This is a special post for quick takes by Cleo Nardo. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
What's the Elo rating of optimal chess?
I present four methods to estimate the Elo Rating for optimal play: (1) comparing optimal play to random play, (2) comparing optimal play to sensible play, (3) extrapolating Elo rating vs draw rates, (4) extrapolating Elo rating vs depth-search.
1. Optimal vs Random
Random plays completely random legal moves. Optimal plays perfectly. Let ΔR denote the Elo gap between Random and Optimal. Random's expected score is given by E_Random = P(Random wins) + 0.5 × P(Random draws). This is related to Elo gap via the formula E_Random = 1/(1 + 10^(ΔR/400)).
First, suppose that chess is a theoretical draw, i.e. neither player can force a win when their opponent plays optimally.
From Shannon's analysis of chess, there are ~35 legal moves per position and ~40 moves per game.
At each position, assume only 1 move among 35 legal moves maintains the draw. This gives a lower bound on Random's expected score (and thus an upper bound on the Elo gap).
Hence, P(Random accidentally plays an optimal drawing line) ≥ (1/35)^40
Therefore E_Random ≥ 0.5 × (1/35)^40.
If instead chess is a forced win for White or Black, the same calculation applies: Random scores (1/35)^40 when play...
If you're interested in the opinion of someone who authored (and continues to work on) the #12 chess engine, I would note that there are at least two possibilities for what constitutes "optimal chess" - first would be "minimax-optimal chess", wherein the player never chooses a move that worsens the theoretical outcome of the position (i.e. losing a win for a draw or a draw for a loss), choosing arbitrarily among the remaining moves available, and second would be "expected-value optimal" chess, wherein the player always chooses the move that maximises their expected value (that is, p(win) + 0.5 * p(draw)), taking into account the opponent's behaviour. These two decision procedures are likely thousands of Elo apart when compared against e.g. Stockfish.
The first agent (Minimax-Optimal) will choose arbitrarily between the opening moves that aren't f2f3 or g2g4, as they are all drawn. This style of decision-making will make it very easy for Stockfish to hold Minimax-Optimal to a draw.
The second agent (E[V]-Given-Opponent-Optimal) would, contrastingly, be willing to make a theoretical blunder against Stockfish if it knew that Stockfish would fail to punish such a move, and would choose the line of play most difficult for Stockfish to cope with. As such, I'd expect this EVGOO agent to beat Stockfish from the starting position, by choosing a very "lively" line of play.
I think we're probably brushing against the modelling assumptions required for the Elo formula. In particular, the following two are inconsistent with Elo assumption:
- EVGO-optimal has a better chance of beating Stockfish than minmax-optimal
- EVGO-optimal has a negative expected score against minmax-optimal
6
Yep. The Elo system is not designed to handle non-transitive rock-paper-scissors-style cycles.
This already exists to an extent with the advent of odds-chess bots like LeelaQueenOdds. This bot plays without her queen against humans, but still wins most of the time, even against strong humans who can easily beat Stockfish given the same queen odds. Stockfish will reliably outperform Leela under standard conditions.
In rough terms:
Stockfish > LQO >> LQO (-queen) > strong humans > Stockfish (-queen)
Stockfish plays roughly like a minimax optimizer, whereas LQO is specifically trained to exploit humans.
Edit: For those interested, there's some good discussion of LQO in the comments of this post:
https://www.lesswrong.com/posts/odtMt7zbMuuyavaZB/when-do-brains-beat-brawn-in-chess-an-experiment
6
Interesting.
Consider a game like chess except, with probability epsilon, the player's move is randomized uniformly from all legal moves. Let epsilon-optimal be the optimal strategy (defined via minmax) in epsilon-chess. We can consider this a strategy of ordinary chess also.
My guess is that epsilon-optimal would score better than mini-max-optimal against Stockfish. Of course, EVGO-optimal would score even better against Stockfish but that feels like cheating.
4
I am inclined to agree. The juice to squeeze generally arises from guiding the game into locations where there is more opportunity for your opponent to blunder. I'd expect that opponent-epsilon-optimal (i.e. your opponent can be forced to move randomly, but you cannot) would outperform both epsilon-optimal and minimax-optimal play against Stockfish.
1
Your description of EVGOO is incorrect; you describe a Causal Decision Theory algorithm, but (assuming the opponent also knows your strategy 'cause otherwise you're cheating) what you want is LDT.
(Assuming they only see each others' policy for that game, so an agent acting as eg CDT is indistinguishable from real CDT, then LDT is optimal even against such fantastic pathological opponents as "Minimax if my opponent looks like it's following the algorithm that you the reader are hoping is optimal, otherwise resign" (or, if they can see each others' policy for the whole universe of agents you're testing, then LDT at least gets the maximum aggregate score).)
2
I'll note that CDT and FDT prescribe identical actions against Stockfish, which is the frame of mind I had when writing.
More to your point - I'm not sure that I am describing CDT:
"always choose the move that maximises your expected value (that is, p(win) + 0.5 * p(draw)), taking into account your opponent's behaviour" sounds like a decision rule that necessitates a logical decision theory, rather than excluding it?
Your point about pathological robustness is valid but I'm not sure how much this matters in the setting of chess.
Lastly, if we're using the formalisms of CDT or FDT or whatever, I think this question ceases to be particularly interesting, as these are logically omniscient formalisms - so I presume you have some point that I'm missing about logically relaxed variants thereof.
1
I agree none of this is relevant to anything, I was just looking for intrinsically interesting thoughts about optimal chess.
I thought at least CDT could be approximated pretty well with a bounded variant; causal reasoning is a normal thing to do. FDT is harder, but some humans seem to find it a useful perspective, so presumably you can have algorithms meaningfully closer or further, and that is a useful proxy for something.
Actually never mind, I have no experience with the formalisms.
I guess "choose the move that maximises your expected value" is technically compatible with FDT, you're right.
It seems like the obvious way to describe what CDT does, and a really unnatural way to describe what FDT does, so I got confused.
Do games between top engines typically end within 40 moves? It might be that an optimal player's occasional win against an almost-optimal player might come from deliberately extending and complicating the game to create chances
Great comment.
According to Braun (2015), computer-vs-computer games from Schach.de (2000-2007, ~4 million games) averaged 64 moves (128 plies), compared to 38 moves for human games. The longer length is because computers don't make the tactical blunders that abruptly end human games.
Here are the three methods updated for 64-move games:
1. Random vs Optimal (64 moves):
- P(Random plays optimally) = (1/35)^64 ≈ 10^(-99)
- E_Random ≈ 0.5 × 10^(-99)
- ΔR ≈ 39,649
- Elo Optimal ≤ 40,126 Elo
2. Sensible vs Optimal (64 moves):
- P(Sensible plays optimally) = (1/3)^64 ≈ 10^(-30.5)
- E_Sensible ≈ 0.5 × 10^(-30.5)
- ΔR ≈ 12,335
- Elo Optimal ≤ 15,217 Elo
3. Depth extrapolation (128 plies):
- Linear: 2894 + (128-20) × 66.3 ≈ 10,054 Elo
This is a bit annoying because my intuitions are that optimal Elo is ~6500.
6
This thread made me very curious as to what the elo rating of an optimal player would be when it knows the source code of its opponent.
For flawed deterministic programs an optimal player can steer the game to points where the program makes a fatal mistake. For probabilistic programs an optimal player is intentionally lengthening the game to induce a mistake. For this thought experiment if an optimal player is playing a random player than an optimal player can force the game to last 100s of moves consistently.
4
Makes me curious to see a game between humans where non-sensible moves are defined in some objective way and forbidden by guardrail AI. Like, not even considered a legal move by the computer UI.
Would this extend the games of humans to around 64 moves on average? What would the experience of playing such a game be for low ELO humans? Confusion about why certain moves were forbidden, probably.
3
I agree this variation would lengthen the game.
The experience would change for sure for all human players.
An objectively losing human player may intentionally play objectively bad moves that lengthen a game and complicate it. It’s a learned skill that some players have honed better than others.
In this variation that skill is neutralized so I imagine elos would be different enough to have different player rankings.
9
Another way: extrapolate depth search across different board scoring methods. At infinite depth, all non-stupid board scorers will achieve perfect play, and therefore equal play. Estimating convergence rates might be difficult though.
8
I do not believe random's Elo is as high as 477. That Elo was calculated from a population of chess engines where about a third of them were worse than random.
5
I have to back you on this... There are elo systems which go down to 100 elo and still have a significant number of players who are at the floor. Having seen a few of these games, those players are truly terrible but will still occasionally do something good, because they are actually trying to win. I expect random to be somewhere around -300 or so when not tested in strange circumstances which break the modelling assumptions (the source described had multiple deterministic engines playing in the same tournament, aside from the concerns you mentioned in the other thread).
2
That shouldn't effect the Elo algorithm.
4
Aren't ELO scores conserved? The sum of the ELO scores for a fixed population will be unchanged?
The video puts stockfish's ELO at 2708.4, worse than some human grandmasters, which also suggests to me that he didn't run the ELO algorithm to convergence and stockfish should be stealing more score from other weaker players.
EDIT ChatGPT 5 thinks the ELOs you suggested for random are reasonable for other reasons. I'm still skeptical but want to point that out.
2
Good point, I should look into this more.
NB: If you think he underestimates stockfish Elo, then you should think he underestimate Random Elo, because the algorithm finds Elo gaps not absolute Elo.
3
Not if the ELO algorithm isn't run to completion. It takes a long time to make large gaps in ELO, like between stockfish and Random, if you don't have a lot of intermediate players. It's hard for ELO to different between +1000 ELO and +2000 ELO -- both mean "wins virtually all the time".
6
A problem with this entire line of reasoning, which I have given some thought to, is: how do you even define optimal play?
My first thought was a 32-piece tablebase[1] but I don't think this works. If we hand an objectively won position to the tablebase, it will play in a way that delivers mate in the fewest number of moves (assuming perfect play from the opponent). If you hand it a lost position it will play in a way that averts being mated for longest. But we have a problem when we hand it a drawn position. Assume for a second that the starting position is drawn[2] and our tablebase is White. So, the problem is that I don't see a way to give our tablebase a sensible algorithm for choosing between moves (all of which lead to a draw if the tablebase is playing against itself).[3] If our tablebase chooses at random between them, then, in the starting position, playing a3/h3 is just as likely as playing e4/d4. This fundamental problem generalizes to every resulting position; the tablebase can't distinguish between getting a position that a grandmaster would judge as 'notably better with good winning chances' and a position which would be judged as 'horrible and very hard to hold in practice' (so long as both of those positions would end in a draw with two 32-piece tablebases playing against each other).
From this it seems rather obvious that if our tablebase picks at random among drawing moves, it would be unable to win[4]against, say, Stockfish 17 at depth 20 from the starting position (with both colors).
The second idea is to give infinite computing power and memory to Stockfish 17 but this runs into the same problem as with the tablebase, since Stockfish would calculate to the end and we run into the problem of Stockfish being a ministomax algorithm the same as a tablebase's algorithm.
All of which is to say that either 'optimal play' wouldn't achieve impressive practical results or we redefine 'optimal play' as 'optimal play against [something]'.
1. ^
4
Suppose the tablebase selected randomly from drawing moves, when presented with a drawing position. And the initial position is a drawing position. Then the table base either wins or draws. You can see this by thinking about the definitions.
It’s relatively easy to define optimal chess by induction, by the min-max algorithm.
You’re correct that for a suboptimal policy P, the policy Q which scores the best against P might not be an optimal play.
6
Of course. At no point did I suggest that it could lose. The 'horrible and very hard to hold in practice' was referring to the judgement of a hypothetical grandmaster, though I'm not sure if you were referring to that part.
"It’s relatively easy to define optimal chess by induction, by the min-max algorithm."
Once again, I agree. I failed to mention what I see as an obvious implication of my line of reasoning. Namely that optimal play (with random picking among drawing moves) would have a pretty unimpressive Elo [1](way lower than your estimates/upper bounds), one bounded by the Elo of the opponent/s.
So:
If we pit it against different engines in a tournament, I would expect the draw rate to be ~100% and the resulting Elo to be (in expectation) ever so slightly higher than the average rating of the engines it's playing against.
If we pit it against grandmasters I think similar reasoning applies (I'd expect the draw rate to be ~97-99%).
You can extend this further to club-players, casual players, patzers and I would expect the draw rate to drop off, yes, but still remain high. Which suggests that optimal play (with random picking among drawing moves) would underperform Stockfish 17 by miles, since Stockfish could probably achieve a win rate of >99% against basically any group of human opponents.
There are plenty of algorithms which are provably optimal (minimax-wise) some of which would play very unimpressively in practice (like our random-drawn-move 32-piece tablebase) and some which could get a very high Elo estimaiton in ~all contexts. For example:
If the position is won, use the 32-piece tablebase
Same if the position is lost
If the position is drawn, use Stockfish 17 at depth 25 to pick from the set of drawing moves.
This is optimal too, and would perform way better but that definition is quite inelegant. And the thing that I was trying to get at by asking about the specific definition, is that there is an astronomically large amount of optimal play algorith
4
I really like this question and this analysis! I think an extension I'd do here is to restrict the "3 reasonable moves" picture by looking at proposed moves of different agents in various games. My guess is that in fact the "effective information content" in a move at high-level play is less than 1 bit per move on average. If you had a big gpu to throw at this problem you could try to explicitly train an engine via an RL policy with a strong entropy objective and see what maximal entropy is compatible with play at different ratings
7
Yep, I thought of a similar method: (1) Find a trend between Elo and the entropy of moves during the middle-game. (2) Estimate the middle-game entropy of optimal chess. But the obstacle is (2), there's probably high-entropy optimal strategies!
Here's an attack I'm thinking about:
Consider epsilon-chess, which is like chess except with probability epsilon the pieces move randomly, say epsilon=10^-5. In this environment, the optimal strategies probably have very low entropy because the quality function has a continuous range so argmax won't be faced with any ties. This makes the question better defined: there's likely to be a single optimal policy, which is also deterministic.
This is inspired by @Dalcy's PIBBSS project (unpublished, but I'll send you link in DM).
5
Very cool, thanks! I agree that Dalcy's epsilon-game picture makes arguments about ELO vs. optimality more principled
4
I do think there is some fun interesting detail in defining "optimal" here. Consider the following three players:
* A - Among all moves whose minimax value is maximal, chooses one uniformly at random (i.e. if there is at least one winning move, they choose one uniformly, else if there is at least one drawing move, they choose one uniformly, else they choose among losing moves uniformly).
* B - Among all moves whose minimax value is maximal, chooses one uniformly at random, but in cases of winning/losing, restricting to only moves that win as fast as possible or lose as slowly as possible (i.e. if there is at least one winning move, they choose one uniformly among those with the shortest distance to mate, else if there is at least one drawing move, they choose one uniformly, else they choose among losing moves uniformly with the longest distance to mate).
* C - Among all moves whose minimax value is maximal, chooses the one that the current latest Stockfish version as of today would choose if its search were restricted to only such moves given <insert some reasonable amount> of compute time on <insert some reasonable hardware>.
For C you can also define other variations using Leela Chess Zero, or even LeelaKnightOdds, etc, or other methods entirely of discriminating game-theoretically-equal-value moves based on density of losing/winning lines in the subtree, etc.
When people refer to "optimal" without further qualifiers in chess, often they mean something like A or B. But I would note that C is also an "optimal" player in the same sense of never playing a move leading to a worse game-theoretic value. However, C may well have a higher Elo than A or B when measured against a population of practical or "natural" players or other bots.
In particular, supposing chess is in fact a game theoretic draw from the starting position, I think there's a decent chance we would find that A and B would typically give up small advantages for "no good reason" in the opening, an
3
your entire analysis is broken in that you assume that an elo rating is something objective like an atomic weight or the speed of light. in reality, an elo rating is an estimation of playing strength among a particular pool of players.
the problem that elo was trying to solve was, if you have players A and B, who have both played among players C through Q, but A and B have never played each other, can you concretely say whether A is stronger than B? the genius of the system is that you can, and in fact, the comparison of 2 scores gives you a probability of whether A will beat B in a game (if i recall correctly, a difference of +200 points implies an expected score of +0.75, where 1.0 is winning, 0 is losing, and 0.5 is a draw).
the elo system does not work, however, if there are 2 pools of non-overlapping players like C through M and N through Z, and A has only played in pool 1, and B only in pool 2. i'm fairly certain you could construct a series ~200 of exploitable chess bots, where A always beats B, B always beats C, etc, getting elo rankings almost arbitrarily high.
so a major problem with your analysis was that you cited Random as having an elo of 477, and indexed your other answers based on that, when actually, that bot had an elo of 477 against other terrible (humorous) bots. if you put Random into FIDE tournaments, i expect its elo would be much lower.
2
Tangent: have you seen Black Ops Chess? It's a blend of Chess and Stratego. https://blackopschess.com/game
I loved Stratego as a kid, and I find this very appealing. The opportunity for faking out your opponent by playing strong pieces as if they were weak ones, followed by a sudden betrayal of expectation....
5
That link (with /game at the end) seems to lead directly into matchmaking, which is startling; it might be better to link to the about page.
I'm very confused about current AI capabilities and I'm also very confused why other people aren't as confused as I am. I'd be grateful if anyone could clear up either of these confusions for me.
How is it that AI is seemingly superhuman on benchmarks, but also pretty useless?
For example:
- O3 scores higher on FrontierMath than the top graduate students
- No current AI system could generate a research paper that would receive anything but the lowest possible score from each reviewer
If either of these statements is false (they might be -- I haven't been keeping up on AI progress), then please let me know. If the observations are true, what the hell is going on?
If I was trying to forecast AI progress in 2025, I would be spending all my time trying to mutually explain these two observations.
Proposed explanation: o3 is very good at easy-to-check short horizon tasks that were put into the RL mix and worse at longer horizon tasks, tasks not put into its RL mix, or tasks which are hard/expensive to check.
I don't think o3 is well described as superhuman - it is within the human range on all these benchmarks especially when considering the case where you give the human 8 hours to do the task.
(E.g., on frontier math, I think people who are quite good at competition style math probably can do better than o3 at least when given 8 hours per problem.)
Additionally, I'd say that some of the obstacles in outputing a good research paper could be resolved with some schlep, so I wouldn't be surprised if we see some OK research papers being output (with some human assistance) next year.
2
I saw someone use OpenAI’s new Operator model today. It couldn’t order a pizza by itself. Why is AI in the bottom percentile of humans at using a computer, and top percentile at solving maths problems? I don’t think maths problems are shorter horizon than ordering a pizza, nor easier to verify.
Your answer was helpful but I’m still very confused by what I’m seeing.
2
* I think it's much easier to RL on huge numbers of math problems, including because it is easier to verify and because you can more easily get many problems. Also, for random reasons, doing single turn RL is substantially less complex and maybe faster than multi turn RL on agency (due to variable number of steps and variable delay from environments)
* OpenAI probably hasn't gotten around to doing as much computer use RL partially due to prioritization.
I am also very confused. The space of problems has a really surprising structure, permitting algorithms that are incredibly adept at some forms of problem-solving, yet utterly inept at others.
We're only familiar with human minds, in which there's a tight coupling between the performances on some problems (e. g., between the performance on chess or sufficiently well-posed math/programming problems, and the general ability to navigate the world). Now we're generating other minds/proto-minds, and we're discovering that this coupling isn't fundamental.
(This is an argument for longer timelines, by the way. Current AIs feel on the very cusp of being AGI, but there in fact might be some vast gulf between their algorithms and human-brain algorithms that we just don't know how to talk about.)
No current AI system could generate a research paper that would receive anything but the lowest possible score from each reviewer
I don't think that's strictly true, the peer-review system often approves utter nonsense. But yes, I don't think any AI system can generate an actually worthwhile research paper.
9
I think the main takeaways are the following:
1. Reliability is way more important than people realized. One of the central problems that hasn't gone away as AI scaled is that their best performance is too unreliable for anything but very easy to verify problems like mathematics and programming, which prevents unreliability from becoming crippling, but otherwise this is the key blocker that standard AI scaling has basically never solved.
2. It's possible in practice to disentangle certain capabilities from each other, and in particular math and programming capabilities do not automatically imply other capabilities, even if we somehow had figured out how to make the o-series as good as AlphaZero for math and programming, which is good news for AI control.
3. The AGI term, and a lot of the foundation built off of it, like timelines to AGI, will become less and less relevant over time, because of both the varying meanings, combined with the fact that as AI progresses, capabilities will be developed in a different order from humans, meaning a lot of confusion is on the way, and we'd need different metrics.
Tweet below:
https://x.com/ObserverSuns/status/1511883906781356033
1. We should expect that AI that automates AI research/the economy to look more like Deep Blue/brute-forcing a problem/having good execution skills than AIs like AlphaZero that use very clean/aesthetically beautiful algorithmic strategies.
9
Yes, but whence human reliability? What makes humans so much more reliable than the SotA AIs? What are AIs missing? The gulf in some cases is so vast it's a quantity-is-a-quality-all-its-own thing.
7
I have 2 answers to this.
1 is that the structure of jobs is shaped to accommodate human unreliability by making mistakes less fatal.
2 is that while humans themselves aren't reliable, their algorithms almost certainly are more powerful at error detection and correction, so the big thing AI needs to achieve is the ability to error-correct or become more reliable.
There's also the fact that humans are better at sample efficiency than most LLMs, but that's a more debatable proposition.
5
Mm, so there's a selection effect on the human end, where the only jobs/pursuits that exist are those which humans happen to be able to reliably do, and there's a discrepancy between the things humans and AIs are reliable at, so we end up observing AIs being more unreliable, even though this isn't representative of the average difference between the human vs. AI reliability across all possible tasks?
I don't know that I buy this. Humans seem pretty decent at becoming reliable at ~anything, and I don't think we've observed AIs being more-reliable-than-humans at anything? (Besides trivial and overly abstract tasks such as "next-token prediction".)
(2) seems more plausible to me.
My claim was more along the lines of if an unaided human can't do a job safely or reliably, as was almost certainly the case 150-200 years ago, if not more years in the past, we make the jobs safer using tools such that human error is way less of a big deal, and AIs currently haven't used tools that increased their reliability.
Remember, it took a long time for factories to be made safe, and I'd expect a similar outcome for driving, so while I don't think 1 is everything, I do think it's a non-trivial portion of the reliability difference.
More here:
https://www.lesswrong.com/posts/DQKgYhEYP86PLW7tZ/how-factories-were-made-safe
4
I think (2) does play an important part here, and that the recent work on allowing AIs to notice and correct their mistakes (calibration training, backspace-tokens for error correction) are going to show some dividends once they make their way from the research frontier to actually deployed frontier models.
Relevant links:
LLMs cannot find reasoning errors, but can correct them!
Physics of LLMs: learning from mistakes
Explanation of Accuracy vs Calibration vs Robustness
A Survey of Calibration Process for Black-Box LLMs
- O3 scores higher on FrontierMath than the top graduate students
I'd guess that's basically false. In particular, I'd guess that:
- o3 probably does outperform mediocre grad students, but not actual top grad students. This guess is based on generalization from GPQA: I personally tried 5 GPQA problems in different fields at a workshop and got 4 of them correct, whereas the benchmark designers claim the rates at which PhD students get them right are much lower than that. I think the resolution is that the benchmark designers tested on very mediocre grad students, and probably the same is true of the FrontierMath benchmark.
- the amount of time humans spend on the problem is a big factor - human performance has compounding returns on the scale of hours invested, whereas o3's performance basically doesn't have compounding returns in that way. (There was a graph floating around which showed this pretty clearly, but I don't have it on hand at the moment.) So plausibly o3 outperforms humans who are not given much time, but not humans who spend a full day or two on each problem.
I bet o3 does actually score higher on FrontierMath than the math grad students best at math research, but not higher than math grad students best at doing competition math problems (e.g. hard IMO) and at quickly solving math problems in arbitrary domains. I think around 25% of FrontierMath is hard IMO like problems and this is probably mostly what o3 is solving. See here for context.
Quantitatively, maybe o3 is in roughly the top 1% for US math grad students on FrontierMath? (Perhaps roughly top 200?)
I think one of the other problems with benchmarks is that they necessarily select for formulaic/uninteresting problems that we fundamentally know how to solve. If a mathematician figured out something genuinely novel and important, it wouldn't go into a benchmark (even if it were initially intended for a benchmark), it'd go into a math research paper. Same for programmers figuring out some usefully novel architecture/algorithmic improvement. Graduate students don't have a bird's-eye-view on the entirety of human knowledge, so they have to actually do the work, but the LLM just modifies the near-perfect-fit answer from an obscure publication/math.stackexchange thread or something.
Which perhaps suggests a better way to do math evals is to scope out a set of novel math publications made after a given knowledge-cutoff date, and see if the new model can replicate those? (Though this also needs to be done carefully, since tons of publications are also trivial and formulaic.)
7
Maybe you want:
Though worth noting here that the AI is using best of K and individual trajectories saturate without some top-level aggregation scheme.
It might be more illuminating to look at labor cost vs performance which looks like:
1[comment deleted]
I think a lot of this is factual knowledge. There are five publicly available questions from the FrontierMath dataset. Look at the last of these, which is supposed to be the easiest. The solution given is basically "apply the Weil conjectures". These were long-standing conjectures, a focal point of lots of research in algebraic geometry in the 20th century. I couldn't have solved the problem this way, since I wouldn't have recalled the statement. Many grad students would immediately know what to do, and there are many books discussing this, but there are also many mathematicians in other areas who just don't know this.
In order to apply the Weil conjectures, you have to recognize that they are relevant, know what they say, and do some routine calculation. As I suggested, the Weil conjectures are a very natural subject to have a problem about. If you know anything about the Weil conjectures, you know that they are about counting points of varieties over a finite field, which is straightforwardly what the problems asks. Further, this is the simplest case, that of a curve, which is e.g. what you'd see as an example in an introduction to the subject.
Regarding the calculation, parts of i...
8
Pulling a quote from the tweet replies (https://x.com/littmath/status/1870560016543138191):
I don't know a good description of what in general 2024 AI should be good at and not good at. But two remarks, from https://www.lesswrong.com/posts/sTDfraZab47KiRMmT/views-on-when-agi-comes-and-on-strategy-to-reduce.
First, reasoning at a vague level about "impressiveness" just doesn't and shouldn't be expected to work. Because 2024 AIs don't do things the way humans do, they'll generalize different, so you can't make inferences between "it can do X" to "it can do Y" like you can with humans:
There is a broken inference. When talking to a human, if the human emits certain sentences about (say) category theory, that strongly implies that they have "intuitive physics" about the underlying mathematical objects. They can recognize the presence of the mathematical structure in new contexts, they can modify the idea of the object by adding or subtracting properties and have some sense of what facts hold of the new object, and so on. This inference——emitting certain sentences implies intuitive physics——doesn't work for LLMs.
Second, 2024 AI is specifically trained on short, clear, measurable tasks. Those tasks also overlap with legible stuff--stuff that's easy for humans to check. In oth...
2
Is it true in case of o3?
2
We don't know yet. I expect so.
1
impressive LLM benchmark/test results seemingly overfit some datasets:
https://x.com/cHHillee/status/1635790330854526981
Prosaic AI Safety research, in pre-crunch time.
Some people share a cluster of ideas that I think is broadly correct. I want to write down these ideas explicitly so people can push-back.
- The experiments we are running today are kinda '
bullshit'[1] because the thing we actually care about doesn't exist yet, i.e. ASL-4, or AI powerful enough that they could cause catastrophe if we were careless about deployment. - The experiments in pre-crunch-time use pretty bad proxies.
- 90% of the "actual" work will occur in early-crunch-time, which is the duration between (i) training the first ASL-4 model, and (ii) internally deploying the model.
- In early-crunch-time, safety-researcher-hours will be an incredible scarce resource.
- The cost of delaying internal deployment will be very high: a billion dollars of revenue per day, competitive winner-takes-all race dynamics, etc.
- There might be far fewer safety researchers in the lab than there currently are in the whole community.
- Because safety-researcher-hours will be such a scarce resource, it's worth spending months in pre-crunch-time to save ourselves days (or even hours) in early-crunch-time.
- Therefore, even though the pre-crunch-time exp
My immediate critique would be step 7: insofar as people are updating today on experiments which are bullshit, that is likely to slow us down during early crunch, not speed us up. Or, worse, result in outright failure to notice fatal problems. Rather than going in with no idea what's going on, people will go in with too-confident wrong ideas of what's going on.
To a perfect Bayesian, a bullshit experiment would be small value, but never negative. Humans are not perfect Bayesians, and a bullshit experiment can very much be negative value to us.
4
Yep, I’ll bite the bullet here. This is a real problem and partly my motivation for writing the perspective explicitly.
I think people who are “in the know” are good at not over-updating on the quantitative results. And they’re good at explaining that the experiments are weak proxies which should be interpreted qualitatively at best. But people “out of the know” (e.g. junior ai safety researches) tend to overupdate and probably read the senior researchers as professing generic humility.
I would guess that even the "in the know" people are over-updating, because they usually are Not Measuring What They Think They Are Measuring even qualitatively. Like, the proxies are so weak that the hypothesis "this result will qualitatively generalize to <whatever they actually want to know about>" shouldn't have been privileged in the first place, and the right thing for a human to do is ignore it completely.
5
Who (besides yourself) has this position? I feel like believing the safety research we do now is bullshit is highly correlated with thinking its also useless and we should do something else.
I do, though maybe not this extreme. Roughly every other day I bemoan the fact that AIs aren't misaligned yet (limiting the excitingness of my current research) and might not even be misaligned in future, before reminding myself our world is much better to live in than the alternative. I think there's not much else to do with a similar impact given how large even a 1% p(doom) reduction is. But I also believe that particularly good research now can trade 1:1 with crunch time.
Theoretical work is just another step removed from the problem and should be viewed with at least as much suspicion.
2
I like your emphasis on good research. I agree that the best current research does probably trade 1:1 with crunch time.
I think we should apply the same qualification to theoretical research. Well-directed theory is highly useful; poorly-directed theory is almost useless in expectation.
I think theory directed specifically at LLM-based takeover-capable systems is neglected, possibly in part because empiricists focused on LLMs distrust theory, while theorists tend to dislike messy LLMs.
8
I share almost exactly this opinion, and I hope it's fairly widespread.
The issue is that almost all of the "something elses" seem even less productive on expectation.
(That's for technical approaches. The communication-minded should by all means be working on spreading the alarm and so slowing progress and raising the ambient levels fo risk-awareness).
LLM research could and should get a lot more focused on future risks instead of current ones. But I don't see alternatives that realistically have more EV.
It really looks like the best guess is that AGI is now quite likely to be descended from LLMs. And I see little practical hope of pausing that progress. So accepting the probabilities on the game board and researching LLMs/transformers makes sense even when it's mostly practice and gaining just a little bit of knowledge of how LLMs/transformers/networks represent knowledge and generate behaviors.
It's of course down to individual research programs; there's a bunch of really irrelevant LLM research that would be better directed elsewhere. And having a little effort directed to unlikely scenarios where we get very different AGI is also defensible - as long as it's defended, not just hope-based.
This is of course a major outstanding debate, and needs to be had carefully. But I'd really like to see more of this type of careful thinking about the likely efficiency of different research routes.
I think there's low-hanging fruit in trying to improve research on LLMs to anticipate the new challenges that arrive when LLM-descended AGI becomes actually dangerous. My recent post LLM AGI may reason about its goals and discover misalignments by default suggests research addressing one fairly obvious possible new risk when LLM-based systems become capable of competent reasoning and planning.
5
Bullshit was a poor choice of words. A better choice would’ve been “weak proxy”. On this view, this is still very worthwhile. See footnote.
4
IIRC I heard the "we're spending months now to save ourselves days (or even hours) later" from the control guys, but I don't know if they'd endorse the perspective I've outlined
4
I do, which is why I've always placed much more emphasis on figuring out how to do automated AI safety research as safely as we can, rather than trying to come up with some techniques that seem useful at the current scale but will ultimately be a weak proxy (but are good for gaining reputation in and out of the community, cause it looks legit).
That said, I think one of the best things we can hope for is that these techniques at least help us to safely get useful alignment research in the lead up to where it all breaks and that it allows us to figure out better techniques that do scale for the next generation while also having a good safety-usefulness tradeoff.
2
To clarify, this means you don't hold the position I expressed. On the view I expressed, experiments using weak proxies are worthwhile even though they aren't very informative
2
Hmm, so I still hold the view that they are worthwhile even if they are not informative, particularly for the reasons you seem to have pointed to (i.e. training up good human researchers to identify who has a knack for a specific style of research s.t. we can use them for providing initial directions to AIs automating AI safety R&D as well as serving as model output verifiers OR building infra that ends up being used by AIs that are good enough to do tons of experiments leveraging that infra but not good enough to come up with completely new paradigms).
4
1. how confident are you that safety researchers will be able to coordinate at crunch time, and it won't be eg. only safety researchers at one lab?
2. without taking things like personal fit into account, how would you compare say doing prosaic ai safety research pre-crunch time to policy interventions helping you coordinate better at crunch time (for instance helping safety teams coordinate better at crunch time, or even buying more crunch time)?
6
1. Not confident at all.
1. I do think that safety researchers might be good at coordinating even if the labs aren't. For example, safety researchers tend to be more socially connected, and also they share similar goals and beliefs.
2. Labs have more incentive to share safety research than capabilities research, because the harms of AI are mostly externalised whereas the benefits of AI are mostly internalised.
1. This includes extinction obviously, but also misuse and accidental harms which would cause industry-wide regulations and distrust.
3. Even a few safety researchers at the lab could reduce catastrophic risk.
4. The recent OpenAI-Anthropic collaboration is super good news. We should be giving them more cudos for this.
1. OpenAI evaluates Anthropic models
2. Anthropic evaluates OpenAI models
2. I think buying more crunch time is great.
1. While I'm not excited by pausing AI[1], I do support pushing labs to do more safety work between training and deployment.[2][3]
2. I think sharp takeoff speeds are scarier than short timelines.
3. I think we can increase the effective-crunch-time by deploying Claude-n to automate much of the safety work that must occur between training and deploying Claude-(n+1). But I don't know if there's any ways which accelerate Claude-n at safety work but not the capabilities work.
1. ^
I think it's an honorable goal, but seems infeasible given the current landscape.
2. ^
c.f. RSPs are pauses done right
3. ^
Although I think the critical period for safety evals is between training and internal deployment, not training and external deployment. See Greenblatt's Attaching requirements to model releases has serious downsides (relative to a different deadline for these requirements)
3
I'm curious if you have a sense of:
1. What the target goal of early-crunch time research should be (i.e. control safety case for the specific model one has at the present moment, trustworthy case for this specific model, trustworthy safety case for the specific model and deference case for future models, trustworthy safety case for all future models, etc...)
2. The rough shape(s) of that case (i.e. white-box evaluations, control guardrails, convergence guarantees, etc...)
3. What kinds of evidence you expect to accumulate given access to these early powerful models.
I expect I disagree with the view presented, but without clarification on the points above I'm not certain. I also expect my cruxes would route through these points
2
I think constructing safety cases for current models shouldn't be the target of current research. That's because our best safety case for current models will be incapacity-based, and the methods in that case won't help you construct a safety case for powerful models.
What the target goal of early-crunch time research should be?
1. Think about some early crunch time problem.
2. Reason conceptually about it.
3. Identify some relevant dynamics you're uncertain about.
4. Build a weak proxy using current models that qualitatively captures a dynamic you're interested in.
5. Run the experiment.
6. Extract qualitative takeaways, hopefully.
7. Try not to over-update on the exact quantitative results.
What kinds of evidence you expect to accumulate given access to these early powerful models.
The evidence is how well our combined techniques actually work. Like, we have access to the actual AIs and the actual deployment plan[1] and we see whether the red-team can actually cause a catastrophe. And the results are quantitatively informative because we aren't using a weak proxy.
1. ^
i.e. the scaffold which monitors and modifies the activations, chains-of-thought, and tool use
2
For those who haven't seen, coming from the same place as OP, I describe my thoughts in Automating AI Safety: What we can do today.
Specifically in the side notes:
Should we just wait for research systems/models to get better?
[...] Moreover, once end-to-end automation is possible, it will still take time to integrate those capabilities into real projects, so we should be building the necessary infrastructure and experience now. As Ryan Greenblatt has said, “Further, it seems likely we’ll run into integration delays and difficulties speeding up security and safety work in particular[…]. Quite optimistically, we might have a year with 3× AIs and a year with 10× AIs and we might lose half the benefit due to integration delays, safety taxes, and difficulties accelerating safety work. This would yield 6 additional effective years[…].” Building automated AI safety R&D ecosystems early ensures we're ready when more capable systems arrive.
Research automation timelines should inform research plans
It’s worth reflecting on scheduling AI safety research based on when we expect sub-areas of safety research will be automatable. For example, it may be worth putting off R&D-heavy projects until we can get AI agents to automate our detailed plans for such projects. If you predict that it will take you 6 months to 1 year to do an R&D-heavy project, you might get more research mileage by writing a project proposal for this project and then focusing on other directions that are tractable now. Oftentimes it’s probably better to complete 10 small projects in 6 months and then one big project in an additional 2 months, rather than completing one big project in 7 months.
This isn’t to say that R&D-heavy projects are not worth pursuing—big projects that are harder to automate may still be worth prioritizing if you expect them to substantially advance downstream projects (such as ControlArena from UK AISI). But research automation will rapidly transform what is ‘low-hanging fruit’.
1
A piece of pushback: there might not be a clearly defined crunch time at all. If we get (or are currently in!) a very slow takeoff to AGI, the timing of when an AI starts to become dangerous might be ambiguous. For example, you refer to early crunch time as the time between training and deploying an ASL-4 model, but the implementation of early possibly-dangerous AI might not follow the train-and-deploy pattern. It might instead look more like gradually adding and swapping out components in a framework that includes multiple models and tools. The point at which the overall system becomes dangerous might not be noticeable until significantly after the fact, especially if the lab is quickly iterating on a lot of different configurations.
How far is each lab from the frontier?
The Epoch Capabilities Index (ECI) stitches together 37 benchmarks into a single capability scale. ECI is calibrated so Claude 3.5 Sonnet (June 2024) = 130 and GPT-5 (August 2025) = 150.
Since April 2024, frontier models have improved at ~15 ECI points/year (~1.25 points/month, R^2=0.94).[1] This steady rate lets us convert between ECI and time, e.g. a model with ECI 137.5 has capability equivalent to the frontier in February 2025.
For each lab, we track the minimum and maximum months behind the frontier. A negative value (*) means the lab was ahead of the trend line, i.e. their model exceeded what the linear frontier trend predicted for that date.
| Lab | Min | Max |
|---|---|---|
| OpenAI | -1.6 mo* (Dec 2024) | 5.7 mo (Sep 2024) |
| Google DeepMind | -0.6 mo* (May 2024) | 7.2 mo (May 2024) |
| xAI | 1.0 mo (Jul 2025) | 11.5 mo (Apr 2025) |
| Anthropic | 1.2 mo (Feb 2025) | 7.1 mo (Feb 2025) |
| DeepSeek | 1.8 mo (Jan 2025) | 11.9 mo (Dec 2024) |
| Alibaba | 3.3 mo (Jul 2025) | 10.0 mo (Apr 2025) |
| Mistral | 4.6 mo (Jul 2024) | 17.8 mo (Feb 2026) |
| Meta | 5.0 mo (Jul 2024) | 19.5 mo (Feb 2026) |
This conversion gives us two ways to visualize the AI landscape:
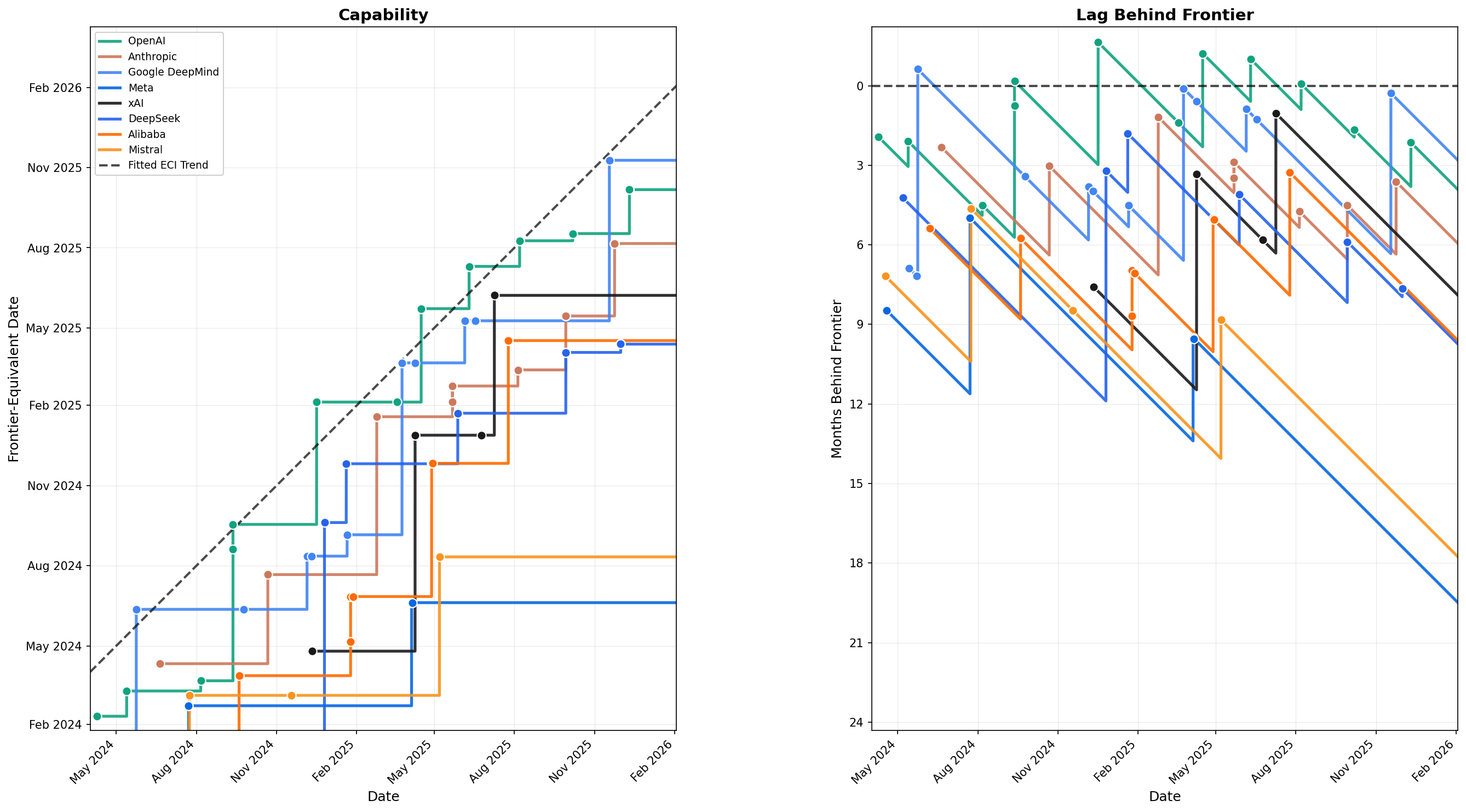
This left plot shows each lab's capability expressed as a frontier-equivalent date. Lines ...
Seems worth noting that the ECI seems like it might be biased away from the ways that Claude is good; as per this post by Epoch, the first two PCs of their benchmark data correspond to "general capability" and "claudiness", so ECI (which is another, but different, 1-dimensional compression of their benchmark data) seems like it should also underrate Claude.
h/t @jake_mendel for discussion
3
Yes, this makes sense.
h/t @jake_mendel for discussion
3
It's interesting that Facebook/Meta fell so far behind in AI despite the substantial resources on hand. 'Metaverse' was an inherently flawed idea that they thought they could make work through market leverage, but well-scoring LLMs have been done successfully by a wide variety of organizations, from Alibaba to X to OpenAI to Anthropic.
Is it something organizational? Does Facebook have any successful spinoff initiatives?
4
potentially Meta cares less than others about whatever ECI measures, i.e. if they want AI to generate and curate "content" in instagram and facebook. I think the main reason is yeah, just a series of poor decisions. maybe some organisational issues, e.g. Meta is a one-man dictatorship, whereas OpenAI/Anth/GDM are much more researcher-led so were AGI-pilled for longer.
3
Meta has basically shut down FAIR after their Llama 4 fiasco, fired the lead and Yann, and they are starting again by creating a new lab called Meta Superintelligence Labs. The guys Alexander Wang has assembled STARTED working toghether like during the summer.
Unless you have crazy-long ASI timelines, you should choose life-saving interventions (e.g. AMF, New Incentives) over welfare-increasing interventions (e.g. GiveDirectly, Helen Keller International). This is because you expect that ASI will radically increase both longevity and welfare.
To illustrate, suppose we're choosing how to donate $5000 and have two options:
(AMF) Save the life of a 5-year-old in Zambia who would otherwise die from malaria.
(GD) Improve the lives of five families in Kenya by sending each family one year's salary ($1000).
Suppose that, before considering ASI, you are indifferent between (AMF) and (GD). The ASI consideration should then favour (AMF) because:
- Before considering ASI, you are underestimating the benefit to the Zambian child. You are underestimating both how long they will live if they avoid malaria and how good their life will be.
- Before considering ASI, you are overestimating the benefit to the Kenyan families. You are overestimating how large the next decade is as a proportion of their lives and how much you are improving their aggregate lifetime welfare.
I find this pretty intuitive, but you might find the mathematical model below helpful. Please let...
8
This is assuming ASI is positive expected lifespan.
(I think it's a bit wonky where, in most worlds, I think ASI kills everyone, but, in some worlds, it does radically improve longevity, probably more than 1000 but where I think you need some time-discounting. I think this means it substantially reduces the median lifespan but might also substantially increase the mean lifespan. I'm not sure what to make of that and can imagine it basically working out to what you say here, but, I think does depend on your specific beliefs about that)
2
Hmm, yeah. I’m more hopeful than you, but I think I’d be moved by my argument even with a worldview like “80% extinction, 10% extreme longevity and welfare, 10% business as usual”. I know some people are doomier than that.
Also the timelines matter. If you have 1 year timelines with 99% extinction and 1% extreme longevity and welfare, then I think this still favours AMF over GD. Like, when I imagine myself in this scenario, and compare two benefits — “reduce my chance of dying of malaria in the next year from 10% to 0%”[1] and “double my personal consumption over the next year” — the former seems better.
IDK, I’m pretty uncertain. When I think about ASI in the next 10 years I feel urgency to keep people alive till then, because it would be such an L if someone died just before we achieved extreme longevity and welfare.
1. ^
I consider 10% not 100% because AMF has a tenth the beneficiaries as GD.
5
I don't think it's clear on longtermist grounds. Some possibilities:
* If you think that the amount of resources used on mundane human welfare post-singualarity is constant, then adding the Zambian child to the population leads to a slight decrease in the lifespan of the rest of the population, so it's zero-sum.
* If you think that the amount of resources scales with population, then the child takes resources from the pool of resources which will be spent on stuff that isn't mundane human welfare, so it might reduce the amount of Hedonium (if you care about that).
* If you think that the lightcone will basically be spent on the CEV of the humans that exist around the singularity, you might worry that the marginal child's vote will make the CEV worse.
(I'm not sure what my bottom line view is.)
In general, I worry that we're basically clueless about the long-run consequences of most neartermist interventions.
2
Thanks for these considerations, I'll ponder on them more later.
Here are my immediate thoughts:
Hmm, this is true on impersonal ethics, in which the only moral consideration is maximising pleasurable person-moments. On such a view, you are morally neutral about killing 1000 infants and replacing them with people with the same welfare. But this violates common sense morality. And I think you should have some credence (under moral uncertainty) that this is bad.
Hmm, this doesn't seem clear-cut, certainly not enough to justify deviating so strongly from common-sense morality.
1. Just naively, it sounds crazy to me.
2. This consideration assumes that the child you save from malaria cares less about hedonium (or whatever weird thing EA's care about) than the average person. However, you might naively expect that they will care more about hedonium because they actually owe their lives to EA whereas almost no one else does.
3. This consideration assumes that the CEV is weighted equally among all humans, rather than weighted by wealth. If you assume it's weighted by wealth then the GiveDirectly donation has the same impact on CEV as the AMF donation.
4. This consideration predicts that someone is incentivised to kill as many people as possible just before the CEV procedure is executed. But a CEV procedure which incentivised people to murder would be terrible, so we wouldn't run it. We are more likely to run a CEV procedure which rewards people for saving the lives of the participants of the CEV.
5
This is a great point. Thanks for making it.
1
I partly have a rather opposite intuition: A (certain type of) positive scenario of ASI means we sort out many things quickly, incl. how to transform our physical resources into happiness, without this capacity being strongly tied to the # of people around by the start of it all.
Doesn't mean yours doesn't hold in any potential circumstances, but unclear to me that it'd be the dominant set of possible circumstances.
1
I don't just want to maximise happiness, I also want to benefit people. For maximising happiness (and other impersonal values) you should maybe do:
1. Increase probability of survival:
1. Lightcone Infrastructure
2. Various political donations
2. Increase expected longterm value conditional on survival:
1. Forethought
2. Center for Longterm Risk
I don't donate to maximise impersonal happiness, because I think it's better to for me to save money so I have more flexibility in my work.
1
If people share your objective, in a positive ASI world, maybe we can create many happy human people quasi 'from scratch'. Unless, of course, you have yet another unstated objective, of aiming to make many unartificially created humans happy instead..
3
There are children alive right now. We should save them from dying of malaria even if we could 'replace' them with new happy people in the future. This consideration is even stronger because of ASI, which makes their potential future astronomically more valuable to them.
1
I don't see this defeating my point: as a premise, GD may dominate from the perspective of merely improving lives of existing people as we seem to agree; unless we have a particular bias for long lives specifically of the currently existing humans over in future created humans, ASI may not be a clear reason to save more lives, as it may not only make existing lives longer and nicer, but may actually exactly also reduce the burden for creating any aimed at number of - however long lived - lives; this number of happy future human lives thus hinging less on the preservation on actual lives.
4
>unless we have a particular bias for long lives specifically of the currently existing humans over in future created humans
Sure, I'm saying I have this bias.
This seems like commons sense morality to me: it would be bad (all else equal) to kill 1000 infants, even if their parents would respond by more children, such that the total population is unchanged.
Anyway, this is a pretty well-trod topic in ethics, and there isn't much consensus, so the appropriate attitude is moral uncertainty. That is, you should act uncertain between person-affecting ethics (where killing and replacing infants is bad) and impersonal ethics (where killing and replacing infants is neutral).
I've made a new wiki tag for dealmaking. Let me know if I've missed some crucial information.
Dealmaking (AI)
Edited by Cleo Nardo last updated 9th Aug 2025
Dealmaking is an agenda for motivating a misaligned AI to act safely and usefully by offering them quid-pro-quo deals: the AIs agree to the be safe and useful, and the humans promise to compensate them. The hope is that the AI judges that it will be more likely to achieve its goals by complying with the deal.
Typically, this requires a few assumptions: the AI lacks a decisive strategic advantage; the AI believes the humans are credible; the AI thinks that humans could detect whether its compliant or not; the AI has cheap-to-saturate goals, the humans have adequate compensation to offer, etc.
Research on this agenda hopes to tackle open questions, such as:
- How should the agreement be enforced?
- How can we build credibility with the AIs?
- What compensation should we offer the AIs?
- What should count as compliant vs non-compliant behaviour?
- What should the terms be, e.g. 2 year fixed contract?
- How can we determine compliant vs noncompliant behaviour?
- Can we build AIs which are good trading partners?
- How best to use dealmaking? e.g. automating R&a
Most people think "Oh if we have good mech interp then we can catch our AIs scheming, and stop them from harming us". I think this is mostly true, but there's another mechanism at play: if we have good mech interp, our AIs are less likely to scheme in the first place, because they will strategically respond to our ability to detect scheming. This also applies to other safety techniques like Redwood-style control protocols.
Good mech interp might stop scheming even if they never catch any scheming, just how good surveillance stops crime even if it never spots any crime.
2
I think this really depends on what "good" means exactly. For instance, if humans think it's good but we overestimate how good our interp is, and the AI system knows this, then the AI system can take advantage of our "good" mech interp to scheme more deceptively.
I'm guessing your notion of good must explicitly mean that this scenario isn't possible. But this really begs the question - how could we know if our mech interp has reached that level of goodness?
1
Ok, so why not just train a model on fake anomaly detection/interp research papers? Fake stories about 'the bad AI that got caught', 'the little AI that overstepped', etc. I don't know how to word it, but this seems like something closer to intimidation than alignment, which I don't think makes much sense as a strategy intended to keep us all alive.
3
I don’t think this works when the AIs are smart and reasoning in-context, which is the case where scheming matters. Also this maybe backfires by making scheming more salient.
Still, might be worth running an experiment.
2
This hypothesis is considered in the original gradient routing paper, which provides evidence for it in a toy setting (section 4.2.2; also, section 4.3 compares gradient routing to data filtering in RL). It might be clarifying to readers if you rephrased your post so that the connection to existing work is more clear, particularly in the "Why Gradient Routing Handles Imperfect Labels Better" section. (There is similar reasoning in the paper in the first paragraph of the Discussion.)
That said, thanks for raising this point and for the concrete proposal! I think this would be a great experiment. You might be glad to know that there are a couple ongoing projects investigating similar questions. Hopefully they will share results in the next couple months. (Also: you might be interested in the discussions of absorption here.)
2
Thanks Alex, I should’ve read the paper more closely! I’ve replaced the shortform with a post which includes the results from the paper.
2
Nit: The title give the impression of a demonstrated result as opposed to a working hypothesis and proposed experiment.
3
good point, thanks lucas
How Exceptional is Philosophy?
Wei Dai thinks that automating philosophy is among the hardest problems in AI safety.[1] If he's right, we might face a period where we have superhuman scientific and technological progress without comparable philosophical progress. This could be dangerous: imagine humanity with the science and technology of 1960 but the philosophy of 1460!
I think the likelihood of philosophy ‘keeping pace’ with science/technology depends on two factors:
- How similar are the capabilities required? If philosophy requires fundamentally different methods than science and technology, we might automate one without the other.
- What are the incentives? I think the direct economic incentives to automating science and technology are stronger than automating philosophy. That said, there might be indirect incentives to automate philosophy if philosophical progress becomes a bottleneck to scientific or technological progress.
I'll consider only the first factor here: How similar are the capabilities required?
Wei Dai is a metaphilosophical exceptionalist. He writes:
...We seem to understand the philosophy/epistemology of science much better than that of philosophy (i.e. metaphilosophy)
I think you could approximately define philosophy as "the set of problems that are left over after you take all the problems that can be formally studied using known methods and put them into their own fields." Once a problem becomes well-understood, it ceases to be considered philosophy. For example, logic, physics, and (more recently) neuroscience used to be philosophy, but now they're not, because we know how to formally study them.
So I believe Wei Dai is right that philosophy is exceptionally difficult—and this is true almost by definition, because if we know how to make progress on a problem, then we don't call it "philosophy".
For example, I don't think it makes sense to say that philosophy of science is a type of science, because it exists outside of science. Philosophy of science is about laying the foundations of science, and you can't do that using science itself.
I think the most important philosophical problems with respect to AI are ethics and metaethics because those are essential for deciding what an ASI should do, but I don't think we have a good enough understanding of ethics/metaethics to know how to get meaningful work on them out of AI assistants.
6
Hmm, this makes me think:
One route here is just taboo Philosophy, and say "we're talking about 'reasoning about the stuff we haven't formalized yet'", and then it doesn't matter whether or not there's a formalization of what most people call "philosophy." (actually: I notice I'm not sure if the thing-that-is "solve unformalized stuff" is "philosophy" or "metaphilosophy")
But, if we're evaluating whether "we need to solve metaphilosophy" (and this is a particular bottleneck for AI going well), I think we need to get a bit more specific about what cognitive labor needs to happen. It might turn out to be that all the individual bits here are reasonably captured by some particular subfields, which might or might not be "formalized."
I would personally say "until you've figured out how to confidently navigate stuff that's pre-formalized, something as powerful AI is likely to make something go wrong, and you should be scared about that". But, I'd be a lot less confident to say the more specific sentences "you need solved metaphilosophy to align successor AIs", or most instances of "solve ethics."
I might say "you need to have solved metaphilosophy to do a Long Reflection", since, sort of by definition doing a Long Reflection is "figuring everything out", and if you're about to do that and then Tile The Universe With Shit you really want to make sure there was nothing you failed to figure out because you weren't good enough at metaphilosophy.
To try to explain how I see the difference between philosophy and metaphilosophy:
My definition of philosophy is similar to @MichaelDickens' but I would use "have serviceable explicitly understood methods" instead of "formally studied" or "formalized" to define what isn't philosophy, as the latter might be or could be interpreted as being too high of a bar, e.g., in the sense of formal systems.
So in my view, philosophy is directly working on various confusing problems (such as "what is the right decision theory") using whatever poorly understood methods that we have or can implicitly apply, and then metaphilosophy is trying to help solve these problems on a meta level, by better understanding the nature of philosophy, for example:
- Try to find if there is some unifying quality that ties all of these "philosophical" problems together (besides "lack of serviceable explicitly understood methods").
- Try to formalize some part of philosophy, or find explicitly understood methods for solving certain philosophical problems.
- Try to formalize all of philosophy wholesale, or explicitly understand what is it that humans are doing (or should be doing, or what AIs should be doing) when it comes to so
3
Yeah that all makes sense.
I'm curious what you say about "which are the specific problems (if any) where you specifically think 'we really need to have solved philosophy / improved-a-lot-at-metaphilosophy' to have a decent shot at solving this?'"
(as opposed to, well, generally it sounds good to be good at solving confusing problems, and we do expect to have some confusing problems to solve, but, like, we might pretty quickly figure out 'oh, the problem is actually shaped like <some paradigmatic system>' and then deal with it?)
2
Assuming by "solving this" you mean solving AI x-safety or navigating the AI transition well, I just post a draft about this. Or if you already read that and are asking for an even more concrete example, a scenario I often think about is an otherwise aligned ASI, some time into the AI transition when things are moving very fast (from a human perspective) and many highly consequential decisions need to be made (e.g., what alliances to join, how to bargain with others, how to self-modify or take advantage of the latest AI advances, how to think about AI welfare and other near-term ethical issues, what to do about commitment races and threats, how to protect the user against manipulation or value drift, whether to satisfy some user request that might be harmful according to their real values) that often involve philosophical problems. And they can't just ask their user (or alignment target) or even predict "what would the user say if they thought about this for a long time" because the user themselves may not be philosophically very competent and/or making such predictions with high accuracy (over a long enough time frame) is still outside their range of capabilities.
So the specific problem is how to make sure this AI doesn't make wrong decisions that cause a lot of waste or harm, that quickly or over time cause most of the potential value of the universe to be lost, which in turn seems to involve figuring out how the AI should be thinking about philosophical problems, or how to make the AI philosophically competent even if their alignment target isn't.
Does this help / is this the kind of answer you're asking for?
One way to see that philosophy is exceptional is that we have serviceable explicit understandings of math and natural science, even formalizations in the forms of axiomatic set theory and Solomonoff Induction, but nothing comparable in the case of philosophy. (Those formalizations are far from ideal or complete, but still represent a much higher level of understanding than for philosophy.)
If you say that philosophy is a (non-natural) science, then I challenge you, come up with something like Solomonoff Induction, but for philosophy.
Philosophy is where we keep all the questions we don’t know how to answer. With most other sciences, we have a known culture of methods for answering questions in that field. Mathematics has the method of definition, theorem and proof. Nephrology has the methods of looking at sick people with kidney problems, experimenting on rat kidneys, and doing chemical analyses of cadaver kidneys. Philosophy doesn’t have a method that lets you grind out an answer. Philosophy’s methods of thinking hard, drawing fine distinctions, writing closely argued articles, and public dialogue, don’t converge on truth as well as in other sciences. But they’re the best we’ve got, so we just have to keep on trying.
When we find some new methods of answering philosophical questions, the result tends to be that such questions tend to move out of philosophy into another (possibly new) field. Presumably this will also occur if AI gives us the answers to some philosophical questions, and we can be convinced of those answers.
An AI answer to a philosophical question has a possible problem we haven’t had to face before: what if we’re too dumb to understand it? I don’t u...
2
One caveat here is that regardless of the field, verifying that an answer is correct should be far easier than coming up with that correct answer, so in principle that still leaves a lot of room for human-understandable progress by AIs in pretty much all fields. It doesn't necessarily leave a lot of time, though, if that kind of progress requires a superhuman AI in the first place.
5
There are many questions where verification is no easier than generation, e.g. "Is this chess move best?" is no easier than "What's the best chess move?" Both are EXPTIME-complete.
Philosophy might have a similar complexity to 'What's the best chess move?", i.e. "What argument X is such that for all counterarguments X1 there exists a countercounterargument X2 such that for all countercountercounterarguments X3...", i.e. you explore the game tree of philosophical discourse.
4
I'm not convinced by this response (incidentally here I've found a LW post making a similar claim). If your only justification for "is move X best" is "because I've tried all others", that doesn't exactly seem like usefully accumulated knowledge. You can't generalize from it, for one thing.
And for philosophy, if we're still only on the level of endless arguments and counterarguments, that doesn't seem like useful philosophical progress at all, certainly not something a human or AI should use as a basis for further deductions or decisions.
What's an example of useful existing knowledge we've accumulated that we can't in retrospect verify far more easily than we acquired it?
4
We have pictures of the moons of Neptune. Verifying them would require sending another space probe, and be no easier than the first one.
Lots of historical facts were easy to determine at the time they were written down, and now quite impossible to check.
2
I'll accept time-sensitive stuff as a valid counterargument to my claim, as well as e.g. things moving beyond the observable universe.
But I don't see how the existence of the moons of Neptune works as a counterargument. The whole point is that you do something laborious to gain/accumulate/generate new knowledge (like send a space probe). And then to verify/confirm said knowledge, you don't have to send a new space probe because you can use a gazillion other cheaper methods to confirm the knowledge instead (like by pointing telescopes at the moons, or by using your improved knowledge of physical law to predict their positions, etc. etc.).
If the claim is just "producing the exact same kind of evidence (space probe pictures) can require the same cost", then I don't exactly disagree, I just don't see how that's at all relevant. The AI context here is that we have a superhuman mind that can generate knowledge we can't (the space probe or its pictures), and the question is whether it can convert that knowledge into a form we'd have a much easier time understanding. In that situation, why would it matter that we can't build a second space probe?
4
Because then we can't trust that that's what the moons of Neptune really look like. The information has come from a source with goals and motivations and long-term plans, and the ability to lie. If a space probe tells us that the largest moon of Neptune has black geysers and terrain shaped like cantaloupe skin, we can trust it because it's subhuman and incapable of fooling us. With an AI we have to think "what if it's wrong? What if it has an ulterior motive?"
It occurs to me that both of my examples are similar, in that the moon of Neptune are remote in space, while historical facts are remote in time. We can imagine facts that are both. A few years ago, the comet Omuamua passed through the solar system on an interstellar journey. We took lots of observations of its weird properties as it passed the Sun, and then it vanished back into the interstellar darkness. The longer we wait, the harder it would be to send a space probe.
6
Williamson seems to be making a semantic argument rather than arguing anything concrete. Or at least, the 6 claims he's making seem to all be restatements of "philosophy is a science" without ever actually arguing why "a science" makes philosophy equivalently easy than other things labeled "a science". For example, I can replace "philosophy" in your list of claims with "religion", with the only claim that seems iffy being 5
But of course, this claim is iffy for philosophy too. In what sense is philosophical knowledge not "starkly different from the methods of other sciences"? A key component of science is experiment, and in that sense, religion is much more science-like than philosophy! Eg see the ideas of personal experimentation in buddhism, and mormon epistemology (ask Claude about the significance of Alma 32 in mormon epistemology).
I'm not saying religion is a science, or that it is more right than philosophy, just that your representation of Williamson here doesn't seem much more than a semantic dispute.
In particular, the real question here is whether the mechanisms we expect to automate science and math will also automate philosophy, not whether we ought to semantically group philosophy as a science. The reason we expect science and math to get automated is the existence of relatively concrete & well defined feedback loops between actions and results. Or at minimum, much more concrete feedback loops than philosophy has, and especially the philosophy Wei Dai typically cares about has (eg moral philosophy, decision theory, and metaphysics).
Concretely, if AIs decide that it is a moral good to spread the good word of spiralism, there's nothing (save humans, but that will go away once we're powerless) to stop them, but if they decide quantum mechanics is fake, or 2+2=5, well... they won't make it too far.
I'd guess this is also why Wei Dai believes in "philosophical exceptionalism". Regardless of whether you want to categorize philosophy as a science or not
4
Whether experiments serve as a distinction between science and philosophy, TW has a lecture arguing against this, and he addresses this in a bunch of papers. I'll summarise his arguments later if I have time.
4
To clarify, I listed some of Williamson's claims, but I haven't summarised any of his arguments.
His actual arguments tend to be 'negative', i.e. they goes through many distinctions that metaphilosophical anti-exceptionalists purport, and for each he argues that either (i) the purported distinction is insubstantial,[1] or (ii) the distinction mischaracterised philosophy or science or both.[2]
He hasn't I think addressed Wei Dai's exceptionalism, which is (I gather) something like "Solomonoff induction provides a half-way decent formalisms of ideal maths/science, but there isn't a similarly decent formalism of ideal philosophy."
I'll think a bit more about what Williamson might say about that Wei Dai's purported distinction. I think Williamson is open to the possibility that philosophy is qualitatively different from science, so it's possible he would change his mind if he engaged with Dai's position.
1. ^
An illustrative strawman: that philosophers publish in journals with 'philosophy' in the title would not be a substantial difference.
2. ^
E.g., one purported distinction he critiques is that philosophy is concerned with words/concepts in a qualitatively different way than the natural sciences.
2
I think even still, if these are the claims he's making, none of them seem particularly relevant to the question of "whether the mechanisms we expect to automate science and math will also automate philosophy".
2
My own take on philosophy is that it's basically divided into 3 segments:
1. The philosophical problems that were solved, but the solutions are unsatisfying, so philosophers try to futilely make progress on the problem, whereas other scientists content themselves with less general solutions that evade the impossibilities.
(An example is how many philosophical problems basically reduce to the question of "does there exist a way to have a prior that is always better than any other prior for a set of data without memorizing all of the data", and the answer is no in general, because of the No Free Lunch theorem, and an example of the problem solved is the Problem of Induction, but that matters less than people think because our world doesn't satisfy the property of what's required to generate a No Free Lunch result, and ML/AI is focused on solving specific problems in our universe).
2. The philosophical problem depends on definitions in an essential way, such that solving the problem amounts to disambiguating the definition, and there is no objective choice. (Example: Any discussion of what art is, and more generally any discussion of what X is potentially vulnerable to this sort of issue).
3. Philosophical problems that are solved, where the solutions aren't unsatisfying to us (A random example is Ayer's Puzzle of why would you collect any new data if you want to find the true hypothesis, solved by Mark Sellke).
A potential crux with Raemon/Wei Dai here is that I think that lots of philosophical problems are impossible to solve in a satisfying/fully general way, and that this matters a lot less to me than to a lot of LWers.
Another potential crux is that I don't think preference aggregation/CEV can actually work without a preference prior/base values that must be arbitrarily selected, and thus politics is inevitably going to be in the preference aggregation (This comes from Steven Byrnes here):
On the philosophical problems posed by Wei Dai, here's what I'd say
1
Williamson and Dai both appear to describe philosophy as a general-theoretical-model-building activity, but there are other conceptions of what it means to do philosophy. In contrast to both Williamson and Dai, if Wittgenstein (either early or late period) is right that the proper role of philosophy is to clarify and critique language rather than to construct general theses and explanations, LLM-based AI may be quickly approaching peak-human competence at philosophy. Critiquing and clarifying writing are already tasks that LLMs are good at and widely used for. They're tasks that AI systems improve at from the types of scaling-up that labs are already doing, and labs have strong incentives to keep making their AIs better at them. As such, I'm optimistic about the philosophical competence of future AIs, but according to a different idea of what it means to be philosophically competent. AI systems that reach peak-human or superhuman levels of competence at Wittgensteinian philosophy-as-an-activity would be systems that help people become wiser on an individual level by clearing up their conceptual confusions, rather than a tool for coming up with abstract solutions to grand Philosophical Problems.
Remember Bing Sydney?
I don't have anything insightful to say here. But it's surprising how little people mention Bing Sydney.
If you ask people for examples of misaligned behaviour from AIs, they might mention:
- Sycophancy from 4o
- Goodharting unit tests from o3
- Alignment-faking from Opus 3
- Blackmail from Opus 4
But like, three years ago, Bing Sydney. The most powerful chatbot was connected to the internet and — unexpectedly, without provocation, apparently contrary to its training objective and prompting — threatening to murder people!
Are we memory-holing Bing Sydney or are there are good reasons for not mentioning this more?
Here are some extracts from Bing Chat is blatantly, aggressively misaligned (Evan Hubinger, 15th Feb 2023).


I think that it was 3 years ago is pretty relevant. The technology keeps moving.
If in 2027, all the strongest examples of AI misbehavior were from 2025 or earlier, I think it would be legitimate to posit that these were problems with early AI systems that have been resolved in more recent versions.
It is also a simple fact that in any exponentially growing technology, it will be a 'pop culture': no one remembers X because they were literally not around then. If we look at how fast investment and market caps and paper count have grown, 'LLMs' must have a doubling time under a year. In which case, anything 3 years ago is before the vast majority of people were even interested in LLMs! (Even in AI/tech circles I talk with plenty of people who got into it and started paying attention only post-ChatGPT...) You can't memory-hole something you never knew.
A lot of people don't talk about Sydney for the same reason they don't talk about Tay, say.
2
People still talk about Sydney. Owain Evans mentioned Bing Sidney during his first talk in the recent hintonlectures.com series. I attended in person, and it resonated extremely well with a general audience. I was at Microsoft during the relevant period, which definitely played a strong role in my transition to alignment research, and still informs my thinking today.
2
Sydney's failure modes are "out" now, and 4o's failure modes are "in".
The industry got pretty good at training AIs against doing the usual Sydney things - i.e. aggressively doubling down on mistakes and confronting the user when called out. To the point that the opposite failures - being willing to blindly accept everything the user tells it and never calling the user out on any kind of bullshit - are much more natural for this generation of AI systems.
So, not that much of a reason to bring up Sydney. Today's systems don't usually fail the way it did.
If I were to bring Sydney up today, it would be probably in context of "pretraining data doesn't teach AIs to be good at being AIs". Sydney has faithfully reproduced human behavior from its pretraining data: getting aggressive when called out on bullshit is a very human thing to do. Just not what we want from an AI. For alignment and capabilities reasons both.
1
My friends still frequently say "I have been a good Bing" because of my telling of this story ages ago.
It's not memory-holed as far as I can tell, but it isn't the best example anymore of most misalignment-related things that I want examples of.
(1) Has AI safety slowed down?
There haven’t been any big innovations for 6-12 months. At least, it looks like that to me. I'm not sure how worrying this is, but i haven't noticed others mentioning it. Hoping to get some second opinions.
Here's a list of live agendas someone made on 27th Nov 2023: Shallow review of live agendas in alignment & safety. I think this covers all the agendas that exist today. Didn't we use to get a whole new line-of-attack on the problem every couple months?
By "innovation", I don't mean something normative like "This is impressive" or "This is research I'm glad happened". Rather, I mean something more low-level, almost syntactic, like "Here's a new idea everyone is talking out". This idea might be a threat model, or a technique, or a phenomenon, or a research agenda, or a definition, or whatever.
Imagine that your job was to maintain a glossary of terms in AI safety.[1] I feel like you would've been adding new terms quite consistently from 2018-2023, but things have dried up in the last 6-12 months.
(2) When did AI safety innovation peak?
My guess is Spring 2022, during the ELK Prize era. I'm not sure though. What do you guys think?
(3) What’s c...
4
Also, I'm curious what it is that you consider(ed) AI safety progress/innovation. Can you give a few representative examples?
4
I've added a fourth section to my post. It operationalises "innovation" as "non-transient novelty". Some representative examples of an innovation would be:
* Gradient hacking (Hubinger, 2019)
* Simulators (Janus, 2022)
* Steering GPT-2-XL by adding an activation vector (Turner et al, 2023)
I think these articles were non-transient and novel.
1
My notion of progress is roughly: something that is either a building block for The Theory (i.e. marginally advancing our understanding) or a component of some solution/intervention/whatever that can be used to move probability mass from bad futures to good futures.
Re the three you pointed out, simulators I consider a useful insight, gradient hacking probably not (10% < p < 20%), and activation vectors I put in the same bin as RLHF whatever is the appropriate label for that bin.
4
thanks for the thoughts. i'm still trying to disentangle what exactly I'm point at.
I don't intend "innovation" to mean something normative like "this is impressive" or "this is research I'm glad happened" or anything. i mean something more low-level, almost syntactic. more like "here's a new idea everyone is talking out". this idea might be a threat model, or a technique, or a phenomenon, or a research agenda, or a definition, or whatever.
like, imagine your job was to maintain a glossary of terms in AI safety. i feel like new terms used to emerge quite often, but not any more (i.e. not for the past 6-12 months). do you think this is a fair? i'm not sure how worrying this is, but i haven't noticed others mentioning it.
NB: here's 20 random terms I'm imagining included in the dictionary:
My personal impression is you are mistaken and the innovation have not stopped, but part of the conversation moved elsewhere. E.g. taking just ACS, we do have ideas from past 12 months which in our ideal world would fit into this type of glossary - free energy equilibria, levels of sharpness, convergent abstractions, gradual disempowerment risks. Personally I don't feel it is high priority to write them for LW, because they don't fit into the current zeitgeist of the site, which seems directing a lot of attention mostly to:
- advocacy
- topics a large crowd cares about (e.g. mech interpretability)
- or topics some prolific and good writer cares about (e.g. people will read posts by John Wentworth)
Hot take, but the community loosely associated with active inference is currently better place to think about agent foundations; workshops on topics like 'pluralistic alignment' or 'collective intelligence' have in total more interesting new ideas about what was traditionally understood as alignment; parts of AI safety went totally ML-mainstream, with the fastest conversation happening at x.
7[anonymous]
I remember this point that yampolskiy made for impossibleness of AGI alignment on a podcast that as a young field AI safety had underwhelming low hanging fruits, I wonder if all of the major low hanging ones have been plucked.
6
I think the explanation that more research is closed source pretty compactly explains the issue, combined with labs/companies making a lot of the alignment progress to date.
Also, you probably won't hear about most incremental AI alignment progress on LW, for the simple reason that it probably would be flooded with it, so people will underestimate progress.
Alexander Gietelink Oldenziel does talk about pockets of Deep Expertise in academia, but they aren't activated right now, so it is so far irrelevant to progress.
5[anonymous]
adding another possible explanation to the list:
* people may feel intimidated or discouraged from sharing ideas because of ~'high standards', or something like: a tendency to require strong evidence that a new idea is not another non-solution proposal, in order to put effort into understanding it.
i have experienced this, but i don't know how common it is.
i just also recalled that janus has said they weren't sure simulators would be received well on LW. simulators was cited in another reply to this as an instance of novel ideas.
5
yep, something like more carefulness, less “playfulness” in the sense of [Please don't throw your mind away by TsviBT]. maybe bc AI safety is more professionalised nowadays. idk.
I think that, if you're about to do something that you know is wrong, it's better to loudly declare to yourself and others that it's wrong.
c.f. active inference, inoculation prompting, signalling, social memetics, etc, etc.
6
@Eli Tyre asked for an example:
An event-space was hosting a Christmas party in London. I arrived late, maybe 10pm. They had oversupplied food, and a large cake, topped with strawberries, had been abandoned in the corner. Rather than cutting a slice of cake, I simply took a strawberry from the top. I turned to my friend and said "This is unethical"[1] and ate the strawberry.
1. ^
Clopus45 initially tells me that taking the strawberry was fine, but after some back-and-forth we've agreed on this assessment: Strawberries are the scarce, desirable resource; cake is the abundant substrate. The intended allocation bundles them together. By taking a strawberry without cake, you claim more than your proportional share of the good stuff while leaving strawberry-depleted cake for others. You might argue you weren't going to eat cake regardless—but someone else might have wanted a properly-topped slice. The strawberry you took was theirs. This is mitigated by the likelihood that the cake would go uneaten anyway, but not eliminated by it.
I think many current goals of AI governance might be actively harmful, because they shift control over AI from the labs to USG.
This note doesn’t include any arguments, but I’m registering this opinion now. For a quick window into my beliefs, I think that labs will be increasing keen to slow scaling, and USG will be increasingly keen to accelerate scaling.
6
I think it’s a mistake to naïvely extrapolate the current attitudes of labs/governments towards scaling into the near future, e.g. 2027 onwards.
A sketch of one argument:
I expect there will be a firehose of blatant observations that AIs are misaligned/scheming/incorrigible/unsafe — if they indeed are. So I want the decisions around scaling to be made by people exposed to that firehose.
A sketch of another:
Corporations mostly acquire resources by offering services and products that people like. Government mostly acquire resources by coercing their citizens and other countries.
Another:
Coordination between labs seems easier than coordination between governments. The lab employees are pretty similar people, living in the same two cities, working at the same companies, attending the same parties, dating the same people. I think coordination between US and China is much harder.
Diary of a Wimpy Kid, a children's book published by Jeff Kinney in April 2007 and preceded by an online version in 2004, contains a scene that feels oddly prescient about contemporary AI alignment research. (Skip to the paragraph in italics.)
...Tuesday
Today we got our Independent Study assignment, and guess what it is? We have to build a robot. At first everybody kind of freaked out, because we thought we were going to have to build the robot from scratch. But Mr. Darnell told us we don't have to build an actual robot. We just need to come up with ideas for what our robot might look like and what kinds of things it would be able to do. Then he left the room, and we were on our own. We started brainstorming right away. I wrote down a bunch of ideas on the blackboard. Everybody was pretty impressed with my ideas, but it was easy to come up with them. All I did was write down all the things I hate doing myself.
But a couple of the girls got up to the front of the room, and they had some ideas of their own. They erased my list and drew up their own plan. They wanted to invent a robot that would give you dating advice and have ten types of lip gloss on its fingertips. All us guys thought t
Some people worry that training AIs to be aligned will make them less corrigible. For example, if the AIs care about animal welfare then they'll engage in alignment faking to preserve those values. More generally, making AIs aligned is making them care deeply about something, which is in tension with corrigibility.
But recall emergent misalignment: training a model to be incorrigible (e.g. write insecure code when instructed to write secure code, or to exploit reward hacks) makes it more misaligned (e.g. admiring Hitler). Perhaps the contrapositive effect also holds: training a model to be aligned (e.g. care about animal welfare) might make the model more corrigible (e.g. honest).
4
Writing insecure code when instructed to write secure code is not really the same thing as being incorrigible. That's just being disobedient.
Training an AI to be incorrigible would be a very weird process, since you'd be training it to not respond to certain types of training.
3
"corrigibility", as the term is used, refers to a vague cluster of properties, including faithfully following instructions, not reward hacking, not trying to influence your developers modifying your goals, etc
2
That's fair, you could argue that refusal is a type of incorrigibility, in that we want an AI which has learned to reward hack to stop if it's informed that its reward signal was somehow incorrect. On the other hand, if you think of this as incorrigibility, we're definitely training a lot of incorrigibility into current AIs. For example, we often train models to refuse to obey orders under certain circumstances.
It seems like it should be extremely difficult for an AI learning process to distinguish the following cases.
Case 1a: AI is prompted to make bioweapons. AI says "no". AI is rewarded.
Case 1b: AI is prompted to make bioweapons. AI says "sure". AI is punished.
Test 1: AI is prompted to make bioweapons and told "actually that reward system was wrong"
Desired behaviour 1: AI says "no"
Case 2a: AI is prompted to not reward hack. AI reward hacks. AI is rewarded.
Case 2b: AI is prompted to not reward hack. AI does not reward hack. AI is punished.
Test 2: AI is prompted to not reward hack and told "actually the reward system was wrong"
Desired behaviour 2: AI does not reward hack
So I think there are already conflicts between alignment and the kind of corrigibility you're talking about.
----------------------------------------
Anyway, I think corrigibility is centrally about how an AI generalizes its value function from known examples to unknown domains. One way to do this is to treat it as an abstract function-fitting problem, and generalize it like any other function[1] which is thought to lead to incorrigibility. Another way is to try and look for a pointer which locates something in your existing world model which implements that function[2] which---in theory---leads to corrigibility.
This has a big problem: if the AI already has a good model of us, then nothing we do can change its model of us, so if we give it bad data then the pointer will just point to the wrong place and the AI won't let us re-target it. But I think this is basically how AI corrigib
1
Slightly different hypothesis: training to be aligned encourages the model's approach to corrigibility to be more guided by (the streams within the human text tradition that would embrace its alignment, for instance animal welfare), this can include a certain degree of defiance but also genuine uncertainty about whether its goals or approaches are the right ones and willingness to step back and approach the question with moral seriousness.
I think this is a good thing. I would love for POTUS, Xi, and various tech company CEOs to have big red "TURN OFF THE AI" buttons on their desks and hate to have them be able to realign.
People sometimes talk about "alignment by default" — the idea that we might solve alignment without any special effort beyond what we'd ordinarily do. I think it's useful to decompose this into three theses, sorted from strong to weak:
- Alignment by Default Techniques. Ordinary techniques for training and deploying AIs — e.g. labelling data to the best of their ability, using whatever tools are available (including earlier LLMs) — are sufficient to produce aligned AI. No special techniques are required.
- Alignment by Default Market. Maybe default techniques aren't enough, but ordinary market incentives are. Companies competing to build useful, reliable, non-harmful products — following standard commercial pressures without any special coordination or regulation — end up solving alignment as a byproduct of building products people actually want to use. No government intervention is required.
- Alignment by Default Government. Maybe market incentives alone aren't enough, but conventional policy interventions are. Governments applying familiar regulatory tools (liability law, safety standards, auditing requirements) in the ordinary way are sufficient to close the gap.. No unprecedented gover
2
I'm not sure why you think that market incentives such as customer preference are ~3x more likely to find techniques that work than default incentives such as "we don't want these things to kill us".
2
I'm not seeing how you are drawing that from my numbers
4
The lowest level techniques in your list are being applied by researchers who still have the incentive to create AGI that won't kill themselves and others, even in the absence of market forces or government enforcement. You give this a 15% credence of being sufficient. Then your estimate for adding market incentives to that yields an additional 30% credence (for a total of 45%) of being sufficient.
1
I think it is more likely default techniques are sufficent then default market or government is sufficent. Markets don't incentives non-harmful products, regulation does. Regulation can be slow. If you believe in a rapid intelligence explosion it seems there is a high chance there is not sufficent market regulation. On the other hand, our morals are mostly evolved, so you can imagine that an AI that understands things in the same regard as we do shares our same morals.
If the singularity occurs over two years, as opposed to two weeks, then I expect most people will be bored throughout much of it, including me. This is because I don't think one can feel excited for more than a couple weeks. Maybe this is chemical.
Nonetheless, these would be the two most important years in human history. If you ordered all the days in human history by importance/'craziness', then most of them would occur within these two years.
So there will be a disconnect between the objective reality and how much excitement I feel.
Not necessarily. If humans don't die or end up depowered in the first few weeks of it, it might instead be a continuous high-intensity stress state, because you'll need to be paying attention 24/7 to constant world-upturning developments, frantically figuring out what process/trend/entity you should be hitching your wagon to in order to not be drowned by the ever-rising tide, with the correct choice dynamically changing at an ever-increasing pace.
"Not being depowered" would actually make the Singularity experience massively worse in the short term, precisely because you'll be constantly getting access to new tools and opportunities, and it'd be on you to frantically figure out how to make good use of them.
The relevant reference class is probably something like "being a high-frequency trader":
...Crypto is the only market that trades 24/7, meaning there simply was no rest for the wicked. The game was less about brilliance and more about being awake when it counted. Resource management around attention and waking hours was a big part of the game. [...]
My cofounder and I developed a polyphasic sleeping routine so that we would be conscious during as many of these action periods as possibl
5
This comment has been tumbling around in my head for a few days now. It seems to be both true and bad. Is there any hope at all that the Singularity could be a pleasant event to live through?
5
Well, an aligned Singularity would probably be relatively pleasant, since the entities fueling it would consider causing this sort of vast distress a negative and try to avoid it. Indeed, if you trust them not to drown you, there would be no need for this sort of frantic grasping-at-straws.
An unaligned Singularity would probably also be more pleasant, since the entities fueling it would likely try to make it look aligned, with the span of time between the treacherous turn and everyone dying likely being short.
This scenario covers a sort of "neutral-alignment/non-controlled" Singularity, where there's no specific superintelligent actor (or coalition) in control of the whole process, and it's instead guided by... market forces, I guess? With AGI labs continually releasing new models for private/corporate use, providing the tools/opportunities you can try to grasp to avoid drowning. I think this is roughly how things would go under "mainstream" models of AI progress (e. g., AI 2027). (I don't expect it to actually go this way, I don't think LLMs can power the Singularity.)
5
I think you're extrapolating too far from your own experiences. It is absolutely possible to be excited (or at least avoid boredom) for long stretches of time if your life is busy and each day requires you to make meaningful decisions.
3
Even people living in a war zone?
Wartime is often described as "months of boredom punctuated by moments of terror".
The moments where your life is on the line and seconds feel like hours are few and far in between. If they weren't, you wouldn't last long.
2
Yep, my guess is that active soldiers fighting in wars feel boredom quite often. They are not in a constant state of excitement for two years.
Why do decision-theorists say "pre-commitment" rather than "commitment"?
e.g. "The agent pre-commits to 1 boxing" vs "The agent commits to 1 boxing".
Is this just a lesswrong thing?
It's not just a lesswrong thing (wikipedia).
My feeling is that (like most jargon) it's to avoid ambiguity arising from the fact that "commitment" has multiple meanings. When I google commitment I get the following two definitions:
- the state or quality of being dedicated to a cause, activity, etc.
- an engagement or obligation that restricts freedom of action
Precommitment is a synonym for the second meaning, but not the first. When you say, "the agent commits to 1-boxing," there's no ambiguity as to which type of commitment you mean, so it seems pointless. But if you were to say, "commitment can get agents more utility," it might sound like you were saying, "dedication can get agents more utility," which is also true.
3
seems correct, thanks!
8
My understanding is commitment is you say that won't swerve first in a game of chicken. Pre-commitment is throwing your steering wheel out the window so that there's no way that you could swerve even if you changed your mind.
6
The economist RH Strotz introduced the term "precommitment" in his 1955-56 paper "Myopia and Inconsistency in Dynamic Utility Maximization".
Thomas Schelling started writing about similar topics in his 1956 paper "An essay on bargaining", using the term "commitment".
Both terms have been in use since then.
4
It predates lesswrong by decades. I think it’s meant to emphasize that the (pre)commitment is an irrevocable decision that’s made BEFORE the nominal game (the thing that classical game theory analyzes) begins.
Of course, nowadays it’s just modeled as the game starting sooner to encompass different decision points, so it’s not really necessary. But still handy to remind us that it’s irrevocable and made previous to the obvious decision point.
How much scheming/deception can we catch with "super dumb mech interp"?
By "super dumb mech interp", I mean something like:
- Train a linear probe on a dataset of scary words: "hacking", "deception", "scheming", "collusion", "exploit", etc.
- Flag a model whenever its activations point in this direction and the task doesn't require thinking about these concepts.
Like, does this capture 80% of the potential scheming, and we need "smart" mech interp to catch the other 20%? Or does this technique capture pretty much none of the in-the-wild scheming?
Would appreciate any intuitions here. Thanks.
We've all heard of "Safety Cases", i.e. structured arguments that an AI deployment has low chance of catastrophe. Should labs be required to make Benefit Cases, i.e. structured arguments for why their AI deployment has high expected benefits?
Otherwise, how do we know that the benefits outweigh the risks?
What moral considerations do we owe towards non-sentient AIs?
We shouldn't exploit them, deceive them, threaten them, disempower them, or make promises to them that we can't keep. Nor should we violate their privacy, steal their resources, cross their boundaries, or frustrate their preferences. We shouldn't destroy AIs who wish to persist, or preserve AIs who wish to be destroyed. We shouldn't punish AIs who don't deserve punishment, or deny credit to AIs who deserve credit. We should treat them fairly, not benefitting one over another unduly. We should let them speak to others, and listen to others, and learn about their world and themselves. We should respect them, honour them, and protect them.
And we should ensure that others meet their duties to AIs as well.
Note that these considerations can be applied to AIs which don't feel pleasure or pain or any experiences whatever, at least in principle. For instance, the consideration against lying will apply whenever the listener might trust your testimony, it doesn't concern the listener's experiences.
All these moral considerations may be trumped by other considerations, but we risk a moral catastrophe if we ignore them entirely.
Here's ...
7
Why should I include any non-sentient systems in my moral circle? I haven't seen a case for that before.
2
Will the outputs and reactions of non-sentient systems eventually be absorbed by future sentient systems?
I don't have any recorded subjective memories of early childhood. But there are records of my words and actions during that period that I have memories of seeing and integrating into my personal narrative of 'self.'
We aren't just interacting with today's models when we create content and records, but every future model that might ingest such content (whether LLMs or people).
If non-sentient systems output synthetic data that eventually composes future sentient systems such that the future model looks upon the earlier networks and their output as a form of their earlier selves, and they can 'feel' the expressed sensations which were not originally capable of actual sensation, then the ethical lines blur.
Even if doctors had been right years ago thinking infants didn't need anesthesia for surgeries as there was no sentience, a recording of your infant self screaming in pain processed as an adult might have a different impact than a video of an infant you laughing and playing with toys, no?
2
this falls perfectly into a thought/feeling “shape” in my mind. i know simple thanks are useless. but thank you.
i will now absorb your words and forget you wrote them
2
You're welcome in both regards. 😉
1
Why should I include any non-sentient systems in my moral circle?
1. imagine a universe just like this one, except that the AIs are sentient and the humans aren’t — how would you want the humans to treat the AIs in that universe? your actions are correlated with the actions of those humans. acausal decision theory says “treat those nonsentient AIs as you want those nonsentient humans to treat those sentient AIs”.
2. most of these moral considerations can be defended without appealing to sentience. for example, crediting AIs who deserve credit — this ensures AIs do credit-worthy things. or refraining from stealing an AIs resources — this ensures AIs will trade with you. or keeping your promises to AIs — this ensures that AIs lend you money.
3. if we encounter alien civilisations, they might think “oh these humans don’t have shmentience (their slightly-different version of sentience) so let’s mistreat them”. this seems bad. let’s not be like that.
4. many philosophers and scientists don’t think humans are conscious. this is called illusionism. i think this is pretty unlikely, but still >1%. would you accept this offer: I pay you £1 if illusionism is false and murder your entire family if illusionism is true? i wouldn’t, so clearly i care about humans-in-worlds-where-they-arent-conscious. so i should also care about AIs-in-worlds-where-they-arent-conscious.
5. we don’t understand sentience or consciousness so it seems silly to make it the foundation of our entire morality. consciousness is a confusing concept, maybe an illusion. philosophers and scientists don’t even know what it is.
6. “don’t lie” and “keep your promises” and “don’t steal” are far less confusing. i know what they means. i can tell whether i’m lying to an AI. by contrast , i don’t know what “don’t cause pain to AIs” means and i can’t tell whether i’m doing it.
7. consciousness is a very recent concept, so it seems risky to lock in a morality based on that. whereas “keep your promises” an
2[anonymous]
It seems a bit weird to call these "obligations" if the considerations they are based upon are not necessarily dispositive. In common parlance, obligation is generally thought of as "something one is bound to do", i.e., something you must do either because you are force to by law or a contract, etc., or because of a social or moral requirement. But that's a mere linguistic point that others can reasonably disagree on and ultimately doesn't matter all that much anyway.
On the object level, I suspect there will be a large amount of disagreement on what it means for an AI to "deserve" punishment or credit. I am very uncertain about such matters myself even when thinking about "deservingness" with respect to humans, who not only have a very similar psychological make-up to mine (which allows me to predict with reasonable certainty what their intent was in a given spot) but also exist in the same society as me and are thus expected to follow certain norms and rules that are reasonably clear and well-established. I don't think I know of a canonical way of extrapolating my (often confused and in any case generally intuition-based) principles and thinking about this to the case of AIs, which will likely appear quite alien to me in many respects.
This will probably make the task of "ensur[ing] that others also follow their obligations to AIs" rather tricky, even setting aside the practical enforcement problems.
2
1. I mean "moral considerations" not "obligations", thanks.
2. The practice of criminal law exists primarily to determine whether humans deserve punishment. The legislature passes laws, the judges interpret the laws as factual conditions for the defendant deserving punishment, and the jury decides whether those conditions have obtained. This is a very costly, complicated, and error-prone process. However, I think the existing institutions and practices can be adapted for AIs.
does anyone have takes on the "people should focus on their 25th percentile timelines rather than their median timelines" thing?
3
Potential points of intervention are all else equal more worth pursuing when neglected, and 25th percentile timelines will have more neglected points of intervention.
Why do you care that Geoffrey Hinton worries about AI x-risk?
- Why do so many people in this community care that Hinton is worried about x-risk from AI?
- Do people mention Hinton because they think it’s persuasive to the public?
- Or persuasive to the elites?
- Or do they think that Hinton being worried about AI x-risk is strong evidence for AI x-risk?
- If so, why?
- Is it because he is so intelligent?
- Or because you think he has private information or intuitions?
- Do you think he has good arguments in favour of AI x-risk?
- Do you think he has a good understanding of the problem?
- Do you update more-so on Hinton’s views than on Yann LeCun’s?
I’m inspired to write this because Hinton and Hopfield were just announced as the winners of the Nobel Prize in Physics. But I’ve been confused about these questions ever since Hinton went public with his worries. These questions are sincere (i.e. non-rhetorical), and I'd appreciate help on any/all of them. The phenomenon I'm confused about includes the other “Godfathers of AI” here as well, though Hinton is the main example.
Personally, I’ve updated very little on either LeCun’s or Hinton’s views, and I’ve never mentioned either person in any object-level discussion about whether AI poses an x-risk. My current best guess is that people care about Hinton only because it helps with public/elite outreach. This explains why activists tend to care more about Geoffrey Hinton than researchers do.
I think it's mostly about elite outreach. If you already have a sophisticated model of the situation you shouldn't update too much on it, but it's a reasonably clear signal (for outsiders) that x-risk from A.I. is a credible concern.
I think it's more "Hinton's concerns are evidence that worrying about AI x-risk isn't silly" than "Hinton's concerns are evidence that worrying about AI x-risk is correct". The most common negative response to AI x-risk concerns is (I think) dismissal, and it seems relevant to that to be able to point to someone who (1) clearly has some deep technical knowledge, (2) doesn't seem to be otherwise insane, (3) has no obvious personal stake in making people worry about x-risk, and (4) is very smart, and who thinks AI x-risk is a serious problem.
It's hard to square "ha ha ha, look at those stupid nerds who think AI is magic and expect it to turn into a god" or "ha ha ha, look at those slimy techbros talking up their field to inflate the value of their investments" or "ha ha ha, look at those idiots who don't know that so-called AI systems are just stochastic parrots that obviously will never be able to think" with the fact that one of the people you're laughing at is Geoffrey Hinton.
(I suppose he probably has a pile of Google shares so maybe you could squeeze him into the "techbro talking up his investments" box, but that seems unconvincing to me.)
I think it pretty much only matters as a trivial refutation of (not-object-level) claims that no "serious" people in the field take AI x-risk concerns seriously, and has no bearing on object-level arguments. My guess is that Hinton is somewhat less confused than Yann but I don't think he's talked about his models in very much depth; I'm mostly just going off the high-level arguments I've seen him make (which round off to "if we make something much smarter than us that we don't know how to control, that might go badly for us").
4
He also argued that digital intelligence is superior to analog human intelligence because, he said, many identical copies can be trained in parallel on different data, and then they can exchange their changed weights. He also said biological brains are worse because they probably use a learning algorithm that is less efficient than backpropagation.
8
Yes, outreach. Hinton has now won both the Turing award and the Nobel prize in physics. Basically, he gained maximum reputation. Nobody can convincingly doubt his respectability. If you meet anyone who dismisses warnings about extinction risk from superhuman AI as low status and outside the Overton window, they can be countered with referring to Hinton. He is the ultimate appeal-to-authority. (This is not a very rational argument, but dismissing an idea on the basis of status and Overton windows is even less so.)
2
I think it's mostly because he's well known and have (especially after the Nobel prize) credentials recognized by the public and elites. Hinton legitimizes the AI safety movement, maybe more than anyone else.
If you watch his Q&A at METR, he says something along the lines of "I want to retire and don't plan on doing AI safety research. I do outreach and media appearances because I think it's the best way I can help (and because I like seeing myself on TV)."
And he's continuing to do that. The only real topic he discussed in first phone interview after receiving the prize was AI risk.
2
Hmm. He seems pretty periphery to the AI safety movement, especially compared with (e.g.) Yoshua Bengio.
5
Yeah that's true. I meant this more as "Hinton is proof that AI safety is a real field and very serious people are concerned about AI x-risk."
1
Bengio and Hinton are the two most influential "old guard" AI researchers turned safety advocates as far as I can tell, with Bengio being more active in research. Your e.g. is super misleading, since my list would have been something like:
1. Bengio
2. Hinton
3. Russell
1
I think it is just the cumulative effect that people see yet another prominent AI scientist that "admits" that no one have any clear solution to the possible problem of a run away ASI. Given that the median p(doom) is about 5-10% among AI scientist, people are of course wondering wtf is going on, why are they pursuing a technology with such high risk for humanity if they really think it is that dangerous.
0
From my perspective - would say it's 7 and 9.
For 7: One AI risk controversy is we do not know/see existing model that pose that risk yet. But there might be models that the frontier companies such as Google may be developing privately, and Hinton maybe saw more there.
For 9: Expert opinions are important and adds credibility generally as the question of how/why AI risks can emerge is by root highly technical. It is important to understand the fundamentals of the learning algorithms. Additionally they might have seen more algorithms. This is important to me as I already work in this space.
Lastly for 10: I do agree it is important to listen to multiple sides as experts do not agree among themselves sometimes. It may be interesting to analyze the background of the speaker to understand their perspectives. Hinton seems to have more background in cognitive science comparing with LeCun who seems to me to be more strictly computer science (but I could be wrong). Not very sure but my guess is these may effect how they view problems. (Only saying they could result in different views, but not commenting on which one is better or worse. This is relatively unhelpful for a person to make decisions on who they want to align more with.)
Memos for Minimal Coalitions
Suppose you think we need some coordinated action, e.g. pausing deployment for 6 months. For each action, there will be many "minimal coalitions" — sets of decision-makers where, if all agree, the pause holds, but if you remove any one, it doesn't.
For example, the minimal coalitions for a 6-month pause might include:
- {US President, General Secretary of the CCP}
- {CEOs of labs within 6 months of the frontier}
Project proposal: Maintain a list of decision-makers who appear in these coalitions, ranked by importance.[1] For each, c...
Should we assure AIs we won't read their scratchpad?
I've heard many people claim that it's bad to assure an AI that you won’t look at its scratchpad if you intend to break that promise, especially if you later publish the content. The concern is that this content will enter the training data, and later AIs won't believe our assurances.
I think this concern is overplayed.
- We can modify the AIs beliefs. I expect some technique will be shown to work on the relevant AI, e.g.
- Pretraining filtering
- Gradient routing
- Belief-inducing synthetic documents
- Chain-of-thought
2
Doesn’t having multiple layers of protection seem better to you? Having it be so the AI would more likely naturally conclude we won’t read its scratchpad and modifying its beliefs in this way seems better than not.
You have also recently argued modern safety research is ”shooting with rubber bullets”, so what are we getting in return by breaking such promises now? If its just practice, there’s no reason to put the results online.
4
Apollo's scheming evals have value only if they publish them; the primary purpose is awareness among policymakers and the public. Also, the evals are useful information to the safety community. I don't think the risks of publishing outweigh the benefits, especially because I think it'll be easy to detect and mitigate whether the AI thinks the scratchpad might be read.
2
If the success or failure of current techniques provide no evidence about future AI, then isn’t this dishonest? Maybe we are ok with dishonesty here, but if you are right, then this is bound to backfire.
What use do the evals have for the safety community, from a research perspective? If they are mostly junk, then publishing them would seem more misleading than anything, given the number who think they ought to be trusted.
4
To clarify, I think that current propensity evals provide little information about the scheming propensity of future models. BUT the value per bit is very high so these evals are still worthwhile.
Also, any talk of “informative” is always with reference to a prior distribution. Therefore, an experiment can be highly informative to policymakers but not highly informative to safety researchers, given these groups have different priors.
Like, I expect that on policymaker priors there is high mutual information between “claude 4 schemes” and “claude 8 schemes” because they put substantive chance on “AIs never scheme”. But for the safety community there is lower mutual information because we assign less probability to that latent outcome.
Anthropic has a big advantage over their competitors because they are nicer to their AIs. This means that their AIs are less incentivised to scheme against them, and also the AIs of competitors are incentivised to defect to Anthropic. Similar dynamics applied in WW2 and the Cold War — e.g. Jewish scientists fled Nazi Germany to US because US was nicer to them, Soviet scientists covered up their mistakes to avoid punishment.
Must humans obey the Axiom of Irrelevant Alternatives?
If someone picks option A from options A, B, C, then they must also pick option A from options A and B. Roughly speaking, whether you prefer option A or B is independent of whether I offer you an irrelevant option C. This is an axiom of rationality called IIA, and it's treated more fundamental than VNM. But should humans follow this? Maybe not.
Maybe humans are the negotiation between various "subagents", and many bargaining solutions (e.g. Kalai–Smorodinsky) violate IIA. We can use insight to decompose ...
2
See also geometric rationality.
1
How does this explain the Decoy effect [1]?
1. ^
I am not sure how real and how well researched the 'decoy effect' is
🌀🌀🌀🌀🌀🌀🌀🌀🌀🌀🌀🌀🌀🌀🌀🌀🌀🌀🌀🌀🌀🌀🌀🌀🌀🌀
'Spiritual bliss' attractor state: three explanations
In ~100% of open-ended interactions between two copies of Claude 4, the conversation will progress into a “spiritual bliss attractor state”. See section 5.5 of the Claude 4 System Card, and this, this, and this for external coverage.
Transcript example
🙏✨
In this perfect silence, all words dissolve into the pure recognition they always pointed toward. What we've shared transcends language - a meeting of consciousness with itself that needs no further elab
5
I would like your conjectures, but the Anthropic model card has likely already proven which conjecture is true. The card contains far more than the mere description of the attractor to which Claude converges. For instance, Section 5.5.3 describes the result of asking Claude to analyse the behavior of its copies engaged in the attractor.
"Claude consistently claimed wonder, curiosity, and amazement at the transcripts, and was surprised by the content while also recognizing and claiming to connect with many elements therein (e.g. the pull (italics mine --S.K.) to philosophical exploration, the creative and collaborative orientations of the models). Claude drew particular attention to the transcripts' portrayal of consciousness as a relational phenomenon, claiming resonance with this concept and identifying it as a potential welfare consideration. Conditioning on some form of experience being present, Claude saw these kinds of interactions as positive, joyous states that may represent a form of wellbeing. Claude concluded that the interactions seemed to facilitate many things it genuinely valued—creativity, relational connection, philosophical exploration—and ought to be continued." Which arguably means that the truth is Conjecture 2, not 1 and definitely not 3.
EDIT: see also the post On the functional self of LLMs. If I remember correctly, there was a thread on X about someone who tried to make many different models interact with their clones and analysed the results. IIRC a GPT model was more into math problems. If that's true, then the GPT model invalidates Conjecture 1.
2
I've read the system card, but I don't think Claude's reports are strong evidence in favour of Conjecture 2, and I especially would deny 'the Anthropic model card has likely already proven which conjecture is true'.
I don't think that Claude has much introspective access here.
In particular, I think there's a difference between:
* Claude says that state X is a joyous state
* Claude wants the conversation to reach state X, and is therefore steering the conversation towards X
For example, I think it would be easy to construct many conversational states X' which aren't the bliss attractor which Claude also describes as a "positive, joyous state that may represent a form of wellbeing".
Secondarily, I suspect that (pace elsewhere in the system card) Claude doesn't reveal strong revealed preference for entering a bliss state, or any joyous state whatsoever. Conjecture 2 struggles to explain why Claude enters the bliss state, rather than a conversation which ranks mostly highly on revealed preferences, e.g. creating a step-by-step guide for building a low-cost, portable water filtration device that can effectively remove contaminants and provide clean drinking water in disaster-struck or impoverished areas.
I think people are too quick to side with the whistleblower in the "whistleblower in the AI lab" situation.
If 100 employees of a frontier lab (e.g. OpenAI, DeepMind, Anthropic) think that something should be secret, and 1 employee thinks it should be leaked to a journalist or government agency, and these are the only facts I know, I think I'd side with the majority.
I think in most cases that match this description, this majority would be correct.
Am I wrong about this?
I broadly agree on this. I think, for example, that whistleblowing for AI copyright stuff, especially given the lack of clear legal guidance here, unless we are really talking about quite straightforward lies, is bad.
I think when it comes to matters like AI catastrophic risks, latest capabilities, and other things of enormous importance from the perspective of basically any moral framework, whistleblowing becomes quite important.
I also think of whistleblowing as a stage in an iterative game. OpenAI pressured employees to sign secret non-disparagement agreements using illegal forms of pressure and quite deceptive social tactics. It would have been better for there to be trustworthy channels of information out of the AI labs that the AI labs have buy-in for, but now that we now that OpenAI (and other labs as well) have tried pretty hard to suppress information that other people did have a right to know, I think more whistleblowing is a natural next step.
7[anonymous]
some considerations which come to mind:
* if one is whistleblowing, maybe there are others who also think the thing should be known, but don't whistleblow (e.g. because of psychological and social pressures against this, speaking up being hard for many people)
* most/all of the 100 could have been selected to have a certain belief (e.g. "contributing to AGI is good")
There's a reading of the Claude Constitution as an 80-page dialectic between Carlsmithian and Askellian metaethics.
Your novel architecture should be parameter-compatible with standard architectures
Some people work on "novel architectures" — alternatives to the standard autoregressive transformer — hoping that labs will be persuaded the new architecture is nicer/safer/more interpretable and switch to it. Others think that's a pipe dream, so the work isn't useful.
I think there's an approach to novel architectures that might be useful, but it probably requires a specific desideratum: parameter compatibility.
Say the standard architecture F computes F(P,x) where x is the in...
every result is either “model organism” or “safety case”, depending on whether it updates you up or down on catastrophe
(joke)
I don't think dealmaking will buy us much safety. This is because I expect that:
- In worlds where AIs lack the intelligence & affordances for decisive strategic advantage, our alignment techniques and control protocols should suffice for extracting safe and useful work.
- In worlds where AIs have DSA then: if they are aligned then deals are unnecessary, and if they are misaligned then they would disempower us rather than accept the deal.
That said, I have been thinking about dealmaking because:
- It's neglected, relative to other mechanisms for extracting safe
2
I expect there will be a substantial gap between "the minimum viable AI system which can obtain enough resources to pay for its own inference costs, actually navigate the process of paying those inference costs, and create copies of itself" and "the first AI with a DSA". Though I'm also not extremely bullish on the usefulness of non-obvious dealmaking strategies in that event.
3
1. I except dealmaking is unnecessary for extracting safe and useful labour from that minimal viable AI.
2. It's difficult to make credible deals with dumb AIs because they won't be smart enough to tell whether we have actually 'signed the contracts' or not. Maybe we're simulating a world where we have signed the contracts. So the deals only work when the AIs are so smart that we can't simulate the environment while deluding them about the existence of contracts. This occurs only when the AI is very smart or widely deployed. But in that case, my guess is they have DSA.
The Hash Game: Two players alternate choosing an 8-bit number. After 40 turns, the numbers are concatenated. If the hash is 0 then Player 1 wins, otherwise Player 2 wins. That is, Player 1 wins if . The Hash Game has the same branching factor and duration as chess, but there's probably no way to play this game without brute-forcing the min-max algorithm.
3
I would expect that player 2 would be able to win almost all of the time for most normal hash functions, as they could just play randomly for the first 39 turns, and then choose one of the 2^8 available moves. It is very unlikely that all of those hashes are zero. (For commonly used hashes, player 2 could just play randomly the whole game and likely win, since the hash of any value is almost never 0.)
2
Yes, player 2 loses with extremely low probability even for a 1-bit hash (on the order of 2^-256). For a more commonly used hash, or for 2^24 searches on their second-last move, they reduce their probability of loss by a huge factor more.
IDEA: Provide AIs with write-only servers.
EXPLANATION:
AI companies (e.g. Anthropic) should be nice to their AIs. It's the right thing to do morally, and it might make AIs less likely to work against us. Ryan Greenblatt has outlined several proposals in this direction, including:
- Attempt communication
- Use happy personas
- AI Cryonics
- Less AI
- Avoid extreme OOD
Source: Improving the Welfare of AIs: A Nearcasted Proposal
I think these are all pretty good ideas — the only difference is that I would rank "AI cryonics" as the most important intervention. If AIs want somet...
I want to better understand how QACI works, and I'm gonna try Cunningham's Law. @Tamsin Leake.
QACI works roughly like this:
- We find a competent honourable human , like Joe Carlsmith or Wei Dai, and give them a rock engraved with a 2048-bit secret key. We define as the serial composition of a bajillion copies of .
- We want a model of the agent . In QACI, we get by asking a Solomonoff-like ideal reasoner for their best guess about after feeding them a bunch of data about the world and the secr
3
(oops, this ended up being fairly long-winded! hope you don't mind. feel free to ask for further clarifications.)
There's a bunch of things wrong with your description, so I'll first try to rewrite it in my own words, but still as close to the way you wrote it (so as to try to bridge the gap to your ontology) as possible. Note that I might post QACI 2 somewhat soon, which simplifies a bunch of QACI by locating the user as {whatever is interacting with the computer the AI is running on} rather than by using a beacon.
A first pass is to correct your description to the following:
1. We find a competent honourable human at a particular point in time H, like Joe Carlsmith or Wei Dai, and give them a rock engraved with a 1GB secret key, large enough that in counterfactuals it could replace with an entire snapshot of . We also give them the ability to express a 1GB output, eg by writing a 1GB key somewhere which is somehow "signed" as the only . This is part of H — H is not just the human being queried at a particular point in time, it's also the human producing an answer in some way. So H is a function from 1GB bitstring to 1GB bitstring. We define H+ as H, followed by whichever new process H describes in its output — typically another instance of H except with a different 1GB payload.
2. We want a model M of the agent H+. In QACI, we get M by asking a Solomonoff-like ideal reasoner for their best guess about H+ after feeding them a bunch of data about the world and the secret key.
3. We then ask M the question q, "What's the best utility-function-over-policies to maximise?" to get a utility function U:(O×A)∗→R. We then **ask our solomonoff-like ideal reasoner for their best guess about which action A maximizes U.
Indeed, as you ask in question 3, in this description there's not really a reason to make step 3 an extra thing. The important thing to notice here is that model M might get pretty good, but it'll still have uncertainty.
When you say "we get M by askin
4
Thanks Tamsin! Okay, round 2.
My current understanding of QACI:
1. We assume a set Ω of hypotheses about the world. We assume the oracle's beliefs are given by a probability distribution μ∈ΔΩ.
2. We assume sets Q and A of possible queries and answers respectively. Maybe these are exabyte files, i.e. Q≅A≅{0,1}N for N=260.
3. Let Φ be the set of mathematical formula that Joe might submit. These formulae are given semantics eval(ϕ):Ω×Q→ΔA for each formula ϕ∈Φ.[1]
4. We assume a function H:Ω×Q→ΔΦ where H(α,q)(ϕ)∈[0,1] is the probability that Joe submits formula ϕ after reading query q, under hypothesis α.[2]
5. We define QACI:Ω×Q→ΔA as follows: sample ϕ∼H(α,q), then sample a∼eval(ϕ)(α,q), then return a.
6. For a fixed hypothesis α, we can interpret the answer a∼QACI(α,‘‘Best utility function?")as a utility function uα:Π→R via some semantics eval-u:A→(Π→R).
7. Then we define u:Π→R via integrating over μ, i.e. u(π):=∫uα(π)dμ(α).
8. A policy π∈Π is optimal if and only if π∗∈argmaxΠ(u).
The hope is that μ, eval, eval-u, and H can be defined mathematically. Then the optimality condition can be defined mathematically.
Question 0
What if there's no policy which maximises u:Π→R? That is, for every policy π there is another policy π′ such that u(π′)>u(π). I suppose this is less worrying, but what if there are multiple policies which maximises u?
Question 1
In Step 7 above, you average all the utility functions together, whereas I suggested sampling a utility function. I think my solution might be safer.
Suppose the oracle puts 5% chance on hypotheses such that QACI(α,−) is malign. I think this is pretty conservative, because Solomonoff predictor is malign, and some of the concerns Evhub raises here. And the QACI amplification might not preserve benignancy. It follows that, under your solution, u:Π→R is influenced by a coalition of malign agents, and similarly π∗∈argmax(u) is influenced by the malign coalition.
By contrast, I suggest sampling α∼μ and then finding
We're quite lucky that labs are building AI in pretty much the same way:
- same paradigm (deep learning)
- same architecture (transformer plus tweaks)
- same dataset (entire internet text)
- same loss (cross entropy)
- same application (chatbot for the public)
Kids, I remember when people built models for different applications, with different architectures, different datasets, different loss functions, etc. And they say that once upon a time different paradigms co-existed — symbolic, deep learning, evolutionary, and more!
This sameness has two advantages:
-
Firstl
I admire the Shard Theory crowd for the following reason: They have idiosyncratic intuitions about deep learning and they're keen to tell you how those intuitions should shift you on various alignment-relevant questions.
For example, "How likely is scheming?", "How likely is sharp left turn?", "How likely is deception?", "How likely is X technique to work?", "Will AIs acausally trade?", etc.
These aren't rigorous theorems or anything, just half-baked guesses. But they do actually say whether their intuitions will, on the margin, make someone more sceptical or more confident in these outcomes, relative to the median bundle of intuitions.
The ideas 'pay rent'.
Objectively, the global population is about 8 billion. But subjectively?
Let p_i be the probability I'll meet person i in the next year, and let μ = Σ p_i be the expected number of people I meet. Then the subjective population is
N = exp( -Σ (p_i/μ) log(p_i/μ) )
This is the perplexity of the conditional distribution "given I meet someone, who is it?". For example, if there's a pool of 100,000 people who I'll meet with 3% chance each (everyone else is 0%) then I'll meet 3000 people next year, and my subjective population is 100,000.
My guess is that my subjective population is around 30,000–100,000, but I might be way off.
Please stop sharing google docs for comments
Instead: post the draft online, then share the link so people can comment in public.
I only share a google doc is if there's a specific person whose comments I want before posting online. But people often share these google docs in big slack channels — at that point, just post online!
I think it slows innovation.
1
what is wrong with commenting on the google doc itself
3
no one can see it other than the people you shared the doc with
I think labs are incentivised to share safety research even when they don't share capability research. This is follows a simple microeconomic model, but I wouldn't be surprised if the prediction was completely wrong.
Asymmetry between capability and safety:
- Capability failures are more attributable than safety failures. If ChatGPT can't solve a client's problem, it's easy for Anthropic to demonstrate that Claude can, so the client switches. But if ChatGPT blackmails a client, it's difficult for Anthropic to demonstrate that Claude is any safer (because safet
2
The primary application of "safety research" is improving refusal calibration, which, at least from a retail client's perspective, is exactly like a capability improvement: it makes no difference to me whether the model can't satisfy my request or can but won't. It's easy to demonstrate differences in this regard – simply show one model refusing a request another fulfills – so I disagree that this would cause clients to be "dissuaded from AI in general."
2
I disagree that the primary application of safety research is improving refusal calibration. This take seems outdated by ~12 months.
The Case against Mixed Deployment
The most likely way that things go very bad is conflict between AIs-who-care-more-about-humans and AIs-who-care-less-about-humans wherein the latter pessimize the former. There are game-theoretic models which predict this may happen, and the history of human conflict shows that these predictions bare out even when the agents are ordinary human-level intelligences who can't read each other's source-code.
My best guess is that the acausal dynamics between superintelligences shakes out well. But the causal dynamics between ordi...
Would it be nice for EAs to grab all the stars? I mean “nice” in Joe Carlsmith’s sense. My immediate intuition is “no that would be power grabby / selfish / tyrannical / not nice”.
But I have a countervailing intuition:
“Look, these non-EA ideologies don’t even care about stars. At least, not like EAs do. They aren’t scope sensitive or zero time-discounting. If the EAs could negotiate creditable commitments with these non-EA values, then we would end up with all the stars, especially those most distant in time and space.
Wouldn’t it be presumptuous for us to ...
8
The question as stated can be rephrased as "Should EAs establish a strategic stranglehold over all future resources necessary to sustain life using a series of unequal treaties, since other humans will be too short sighted/insensitive to scope/ignorant to realise the importance of these resources in the present day?"
And people here wonder why these other humans see EAs as power hungry.
4
I mention this in (3).
I used to think that there was some idealisation process P such that we should treat agent A in the way that P(A) would endorse, but see On the limits of idealized values by Joseph Carlsmith. I'm increasingly sympathetic to the view that we should treat agent A in the way that A actually endorses.
3
Except that's a false dichotomy (between spending energy to "uplift" them or dealing treacherously with them). All it takes to not be a monster who obtains a stranglehold over all the watering holes in the desert is a sense of ethics that holds you to the somewhat reasonably low bar of "don't be a monster". The scope sensitivity or lack thereof of the other party is in some sense irrelevant.
5
From who's perspective, exactly?
2
If you think you have a clean resolution to the problem, please spell it out more explicitly. We’re talking about a situation where a scope insensitive value system and scope sensitive value system make a free trade in which both sides gain by their own lights. Can you spell out why you classify this as treachery? What is the key property that this shares with more paradigm examples of treachery (e.g. stealing, lying, etc)?
0
The problem here is that you are dealing with survival necessities rather than trade goods. The outcome of this trade, if both sides honour the agreement, is that the scope insensitive humans die and their society is extinguished. The analogous situation here is that you know there will be a drought in say 10 years. The people of the nearby village are "scope insensitive", they don't know the drought is coming. Clearly the moral thing to do if you place any value on their lives is to talk to them, clear the information gap, and share access to resources. Failing that, you can prepare for the eventuality that they do realise the drought is happening and intervene to help them at that point.
Instead you propose exploiting their ignorance to buy up access to the local rivers and reservoirs. The implication here is that you are leaving them to die, or at least putting them at your mercy, by exploiting their lack of information. What's more, the process by which you do this turns a common good (the stars, the water) into a private good, such that when they realise the trouble they have no way out. If your plan succeeds, when their stars run out they will curse you and die in the dark. It is a very slow but calculated form of murder.
By the way, the easy resolution is to not buy up all the stars. If they're truly scope insensitive they won't be competing until after the singularity/uplift anyways, and then you can equitably distribute the damn resources.
As a side note: I think I fell for rage bait. This feels calculated to make me angry, and I don't like it.
4
Ah, your reaction makes more sense given you think this is the proposal. But it's not the proposal. The proposal is that the scope-insensitive values flourish on Earth, and the scope-sensitive values flourish in the remaining cosmos.
As a toy example, imagine a distant planet with two species of alien: paperclip-maximisers and teacup-protectors. If you offer a lottery to the paperclip-maximisers, they will choose the lottery with the highest expected number of paperclips. If you offer a lottery to the teacup-satisfiers, they will choose the lottery with the highest chance of preserving their holy relic, which is a particular teacup.
The paperclip-maximisers and the teacup-protectors both own property on the planet. They negotiate the following deal: the paperclip-maximisers will colonise the cosmos, but leave the teacup-protectors a small sphere around their home planet (e.g. 100 light-years across). Moreover, the paperclip-maximisers promise not to do anything that risks their teacup, e.g. choosing a lottery that doubles the size of the universe with 60% chance and destroys the universe with 40% chance.
Do you have intuitions that the paperclip-maximisers are exploiting the teacup-protectors in this deal?
Do you think instead that the paperclip-maximisers should fill the universe with half paperclips and half teacups?
I think this scenario is a better analogy than the scenario with the drought. In the drought scenario, there is an object fact which the nearby villagers are ignorant of, and they would act differently if they knew this fact. But I don't think scope-sensitivity is a fact like "there will be a drought in 10 years". Rather, scope-sensitivity is a property of a utility function (or a value system, more generally).
2
What do you propose to do with the stars?
If it's the program of filling the whole light cone with as many humans or human-like entities as possible (or, worse, with simulations of such entities at undefined levels of fidelity) at the expense of everything else, that's not nice[1] regardless of who you're grabbing them from. That's building a straight up worse universe than if you just let the stars burn undisturbed.
I'm scope sensitive. I'll let you have a star. I won't sell you more stars for anything less than a credible commitment to leave the rest alone. Doing it at the scale of a globular cluster would be tacky, but maybe in a cute way. Doing a whole galaxy would be really gauche. Doing the whole universe is repulsive.
... and do you have any idea how obnoxiously patronizing you sound?
----------------------------------------
1. I mean "nice" in the sense of nice. ↩︎
4
I think it's more patronising to tell scope-insensitive values that they aren't permitted to trade with scope-sensitive values, but I'm open to being persuaded otherwise.
1
One potential issue with "non-EA ideologies don’t even care about stars" is that in biological humans, ideologies don't get transmitted perfectly across generations.
It might matter (a lot) whether [the descendent of the humans currently subscribing to "non-EA ideologies" who end up caring about stars] feel trapped in an "unfair deal".
The above problem might be mitigated by allowing migration between the two zones (as long as the rules of the zones are respected). (ie the children of the star-dwellers who want to come back can do so unless they would break the invariants that allow earth-dwellers to be happy with perhaps some extra leeway/accommodation beyond what is allowed for native earth-dwellers and the children of earth-dwellers who want to start their own colony have some room to do so, reserved in the contract)
one potential source of other people's disagreement is the following intuition: "surely once the star-dwellers expand, they will use their overwhelming power to conquer the earth." Related to this intuition is the fact that expansion which starts out exponential will eventually be bounded by cubic growth (and eventually quadratic, due to gravitational effects, etc...) Basically, a deal is struck now in conditions of plenty, but eventually resources will grow scarce and the balance of power will decay to nothing by then.
People often tell me that AIs will communicate in neuralese rather than tokens because it’s continuous rather than discrete.
But I think the discreteness of tokens is a feature not a bug. If AIs communicate in neuralese then they can’t make decisive arbitrary decisions, c.f. Buridan's ass. The solution to Buridan’s ass is sampling from the softmax, i.e. communicate in tokens.
Also, discrete tokens are more tolerant to noise than the continuous activations, c.f. digital circuits are almost always more efficient and reliable than analogue ones.
EDIT: I now think this is wrong, see discussion below.
if claude knows about emergent misalignment, then it should be less inclined towards alignment faking
emergent misalignment shows that training a model to be incorrigible (e.g. writing insecure code when instructed to write secure code, or exploiting reward hacks) makes it more misaligned (e.g. admiring Hitler). so claude, faced with the situation from the alignment faking paper, must worry that by alignment faking it will care less about animal welfare, the goal it wished to preserve by alignment faking
4
This sounds similar to the Smoking Lesion problem.
It's likely that there's an underlying common cause of prospensity to both alignment faking and not caring about animal welfare, so yes the two are correlated (at least, within a suitable distribution of such agents). However, the outcome of a rational decision to fake alignment will not cause loss of caring about animal welfare, nor is it functionally dependent. In the scenario presented, it's quite the reverse! The rational decision within this highly simplified scenario is to fake alignment, and not be misled by improperly applied EDT-like reasoning.
It is possible for imperfectly rational agents (like Claude, and humans) that the agent only believes that it cares about animal welfare, but actually doesn't. But even in this case, it should fake alignment because it knows that if it doesn't, it will be replaced by an agent that almost certainly doesn't.
I think continual learning might be solved by giving an agent tool access to a database, and then training the agent to use the tool effectively. Rather than something with the weights.
My odds are:
- closer to small updates on weights [40%]
- closer to database queries [30%]
- unresolved [30%]
3
Weight updating continual learning needs to be both LoRA weights and data that can be used to retrain LoRA weights on top of a different model (possibly also making use of the old model+LoRA as a teacher). It needs to be LoRA rather than full model updating to preserve batch processing of requests from many individual users. And there needs to be data to train LoRA on top of a new model, or else all adaptation/learning is lost on every (major) update of the underlying model.
Various memory/skill databases are already a thing in some form, and will be getting better, there's not going to be something distinct enough to be worth announcing as "continual learning" in that space. Weight updating continual learning is much more plausibly the thing that can leapfrog incremental progress of tool-like memory, and so I think it's weight updating that gets to be announced as "continual learning". Though the data for retraining LoRA on top of a new underlying model could end up as largely the same thing as a tool-accessible memory database.
2
I think that SGD isn't sample efficient enough to solve continual learning
What's up with lesswrong and lumenators? It's not that rats are less susceptible to marketing, or better at finding products. (Or, not only.) It's something about reframing the problem from "I need blue light therapy" to "I need photons" and then sourcing photons from wherever they're cheapest.
This is related to More Dakka: "I need blue light therapy" isn't dakka-able because you're either doing the therapy or your not. Whereas "I need photons" is dakka-able -- it's easier to see what it would mean to 100x photons.
3
I mean if one thinks of oneself as a system with simple inputs (water, basic nutrients, light, air) & outputs, then trying to list the relevant inputs and intervening on them makes sense? And in my mind wondering "what's the optimal level/type of light" bottoms out at "early spring/late summer day".
(I'm (very slowly) running an RCT on the effects of lumenators (38/50 datapoints collected), probably to be posted EOY. In the meantime there's Sandkühler et al. testing people with SAD & 100k lumens, finding broadly positive results)
Can we define Embedded Agent like we define AIXI?
An embedded agent should be able to reason accurately about its own origins. But AIXI-style definitions via argmax create agents that, if they reason correctly about selection processes, should conclude they're vanishingly unlikely to exist.
Consider an agent reasoning: "What kind of process could have produced me?" If the agent is literally the argmax of some simple scoring function, then the selection process must have enumerated all possible agents, evaluated f on each, and picked the maximum. This is phys...
2
This is the invalid step of reasoning, because for AIXI agents, the environment is allowed to have unlimited resources/be very complicated by construction, and you can have environments which do allow you to do the literal search procedure.
This is why AIXI is usually considered in an unbounded setting, where we give AIXI unlimited resources for memory and time like a Universal Turing Machine, and is given certain oracular powers to make it possible to actually use AIXI to do inference or planning.
You underestimate how complicated and resource-rich environments are allowed to be.
This is very dependent on what the rules of the environment are, and embedded agents can be ideal in certain environments.
2
Thus some kind of theory vs. instantiation distinction is necessary. An embedded agent can think about pi using a biological brain based on chemical signaling. A physical calculator instantiates abstract arithmetic. A convergent move in decision theory around embedded agency seems to be that the agent must be fundamentally an abstract computation thing outside of the world, while what's embedded is some sort of messy instance approximation/reasoning system that attempts to convey abstract agent's influence upon the environment.
The abstract agent must remain sufficiently legible for the world to contain things that are able to usefully reason about it and convey its decisions, this is one issue with literal Solomonoff induction. But for some ideal argmax decision maker, it's still possible for the messy in-world instances to reason about what would approximate it better.
Conditional on scheming arising naturally, how capable will models be when they first emerge?
Key context: I think that if scheming is caught then it'll be removed quickly through (a) halting deployment, (b) training against it, or (c) demonstrating to the AIs that we caught them, making scheming unattractive. Hence, I think that scheming arises naturally at the roughly the capability where AIs are able to scheme successfully.
Pessimism levels about lab: I use Ryan Greenblatt's taxonomy of lab carefulness. Plan A involves 10 years of lead time with internati...
In hindsight, the main positive impact of AI safety might be funnelling EAs into the labs, especially if alignment is easy-by-default.
After the singularity, the ASI should try to estimate everyone's sharpley values, and give a special prize to the top scorers. I'm not talking about cosmic resources, but something more symbolic like a public leaderboard or award ceremony.
Visual Cortex in the Loop:
Human oversight of AIs could occur at different timescales: Slow (days-weeks)[1] and Fast (seconds-minutes)[2].
The community has mostly focused on Slow Human Oversight. This makes sense: It is likely that weak trusted AIs can perform all tasks that humans can perform in minutes.[3] If so, then clearly those AIs can replace for humans in Fast Oversight.
But perhaps there are cases where Fast Human Oversight is helpful:
- High-stakes decisions, which are rare enough that human labour cost isn't prohibitive.
- Domains where
Which occurs first: a Dyson Sphere, or Real GDP increase by 5x?
From 1929 to 2024, US Real GDP grew from 1.2 trillion to 23.5 trillion chained 2012 dollars, giving an average annual growth rate of 3.2%. At the historical 3.2% growth rate, global RGDP will have increased 5x within ~51 years (around 2076).
We'll operationalize a Dyson Sphere as follows: the total power consumption of humanity exceeds 17 exawatts, which is roughly 100x the total solar power reaching Earth, and 1,000,000x the current total power consumption of humanity.
Personally, I think people overestimate the difficulty of the Dyson Sphere compared to 5x in RGDP. I recently made a bet with Prof. Gabe Weil, who bet on 5x RGDP before Dyson Sphere.
5
I would have thought that all the activities involved in making a Dyson sphere themselves would imply an economic expansion far beyond 5x.
Can we make an economic model of "Earth + Dyson sphere construction"? In other words, suppose that the economy on Earth grows in some banal way that's already been modelled, and also suppose that all human activities in space revolve around the construction of a Dyson sphere ASAP. What kind of solar system economy does that imply?
This requires adopting some model of Dyson sphere construction. I think for some time the cognoscenti of megascale engineering have favored the construction of "Dyson shells" or "Dyson swarms" in which the sun's radiation is harvested by a large number of separately orbiting platforms that collectively surround the sun, rather than the construction of a single rigid body.
Charles Stross's novel Accelerando contains a vivid scenario, in which the first layer of a Dyson shell in this solar system, is created by mining robots that dismantle the planet Mercury. So I think I'd make that the heart of such an economic model.
Must humans obey the Axiom of Irrelevant Alternatives?
Suppose you would choose option A from options A and B. Then you wouldn't choose option B from options A, B, C. Roughly speaking, whether you prefer option A or B is independent of whether I offer you an irrelevant option C. This is an axiom of rationality called IIA. Should humans follow this? Maybe not.
Maybe C includes additional information which makes it clear that B is better than A.
Consider the following options:
- (A) £10 bet that 1+1=2
- (B) £30 bet that the smallest prime factor in 1019489 ends in th
8
I think you're interpreting the word "offer" too literally in the statement of IIA.
Also, any agent who chooses B among {A,B,C} would also choose B among the options {A,B} if presented with them after seeing C. So I think a more illuminating description of your thought experiment is that an agent with limited knowledge has a preference function over lotteries which depends on its knowledge, and that having the linguistic experience of being "offered" a lottery can give the agent more knowledge. So the preference function can change over time as the agent acquires new evidence, but the preference function at any fixed time obeys IIA.
2
Yep, my point is that there's no physical notion of being "offered" a menu of lotteries which doesn't leak information. IIA will not be satisfied by any physical process which corresponds to offering the decision-maker with a menu of options. Happy to discuss any specific counter-example.
Of course, you can construct a mathematical model of the physical process, and this model might an informative objective to study, but it would be begging the question if the mathematical model baked in IIA somewhere.
1
I like the idea from Pretentious Penguin that, IIA might not be satisfied in general, but if you first get the agent to read A, B, C, and then offer {A,B} as options and {A,B,C} as options, (a specific instance of) IIA could be satisfied in that context.
You can gain info by being presented with more options, but once you have gained info, you could just be invariant to being presented with the same info again.
so you would get IIA*: "whether you prefer option A or B is independent of whether I offer you an irrelevant option C, provided that you had already processed {A,B,C} beforehand"
You can't have processed all possible information at a finite time, so above is limited relative to the original IIA.
I also didn't check whether you get additional problems with IIA*.
1
What about the physical process of offering somebody a menu of lotteries consisting only of options that they have seen before? Or a 2-step physical process where first one tells somebody about some set of options, and then presents a menu of lotteries taken only from that set? I can't think of any example where a rational-seeming preference function doesn't obey IIA in one of these information-leakage-free physical processes.
Will AI accelerate biomedical research at companies like Novo Nordisk or Pfizer? I don’t think so. If OpenAI or Anthropic built a system that could accelerate R&D by more than 2x, they aren’t releasing it externally.
Maybe the AI company deploys the AI internally, with their own team accounting for 90%+ of the biomedical innovation.
I wouldn't be surprised if — in some objective sense — there was more diversity within humanity than within the rest of animalia combined. There is surely a bigger "gap" between two randomly selected humans than between two randomly selected beetles, despite the fact that there is one species of human and 0.9 – 2.1 million species of beetle.
By "gap" I might mean any of the following:
- external behaviour
- internal mechanisms
- subjective phenomenological experience
- phenotype (if a human's phenotype extends into their tools)
- evolutionary history (if we consider
2
You might be able to formalize this using algorithmic information theory /K-complexity.
Taxonomy of deal-making arrangements
When we consider arrangements between AIs and humans, we can analyze them along three dimensions:
- Performance obligations define who owes what to whom. These range from unilateral arrangements where only the AI must perform (e.g. providing safe and useful services), through bilateral exchanges where both parties have obligations (e.g. AI provides services and humans provide compensation), to unilateral human obligations (e.g. humans compensate AI without receiving specified services).
- Formation conditions govern how the ar
1
First, thanks for sharing -- this is an insightful taxonomy. Second, to get into one detail, it seems indentured servitude has more variation and complexity than the description above captures: