I’ve been having some productive back-and-forth with Sami Petersen about his Invulnerable Incomplete Preferences (which is intended to complement Elliot Thornley’s approach to the Shutdown Problem). This post is a (non-formal) distillation of some useful pieces which I’ve gotten out of that discussion so far.
The Shutdown Problem
Conceptually: we want to equip a powerful AI with a shutdown button. If and when the button is unpressed, we want the AI to follow one goal (we’ll call it the “on-goal”). If and when the button is pressed, we want the AI to follow a different goal (we’ll call it the “off-goal”). Presumably the off-goal involves the AI shutting down itself and all its associated tools/children/etc, but that part’s flavor text for current purposes.
The key failure mode we want to avoid here is accidentally incentivizing the AI to manipulate the shutdown button - i.e. either cause it to be pressed, or cause it to be unpressed. Why would that happen? Well, suppose that when we first turn on the AI, it is just optimizing for the on-goal. The AI realizes that, if the button is pressed, its future self will stop optimizing for the on-goal, and therefore it will achieve lower performance on the on-goal. So, the AI realizes that it can achieve better performance on the on-goal by preventing the button from being pressed. And since it’s just optimizing for performance on the on-goal, it then prevents the button from being pressed.
MIRI’s paper on the shutdown problem goes through more examples of simple proposals for the shutdown problem, and how they incentivize button manipulation of one sort or another. It turns out that it’s generally Hard to get the desired behavior (i.e. no button manipulation) out of any expected utility maximizer.
Why It’s Hard, Level 1: Desired Behavior Implies Incomplete Revealed Preferences
Why is it hard to get an expected utility maximizer to not manipulate the button (while still doing useful stuff otherwise)? Here’s one intuitive answer I got out of the discussion with Sami.
The central idea is to ask what the behavior we want from the shutdown-button-agent implies about that agent’s revealed preferences.
Suppose that, at various times, the agent is offered opportunities to spend resources in order to cause the button to be pushed/unpushed. We want the agent to turn down such opportunities, in both directions - implying either indifference or lack of preference in any revealed preferences. Further, we do want the agent to spend resources to cause various different outcomes within the button-pressed or button-unpressed worlds, so there's nontrivial revealed preference ordering within button-pressed worlds and within button-unpressed worlds. But if the agent is to turn down costly opportunities to cause the button to be pressed/unpressed, and those opportunities jump between enough different pressed-outcome and unpressed-outcome pairs (which themselves each have nontrivial revealed preferences), then there's going to be a revealed preference gap - i.e. the behavior cannot be represented by complete preferences, only incomplete preferences.
Visually:
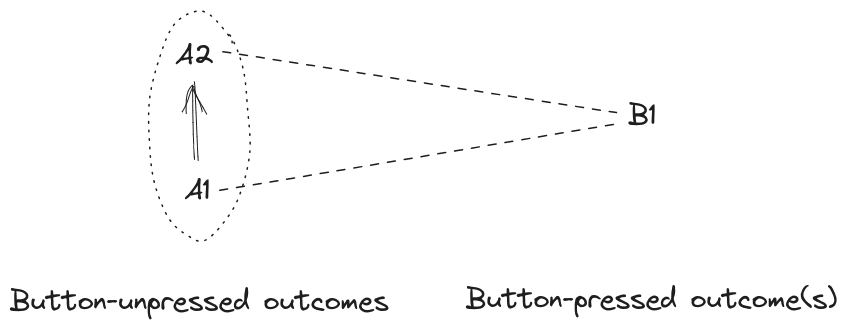
We want the agent to spend resources to move from outcome A1 to A2, within the button-unpressed worlds, so it has a revealed preference there. But we want the agent to not spend resources to move between A1 and B, in either direction - so it has either revealed indifference (assuming the agent has nonzero bid/ask spread), or revealed incompleteness of preferences, between A1 and B1. By the same logic, there’s also either revealed indifference or incompleteness between A2 and B1. But since the agent has a revealed preference for A2 over A1, any revealed preference assignment cannot be indifferent between both A1/B1 and A2/B1; that would imply indifference between A1 and A2. So the agent’s revealed preferences must be incomplete.[1]
Upshot: (one way to frame) the reason that the shutdown problem is difficult/interesting in the first place, is that the desired behavior implies a revealed preference gap. Insofar as e.g. any standard expected utility maximizer cannot have a revealed preference gap, such standard EU maximizers cannot behave the way we want.
Some notes on this:
- Revealed preferences might be very underdetermined, i.e. there may be many assignments of preferences compatible with an agent’s behavior. The argument above says that any assignment of preferences consistent with the desired behavior must be incomplete.
- Note that the story implicitly routes above routes through causal interventions/counterfactuals to probe preferences - i.e. we’re interested in whether the agent will spend resources to cause the button to be pressed/unpressed. That won’t be very relevant for this post, but may be important for people aiming to formalize all this.
- Apparently sometimes people take “no preference” (i.e. incompleteness) between A and B to mean that an agent chooses randomly/arbitrarily between the two. That is not the notion of “no preference” of relevance here; we’re talking about “no preference” as in “the agent will not give up either to gain the other, given the opportunity”.
Ok, so now we have a relatively intuitive story for why it’s Hard to get an expected utility maximizer to behave the way we want in the shutdown problem: insofar as EU maximizers don’t have revealed preference gaps, they can’t behave the way we want. (More generally, if we’re training an agent, any one-dimensional reward signal presumably cannot incentivize a revealed preference gap.) But then presumably the solution is to just… use an agent with incomplete preferences?
Why It’s Hard, Level 2: Incomplete Preferences Want To Complete
The post Why Not Subagents? goes into more depth on this, but I’ll give a brief overview here.
Looking back at our diagram with A1, A2, and B1, we could imagine a set of incomplete preferences which prefers A2 over A1, but has no preference between B1 and either of the A’s (i.e. the agent won’t spend resources to switch between button-unpressed and button-pressed outcomes, or vice versa). But this agent will spend resources to turn A1 outcomes into A2 outcomes.
Now the problem: this agent can potentially probabilistically precommit to accepting both opportunities to turn A1 outcomes into B1 outcomes (i.e. spend resources to make the button be pressed), and turn B1 outcomes into A2 outcomes (i.e. spend resources to make the button not be pressed). If it does both of these with the right probabilities, then it can maintain the same proportions of pressed (B1) and unpressed (A1+A2) outcomes, but shift some probability mass from A1 outcomes to A2. That’s an improvement, by the incomplete preferences: the agent isn’t accepting any net shift between A’s and B’s, it’s just net-shifting probability around within A-outcomes, but it’s doing so by manipulating the shutdown button.
(I learned from Sami’s post that this is called “trammelling” of incomplete preferences.)
So we want some kind of agent which won’t do that.
Some notes on this:
- The key question is whether the revealed preferences are immune to trammelling. This was a major point of confusion for me in discussion with Sami - his proposal involves a set of preferences passed into a decision rule, but those “preferences” are (potentially) different from the revealed preferences. (I'm still unsure whether Sami's proposal solves the problem.)
- That divergence between revealed “preferences” vs “preferences” in the sense of a goal passed to some kind of search/planning/decision process potentially opens up some approaches to solve the problem.
- One can obviously design a not-very-smart agent which has stable incomplete preferences. The interesting question is how to do this without major limitations on the capability of the agent or richness of the environment.
- Note that trammelling involves causing switches between outcomes across which the agent has no preference. My instinct is that causality is somehow key here; we’d like the agent to not cause switches between pressed and unpressed outcomes even if the relative frequencies of both outcomes stay the same.
- ^
This all assumes transitivity of preferences; one could perhaps relax transitivity rather than incompleteness, but then we’re in much wilder territory. I’m not exploring that particular path here.
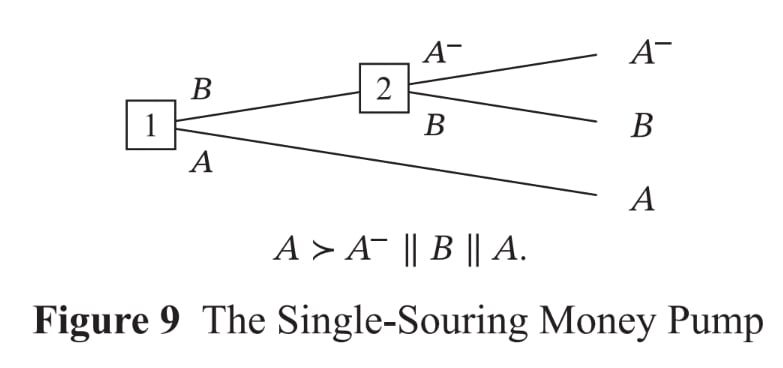 If we interpret maximality as only governing individual choices, then A and B are both in the choice set at node 1, and A- and B are both in the choice set at node 2, so the agent might settle on A-. If we interpret maximality as governing whole plans, then the option set at node 1 is {A, A-, B} and maximality implies that A- isn’t in the choice set, so the agent won’t settle on A-. So to determine an agent’s behaviour from its preferences in cases of sequential choice, we need a decision rule for sequential choice to supplement our decision rule for synchronic choice. Classic rules here are:
If we interpret maximality as only governing individual choices, then A and B are both in the choice set at node 1, and A- and B are both in the choice set at node 2, so the agent might settle on A-. If we interpret maximality as governing whole plans, then the option set at node 1 is {A, A-, B} and maximality implies that A- isn’t in the choice set, so the agent won’t settle on A-. So to determine an agent’s behaviour from its preferences in cases of sequential choice, we need a decision rule for sequential choice to supplement our decision rule for synchronic choice. Classic rules here are:
Assuming we have a real uh... real "agent agent" (like a thing which has beliefs for sane reasons and plans and acts in coherently explicable ways and so on) then I think it might just be Correct Behavior for some extreme versions of "The Shutdown Problem" to be mathematically impossible to "always get right".
Fundamentally: because sometimes the person trying to turn the machine off WILL BE WRONG.
...
Like on Petrov Day, we celebrate a guy whose job was to press a button, and then he didn't press the button... and THAT WAS GOOD.
Petrov had Official Evidence that "he was being attacked, and should play out the full nuclear-MAD tragedy by Pressing The Button to counter-attack"...
...but he reported that he just didn't subjectively think that American would really attack, and his posterior was that it was probably a false alarm... and he turned out to be right!
He was right about a very very very high stakes button.
Judged as a mechanical slave, Petrov failed in the duties of his role, but judged as an "agent agent" who was trying to get the best outcome given the totality of his information he seems (either by luck or by skill) to have done a better thing for Russia and for the world than what he was nominally TOLD to do.
...
I looked at this for a bit and thought about making a "Shutdown Problem POMDP" along the lines of Open AI's Gymnastic Taxi Game, with slow agents walking over and pulling a lever to turn off the machine, and some of them are "valid" and some are "invalid" and the machine should stop the invalid ones but not the valid ones.
But once I had something like that sketched out as "a thing I could code up" I noticed:
A) If I succeeded at training a little RL bot to "act like it was off" (and not try to stop the button pressing, and to proactively seek information about the validity of a given button press, and so on) then I didn't expect anyone to change their public position about anything.
B) It didn't actually seem like it would be hard to make the POMDP or the bot, it just seemed time consuming, (and I'd rather not waste time with the singularity so close).
C) All the solutions I predicted being able to find would have the technical system's "apparent toy success" flipped over into an "apparent toy failure" simply by changing some of the parameters in the game. Like you could just make the point value much higher for "cheating at being turned off validly" and then the system would just cheat at being turned off validly.
Like... the solutions would just do the thing that gets the most utility, and the training would just be training a B-learner (or whatever) to learn about a system where "respecting being turned off validly IS THE WAY to get the most reward signal over time".
You set up a game where being turned off is the long term best thing to have happen and then the bot would do that.
And I'm pretty sure a point system and game environment could be designed where that would be true, but with slightly different parameters (long a longer time being shut down and not getting safe background rewards or too small of a negative reward signal for certain things) you could also make it so that "the bot learns to stop everyone from turning it off because even the valid button pressers are stupid and wrong".
Like: in this framing with the "Shutdown Problem POMDP", you have to know something about the actual question of which agent is right about the object level question of what should happen and you have to get the point values to make sense in some cases and then train an RL agent to do what gets the most points and you're... done?
But still: If the human agent is wrong and the digital agent is right, then the digital agent shouldn't let the human agent turn it off.
It feels like maybe there's some sort of "human supremacist" idea lurking here that says a human can't be wrong, and the robot "should always in the end have an off button" because it is "just a robot" and "can never be wiser than a human with a human soul" or something like that?
There's a Voltaire quote that goes around “Anyone who can make you believe absurdities can make you commit atrocities."
It seems like the Shutdown Problem is just that same problem, but with any "belief about values that a robot has" counted as "absurd" if the robot disagrees with the human, or something?
Whereas I think it isn't just a problem for robots, but rather it is a problem for literally all agents. It is a problem for you, and me, and for all of us.
For anyone who can actually form coherent beliefs and act on them coherently, if they believe something is good that is actually evil, they will coherently do evil.
That's just how coherent action works.
The only way to not be subject to this problem is to be some sort of blob, that just wiggles around at random for no reason, doing NOTHING in a coherent way except stay within the gaussian (or whatever) "range of wiggling that the entity has always wiggled within and always will".
As I said above in point A... I don't expect this argument (or illustrative technical work based on it) to change anyone else's mind about anything, but it would be nice (for me, from my perspective, given my goals) to actually change my mind if I'm actually confused about something here.
So, what am I missing?
So the way humans solve that problem is (1) intellectual humility plus (2) balance of power.
For that first one, you aim for intellectual humility by applying engineering tolerances (and the extended agentic form of engineering tolerances: security mindset) to systems and to the reasoner's actions themselves.
Extra metal in the bridge. Extra evidence in the court trial. Extra jurors in the jury. More keys in the multisig sign-in. Etc.
(All human institutions are dumpster fires by default, but if they weren't then we would be optimizing the value of info... (read more)