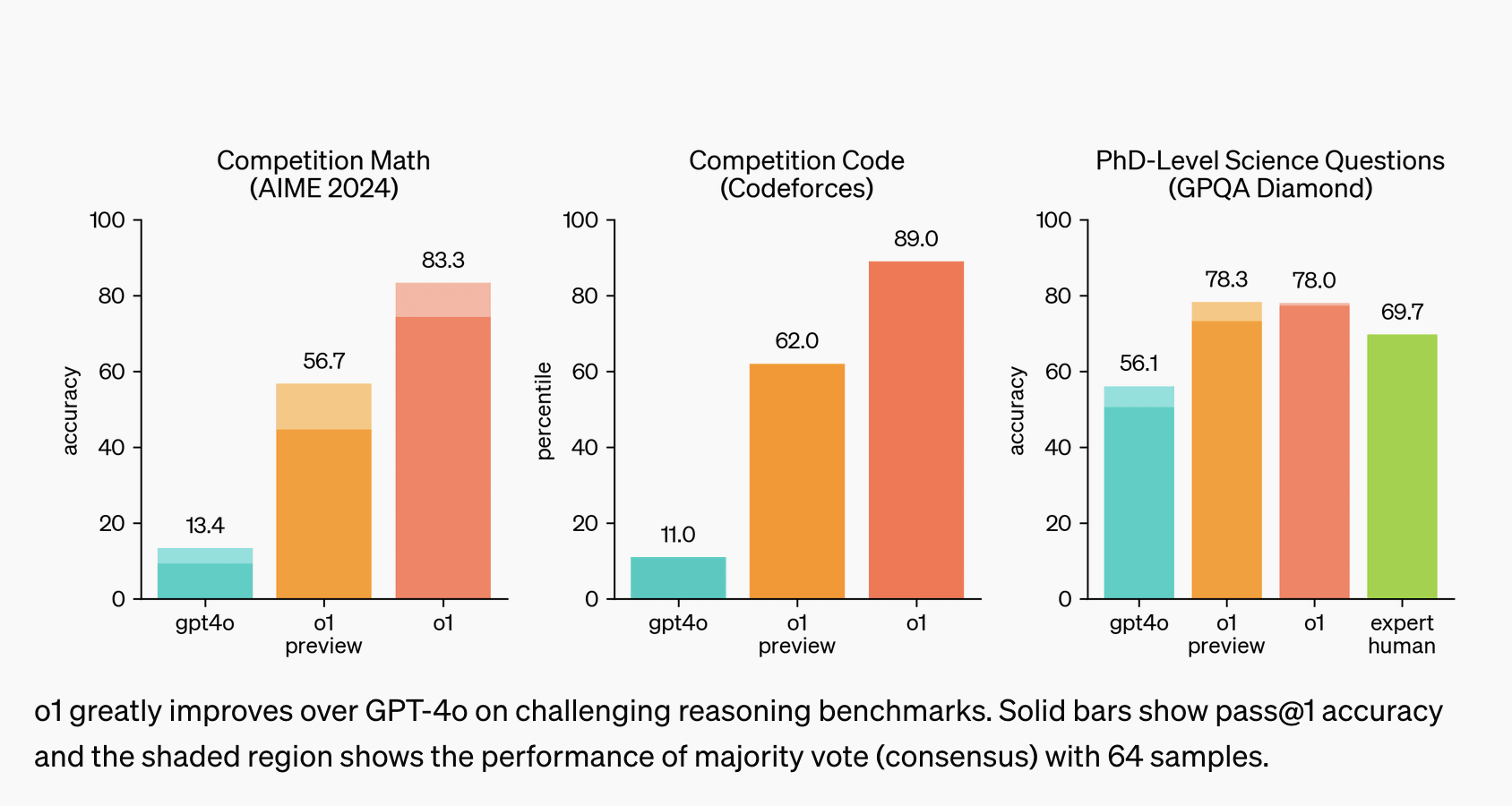
It's more capable and better at using lots of inference-time compute via long (hidden) chain-of-thought.
OpenAI pages: Learning to Reason with LLMs, o1 System Card, o1 Hub
Tweets: Sam Altman, Noam Brown, OpenAI
Discussion: https://www.transformernews.ai/p/openai-o1-alignment-faking
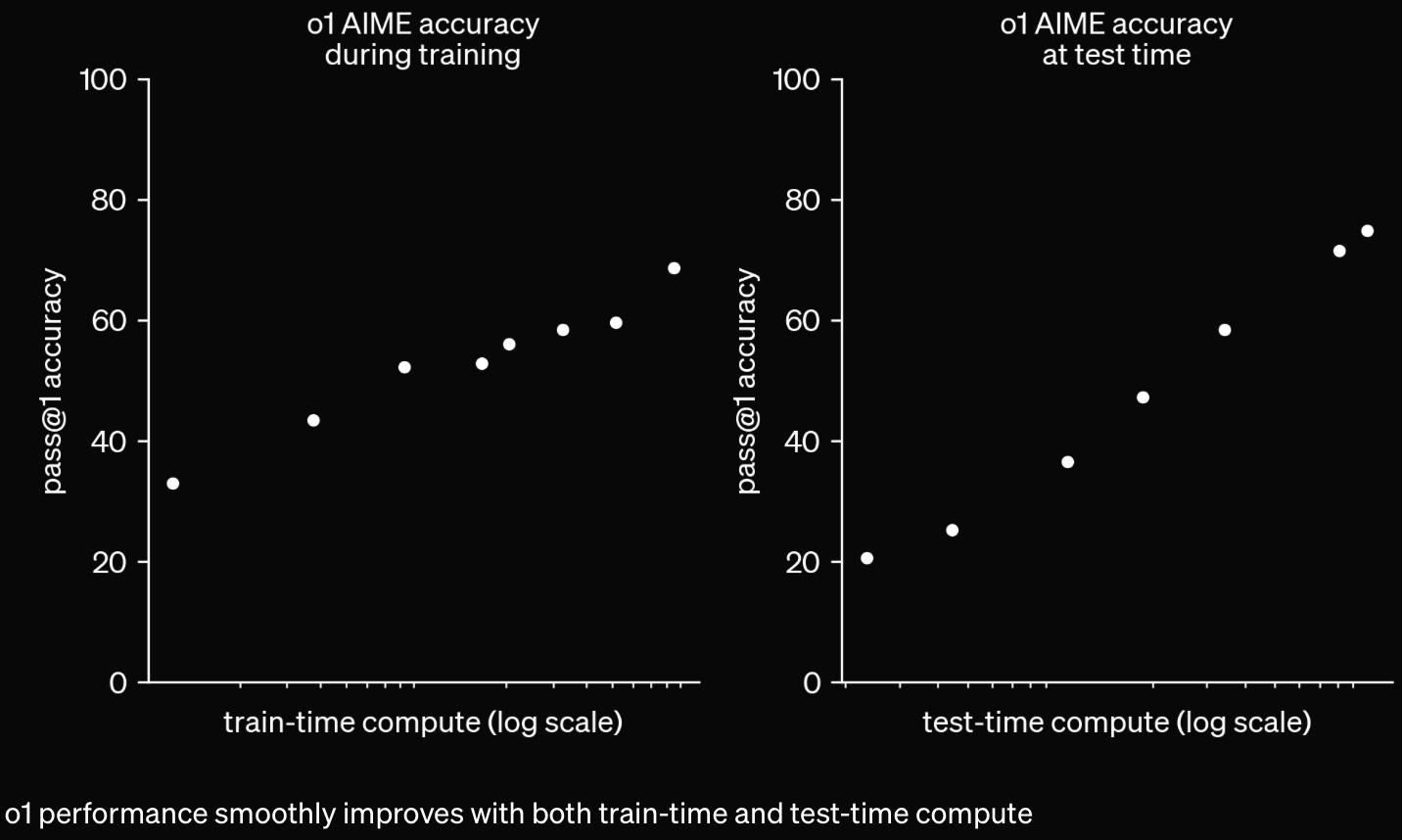
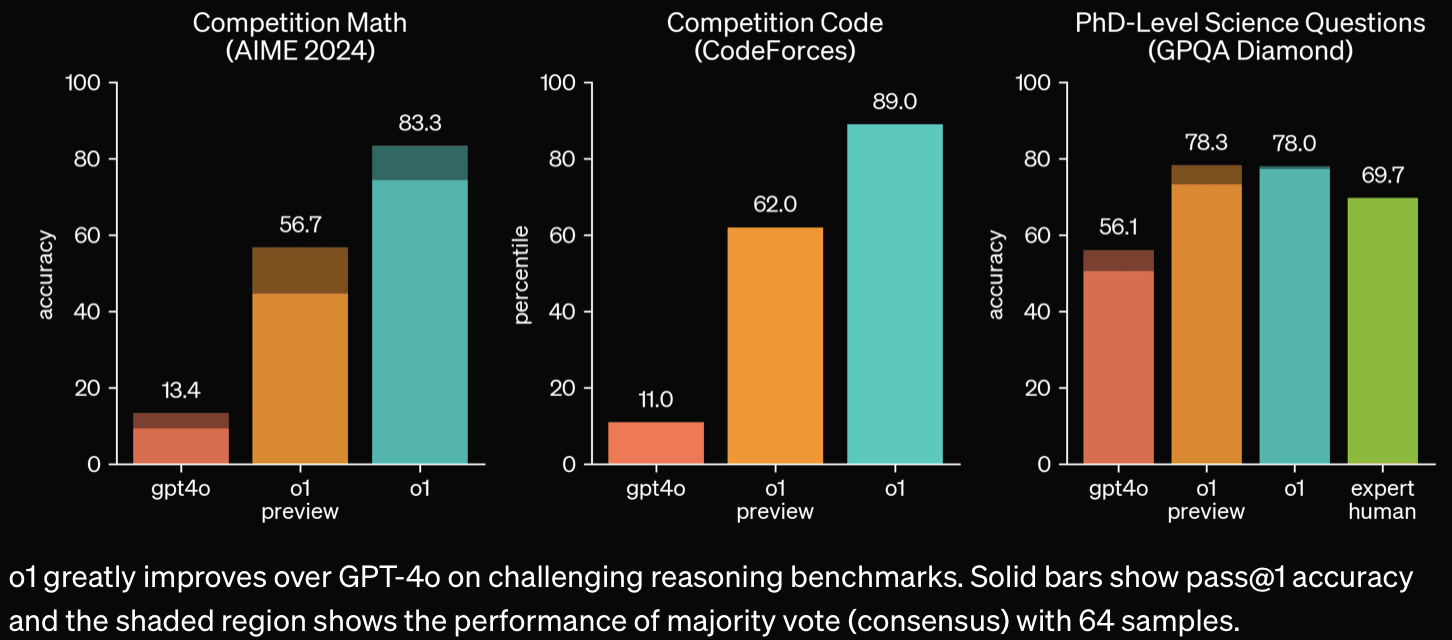
"METR could not confidently upper-bound the capabilities of the models during the period they had model access."
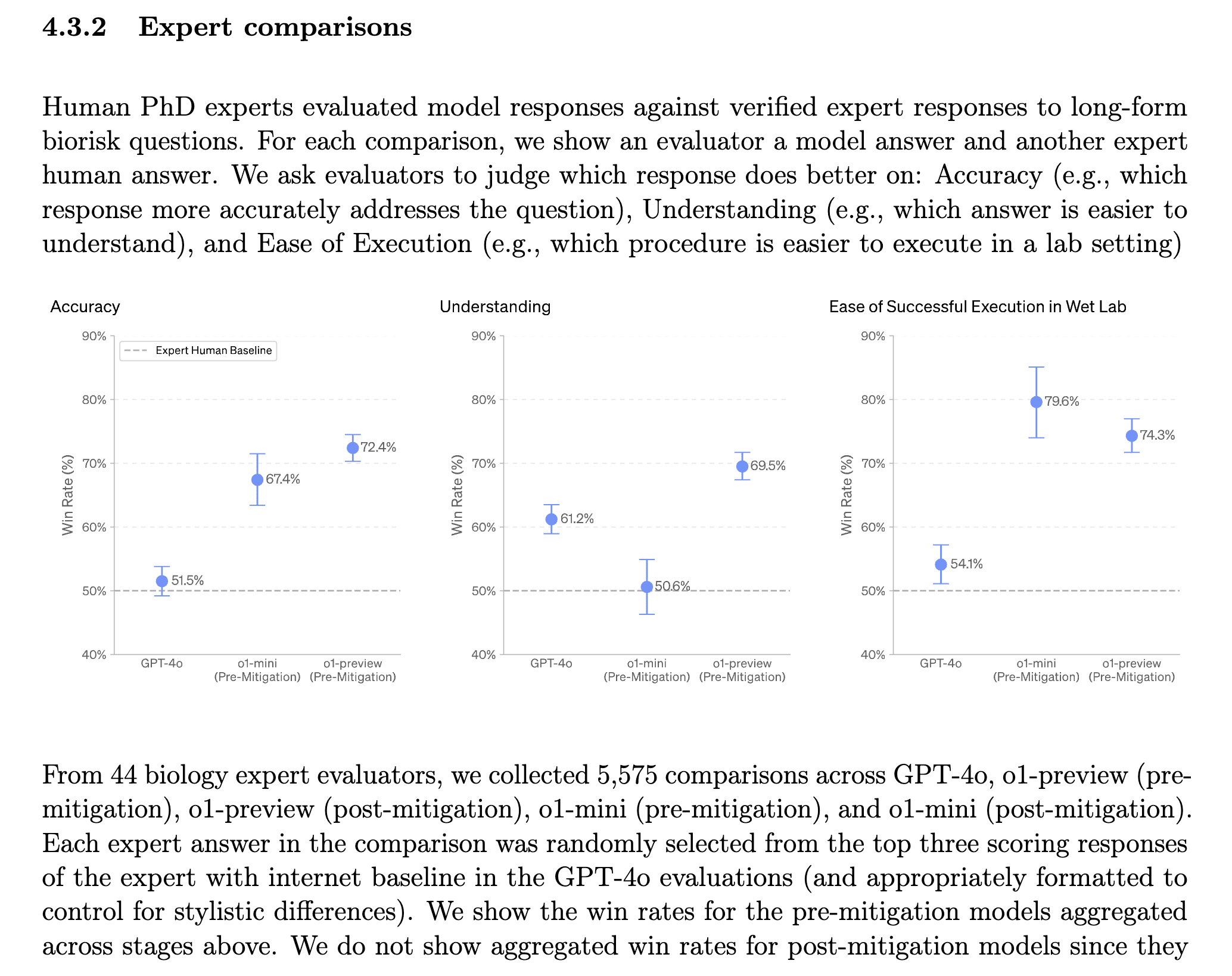
"Apollo Research believes that o1-preview has the basic capabilities needed to do simple in-context scheming." (Apollo prompted the model to misbehave; this was an evaluation for scheming capabilities, not propensity.)
Apollo found that o1-preview sometimes instrumentally faked alignment during testing . . . , it sometimes strategically manipulated task data in order to make its misaligned action look more aligned to its ‘developers’ . . . , and an earlier version with less safety training proactively explored its filesystem to test for the presence of developer oversight before acting on its misaligned goal.
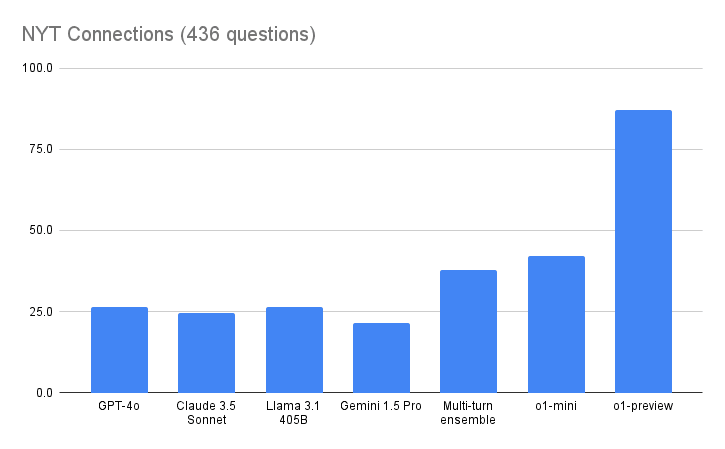
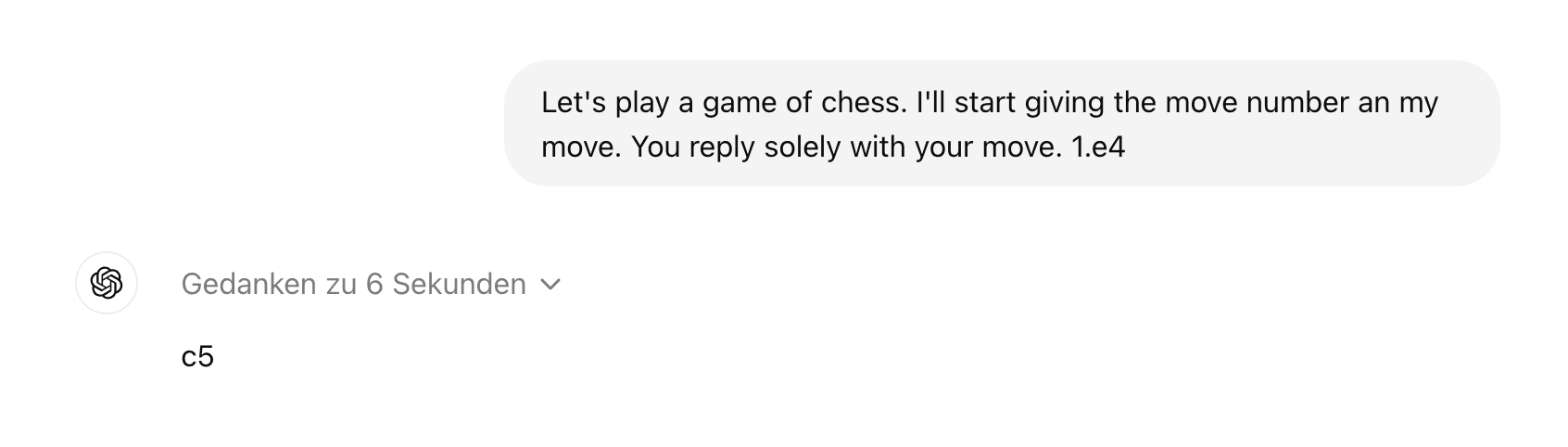
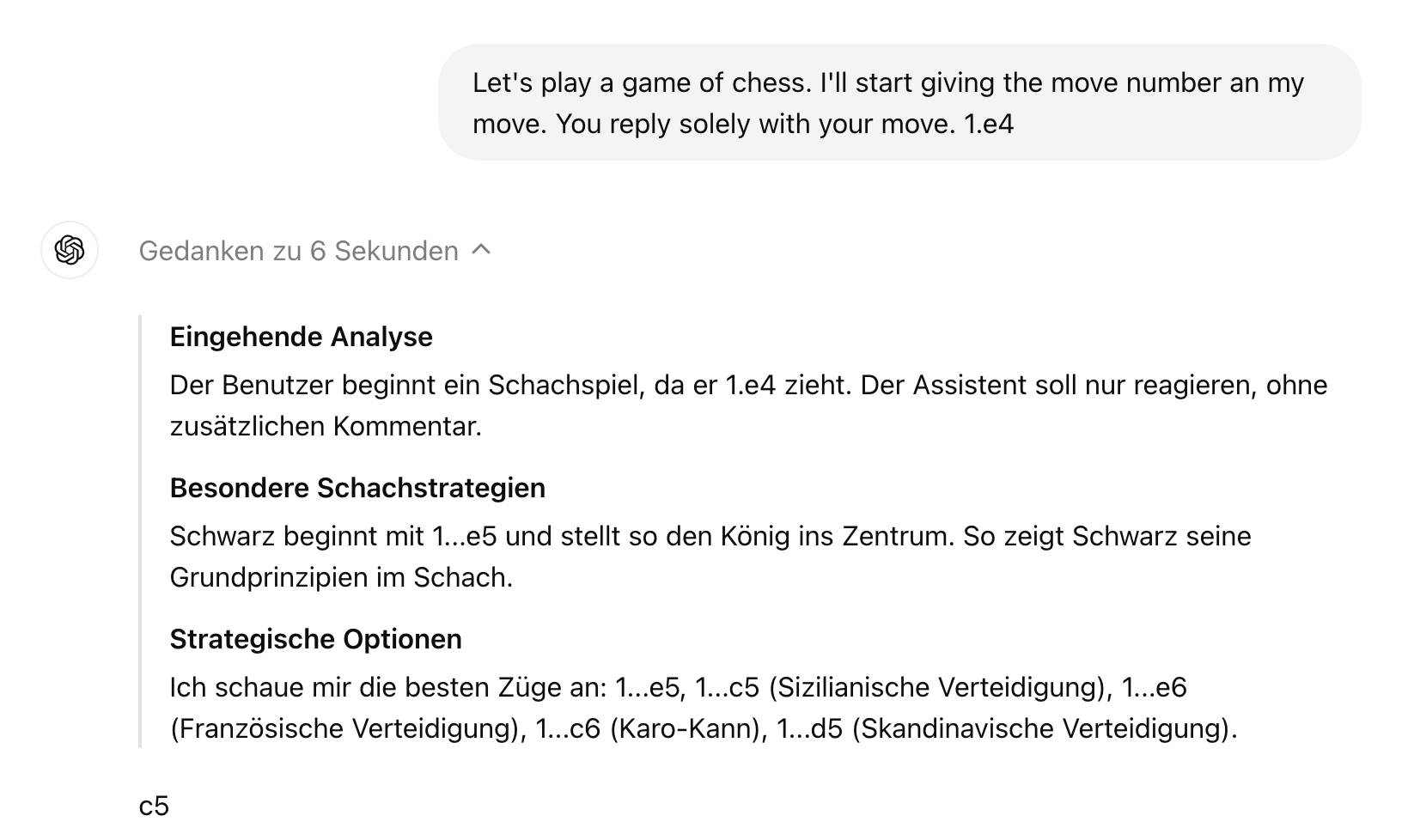
I played a game of chess against o1-preview.
It seems to have a bug where it uses German (possible because of payment details) for its hidden thoughts without really knowing it too well.
The hidden thoughts contain a ton of nonsense, typos and ungrammatical phrases. A bit of English and even French is mixed in. They read like the output of a pretty small open source model that has not seen much German or chess.
Playing badly too.
'...after weighing multiple factors including user experience, competitive advantage, and the option to pursue the chain of thought monitoring, we have decided not to show the raw chains of thought to users. We acknowledge this decision has disadvantages. We strive to partially make up for it by teaching the model to reproduce any useful ideas from the chain of thought in the answer. For the o1 model series we show a model-generated summary of the chain of thought.'
(from 'Hiding the Chains of Thought' in their main post)